Command Palette
Search for a command to run...
SynthID Invisible Watermark Is Available First! It Makes AI-generated Content More Controllable; a large-scale Audio Subtitle Dataset Is Now Online, Containing 6 Million Audio Files

In an era where AI-generated content is becoming increasingly popular, how to quickly distinguish whether content is manually created or AI-generated has become a hot topic. This not only involves news authenticity and copyright protection, but is also closely related to network security.
Recently, Google DeepMind launched SynthID-Text technology, which can embed watermarks losslessly without affecting the quality of text by optimizing the token probability score in the text generation process, and has extremely high detection efficiency. Compared with traditional technologies, it achieves higher classification accuracy at a lower latency cost, providing an innovative solution for AI content supervision.
The hyper.ai official website has now launched a tutorial on how to use SynthID-Text. You can clone and start it with one click to add digital watermarks to AI generation:
One-click start link:
From November 18th to November 22nd, hyper.ai official website updated quickly:
* High-quality public datasets: 10
* Selection of high-quality tutorials: 3
* Community article selection: 4 articles
* Popular encyclopedia entries: 5
* Top conferences with deadlines from November to December: 3
Visit the official website: hyper.ai
Selected public datasets
1. MORE Multimodal Object-Entity Relation Extraction Dataset
The dataset contains 21 different relation types and covers more than 20,000 multimodal relation facts, which are annotated on 3,559 pairs of text captions and corresponding images.
Direct use:https://go.hyper.ai/LlfTx

2. Guava Fruit Disease Guava Fruit Disease Dataset
The dataset contains 473 labeled guava fruit images, which have been subjected to preprocessing steps such as unsharp masking and CLAHE (contrast limited adaptive histogram equalization), increasing the number of images to 3,784. Each image has been preprocessed into a consistent RGB format of 512×512 pixels.
Direct use:https://go.hyper.ai/RRLEd

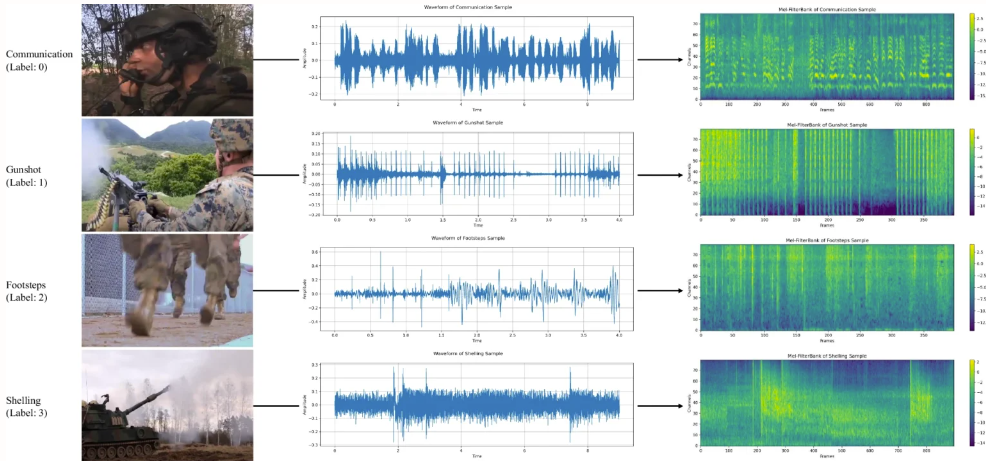
3. MAD Military Audio Dataset
The MAD dataset is designed to support the training and evaluation of audio classification systems, especially in audio classification tasks related to military activities, such as gunfire, artillery fire, or explosions. The dataset is extracted from multiple military videos and contains 8,075 sound samples divided into 7 categories, totaling about 12 hours of audio.
Direct use:https://go.hyper.ai/kxqH3
4. MMPR Multimodal Reasoning Preference Dataset
The MMPR dataset contains 750,000 samples without clear correct answers and 2.5 million samples with clear correct answers. The samples cover multiple fields such as VQA, science, diagrams, mathematics, OCR, and documents to ensure diversity. The dataset aims to improve the performance of models in multimodal reasoning tasks while avoiding potential negative effects during training.
Direct use:https://go.hyper.ai/bbHH0

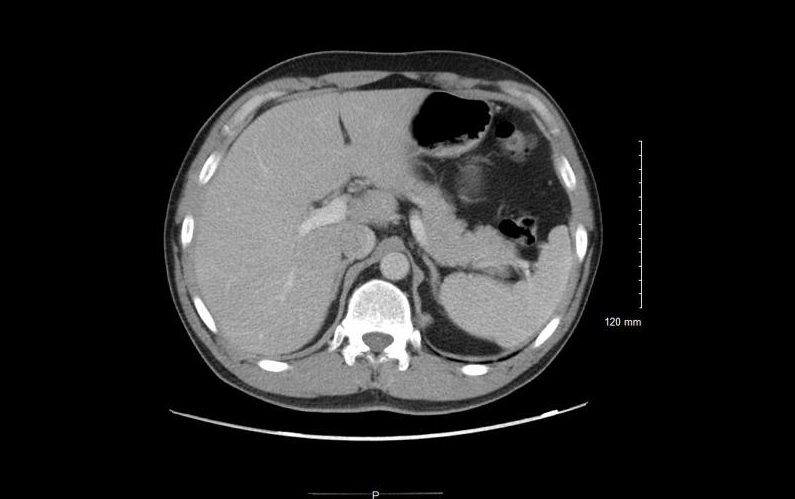
5.ROCOv2 radiology multimodal medical image dataset
The ROCOv2 dataset combines radiological images with related medical concepts and descriptions, and contains more than 70,000 radiological images, covering a variety of clinical patterns, anatomical regions, and directions (for X-rays), and each image has a corresponding medical concept description.
Direct use:https://go.hyper.ai/XgqCa
6. PDFM Geographic Index Dataset
The PDFM Geographic Index Dataset is real data used to evaluate Population Dynamics Based Embeddings. It contains rich summary information of human behavior captured from maps, search trend summaries, and environmental factors such as weather and air quality.
Direct use:https://go.hyper.ai/jpzY1
7. Mantis-Instruct Multi-image Instruction Tuning Dataset
This dataset is a text-image interleaved multimodal dataset focused on multi-image instruction tuning, consisting of 14 subsets containing 721K examples for training the Mantis model family. The dataset covers a variety of multi-image skills, including coreference, reasoning, comparison, and temporal understanding.
Direct use:https://go.hyper.ai/dOtuR
8. MASSW Scientific Workflow Dataset
The MASSW dataset contains more than 152k peer-reviewed publications from 17 top computer science conferences, covering the past 50 years. The dataset defines five key aspects of the scientific workflow: context, key ideas, methods, results, and expected impact. These aspects are used to extract and structure information from each publication to generate a structured summary.
Direct use:https://go.hyper.ai/2pUy8
9. AudioSetCaps Audio subtitle dataset
The AudioSetCaps audio caption dataset contains more than 6.11 million 10-second audio files. Each audio file is accompanied by a descriptive title and 3 Q&A pairs as metadata for generating the final caption.
Direct use:https://go.hyper.ai/3QCQP
10. Traditional Chinese Medicine Dataset SFT Traditional Chinese Medicine Diagnosis Dataset
The dataset contains about 1GB of high-quality content such as clinical cases in various fields of traditional Chinese medicine, famous books, medical encyclopedias, and glossaries. The dataset is mainly composed of internal data from non-network sources. 99% is in simplified Chinese with excellent quality and considerable information density, which is suitable for pre-training or continued pre-training purposes.
Direct use:https://go.hyper.ai/zb7Uf
Selected Public Tutorials
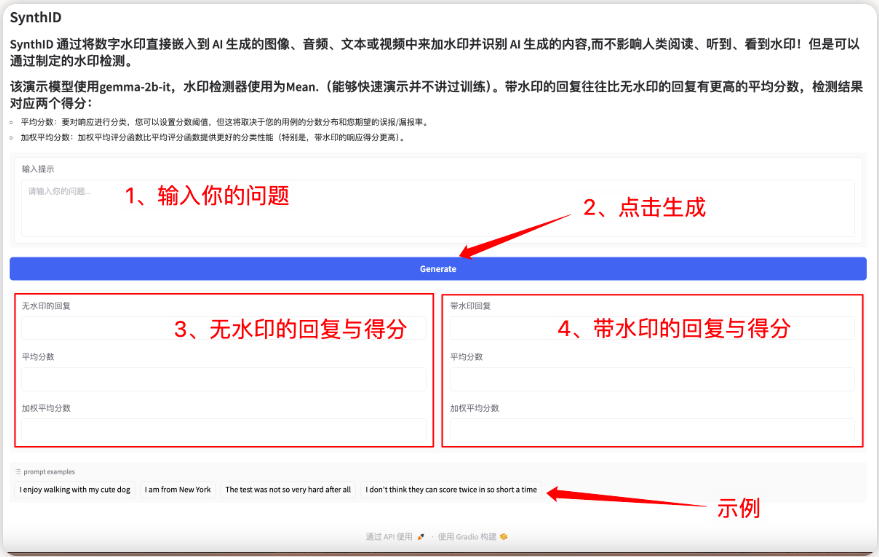
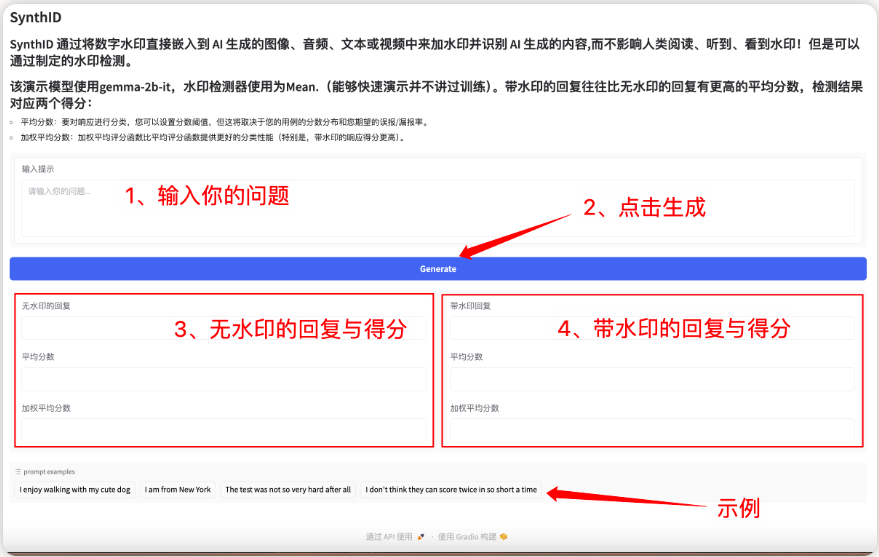
1. SynthID-Text AI text watermark generation tool
The model is a watermark technology for identifying and verifying text generated by a large language model (LLM). It can maintain text quality and achieve high detection accuracy while minimizing latency costs. Its core is to embed an almost imperceptible watermark by slightly adjusting the token probability score in the generation process without compromising text quality and user experience, thereby achieving high detection accuracy.
This project can generate a front-end interactive interface through the Gradio interface. The relevant models and dependencies have been deployed, and watermark text can be generated by starting with one click.
Run online:https://go.hyper.ai/lQ1UK
2. Evo: sequence prediction and generation from molecular to genome scale
Evo is a biologically grounded model that generalizes across the fundamental languages of biology: DNA, RNA, and proteins. The model is capable of performing predictive tasks and generative design, covering sequence prediction and generation at scales from molecules to entire genomes.
Click the link below and follow the tutorial to predict genome-scale sequences.
Run online:https://go.hyper.ai/LgFWm
3. VASP Tutorial: 1-1. DFT Calculation of Isolated Oxygen Atoms
VASP is a software package for electronic structure calculations and quantum mechanics-molecular dynamics simulations. It is one of the most popular commercial software for material simulation and computational material science research. Its high accuracy and powerful functions make it an important tool for researchers to predict and design material properties. It is widely used in solid physics, materials science, chemistry, molecular dynamics and other fields.
This tutorial is the first part of the VASP official tutorial: DFT calculation of isolated oxygen atoms. Click the link below and follow the tutorial instructions to start DFT high-performance calculations from scratch.
Run online:https://go.hyper.ai/pa2NX
💡We have also established a Stable Diffusion tutorial exchange group. Welcome friends to scan the QR code and remark [SD tutorial] to join the group to discuss various technical issues and share application results~

Community Articles
Molecular inverse folding plays a key role in drug and material design, but past research has rarely focused on the inverse folding of universal molecules. In response to this, the team of the Future Industry Research Center of Westlake University proposed a unified model UniIF for the inverse folding of all molecules. Experimental results show that UniIF has achieved state-of-the-art performance in multiple tasks such as protein design, RNA design, and material design. This article is a detailed interpretation and sharing of the paper.
View the full report:https://go.hyper.ai/efhze
In the interdisciplinary application of AI technology, how to combine discrete and continuous variables to improve the quality of crystal material generation has become a core problem in the field of crystal material generation. In response to this, Meta FAIR Laboratory released the material generation model FlowLLM. This model improves the efficiency of generating stable materials by more than 300% compared with previous models, and the efficiency of generating SUN materials is also improved by about 50%. This article is a detailed interpretation and sharing of the paper.
View the full report:https://go.hyper.ai/KJzjz
Recently, Shanghai Jiao Tong University and Shanghai Artificial Intelligence Laboratory have successfully developed a pre-trained protein language model with structure perception capabilities - ProSST. The model is pre-trained on a large dataset containing 18.8 million protein structures, and can effectively integrate protein structure and amino acid sequence information, significantly surpassing existing models in supervised learning tasks. This article is a detailed interpretation and sharing of the paper.
View the full report:https://go.hyper.ai/qi5ei
The GMAI-MMBench benchmark was proposed by Shanghai Artificial Intelligence Laboratory and other scientific research institutions. It covers 284 downstream task datasets worldwide, including 38 medical imaging modalities, 18 clinical-related tasks, 18 departments, and 4 perceptual granularities in visual question-answering format. It is the most comprehensive general medical benchmark to date. In addition, this article also summarizes other medical field datasets for you, including one-click use connections.
View the full report:https://go.hyper.ai/csr2M
Popular Encyclopedia Articles
1. Sigmoid function
2. Nuclear Norm
3. Artificial Neural Networks
4. Data Augmentation
5. Quantum Neural Network
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:
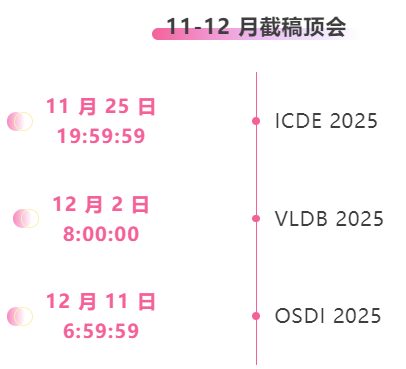
One-stop tracking of top AI academic conferences:https://go.hyper.ai/event
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!
See you next week!
About HyperAI
HyperAI (hyper.ai) is the leading artificial intelligence and high-performance computing community in China.We are committed to becoming the infrastructure in the field of data science in China and providing rich and high-quality public resources for domestic developers. So far, we have:
* Provide domestic accelerated download nodes for 1300+ public data sets
* Includes 400+ classic and popular online tutorials
* Interpretation of 200+ AI4Science paper cases
* Support 500+ related terms search
* Hosting the first complete Apache TVM Chinese documentation in China
Visit the official website to start your learning journey:
Finally, I recommend a "Creator Incentive Program". Interested friends can scan the QR code to participate!









