Command Palette
Search for a command to run...
CUDA's Initial Team Members Sharply Criticized cuTile for "specifically Targeting" Triton; Can the Tile Paradigm Reshape the Competitive Landscape of the GPU Programming Ecosystem?

In December 2025, nearly twenty years after the release of CUDA, NVIDIA launched the latest version, CUDA 13.1. The core change lies in the new CUDA Tile (cuTile) programming model.The GPU kernel structure has been reorganized through a "Tile-based" programming model, allowing developers to write high-performance kernels without directly manipulating the underlying CUDA C++.This is undoubtedly a noteworthy milestone for the GPU programming ecosystem: it may be a new tier of product launched by NVIDIA to address the growing demand for custom operators in the AI era and further enhance the stickiness of the software ecosystem.
After entering the public eye, cuTile quickly sparked widespread discussion in the developer community regarding the development cycle of custom operators, direct competition with Triton, and whether it could become the default entry point for Python. Although cuTile is still in a very early stage, current developer feedback suggests it already has the potential to become a new paradigm.
As the relevant ecosystem gradually takes shape, cuTile's positioning and potential are becoming clearer. On GitHub, in forums, and within internal projects, numerous engineers have affirmed cuTile's improvements in code organization and readability, while some community users have attempted to migrate existing CUDA code to cuTile. With support for the Python ecosystem, will cuTile become the mainstream entry point for GPU programming, or will it create a new technical division of labor between CUDA and Triton? As more real-world workloads emerge, these answers may gradually become clearer in the coming years.
cuTile: Ushering in an Era of "Code-Focused" GPU Programming
For a long time, CUDA has provided developers with a hardware and programming model of Single Instruction Multithreading (SIMT), allowing them to describe the parallel computing logic of the GPU at the granularity of "threads": a kernel is divided into thousands of threads, each thread performs a small segment of computation, groups of threads form blocks, and then the hardware maps them to the Streaming Multiprocessor (SM) for execution.
However, with the exponential growth in computing demands, especially the scale of AI training, over the past 3-5 years, this thread-centric programming has encountered more and more bottlenecks.Researchers and engineers not only need to understand thread scheduling, but also need to deeply consider memory coalescing, warp divergence, and even the execution format of Tensor Cores. In other words, writing a high-performance CUDA kernel requires a thorough understanding of all aspects of the graphics card architecture; otherwise, it is difficult to fully utilize the hardware's capabilities.
The emergence of cuTile is NVIDIA's response to this trend—allowing developers to return to algorithms, while leaving the hardware performance boost to the framework.
Specifically,cuTile is a parallel programming model for NVIDIA GPUs and also a Python-based domain-specific language (DSL). It automatically leverages advanced hardware capabilities.For example, Tensor Cores and Tensor Memory Accelerators, and maintain good portability across different NVIDIA GPU architectures.

From a technical perspective,The foundation of CUDA Tile is CUDA Tile IR (Intermediate Representation), which introduces a set of virtual instructions that allows hardware to be natively programmed in a Tile-based manner. Developers can write higher-level code that can be executed efficiently across multiple generations of GPUs with minimal modifications.
Although NVIDIA's Parallel Thread Execution (PTX) guarantees the portability of SIMT programs,However, CUDA Tile IR extends the CUDA platform to natively support tile-based applications.Developers can focus on dividing data-parallel programs into tiles and tile blocks, with CUDA Tile IR handling the mapping of these tiles to hardware resources, including threads, memory hierarchies, and tensor cores. In other words, tile-based programming allows developers to write algorithms by specifying tiles and defining the computational operations performed on those tiles, without needing to configure the execution method for each element of the algorithm individually—leaving those details to the compiler.
Why did NVIDIA choose to update its programming paradigm after 20 years of CUDA implementation?
The release of cuTile comes nearly twenty years after the initial release of CUDA.Since its release in 2006, CUDA has gradually evolved from a GPU programming interface into a complete ecosystem that spans frameworks, compilers, libraries, and toolchains, and continues to serve as a core infrastructure of NVIDIA's software system to this day. NVIDIA's decision to launch a new programming paradigm to iterate on CUDA in 2025 is not merely a technological evolution, but a direct response to changes in the industry environment.
