Command Palette
Search for a command to run...
MOSS-TTS: A Decoupled, production-grade Speech Generation Model Based on CAT Architecture; Breaking the Barrier of single-cell Analysis: Constructing a cross-cancer Immune Atlas Benchmark Using the Pan-Cancer scRNA-Seq dataset.

Currently, single speech generation models are proving inadequate when faced with complex real-world demands. In practical applications, a speech not only needs to faithfully mimic a specific timbre, but also needs to naturally switch speaking styles across different content and remain stable throughout a narrative lasting tens of minutes. Furthermore, it must support various formats such as dialogue, role-playing, and real-time interaction. These requirements far exceed the capabilities of a single model.
In this context,MOSI.AI and OpenMOSS have released the MOSS-TTS Family of speech generation models.Instead of building a single, massive model, this family of models decouples the speech generation workflow into five production-grade models, including the high-fidelity speech foundation MOSS-TTS and the multi-speaker dialogue model MOSS-TTSD. Its core technology is based on the 1.6B-parameter large-scale audio tokenizer MOSS Audio-Tokenizer, employing a pure Transformer architecture (CAT, Causal Audio Tokenizer with Transformer) to achieve high-fidelity audio reconstruction. This series of models solves many application challenges in complex scenarios, providing a toolchain for the speech generation field that can be directly integrated into the authoring workflow.
The HyperAI website now features "MOSS-TTS: A High-Fidelity Multi-Scene Speech Generation Model." Give it a try!
Online use:https://go.hyper.ai/AtKvk
A quick overview of hyper.ai's official website updates from March 2nd to March 6th:
* High-quality public datasets: 3
* High-quality tutorial selection: 8
* Community article interpretation: 3 articles
* Popular encyclopedia entries: 5
* Top conferences with deadline in March: 4
Visit the official website:hyper.ai
Selected public datasets
1. Drone Sound Audio Detection Dataset
This dataset contains audio recordings of two categories: unknown and drones. It is designed for binary audio classification tasks to detect drone sounds in real-world environments. The audio files in this dataset are provided in standard formats (such as WAV), suitable for preprocessing techniques such as Mel spectrogram extraction, MFCC feature extraction, short-time Fourier transform (STFT), and deep learning models of the raw waveforms.
Direct use:https://go.hyper.ai/vKHJC
2. Adverse Drug Reaction Simulation Dataset
This dataset is designed to mimic pharmacovigilance reports of adverse drug reactions (ADRs) and aims to support research, machine learning experiments, and algorithm development in drug safety monitoring. Case Safety Reports (ICSRs) are artificially generated, inspired by real-world pharmacovigilance systems such as FDA FAERS and EMA EudraVigilance.
Direct use:https://go.hyper.ai/Jex4v
3. Pan-Cancer scRNA-Seq Single-Cell Transcriptional Atlas Dataset
This dataset contains transcriptome expression data from 7,930 single cells, covering three different biological states: healthy immune baseline, liquid tumor (myeloid leukemia), and solid tumor microenvironment (melanoma). It aims to build a cross-cohort integrated single-cell analysis benchmark to provide a benchmark for algorithm performance evaluation and methodological comparison, multi-cohort batch effect correction, immune exhaustion state analysis, and cross-tumor type biomarker mining.
Direct use:https://go.hyper.ai/CnZTc
Selected Public Tutorials
1. ACE-Step 1.5: Music Generation Demo
ACE-Step 1.5 is an open-source music generation foundation model jointly launched by ACE Studio and StepFun, aiming to push the boundaries of open-source music generation capabilities. This model employs an innovative two-stage generation architecture, achieving high-quality, long-duration music content generation through the collaborative integration of a Diffusion Transformer (DiT) and a Language Model (LM).
Run online:https://go.hyper.ai/QZ6oi

2.Qwen3-ASR-1.7B: A New Generation Speech Recognition System
Qwen3-ASR is a new generation of open-source end-to-end Automatic Speech Recognition (ASR) model series launched by Alibaba Cloud's Tongyi Qianwen team. Based on the Qwen3-Omni multimodal foundation model and a self-developed AuT speech encoder, this model focuses on achieving high-precision, multilingual, long-audio, and unified streaming and non-streaming speech-to-text transcription capabilities. Taking raw audio signals as input, the model directly maps them to structured text output through an end-to-end architecture, while supporting character/word-level millisecond-level timestamp alignment. It is suitable for numerous scenarios such as meeting transcription, intelligent captioning, customer service voice archiving, and dialect-based voice interaction.
Run online:https://go.hyper.ai/zb0Vi

3.Deploying vLLM+Open WebUI with Qwen3-Coder-Next
Qwen3-Coder-Next is a lightweight code generation model open-sourced by Alibaba Cloud's Tongyi Qianwen, focusing on all-scenario programming assistance and code generation tasks. Its core advantages are "high performance, low barrier to entry, and easy deployment." Based on the optimized Qwen3 large language model architecture, it integrates pre-trained data specific to the code domain (covering 80+ mainstream programming languages and 1 billion+ code snippets) and RLHF (Human Feedback Reinforcement Learning) code alignment optimization. It has achieved top-tier performance among open-source models in the three authoritative code benchmarks: HumanEval+, MBPP, and MultiPL-E, with performance approaching that of CodeLlama-70B. It is suitable for various programming scenarios, including algorithm writing, business code generation, code commenting, cross-language code conversion, and bug fixing.
Run online:https://go.hyper.ai/ukxPt
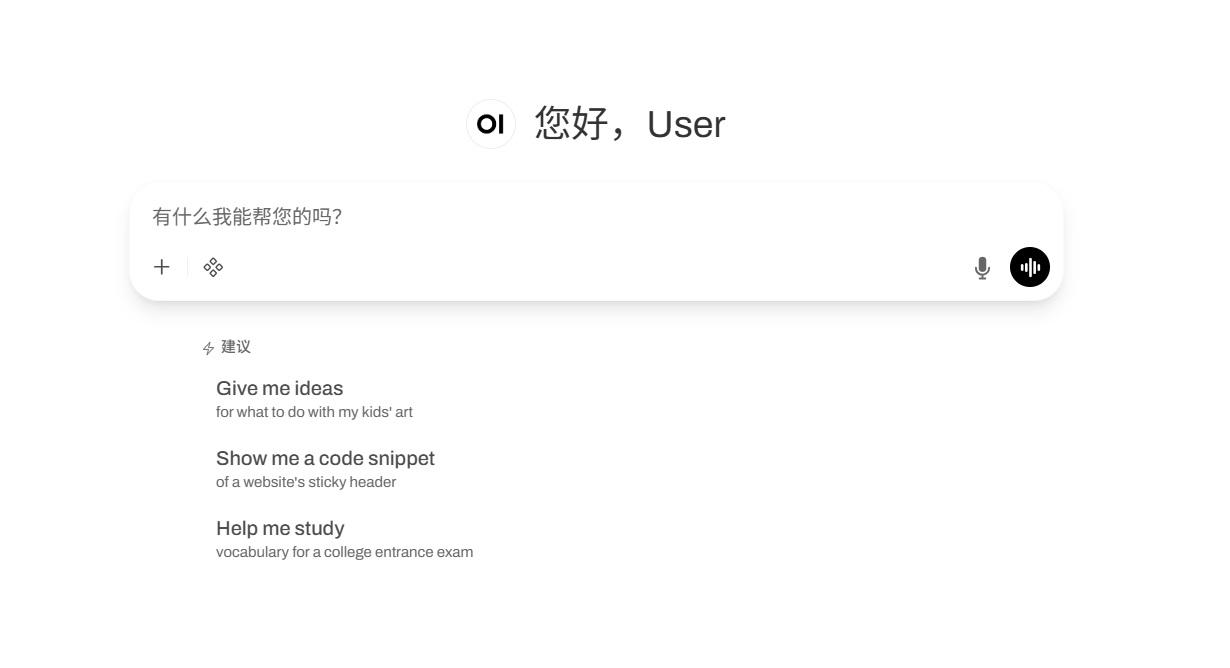
4. VibeVoice-ASR: Multifunctional End-to-End Speech Recognition Demo
VibeVoice-ASR is a high-performance, multi-functional end-to-end speech recognition (ASR) model open-sourced by Microsoft, designed to provide structured, context-aware speech-to-text services for long audio content. This model employs an advanced unified audio modeling architecture, capable of processing audio files up to 60 minutes long at a time. It supports generating structured outputs containing speaker identity (Who), timestamps (When), and transcribed content (What), and allows users to provide contextual information to improve recognition accuracy. Its core technological breakthroughs lie in its efficient long sequence modeling capabilities and cross-lingual multi-task learning mechanism, completely solving the temporal alignment and semantic coherence problems of traditional ASR models when processing long audio files.
Run online:https://go.hyper.ai/8eMFX
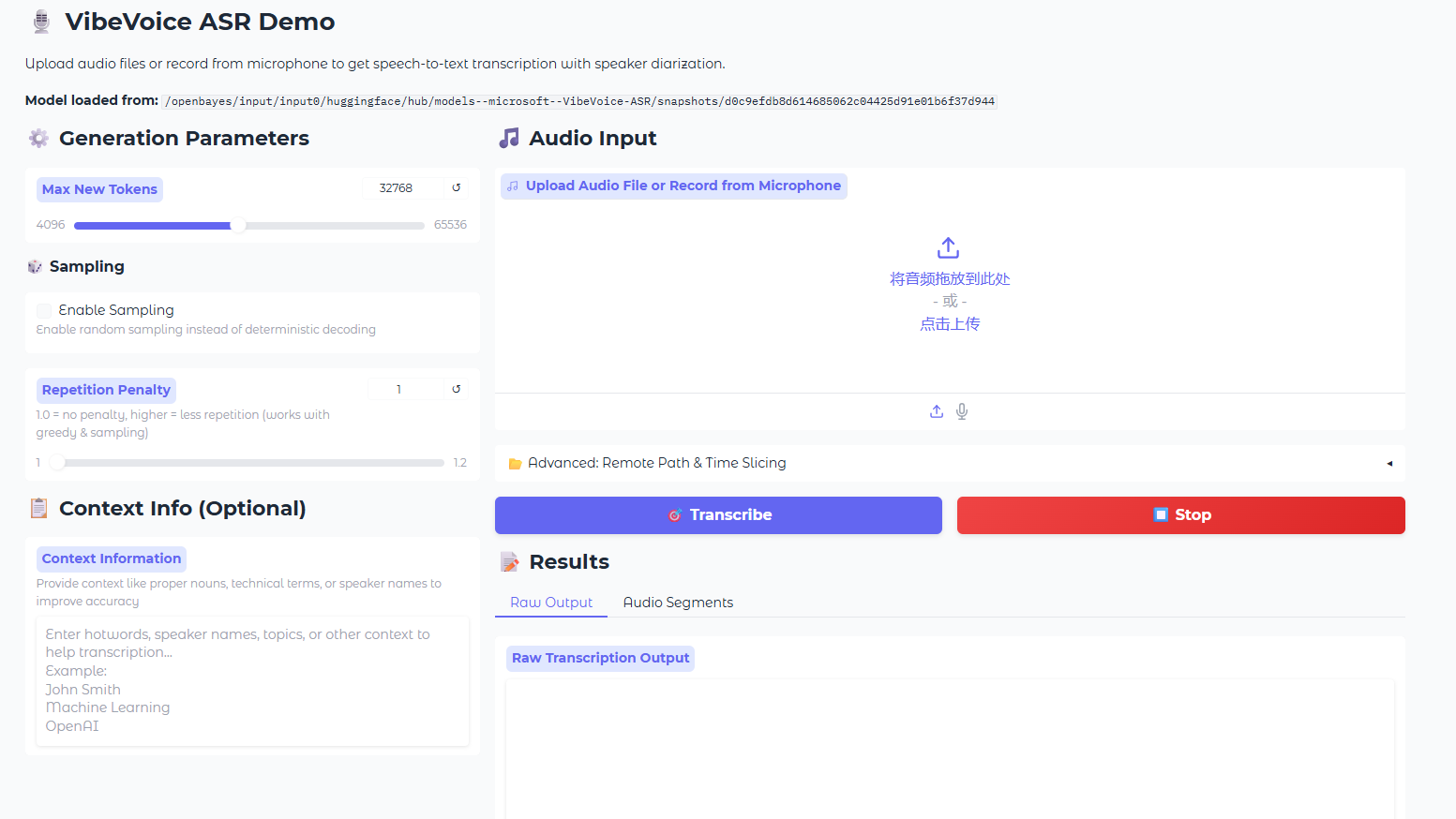
5. MOSS-TTS: A high-fidelity multi-scene speech generation model
The MOSS-TTS series is an open-source speech generation model series launched by MOSI.AI and the OpenMOSS team. When a single audio segment needs to sound human-like, with accurate pronunciation of each word, switching speaking styles across different content, maintaining stability for tens of minutes, and supporting dialogue, role-playing, and real-time interaction, a single TTS model often falls short. Therefore, this project decouples the speech generation workflow into five production-grade models that can be used independently or combined, including the core MOSS-TTS basic model, the MOSS-TTSD multilingual dialogue model, the MOSS-VoiceGenerator voice design model, the MOSS-SoundEffect sound effect generation model, and the MOSS-TTS-Realtime real-time interaction model. This series supports 20 languages and primarily addresses real-world application challenges such as high-fidelity zero-sample speech cloning, stable long text synthesis up to one hour, multilingual and mixed Chinese-English generation, and fine-grained duration and phoneme-level pronunciation control in complex scenarios.
Run online:https://go.hyper.ai/AtKvk
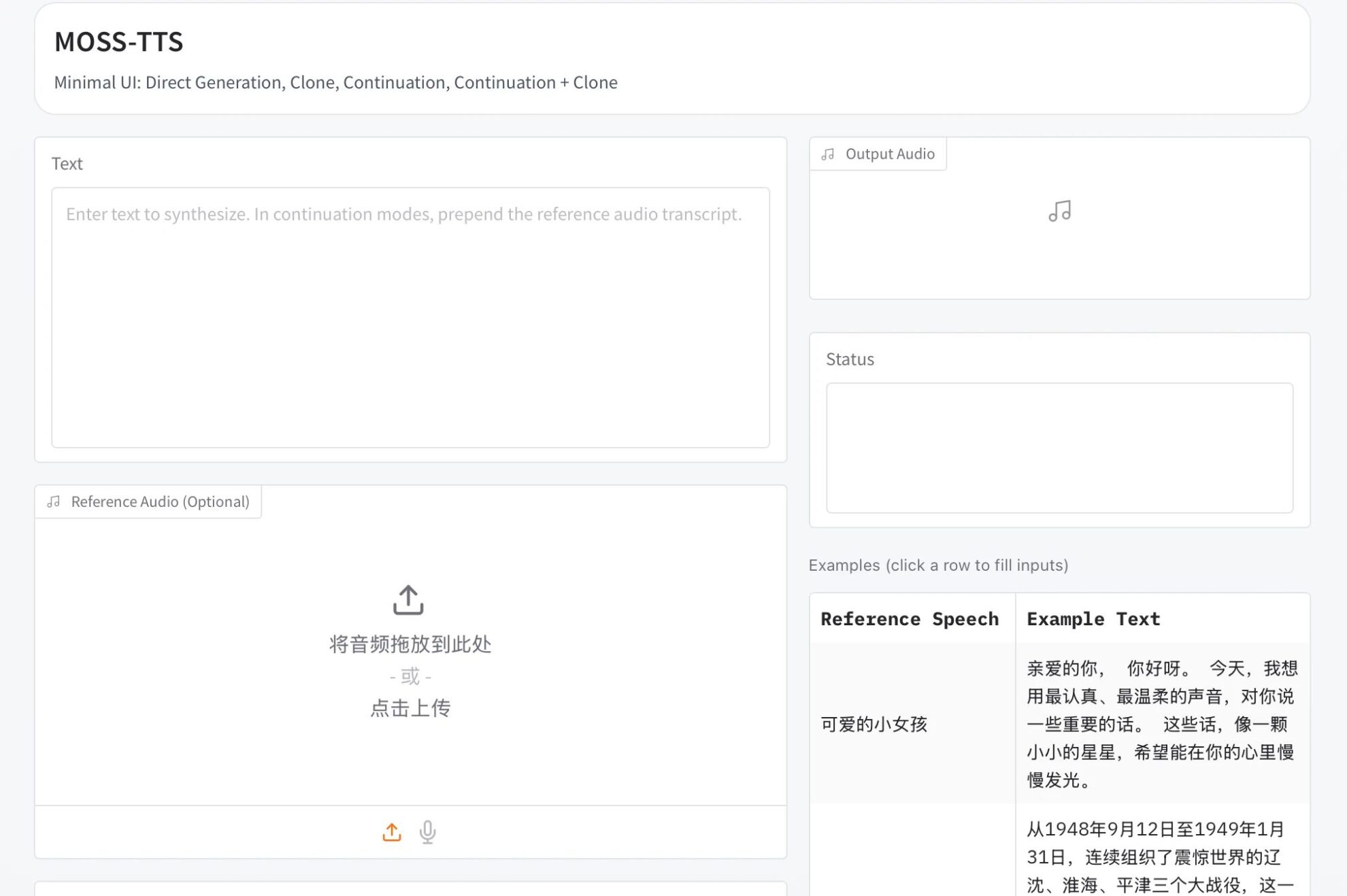
6.Z-Image: Alibaba's open-source text-based image model with 6 billion parameters
Z-Image is a new generation of high-efficiency image generation model launched by the Alibaba Cloud Tongyi Qianwen team. After releasing the Z-Image-Turbo distilled version and making it the top open-source model on the Artificial Analysis list, the Z-Image team officially open-sourced the Z-Image Standard version. As the main community base model of the Z-Image series, the Standard version is a complete, undistilled model that excels in generation quality, style diversity, and secondary development support. It aims to provide community developers with a powerful and flexible image generation foundation, unlocking more possibilities for customized development and fine-tuning.
Run online:https://go.hyper.ai/SsDMv
7. Qwen3-TTS: High-quality, controllable multilingual speech synthesis demo
Qwen3-TTS-12Hz-1.7B-CustomVoice is a new generation of high-quality text-to-speech (TTS) model launched by the Alibaba Tongyi team. This model focuses on achieving multilingual speech synthesis, multi-speaker (Custom Voice) control, text-based style and emotion adjustment, and high-naturalness, low-latency speech generation within a single unified framework. Based on a 12Hz acoustic modeling framework with 1.7B parameters, the model demonstrates excellent performance in speech intelligibility, prosodic consistency, and cross-lingual stability. By introducing the CustomVoice mechanism, the model can directly switch preset speakers during the inference stage without additional training, and combined with natural language style instructions, it achieves more refined expression control.
