Command Palette
Search for a command to run...
A6000 Card With one-click start-up AlphaFold3 Tutorial Is Online! 360-degree Motion Capture Dataset Released, Including More Than 70,000 Videos and 50 Physical Objects

Last week, HyperAl updated the AlphaFold3 dependency database, but many friends reported that the data was too large and difficult to deploy.
This week,The hyper.ai official website launched the "AlphaFold3 Protein Prediction Demo", the relevant data and models have been installed and configured, occupying less than 300 MB of personal storage, and only a single A6000 card is required to quickly deploy and use AlphaFold3 to predict proteins.
Online use:https://go.hyper.ai/KHIRR
From December 16 to December 20, hyper.ai official website updates:
* High-quality public datasets: 10
* Selection of high-quality tutorials: 3
* Community article selection: 4 articles
* Popular encyclopedia entries: 5
* Top conferences with deadlines in January: 9
Visit the official website:hyper.ai
Selected public datasets
The dataset consists of more than 10k drone images with annotated bounding boxes around each drone. The bounding boxes provide precise localization information to detect and track drones in a variety of backgrounds and environments. The dataset is suitable for training and evaluating computer vision models for object detection tasks, especially in applications such as surveillance, drone detection, and autonomous tracking.
Direct use:https://go.hyper.ai/686JV

2. 360Motion-Dataset Motion Capture Dataset
The V1 version of this dataset contains 72k videos covering 50 different entities, such as various animals, and 6 Unreal Engine (UE) scenes, including 1 desert scene and 2 HDRI scenes. In addition, the dataset also contains 121 different trajectory templates, providing researchers with rich movement patterns and behavior changes.
Direct use:https://go.hyper.ai/rsmeQ

This dataset is used to classify and segment brain tumors using various models. It contains 7,153 images in total, including 1,621 glioma images, 1,775 meningioma images, 1,757 pituitary images, and 2,000 tumor-free (healthy brain) images.
Direct use:https://go.hyper.ai/zgX7A
4. LAION-SG Large-Scale High-Quality Image Understanding Dataset
LAION-SG contains 540,005 scene graph-image pairs with object, attribute and relationship annotations, which are divided into training, validation and test sets. The images in the dataset come from the LAION-Aesthetics V2 (6.5+) dataset, and the annotation process uses GPT-4o for automatic annotation.
Direct use:https://go.hyper.ai/HHT6V

5. Clothing Attributes Dataset
The dataset contains 1,856 images with 26 basic clothing attributes, such as long-sleeves, has collar, and striped pattern. The labels were collected using Amazon Mechanical Turk.
Direct use:https://go.hyper.ai/7f3ej

6. Detect Al-Generated Faces Facial Detection Dataset
The dataset contains 3,203 high-quality images of real faces and AI-generated synthetic faces, including 2,202 real images and 1,001 AI-generated images, designed for machine learning and deep learning applications. It aims to provide a resource for distinguishing real faces from AI-generated facial images, suitable for tasks such as deep fake detection, image authenticity verification, and facial image analysis, and can support cutting-edge research and applications.
Direct use:https://go.hyper.ai/SwMXL

7. U-MATH Mathematical Reasoning Dataset
The dataset contains 1.1k unpublished college-level math problems derived from real teaching materials and covers six core math topics: elementary mathematics, algebra, differential calculus, integral calculus, multivariable calculus, and sequences and series.
Direct use:https://go.hyper.ai/FcNc2
8. Open01-SFT supervised fine-tuning dataset
The OpenO1-SFT dataset is a dataset that focuses on activating the Chain-of-Thought ability of language models using the supervised fine-tuning (SFT) method, aiming to enhance the model's ability to generate coherent logical reasoning sequences. It contains 77,685 records that cover not only Chinese but also English, making the dataset useful in multilingual environments.
Direct use:https://go.hyper.ai/KlyzY
9. QwQ-LongCoT-130K fine-tuning dataset
The QwQ-LongCoT-130K dataset is a SFT (Supervised Fine-Tuning) dataset designed for training large language models (LLMs) like O1. This dataset contains about 130k instances, each of which is a response generated using the QwQ-32B-Preview model.
Direct use:https://go.hyper.ai/kE9aG
The dataset was collated from Google Patents using the search query “machine learning and healthcare” and includes patents granted in fields ranging from medical imaging and diagnostic tools to AI-driven treatment recommendations.
Direct use:https://go.hyper.ai/8p1M5
Selected Public Tutorials
1. AlphaFold3 protein prediction demo
AlphaFold3 is an artificial intelligence (AI) tool developed by Google DeepMind in 2024. The AlphaFold 3 model uses a diffusion-based architecture that can not only predict protein structures, but also accurately predict the structures of complexes including nucleic acids, small molecules, ions, and modified residues.
This tutorial will introduce how to quickly deploy and use AlphaFold3 to predict proteins. You only need a single A6000 card to run the experience.
Run online:https://go.hyper.ai/KHIRR
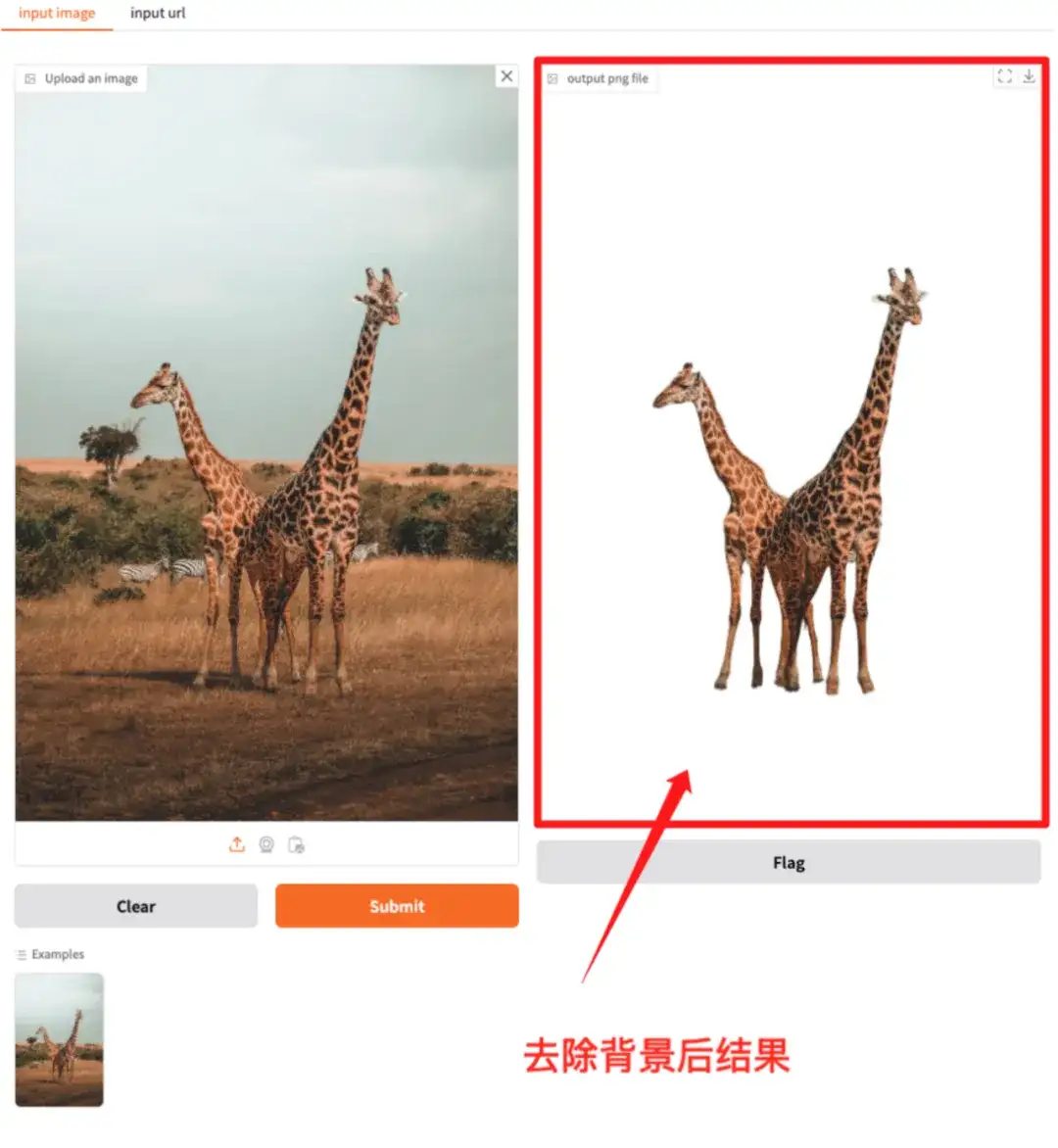
2. RMBG-2.0: Open source background removal model
RMBG-2.0 is an open source background subtraction model designed to effectively separate foreground from background across a variety of categories and image types.
The model has configured the environment and dependencies. You can enter the API address to experience one-click image cutting.
Run online:https://go.hyper.ai/FF10L
3. DePLM: Optimizing Proteins with Denoised Language Models (Small Samples)
The Denoised Protein Language Model (DePLM) can treat the evolutionary information captured by the protein language model as a mixture of relevant and irrelevant information to the optimization target properties, where irrelevant information is regarded as "noise" and eliminated, thereby improving the accuracy of the model in predicting the protein adaptive landscape and helping to identify the functionally optimal sequence for optimization.
This tutorial is about training and reasoning about the Denoised Protein Language Model (DePLM) released by Zhejiang University. The relevant results have been selected for "NeurIPS 24". The platform has configured the required environment and datasets, and you can perform training and reasoning by directly executing the commands given in the tutorial.
Run online:https://go.hyper.ai/ktd87
We have also established a Stable Diffusion tutorial exchange group. Welcome friends to scan the QR code and remark [SD tutorial] to join the group to discuss various technical issues and share application results~

Community Articles
Recently, Enveda, an AI pharmaceutical startup in the United States, announced that it has completed a $130 million Series C financing, with a total financing amount of $360 million. In addition, at the end of October this year, the first candidate drug ENV-294 discovered using the Enveda platform received IND approval from the US FDA and entered the Phase I clinical trial stage. This article is a detailed report on the company.
View the full report:https://go.hyper.ai/rMk2U
Due to the special geographical location of the Qinghai-Tibet Plateau, surface heat flow data in some rugged areas is very scarce. To solve this problem, the School of Earth Sciences of Zhejiang University proposed a geographic neural network weighted regression model with enhanced interpretability, which provides a new research framework and technical support for a comprehensive understanding of the heat flow distribution and geodynamic mechanism of the Qinghai-Tibet Plateau. This article is a detailed interpretation and sharing of the paper.
View the full report:https://go.hyper.ai/vqQDi
In the fifth live broadcast of Meet AI4S, Wang Zeyuan, a doctoral student at the Knowledge Engine Laboratory of Zhejiang University, shared an achievement selected for NeurlPS 2024 and demonstrated a demo. He also introduced his submission experience. It is full of practical information, so click to watch it quickly.
View the full report:https://go.hyper.ai/PLyBo
Google's DeepMind and Google Research have released a number of results in the field of weather forecasting, taking into account short-term, medium-term and long-term forecasts, integrating traditional methods with AI, and gradually building a "hexagonal warrior" for weather forecasting.
View the full report:https://go.hyper.ai/Cvzkc
Popular Encyclopedia Articles
1. Reciprocal sorting fusion RRF
2. Masked Language Modeling (MLM)
3. Nuclear Norm
4. Kolmogorov-Arnold Representation Theorem
5. Data Augmentation
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:

One-stop tracking of top AI academic conferences:https://go.hyper.ai/event
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!