On the one hand, the changing AI workloads have brought about an extremely high demand for custom operators, and the development speed, debugging costs, and talent shortage of traditional CUDA C++ have become constraints. Many teams can design algorithms quickly, but find it difficult to write high-performance, maintainable CUDA kernels in a short period of time. The launch of cuTile is precisely to solve this contradiction: without sacrificing performance, it provides a Python-friendly entry point, allowing more developers to build custom operators at a controllable cost, thereby lowering the overall threshold for GPU programming and shortening the iteration cycle.
In other words,cuTile is NVIDIA's early strategic move to reclaim control of the programming paradigm before the full-scale operator DSL wars begin.
On the other hand, under the trend of "de-Nvidiaization", the competition in the GPU software ecosystem is becoming increasingly fierce: AMD launched the open-source accelerated computing platform ROCm, attracting more third-party libraries and tools to join through open architecture and expanding ecosystem coverage; Intel launched OneAPI, attempting to build a unified programming model across architectures and providing language support such as DPC++ to reduce the complexity of heterogeneous system development. All of these are weakening CUDA's exclusive position.
Furthermore, AI large-scale model companies and chip companies are also racing to develop their own operator DSLs. As early as October 2022, OpenAI released Triton. This open-source deep learning programming language compiler for GPUs allows developers to write high-performance GPU kernels using concise Python-style code without delving into the low-level details of CUDA C++. As a result, Triton quickly gained attention within the community. Many researchers and engineers believe that Triton lowers the entry barrier for GPU operator development. Meanwhile, the Meta/FAIR-related TC/tensor languages, and the operator compilation and optimization frameworks built by the community around TVM/Relay/DeepSpeed, also provide diverse options for competition in specific areas of the software ecosystem.
This directly led to the emergence of cuTile—in order to solidify its commercial moat, NVIDIA had to further improve the packaging and user experience of its software system, so that more developers would choose to stay in the CUDA ecosystem. SemiAnalysis published an article stating that the introduction of cuTile is an important move by NVIDIA to deepen its CUDA moat."The PyTorch compiler now supports NVIDIA Python CuTeDSL in addition to Triton, making FlexAttention twice as fast as the Triton implementation. NVIDIA has been a strong supporter of its closed-source Python CuTeDSL, cuTile, and TileIR ecosystem. Through Python CuTeDSL/cuTile/TileIR, NVIDIA has regained access to closed-source compiler optimizations."
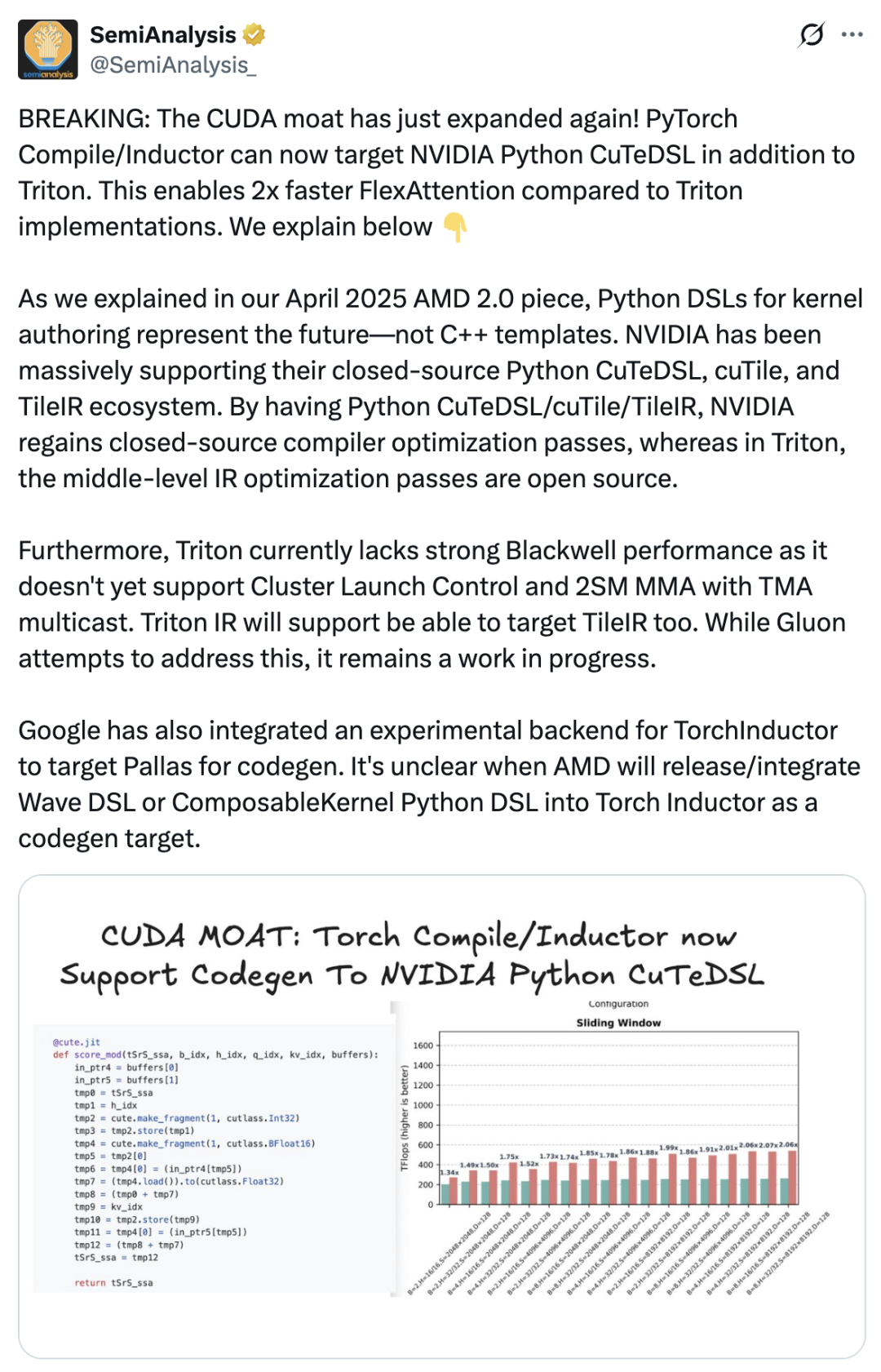
Copying Triton? cuTile's "Tile Mindset": Here's what the developers say.
In fact,The market response to cuTile has been mixed with controversy.Some developers who used it reported that while the Tile optimization was a novel improvement, the excessive number of DSLs also introduced new learning curves. Reddit user Previous-Raisin1434 commented that the new DSLs in cuTile made him feel overwhelmed during the transition period.
"Why are there suddenly thousands of different things? I was using Triton before, and now NVIDIA has released more than a dozen new DSLs," he complained.
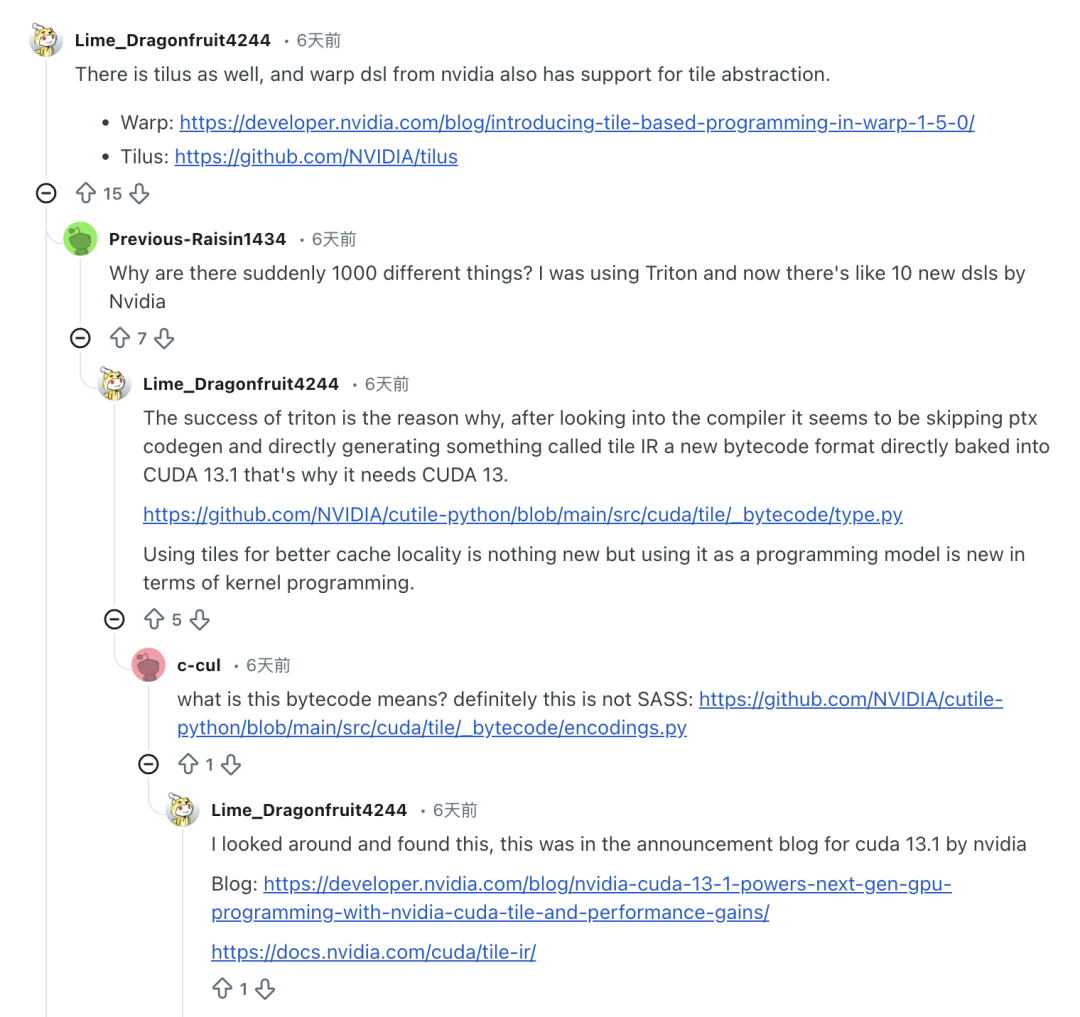
Meanwhile, some industry professionals have questioned cuTile's lack of differentiation and originality, saying, "cuTile feels like NVIDIA's response to Triton, Mojo, and ThunderKittens, as if they've been integrated together."

In this regard,Nicholas Wilt, a member of the initial CUDA team, even posted that..."It's hard not to suspect that cuTile was developed directly to counter Triton. cuTile is a new eDSL for writing kernels, just like Triton or Helion."
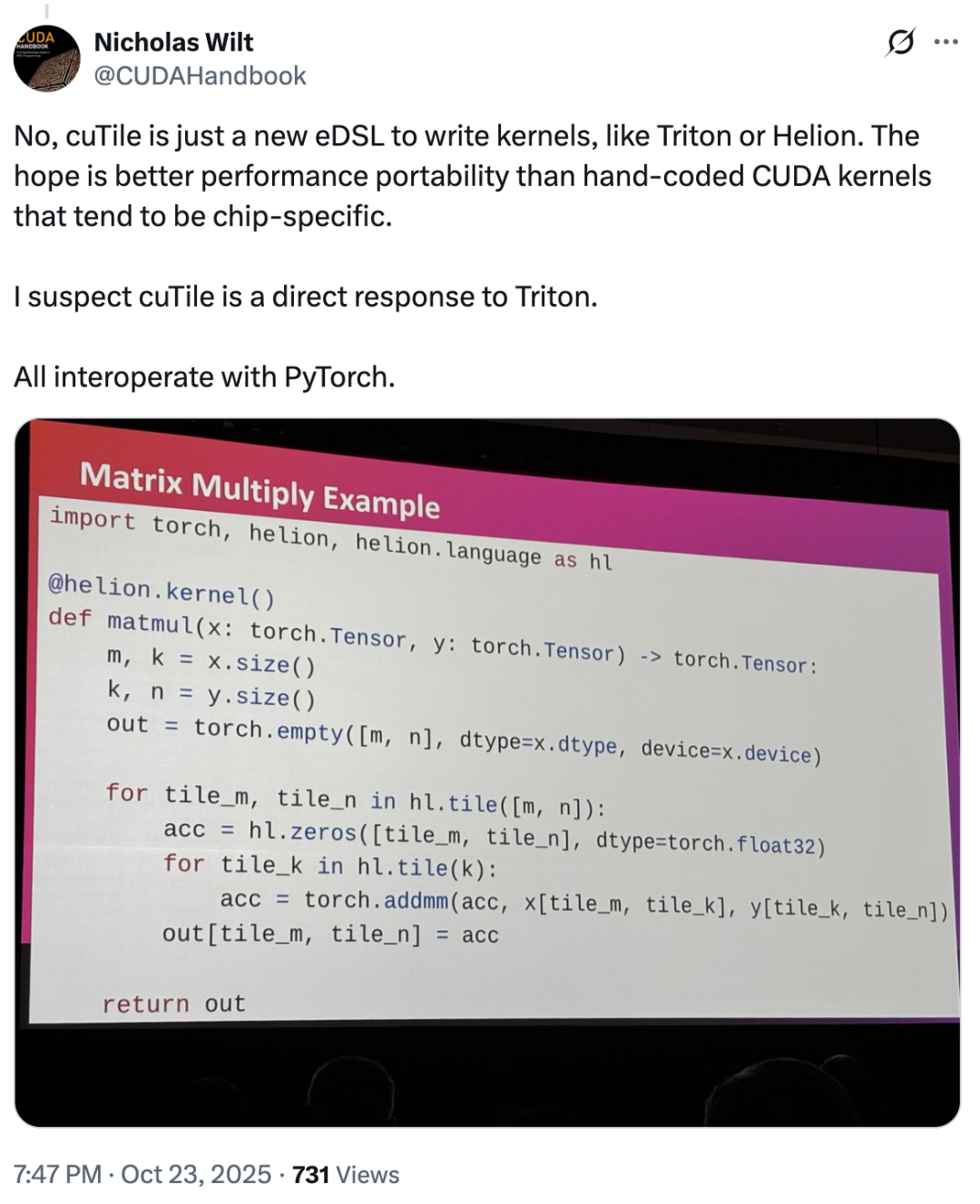
So, did cuTile copy Triton? Most users answered no – in fact, cuTile's market response has been generally optimistic, with only a few dissenting opinions.Most users did not express dissatisfaction with this update; some even praised cuTile as a "revolutionary product.""cuTile eliminates the need for users to worry about memory swapping, warp spclz, memory merging, and over a hundred other issues."
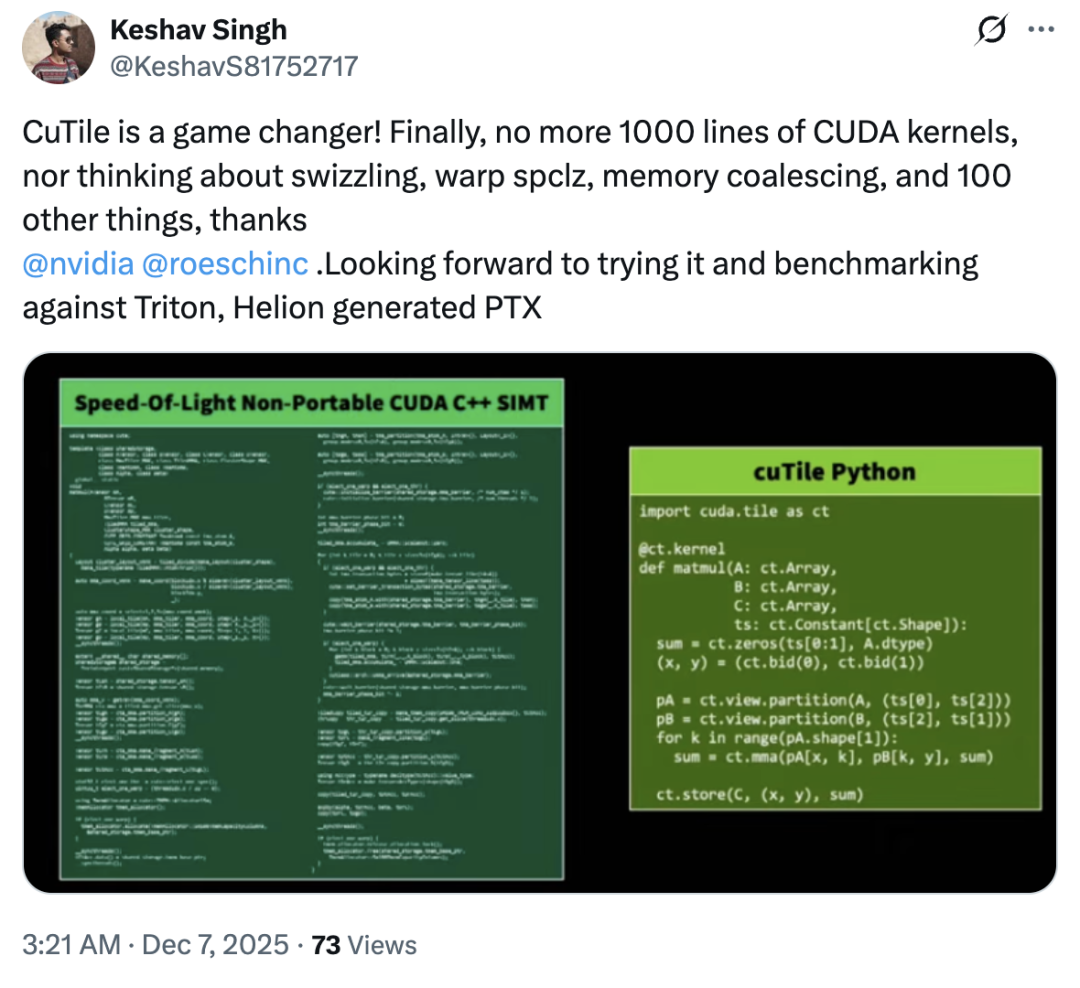
According to a tech blog, the core appeal of cuTile in winning over users lies in its "Tile" concept, which introduces GPU computing to a higher level of abstraction.
"I initially thought this was just another Python binding or simplified wrapper for CUDA, but after delving into its documentation and examples, I discovered it has much greater ambitions." The core idea of cuTile is Tile, which is relevant to parallel computing and hardware acceleration.Tiling is a classic optimization technique that divides large datasets into smaller chunks to better utilize caches or shared memory. cuTile elevates this idea to the level of a programming model. The blog states, "It allows developers to think about and describe computation directly in terms of tiles. You no longer need to explicitly manage how each thread in a block of threads collaborates, how data is loaded from global memory to shared memory, or how synchronization is performed. Instead, you define the tiles of your data, define the operations performed on those tiles, and the cuTile compiler automatically generates efficient kernel code to handle those tedious low-level details."
Although cuTile is still in its early stages, there have been instances of proactively exploring migration paths within the industry.Some algorithm professionals have begun to try to build automated conversion tools from CUDA C++ to cuTile.The aim is to build a viable bridge between existing engineering code and the new paradigm. Among these efforts, developers in the Reddit community have launched an open-source project that can translate parts of the CUDA Kernel into a tile-based format to meet the community's potential migration needs.
However, there is no clear answer as to how far NVIDIA's "Tile" paradigm can go—as a new product, cuTile has only just entered the validation phase. If the migration toolchain from CUDA to cuTile matures further, and the community is willing to form new circles of experimentation and discussion around cuTile, then cuTile may occupy an unprecedented position in the future GPU software ecosystem.However, the outcome of failing to cross these thresholds is quite clear—cuTile may have ended up as a brief experiment in the long history of CUDA.In conclusion, in the current competitive environment, the continued appeal of cuTile will depend on its ability to continuously optimize the development experience, reduce migration costs, and provide irreplaceable performance advantages for complex operators.
Reference Links:
1.https://byteiota.com/nvidia-cutile-python-gpu-kernel-programming-without-cuda-complexity/
2.https://veyvin.com/archives/github-trending-2025-12-08-nvidia-cutile-python
3.https://cloud.tencent.com/developer/article/2512674
4.https://developer.nvidia.com/blog/focus-on-your-algorithm-nvidia-cuda-tile-handles-the-hardware