Run online:https://go.hyper.ai/xWsQ6
8. FoundationMotion Video Q&A System
FoundationMotion is a video understanding and question-answering system jointly developed by NVIDIA and MIT, based on Qwen2.5-VL fine-tuning. It aims to understand and reason about spatial motion in videos. By incorporating visual language pre-training technology, the model can intelligently analyze uploaded video content and answer related questions.
Run online:https://go.hyper.ai/JlGZk
Community article interpretation
1. Breaking through the limitations of traditional multimodal integration! MIT proposes the APOLLO framework, achieving a clear separation of cell-shared and cell-specific information.
With the continuous evolution of single-cell technology and the rapid growth of data scale, how to efficiently and automatically integrate multimodal data while clearly decoupling shared information from modality-specific information has become a core challenge facing single-cell biology. To address this challenge, a joint research team from MIT and ETH Zurich has proposed a general deep learning computing framework, APOLLO (Autoencoder with a Partially Overlapping Latent Space Learned through Latent Optimization). This framework provides a feasible technical path for more comprehensive and accurate analysis of cell states and their regulatory logic by explicitly modeling shared and modality-specific information.
View the full report:https://go.hyper.ai/jaCKf
2. Online Tutorial | Based on 5 million hours of voice data, Qwen3-TTS achieves 3-second voice cloning and fine-tuning.
When generative AI is no longer limited to "generating text" but begins to truly "produce sound," speech is upgraded from an information channel to a programmable and malleable medium of expression. Along this technological evolution path, the new generation of models is beginning to attempt to break through the boundaries of traditional TTS—not only pursuing higher fidelity but also emphasizing multilingual generalization and fine-grained control. Qwen3-TTS, recently open-sourced by the Qwen team, is based on a dual-track language model (LM) architecture, enabling fine-grained control of the output speech while simultaneously synthesizing it in real time.
View the full report:https://go.hyper.ai/eKr7T
3. MIT develops Pichia-CLM model to learn the "language" of yeast DNA, potentially increasing exogenous protein production by up to 3 times.
Currently, various codon optimization tools and methods based on host CUBs have been developed in the industry, but these methods may still not consistently produce highly expressed constructs. In recent years, with the development of artificial intelligence, especially sequence modeling technology, researchers have begun to treat gene sequences as a kind of "language," attempting to learn the implicit rules within them through methods similar to natural language processing. Against this backdrop, a research team from MIT proposed a deep learning-based language model, Pichia-CLM, for codon optimization in the industrial host Pichia pastoris to improve the yield of recombinant proteins.
View the full report:https://go.hyper.ai/a4H2G
Popular Encyclopedia Articles
1. Visual Language Model (VLM)
2. HyperNetworks
3. Gated Attention
4. Human-in-the-loop (HITL)
5. Neural Radiance Field (NeRF)
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:
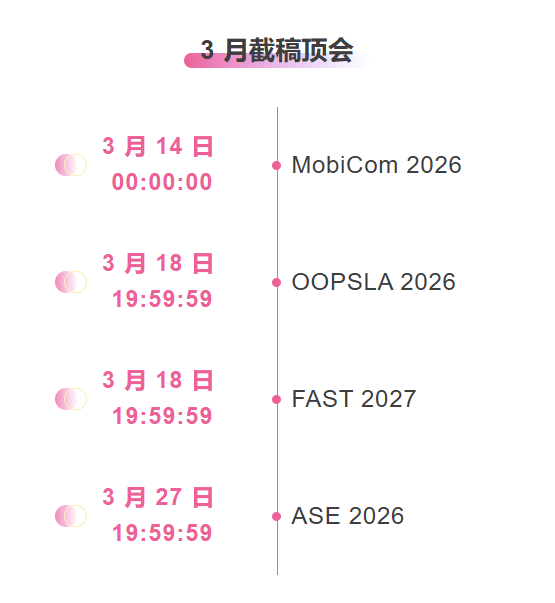
One-stop tracking of top AI academic conferences:https://go.hyper.ai/event
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!
See you next week!








