Command Palette
Search for a command to run...
Achieve multi-tone Hybrid Cloning in 3 Seconds! F5/E2 TTS Tutorial Is Online; PsyDTCorpus 5k Psychological Dialogue Dataset Is Released, Accurately Simulating the Language Style of Psychological Counselors

In the rapid development of voice cloning, AI has been able to simulate increasingly realistic vocal effects, but there are still many challenges in zero-sample learning and multi-emotion control.
Earlier this year, E2 TTS implemented a simplified text-to-speech generation method that only required padding the text input to the same length as the input speech with padding markers, and then denoising to generate speech. Recently, F5 TTS has adopted this method and further improved the performance of the model based on the non-autoregressive generation method of stream matching, making it not only support multi-language synthesis, but also adjust the emotion and speech speed according to the text content, making the speech synthesis of long text more delicate and smooth.
In order to facilitate everyone to experience the sound generation effects of F5 TTS and E2 TTS,The hyper.ai official website has launched the F5/E2 TTS integration tutorial, which can be cloned with one click~
Run online:https://go.hyper.ai/SZxqv
From November 4th to November 8th, hyper.ai official website updates:
* High-quality public datasets: 10
* Selection of high-quality tutorials: 3
* Community article selection: 4 articles
* Popular encyclopedia entries: 5
* Top conferences with deadline in November: 6
Visit the official website: hyper.ai
Selected public datasets
1. Hair Type Dataset Hair Type Dataset
Hair Type Dataset is an image dataset for classifying various hairstyles. It contains high-quality images of 4 hairstyles: Straight, Wavy, Curly, and Dreadlocks, with a total of 1,992 images. This dataset helps train machine learning models to identify and classify hair types.
Direct use:https://go.hyper.ai/aXYcj

2. AllClear Public Cloud Removal Dataset
The AllClear dataset is currently the largest public cloud removal dataset, containing 23,742 globally distributed regions of interest (ROIs), covering diverse land use patterns, and a total of 4 million images. It addresses the problem of lack of benchmarks and diverse training data in cloud removal research.
Direct use:https://go.hyper.ai/e2BYC

3. Muharaf Handwritten Arabic Dataset
The Muharaf dataset is a machine learning dataset focused on handwritten Arabic recognition. This dataset contains more than 1.6k images of historical handwritten pages transcribed by Arabic experts. Each document image is accompanied by the spatial polygon coordinates of its text lines and information about basic page elements.
Direct use:https://go.hyper.ai/NN2UR
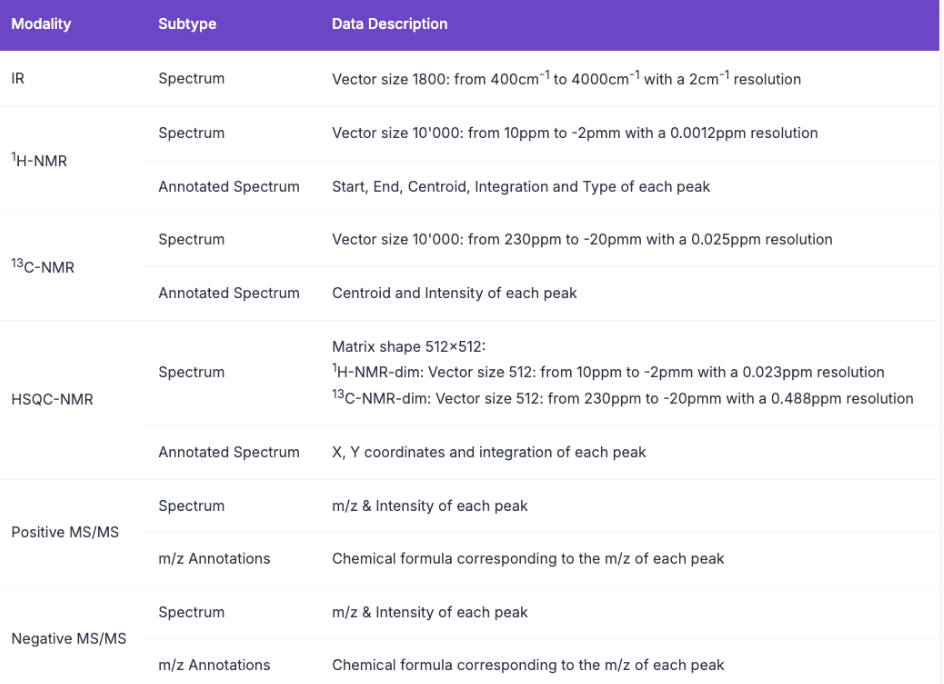
4. Multimodal Spectroscopic Chemical Multimodal Spectroscopic Dataset
The dataset contains simulated 1H-NMR, 13C-NMR, HSQC-NMR, infrared and mass spectrometry (positive and negative ion modes) spectral data of 790,000 molecules extracted from chemical reactions in patent data. It can integrate information from multiple spectral modalities and simulate the method of human experts to analyze molecular structure, which is expected to automate structural analysis and simplify the molecular discovery process from synthesis to structure determination.
Direct use:https://go.hyper.ai/Z7zlr
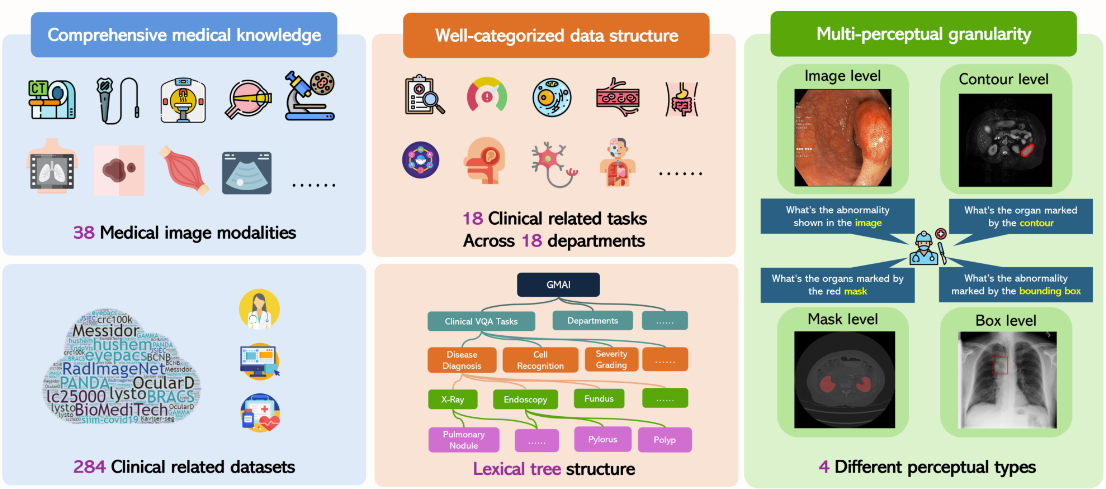
5. GMAI-MMBench Medical Multimodal Evaluation Benchmark Dataset
GMAI-MMBench is a multimodal evaluation benchmark designed to promote the development of general medical artificial intelligence. It contains 284 datasets from different sources, involving 38 medical image modalities and 18 clinically relevant tasks, covering 18 different medical departments, and is evaluated at 4 different perceptual granularities, thereby considering the performance of LVLMs from multiple dimensions.
Direct use:https://go.hyper.ai/FL799
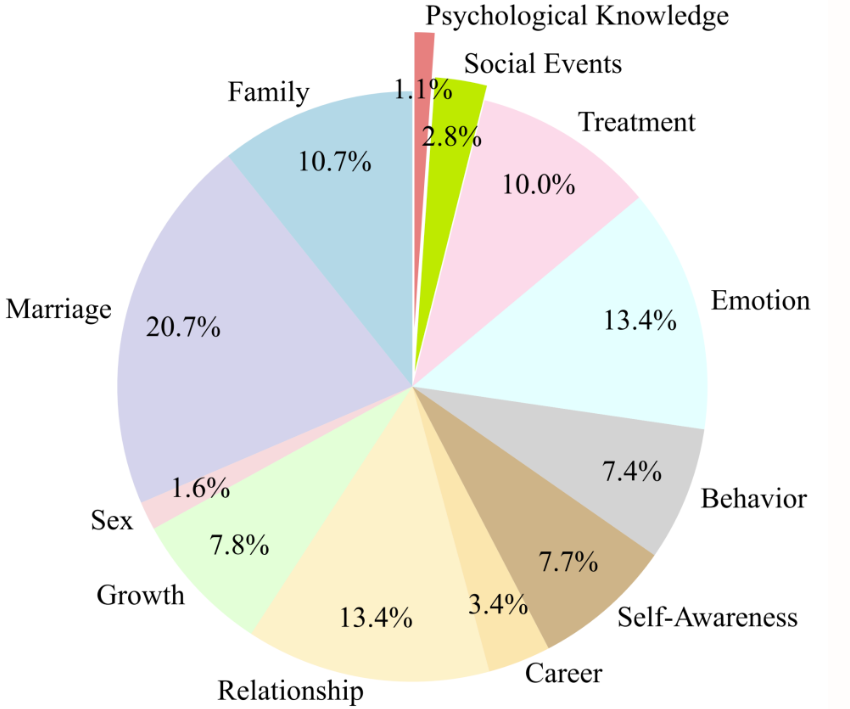
6. PsyDTCorpus Psychological Counselor Digital Twin Dataset
The core goal of the PsyDTCorpus dataset is to simulate the language style and counseling techniques of a specific counselor to support the development and training of the counselor digital twin model SoulChat2.0. The dataset contains 5k high-quality mental health conversation data with the counselor's language style and therapy technology application methods.
Direct use:https://go.hyper.ai/hGi4O
7. GTSinger singing audio dataset
This dataset is a large open source high-quality singing dataset, containing 80.59 hours of singing recorded in professional studios. These songs are sung by 20 professional singers and cover 9 different languages, including Chinese, English, Japanese, Korean, etc., providing researchers with a resource library with extremely rich timbres and styles.
Direct use:https://go.hyper.ai/wBcBz
8. OC22 Catalyst Simulation Dataset
This dataset is a catalyst simulation dataset, namely the Open Catalyst 2022 (OC22) Dataset. This dataset expands and supplements the OC20 dataset, contains more complex catalyst structures and new reaction types, and provides richer data for training and testing AI models.
Direct use:https://go.hyper.ai/M8Cpn
9. OQMD Open Source Quantum Materials Dataset
The OQMD dataset contains the thermodynamic and structural properties of more than 1.22 million materials calculated by density functional theory (DFT). The data in the dataset comes from the Inorganic Crystal Structure Database (ICSD), including DFT total energy calculations of nearly 300,000 compounds and modifications of common crystal structures.
Direct use:https://go.hyper.ai/dGOKs
10. Materials Project Online Materials Database
The data in the Materials Project database includes crystal structure and energy properties, as well as detailed information such as electronic structure and thermodynamic properties. This dataset aims to use high-throughput first-principles calculations to provide comprehensive performance data, structural information, and computational simulation results for more than one million inorganic materials, thereby accelerating the discovery and innovation of new materials.
Direct use:https://go.hyper.ai/tGIVs
For more public datasets, please visit:
Selected Public Tutorials
1. AnyText multilingual visual text generation and editing
AnyText is a multilingual visual text generation and editing model. It can support text generation in multiple languages such as Chinese, English, Japanese, and Korean, and also supports editing the text content in the input image. The text generation technology involved in this model provides possibilities for new AIGC applications such as e-commerce posters, logo design, creative graffiti, and emoticons.
Click the link below, follow the tutorial steps to clone and start the container, and then you can use your creativity to design images.
Run online:https://go.hyper.ai/uMcNa
2. F5/E2 TTS clones any sound in just 3 seconds
This tutorial includes demos of the F5 TTS and E2 TTS models. F5 TTS can quickly generate natural, fluent, and faithful speech to the original text through zero-shot learning without additional supervision. E2 TTS can generate the entire speech sequence at once, significantly improving the generation speed and maintaining high-quality speech output.
This project can generate a front-end interactive interface through the Gradio interface. The relevant models and dependencies have been deployed. You can experience sound cloning by starting it with one click.
Run online:https://go.hyper.ai/SZxqv
3. Stable-Diffusion-3.5-Large Image Generation Demo
The Stable Diffusion 3.5 Large model is a Multimodal Diffusion Generator (MMDiT) text-to-image model featuring significant improvements in image quality, typography, complex prompt understanding, and resource efficiency. Its massive size of 8 billion parameters provides professional-level image generation capabilities, particularly suited for high-resolution image generation needs.
This tutorial has deployed the environment, and you can directly generate high-resolution images according to the tutorial instructions.
Run online:https://go.hyper.ai/w5k5V

💡We have also established a Stable Diffusion tutorial exchange group. Welcome friends to scan the QR code and remark [SD tutorial] to join the group to discuss various technical issues and share application results~

Community Articles
1. Meta releases open source OMat24 dataset, including 110 million DFT calculation results
Recently, Meta released the Open Materials 2024 large-scale open source dataset and a set of supporting pre-trained models. Among them, the OMat24 dataset contains more than 110 million density functional theory calculations focusing on structural and compositional diversity. The dataset is now available on the HyperAI official website. This article is a detailed interpretation and sharing of the research paper.
View the full report:https://go.hyper.ai/3wP7R
During COSCon'24, HyperAI, as a co-production community, held an open source AI forum in the direction of AI for Science. Experts and scholars from Shanghai Jiaotong University, Zhejiang University, Tsinghua University, and OpenBayes shared their views in depth from multiple aspects, including medical artificial intelligence, geographic information artificial intelligence, scientific research intelligent computing cloud platform, and AI-driven urban complex systems. This article is a review of the highlights of the forum. Click here for detailed reports.
View event recap:https://go.hyper.ai/s2RQU
AI pharmaceutical company Terray Therapeutics has completed a $120 million Series B financing round led by Nvidia's venture capital arm NVentures and new investor Bedford Ridge Capital. This is also Nvidia's second investment in Terray. The company has also built the world's largest chemical data set and combined AI with wet experiments to form a closed loop on the data side. Click here for a detailed explanation.
View the full report:https://go.hyper.ai/AWojF
In the fourth episode of the "Meet AI4S" live series, Lan Kunyao, a Ph.D. from the Cross-Media Language Intelligence Laboratory of Shanghai Jiao Tong University, gave a speech titled "Mental Health Diagnosis and Consultation Platform Based on Large Model Agents". He introduced in detail the usage steps, technical highlights, and future plans of the psychological clinic. This article is a transcript of the highlights of the speech, including a demo of the intelligent psychological clinic. Click to watch it quickly.
View the full report:https://go.hyper.ai/CHhKC
Popular Encyclopedia Articles
1. Transformer Model
2. Variational Autoencoder VAE
3. Artificial Neural Networks
4. Pareto Front
5. Large-scale Multi-task Language Understanding (MMLU)
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:

One-stop tracking of top AI academic conferences:https://go.hyper.ai/event
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!
See you next week!
About HyperAI
HyperAI (hyper.ai) is the leading artificial intelligence and high-performance computing community in China.We are committed to becoming the infrastructure in the field of data science in China and providing rich and high-quality public resources for domestic developers. So far, we have:
* Provide domestic accelerated download nodes for 1300+ public data sets
* Includes 400+ classic and popular online tutorials
* Interpretation of 100+ AI4Science paper cases
* Support 500+ related terms search
* Hosting the first complete Apache TVM Chinese documentation in China
Visit the official website to start your learning journey:
Finally, I recommend a "Creator Incentive Program". Interested friends can scan the QR code to participate!









