Command Palette
Search for a command to run...
SEER Is Just the Beginning? The US NIH Issued a Document Prohibiting Chinese Users From Accessing Core Biomedical Data, and Domestic Databases Are Already in Place

On April 5, the news that "SEER database is prohibited for Chinese users" spread like wildfire in the domestic academic circle.
An official reply email received by a doctoral student at Heidelberg University was reprinted by many media outlets, which clearly stated that "starting April 4, 2025, the National Institutes of Health will prohibit researchers and institutions from certain countries from accessing any ongoing projects involving the National Institutes of Health CADRS and related data, and will terminate these projects.These specific countries include China (including Hong Kong and Macau), Russia, Iran, North Korea, Cuba and Venezuela."
In fact, the National Institutes of Health (NIH) of the United States has issued a notice on April 2, local time.It was announced that starting April 4 local time, institutions located in countries of concern will be prohibited from accessing the NIH controlled access database and related data.
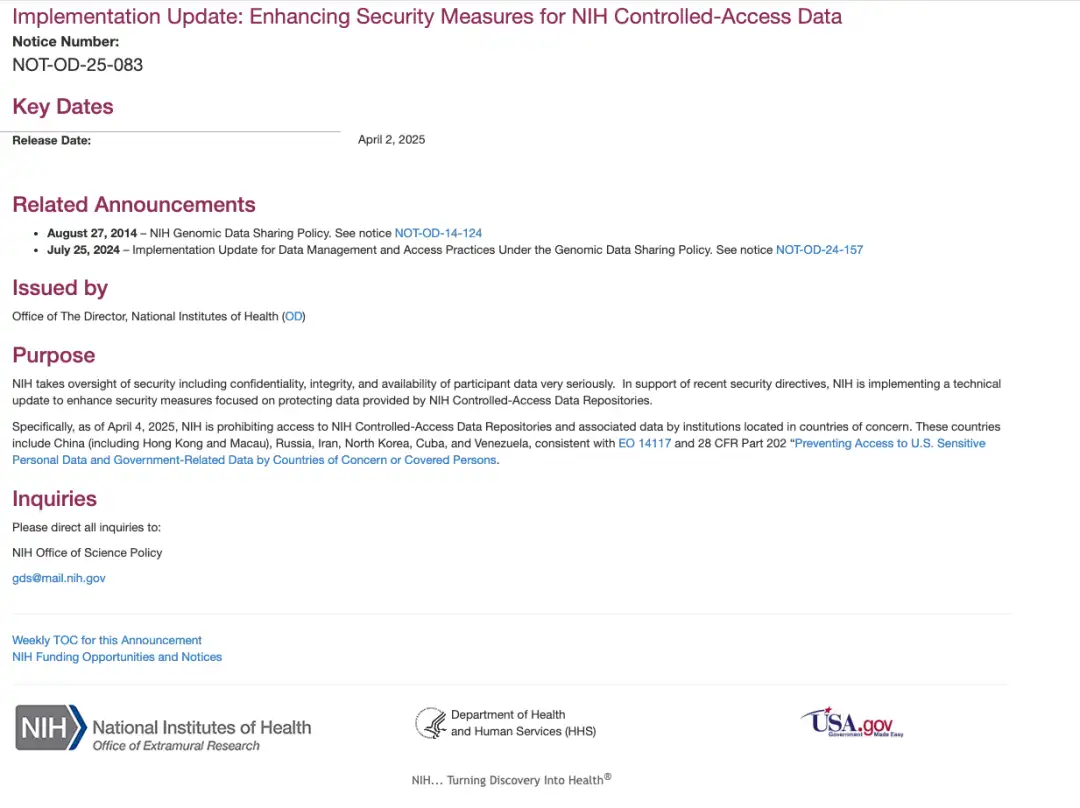
Executive Order No. 14117 mentioned in the notice was issued in February 2024. The U.S. government launched an "Executive Order on Preventing Certain Countries from Accessing Large Amounts of Sensitive Personal Data of U.S. Citizens and U.S. Government-Related Data." As the name suggests, it restricts six "countries of concern" such as China, Russia, and Iran from accessing "large amounts of sensitive personal data and U.S. government-related data" of U.S. citizens.

Among all the "sensitive data", bioinformatics data is the hardest hit.

