Command Palette
Search for a command to run...
Exclusive Chinese Subtitles! LeCun Student Alfredo's Spring AI Course Begins; CVPR'24 Remote Sensing Dataset Download

Recently, Alfredo Canziani, assistant professor of computer science at New York University and a student of Yann LeCun, released his spring "AI course", which covers topics such as discrete probability and naive Bayes, perceptrons and logistic regression, optimization, statistics and neural natural language processing, neural network classification, recurrent neural networks and convolutional neural networks.
This week, HyperAI will broadcast the course live on B Station 24/7. Let's learn together~
Watch link:
http://live.bilibili.com/26483094
From June 24 to June 28, hyper.ai official website updates:
- High-quality public datasets: 10
- High-quality tutorial selection: 3
- Community Article Selection: 4 articles
- Popular encyclopedia entries: 5
- Top conferences with deadlines in July: 4
Visit the official website:hyper.ai
Selected public datasets
1. GeoChat Instruct Remote Sensing Multimodal Instruction Tracking Dataset
The dataset contains nearly 318,000 instructions and aims to extend multimodal instruction adaptation to the remote sensing domain to train multi-task conversational assistants. The related paper results have been accepted by CVPR 2024.
Direct use:https://go.hyper.ai/CXu0K
2. RRSIS-D Large Remote Sensing Image Segmentation Dataset
The dataset contains 17,402 image-description-mask triplets covering a variety of spatial resolutions and object orientations. The related paper results have been accepted by CVPR 2024.
Direct use:https://go.hyper.ai/1VRQG
3. Earth Parser Dataset Remote Sensing Mapping Dataset
This dataset is for training and evaluating parsing methods on large, uncurated aerial LiDAR scans. The dataset contains 7 scenes covering an area of more than 7.7 square kilometers and a total of 98 million 3D points. The related paper results have been accepted by CVPR 2024.
Direct use:https://go.hyper.ai/3pFjm
4. Harvard-GF3300 Retinal Neurological Disease (Glaucoma) Dataset
This dataset is a retinal neurological disease (glaucoma) dataset including 3,300 subjects, containing 2D and 3D image data. The dataset contains an equal number of subjects from 3 major racial groups (white, black, and Asian), which avoids data imbalance issues that may confuse fair learning issues.
Direct use:https://go.hyper.ai/vIhu6
5. Dental X-ray Images for Analysis Dental X-ray Image Dataset
This dataset contains a variety of dental orthodontic tomography (OPG) X-ray images, 70 high-quality samples. By providing annotations, this dataset can be used to train and test machine learning models for dental image analysis tasks such as tooth type classification and anomaly detection.
Direct use:https://go.hyper.ai/vK9zz
6. Multi-region fracture X-ray dataset
The dataset contains fractured and non-fractured X-ray images covering all anatomical body regions including lower limbs, upper limbs, lumbar spine, hip, knee, etc. The dataset is divided into training, testing, and validation folders, with a total of 10,580 radiological images (X-ray) data.
Direct use:https://go.hyper.ai/Yk1bA
7. Fruit and Vegetable Image Recognition Dataset
The dataset contains images of 10 kinds of fruits and 26 kinds of vegetables, and each category is divided into training, testing, and validation sets, providing a diverse set for image recognition tasks.
Direct use:https://go.hyper.ai/FdfRK
The dataset contains information about 15,939 popular characters from various media types and genres. Each entry contains detailed information about the character, the media source, and unique scenes involving the character.
Direct use:https://go.hyper.ai/wf1q1
9. RepLiQA is a possible question answering dataset for benchmarking
RepLiQA is an evaluation dataset containing "context-question-answer" triplets covering 17 topics or document categories, designed to test the ability of large language models (LLMs) to find and use contextual information in provided documents.
Direct use:https://go.hyper.ai/ZkSYD
10. CS-Eval Large Model Network Security Evaluation Dataset
The dataset covers 11 major areas of network security, 42 sub-areas, and 4,369 multiple-choice questions, true-or-false questions, and knowledge extraction questions. It provides comprehensive evaluation tasks based on knowledge and practice, supports user self-evaluation, and provides reference and inspiration for the implementation of large-scale models in network security.
Direct use:https://go.hyper.ai/ziacf
For more public datasets, please visit:
Selected Public Tutorials
1. Bioclip biological classification hierarchical prediction demo
This tutorial demo can classify a given biological image by family, genus, species, etc. It is the Gradio version of the model in the best student paper "BioCLIP: A Vision Foundation Model for the Tree of Life" of CVPR2024.
Run online:https://go.hyper.ai/OEWk1
2. InstantStyle - a consistent image generator
InstantStyle is a text-to-image generation framework developed by the InstantX team of Xiaohongshu, which achieves style transfer while maintaining the text controllability of the content. This tutorial has built the relevant environment for you, and you can experience it with one click!
Run online:https://go.hyper.ai/E6GuW
3. Generate high-quality articles in 5 seconds, Llama 3-Chinese-Chat Demo starts with one click!
This model is a Chinese chat model fine-tuned specifically for Chinese based on the Meta-Llama-3-8b-Instruct model. Compared with the original Meta-Llama-3-8b-Instruct model, it significantly reduces the problems of "Chinese questions with English replies" and mixed Chinese and English. Simply clone and start the container, and directly copy the generated API address to experience the model inference.
Run online:https://go.hyper.ai/BLHcM
Community Articles
Scientists from the UK and Japan used machine learning technology to design a research system that combines researcher-driven and data-driven methods, and successfully created the world's strongest known iron-based superconducting magnet. This article is a detailed interpretation and sharing of the research.
View event details:https://go.hyper.ai/RxV9x
At the Beijing Zhiyuan Conference, Professor Li Jianping, Vice President of Peking University First Hospital and Director of the Institute of Cardiovascular Medicine, shared AI's new exploration and practice in the diagnosis of coronary heart disease and the prediction of clinical myocardial ischemia under the title of "Methods and Difficulties of Clinical Myocardial Ischemia Prediction". This provides a new idea for the diagnosis and treatment of patients with coronary heart disease, and expands the focus from the heart to the kidneys, which is expected to make AI more valuable in clinical medicine. This article is a detailed summary of the speech.
Read the full interview:https://go.hyper.ai/5X9jM
The Tsinghua University research team proposed a large cell model called sc-Foundation, which is trained based on the gene expression data of 50 million cells, has 100 million parameters, and can process about 20,000 genes at the same time. As a basic model, it has shown excellent performance improvement in a variety of biomedical downstream tasks such as cell sequencing depth enhancement, cell drug response prediction, and cell perturbation prediction. This article is a detailed interpretation and sharing of the research.
View the full report:https://go.hyper.ai/v5i5K
Recently, Professor Zhou Hao from the Institute of Intelligent Industry of Tsinghua University, as a computer practitioner, shared with everyone the multiple challenges that AI people encounter in protein design, and described the latest cutting-edge research in the field of protein from three aspects: data structure, generation algorithm, and protein pre-training. This article reports on Professor Zhou Hao's in-depth sharing.
View the full report:https://go.hyper.ai/PTyAp
Popular Encyclopedia Articles
1. Scaling Theorem Scaling Law
2. Reciprocal ranking fusion RRF
3. Neural Radiance Field (NeRF)
4. Large-scale Multi-task Language Understanding (MMLU)
5. Kolmogorov-Arnold Representation Theorem
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:
Station B live broadcast preview
AIfredo Canziani is an assistant professor of computer science at New York University and a student of Yann LeCun. Recently, he released his spring "AI course" video. The knowledge points taught in each chapter include: discrete probability and naive Bayes; perceptron and logistic regression; optimization, statistics and neural natural language processing; neural network classification, etc. This week, Super Neural TV will broadcast the course 24/7.
The following table is a preview of the content selected by the editor↓↓↓
| date | time | content |
|---|---|---|
| Monday, July 1 | 18:00 | Part 1: Introduction to Naive Bayes |
| Tuesday, July 2 | 18:00 | Part 2 Naive Bayes Classification |
| Wednesday, July 3 | 18:00 | Part 3 Naive Bayes Parameter Estimation and Laplace Smoothing |
| Thursday, July 4 | 18:00 | Part 4. Evaluation of Binary Classifiers |
| Friday, July 5 | 18:00 | Part 5 Multiclass Perceptrons Binary and Multiclass Logistic Regression |
| Saturday, July 6 | 18:00 | Part 6 Optimization and Gradient Ascent |
| Sunday, July 7 | 18:00 | Alfredo Canziani's talk on Energy-Based Self-Supervised Learning |
Super Neuro TV broadcasts live 24/7. Click to get the "electronic pickles" in the AI field:
http://live.bilibili.com/26483094
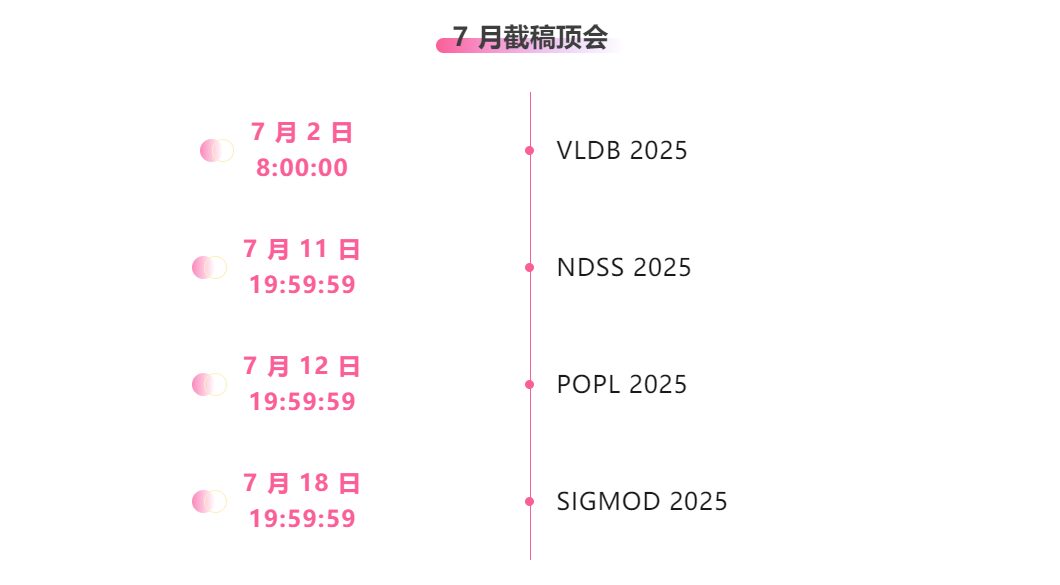
One-stop tracking of top AI academic conferences:https://hyper.ai/events
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!
See you next week!
About HyperAI
HyperAI (hyper.ai) is the leading artificial intelligence and high-performance computing community in China. We are committed to becoming the infrastructure in the field of data science in China and providing rich and high-quality public resources for domestic developers. So far, we have:
- Provide domestic accelerated download nodes for 1300+ public data sets
- Contains 400+ classic and popular online tutorials
- Interpreting 100+ AI4Science paper cases
- Support 500+ related terms search
- Hosting the first complete Apache TVM Chinese documentation in China
Visit the official website to start your learning journey:








