Command Palette
Search for a command to run...
Alphafold3 Dependent Database Has Been Packaged and Launched! ICLR Full Score Paper IC-Light: Accurately Identify Light Tone Features

AlphaFold2 has caused a sensation in the AI4S field since its release and won this year's Nobel Prize. As its upgraded version, AlphaFold3 can not only predict the structure of proteins, but also predict the structure of proteins interacting with various other biological molecules, including how ligands (small molecules) and nucleic acids (DNA and RNA) gather together and interact with each other.
Just last month, Google DeepMind open-sourced the AlphaFold3 model weights and its dependency database for academic research. HyperAl has now launched the AlphaFold3 dependency database. Everyone is welcome to experience the technological breakthroughs brought by AlphaFold3 while reading the paper!
Online use:https://go.hyper.ai/wVItz
From December 9 to December 13, hyper.ai official website updates:
* High-quality public datasets: 10
* Selection of high-quality tutorials: 3
* Community article selection: 5 articles
* Popular encyclopedia entries: 5
* Top conferences with deadlines in January: 9
Visit the official website:hyper.ai
Selected public datasets
1. Alphafold3 depends on the database
The database contains a large number of protein and RNA databases that AlphaFold 3 relies on, including 9 databases: BFD small, MGnify, PDB, PDB seqres, UniProt, UniRef90, NT, RFam and RNACentral.
Direct use:https://go.hyper.ai/wVItz
2. Mol-Instructions Large-scale Biomolecule Instruction Dataset
The dataset contains three types of instructions: molecule-oriented instructions, protein-oriented instructions, and biomolecule text instructions. It aims to provide rich instruction data to enhance the understanding and prediction capabilities of large language models in the field of biomolecules.
Direct use:https://go.hyper.ai/Gut1y
3. CoSQL Conversational Text to SQL Dataset
CoSQL contains 3k+ groups of conversations, a total of 10k+ annotated SQL queries, spanning 200 databases, and the databases used by different groups of data have no intersection, in order to examine the robustness of the model.
Direct use:https://go.hyper.ai/9Blzy

4. QAngaroo multi-step reasoning reading comprehension dataset
The dataset consists of two parts: WikiHop and MedHop, which aims to build a reading comprehension method that can perform multi-hop reasoning, that is, facts scattered in different documents require multiple steps of reasoning to derive new facts.
Direct use:https://go.hyper.ai/u1qRw

5. TCM Ancient Books Traditional Chinese Medicine Ancient Books Dataset
This dataset contains about 700 ancient Chinese medicine texts, covering medical classics from the pre-Qin period to the late Qing Dynasty and the Republic of China. These documents not only include medical theories, prescriptions, pharmacology, etc., but also contain rich clinical cases and medical encyclopedia knowledge.
Direct use:https://go.hyper.ai/8Vh6A
6. IndustryCorpus2 Healthcare Dataset Subset
This dataset is a high-quality data resource library specifically for research and application in the field of medical health. It has undergone a rigorous screening and cleaning process to ensure the accuracy and reliability of the data. It covers a wide range of data types in the field of medical health, including medical records, medical literature, and patient feedback, providing researchers and developers with a comprehensive perspective to explore and innovate.
Direct use:https://go.hyper.ai/G9qn2
7. P-MMEval Multi-language Multi-task Benchmark Dataset
The dataset contains 3 basic natural language processing (NLP) datasets and 5 advanced capability-specific datasets, covering tasks such as code generation, knowledge understanding, mathematical reasoning, logical reasoning, and instruction following.
Direct use:https://go.hyper.ai/qbzhv
8. ShenNong TCM Dataset ShenNong TCM Dataset
This dataset contains more than 110,000 instruction data, which are generated through an entity-centric self-instruction method. It focuses on the core entities and different intent scenarios in the field of traditional Chinese medicine. It can not only improve the model's ability to answer questions related to traditional Chinese medicine, but also assist in traditional Chinese medicine diagnosis and provide personalized medical advice.
Direct use:https://go.hyper.ai/Okruv
9. DS-1000 Code Generation Benchmark Dataset
The dataset contains 1k real-world data science questions from StackOverflow, covering 7 widely used data science libraries in Python, such as NumPy, Pandas, TensorFlow, etc.
Direct use:https://go.hyper.ai/AL4h0
10. IndustryCorpus2-tourism-geography Tourism geography dataset
This dataset is a subset of the tourism geography dataset of IndustryCorpus2, which covers a wide range of data types in the field of tourism geography, including attraction introductions, travel guides, tourist reviews, and geographic information, providing rich application scenarios for various research and application fields such as natural language processing, machine learning, data mining, and tourism recommendation systems.
Direct use:https://go.hyper.ai/FIAM9
Selected Public Tutorials
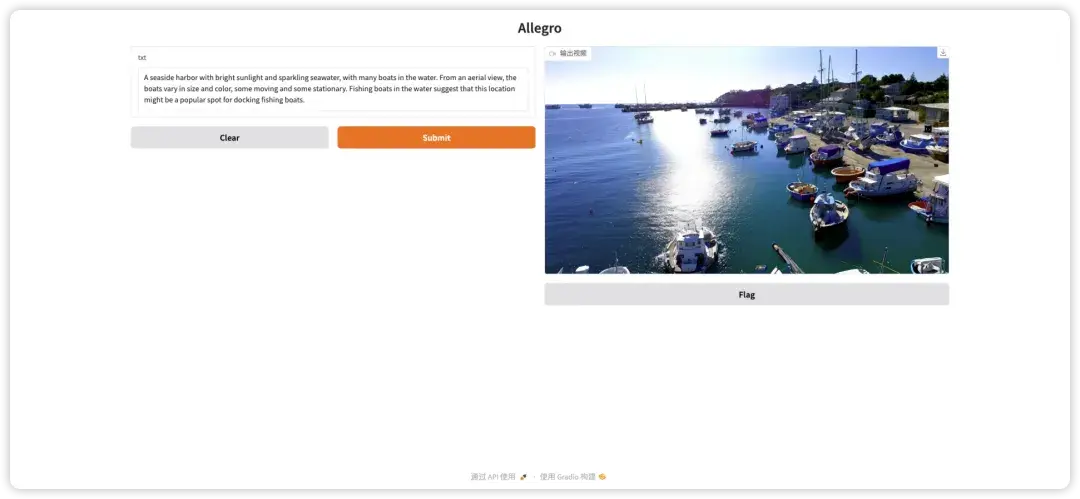
1. Allegro video generation demo
Allegro has the ability to convert basic text input into high-definition video content, with 720p resolution, 15 frames per second, and a maximum video length of 6 seconds. The model has demonstrated excellent performance in the field of video synthesis, with excellent performance in both quality and temporal coherence.
This tutorial is a model inference tutorial. Since it takes a long time for the model to generate a video, this tutorial can generate a 5-second video effect.
Run online:https://go.hyper.ai/MgUVZ
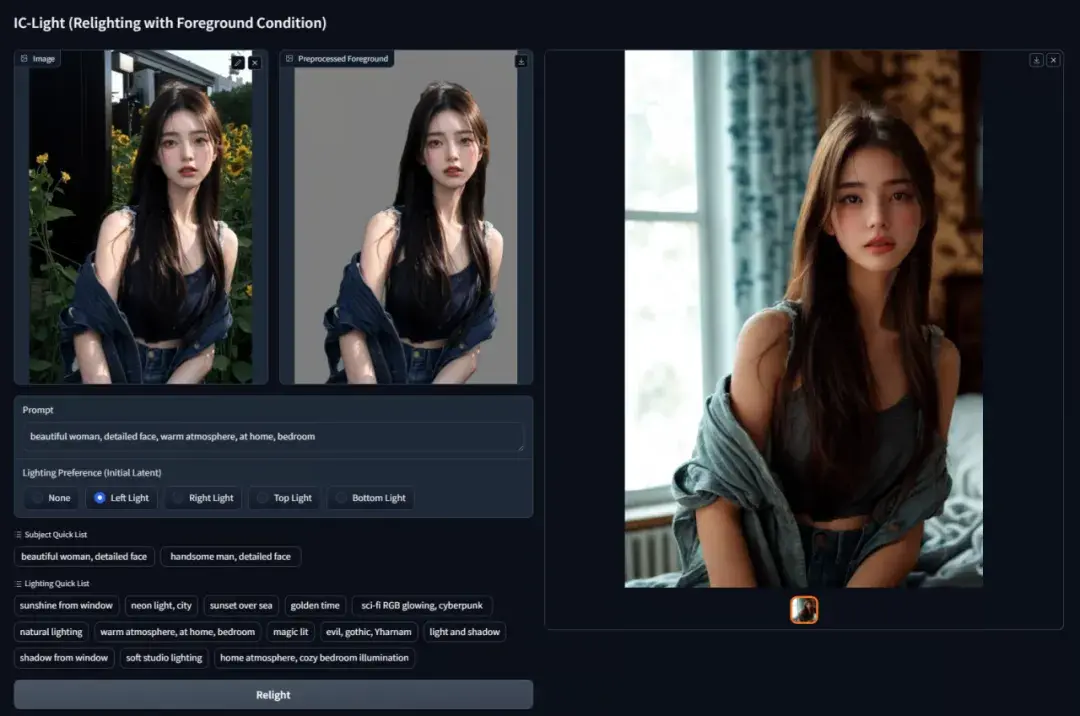
2. IC-Light v2: AI lighting control upgrade demo
IC-Light stands for Imposing Consistent Light, which aims to achieve image relighting projects through machine learning models. This tutorial is an upgraded version of IC-Light v2. Compared with the original IC-Light, this version is trained based on the Flux model, which enables it to more accurately identify the lighting and tone characteristics of the image and achieve a more detailed and realistic fusion effect.
Click the link below and follow the tutorial to control the lighting effects in your image.
Run online:https://go.hyper.ai/hg0cM
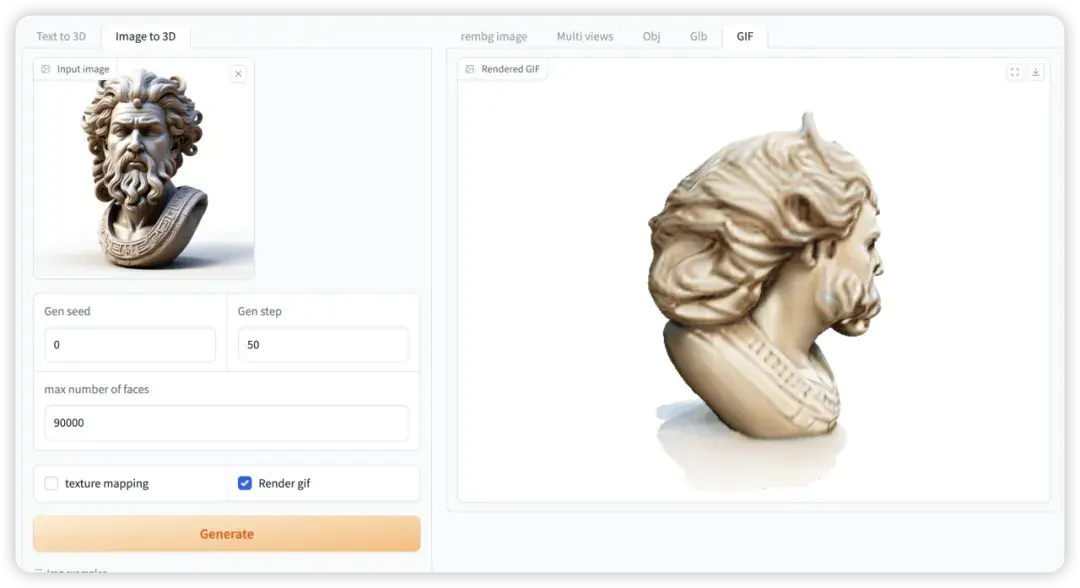
3. Hunyuan3D: Generate 3D assets in just 10 seconds
Hunyuan3D is a 3D generative diffusion model, including a lightweight version and a standard version, both of which support the generation of high-quality 3D assets from text and image inputs. After qualitative and quantitative multi-dimensional evaluation, Hunyuan3D-1.0 performs very well in terms of geometric details, texture details, texture-geometry consistency, 3D rationality, and instruction compliance.
This tutorial is a lightweight version of Hunyuan3D. Click the link below and follow the tutorial instructions to experience 3D model generation.
Run online:https://go.hyper.ai/Rsrno
Community Articles
As a startup, CuspAI's strength should not be underestimated. Its seed round financing was as high as 30 million US dollars, becoming one of the largest seed round financings in Europe that year. In addition, Max Welling, a machine learning expert, is one of the company's co-founders, and Geoffrey Hinton, a double winner of the Nobel Prize and Turing Award, is a board advisor to the company. This article is a detailed introduction to CuspAI.
View the full report:https://go.hyper.ai/3fQFG
With the widespread application of AI technology in our daily lives, the "interpretability" of models has gradually become an urgent problem to be solved. This problem is particularly prominent in time series prediction tasks. In order to make time series prediction a "visible" process, Lu Feng's team at Huazhong University of Science and Technology, in collaboration with the Zomaya team of the University of Sydney and Tongji Hospital, proposed a new method, CGS-Mask. By combining time series prediction with interpretability, this method can not only improve the model prediction accuracy, but also make the prediction results more intuitive and interpretable. This article is a detailed interpretation and sharing of the paper.
View the full report:https://go.hyper.ai/TFEsd
A research team from Stanford University and the Arc Institute in the United States proposed a genome-based model, Evo, which was published on the cover of Science. It can achieve zero-shot prediction and high-precision generation in multimodal tasks of DNA, RNA, and protein. The HyperAI Super Neural Tutorial section is now online, "Evo: Prediction and Generation from Molecular to Genome Scale", which can be quickly experienced by cloning with one click!
View the full report:https://go.hyper.ai/5WPGm
AI godfather Hinton was born into a family of geniuses, but he is a repeat dropout; his startup had only three people, but was acquired by Google for $44 million; he spent nearly half a century developing neural networks, but he said he regretted it... What kind of life experience made him what he is today? This article is an in-depth report on Hinton.
View the full report:https://go.hyper.ai/EHWs6
vLLM is a framework designed for large language model reasoning acceleration, achieving almost zero waste of KV cache memory. The latest version v0.6.4 introduces multi-step scheduling and asynchronous output processing, further optimizing GPU utilization and improving processing efficiency. In order to help domestic developers more easily learn about vLLM version updates and cutting-edge developments, the HyperAI Super Neural Community has completed the localization of vLLM Chinese documentation.
View vLLM Chinese documentation:https://vllm.hyper.ai/
Popular Encyclopedia Articles
1. Mel-frequency Cepstrum MFCCs
2. Reciprocal sorting fusion RRF
3. Masked Language Modeling (MLM)
4. Pareto Front
5. Data Augmentation
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:

One-stop tracking of top AI academic conferences:https://go.hyper.ai/event
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!
See you next week!