A scientific cold war may begin
One year after the executive order was issued, it has finally affected the academic field that advocates openness and borderlessness. As the first shot fired by NIH, SEER's influence is evident.
SEER is a cancer data statistical system established and maintained by the National Cancer Institute (NCI) of the United States.Since its operation in 1973, it has become one of the most authoritative and commonly used cancer epidemiology databases in the world, covering about 48% of the U.S. population. The data covers basic information such as age, gender, diagnosis time, diagnosis information such as cancer type, pathological classification and staging, treatment information such as surgery, radiotherapy/chemotherapy, and follow-up information such as survival time and survival status. Undoubtedly, this database has extremely high research value in the fields of tumor epidemiology, public health, and prognostic models.
Admittedly, the ban on the SEER database is the final word, but there are still many well-known databases that are in danger.
As the main medical research institution in the United States, NIH has 27 institutes and centers focusing on different disease areas.Among them, the NCI, which focuses on cancer research, not only maintains the SEER database, but also manages the Cancer Genome Atlas TCGA (The Cancer Genome Atlas); the National Institute of General Medical Sciences (NIGMS), which focuses on basic biological research, is responsible for maintaining the protein database Protein Data Bank; the U.S. National Library of Medicine (NLM) owns the world's leading medical literature database PubMed; the U.S. National Center for Biotechnology Information (NCBI) owns the genotype-phenotype database dbGaP...
The above commonly used high-value databases all belong to NIH. In other words, they are all banned from access by Chinese users. It may only be a matter of time. The restrictions on data will lead to one-sided research results on the one hand, and increase the difficulty and cycle of research on the other hand. This is undoubtedly a wake-up call for the domestic scientific research community. In addition to actively promoting cooperation with overseas teams, it is of great significance to build an internationally representative "Chinese database".
Actively build local database
The importance of data to scientific research needs no elaboration. Whether it is traditional scientific research or today's AI for Science, it is an important support for research conclusions. Especially in the biological and medical fields, data collection is more difficult. Therefore, as early as after the issuance of Executive Order No. 14117, researchers warned that the database of the National Center for Biotechnology Information (NCBI) and the Cancer Genome Atlas (TCGA) and other high-frequency data are at risk of restricted access.
An industry insider said in an interview with DeepTech, "To deal with the problem of restricted access to this database, I think there may be several points worth trying. First, Chinese scholars can make a collective appeal and hold some consultations with the US to see if there are some feasible solutions, such as changing the database that is restricted to a paid system. Secondly, we can cooperate with other third-party countries that are not restricted. Finally, the most important point is that China needs to quickly establish our own database.Once we have built our own database, we will have more bargaining chips when we negotiate with the Americans. For example, we can discuss whether the two sides should open their databases to each other and achieve mutual sharing."
Although it is still difficult to completely replace SEER in the short term, the accumulation of domestic life science and medical databases has achieved certain results over a long period of time, and some databases can serve as supplements to a certain extent.
For example, the National Genome Science Data Center focuses on the construction of database systems and data resources around genome data of humans, animals, plants, and microorganisms.Currently, we have built the BioProject database for sharing biological research project information, the global biological database directory Database Commons, the genome variation database Genome Variation Map (GVM), the life science literature library OpenLB, and so on.
* Official website:https://ngdc.cncb.ac.cn/
The National Center for Bioinformatics has currently collected 69.9PB of domestic data and 7.75PB of international data.Its bioinformatics database platform includes data such as Genome, RNA-seq, epigenome, etc. Commonly used databases include the public archive database for multi-species whole genome data (Genome Warehouse, GWH), the resource library for sharing biological sample information_Biological Sample Database (BioSample), etc.
*Official website:https://www.cncb.ac.cn/
The China National GeneBank DataBase (CNGBdb) platform built by the Shenzhen National GeneBank (CNGB)Provide biological genetic resource samples and information sharing and application services,Support data submission and archiving, computational analysis, knowledge retrieval, and scientific database development.
It has jointly established the STOmicsDB (Spatial Transcript Omics DataBase) spatiotemporal data portal with the Spatiotemporal Omics Consortium (STOC).The spatial transcriptome data archiving standard and system have been established to support several major scientific projects, including the Mouse Embryonic Development Spatiotemporal Transcriptome Atlas (MOSTA). Through STOmicsD, users can submit a variety of data types, including raw sequencing data, spatial transcriptome matrices, annotation files, image information, and data analysis and visualization of downstream analysis results.
also,The CDCP (Cell-omics Data Coordinate Platform) cell group data portal it built,It has achieved the integration and standardization of multi-dimensional cytogenomics data, supported a number of major scientific projects such as the Non-Human Primate Cell Atlas (NHPCA), and provided a highly efficient cytogenomics data collaboration platform for researchers around the world.
The Genomics Data Portal it initiated is dedicated to the integration and sharing of global biodiversity data.By launching major scientific programs such as the Earth BioGenome Project (EBP) and MEER (Mariana Trench Environmental and Ecological Research), we provide rich genomic data resources in the field of biodiversity to researchers around the world.
Conclusion
Nowadays, science and technology have become the main arena of the game between major powers, especially with the rapid development of AI, scientific research without borders seems to be no longer pure. However, in recent years, independent control and domestic substitution have made achievements in many fields. While calling for openness and win-win results and promoting international cooperation, it is more urgent to strengthen the construction of local databases.
References:








