Command Palette
Search for a command to run...
10k-star Open Source Data Processing Tool Starts With One Click! Supports 176 Languages Recognition; the First high-rise Falling Object Detection Dataset Is Online, Including Nearly 2k Videos in 18 Scenes

In the field of artificial intelligence, multimodal data processing has always been a difficult problem. Faced with complex PDFs, web pages, and e-books in multiple formats, it is not easy to effectively extract key information.
The Shanghai Artificial Intelligence Laboratory and OpenDataLab team launched an open source intelligent data extraction tool - MinerU, which can convert multimodal PDF documents containing elements such as images, formulas, tables, etc. into easy-to-analyze Markdown format. It also supports extracting content from web pages and e-books, solving the need to automatically extract high-quality data from complex documents.
The hyper.ai official website has launched the "MinerU one-stop data extraction tool Demo".Scroll down to get the link~
From August 26 to August 30, hyper.ai official website updates:
* Selection of high-quality tutorials: 3
* High-quality public datasets: 10
* Community article selection: 3 articles
* Popular encyclopedia entries: 5
* Top conferences with deadline in September: 7
Visit the official website:hyper.ai
Selected Public Tutorials
1. MinerU one-stop data extraction tool
MinerU is a tool that converts PDF to machine-readable formats (such as markdown, json), which can be easily extracted to any format, supports accurate recognition of 176 languages, and performs precise language type identification. The model and environment have been deployed, and you can use the large model for inference generation according to the tutorial instructions.
Direct use:https://go.hyper.ai/MIitP
2. One-click deployment of LongWriter-glm4-9b
LongWriter is an open source project developed by Tsinghua University that uses a long-context large language model (LLM) to generate very long text (more than 10,000 words). This tutorial is a one-click deployment demo of the model. You only need to clone and start the container and directly copy the generated API address to experience the model inference.
Direct use:https://go.hyper.ai/Xvktt
Using traditional digital human training programs to generate a high-quality digital human often requires a lot of time and computing resources, and also has high requirements for training materials. The emergence of MuseV and MuseTalk has brought new breakthroughs in the field of digital humans. After using MuseV to generate a digital human video, MuseTalk is used to synchronize lip shape and audio, and a complete digital human can be produced in just a few minutes. All of them have been uploaded to the public tutorial module of hyper.ai, and can be cloned and run online with one click!
MuseV Tutorial:https://go.hyper.ai/9fExW
MuseTalk Tutorials:https://go.hyper.ai/wiw8g
Selected public datasets
1. FADE Falling Object Detection Dataset around Buildings
The FADE dataset contains 1,881 videos covering 18 scenes, 8 different categories of falling objects, 4 different weather conditions, and 4 video resolutions. The diversity and professionalism of the FADE dataset make it a valuable resource for studying fallen object detection around buildings.
Direct use:https://go.hyper.ai/8u8Sr
2. ChiPBench Al chip layout algorithm dataset
ChiPBench is a comprehensive benchmark specifically designed to evaluate the effectiveness of existing AI-based chip layout algorithms in improving the final design PPA metric. The research team collected 20 circuits from different fields (such as CPU, GPU, and microcontroller). These designs can evaluate the impact of layout algorithms on the final design PPA.
Direct use:https://go.hyper.ai/LN4Ab
The dataset contains approximately 9.6k face images, of which 5k are real face images and 4.63k are AI-generated face images.
Direct use:https://go.hyper.ai/N5nVT
4. TableBench Table Question Answering Benchmark Dataset
The dataset contains 886 samples from 18 domains and is designed to facilitate fact-checking, numerical reasoning, data analysis, and visualization tasks.
Direct use:https://go.hyper.ai/Qcs2F
5. Deepfake Detection Video Recognition Dataset
The dataset contains more than 363 original clips, with 28 actors performing in 16 different scenes. These high-quality videos provide a solid foundation for training models on real content. In addition to the original data, the dataset also contains more than 3k processed videos generated using the DeepFakes method.
Direct use:https://go.hyper.ai/Jw59B
6. Vehicle Classification Vehicle Image Classification Dataset
This dataset is designed for the task of vehicle classification and contains 5.6k images divided into 7 categories. Each category represents a different type of vehicle (auto rickshaw, bicycle, car, motorcycle, airplane, ship, train), and all images are in JPEG format with the extension .jpg. It is very suitable for building and testing image classification models to distinguish different types of vehicles.
Direct use:https://go.hyper.ai/e9LNg
7. Detection On Tracks Human Behavior Detection Dataset on Tracks
The dataset contains 3,766 images of humans on railway tracks at a resolution of 1,080 × 1,080. Each image is annotated with a bounding box marking the presence of humans and their behavior on the railway tracks.
Direct use:https://go.hyper.ai/dsr49
8. Ref-AVS Audio-Visual Scene Segmentation Dataset
The Ref-AVS dataset is a benchmark for object segmentation tasks in audio-visual scenes. The dataset contains 48 videos of audible objects, specifically classified into: 20 musical instruments, 8 animals, 15 machines, and 5 humans.
Direct use:https://go.hyper.ai/pGHwm
9. COSMOS 1050K Medical Image Segmentation Dataset
The dataset includes 53 public medical datasets compiled by the research team, covering 18 modalities, 84 objects, 1050K 2D images and 6033 masks.
Direct use:https://go.hyper.ai/nHETv
10. HUST-OBC Oracle dataset contains 140,000 images, helping the team win the ACL Best Paper Award
This dataset is a high-quality HUST-OBC dataset proposed by Wang Pengjie and others from the research team of Professor Bai Xiang of Huazhong University of Science and Technology. It is collected from 3 different sources, including books, websites, and existing datasets. The dataset contains two types of oracle bone sample images. One is the oracle bone image obtained from the processed scans of the original oracle bone rubbings, and the other is the handwritten oracle bone image based on the original oracle bone, which is further subdivided into images based on rubbings and handwritten images based on glyphs.
Direct use:https://go.hyper.ai/46AiA
For more public datasets, please visit:
Community Articles
The Oxford University team developed a medical image segmentation model called Medical SAM 2. The model is based on the SAM 2 framework and treats medical images as videos. It not only performs well in 3D medical image segmentation tasks, but also unlocks a new single-prompt segmentation capability. This article is a detailed interpretation and sharing of the research paper.
View the full report:https://go.hyper.ai/04VFX
In the second episode of the "Meet AI4S" live broadcast series, Li Yuzhe, a postdoctoral fellow in Zhang Qiangfeng's laboratory at the School of Life Sciences at Tsinghua University, shared the team's latest research results under the title "Exploring AI Applications in Genomics: Taking the Spatial Transcriptome Data Characterization Algorithm SPACE as an Example". This article is a transcript of his speech, which is full of practical information.
View the full report:https://go.hyper.ai/eRQeT
In the AI for Bioengineering Summer School, Professor Hong Liang of Shanghai Jiao Tong University shared his views on the application of AI in scientific research, especially in protein design, and his outlook on the future development of AI for Science under the theme of "AI Entering Life and Science". This article is a transcript of the highlights of Professor Hong Liang's speech.
View the full report:https://go.hyper.ai/TWBIk
Popular Encyclopedia Articles
1. DALL-E
2. Intersection over Union (IoU)
3. Masked Language Modeling (MLM)
4. Neural Radiance Field (NeRF)
5. Reciprocal sorting fusion RRF
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:
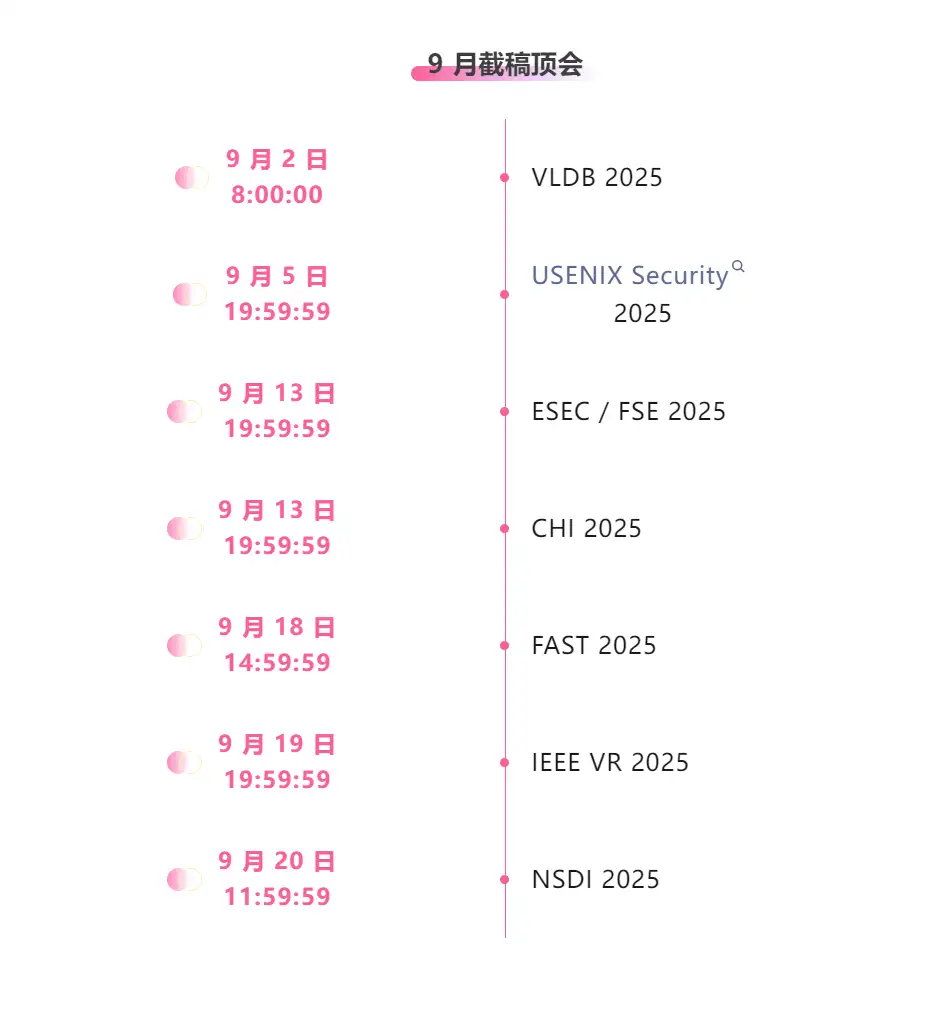
One-stop tracking of top AI academic conferences:https://go.hyper.ai/event
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!
See you next week!
About HyperAI
HyperAI (hyper.ai) is the leading artificial intelligence and high-performance computing community in China.We are committed to becoming the infrastructure in the field of data science in China and providing rich and high-quality public resources for domestic developers. So far, we have:
* Provide domestic accelerated download nodes for 1300+ public data sets
* Includes 400+ classic and popular online tutorials
* Interpretation of 100+ AI4Science paper cases
* Support 500+ related terms search
* Hosting the first complete Apache TVM Chinese documentation in China
Visit the official website to start your learning journey:








