Command Palette
Search for a command to run...
2024 Meet AI Compiler Beijing Offline Gathering Is Scheduled! InfinityInstruct, a Dataset of Tens of Millions of Instructions for Fine-tuning, Is Open Source

High-quality instruction data is an indispensable resource for training and optimizing large language models, and is the cornerstone for improving model performance. Recently, the Beijing Zhiyuan Artificial Intelligence Research Institute released the InfinityInstruct open source project, which contains tens of millions of high-quality instruction fine-tuning datasets, including high-quality data screened based on open source datasets and high-quality instruction data constructed through data synthesis methods.
The first batch of 3 million high-quality Chinese and English instruction datasets InfInstruct-3M, which have been verified by models, were open-sourced at this conference.It is now available on the hyper.ai official website. You can use this dataset and fine-tune the basic model with your own application data to quickly build a high-quality, exclusive Chinese-English bilingual dialogue model.
From June 10th to June 14th, hyper.ai official website updates:
* High-quality public datasets: 10
* Selected high-quality tutorials: 2
* Community article selection: 4 articles
* Popular encyclopedia entries: 5
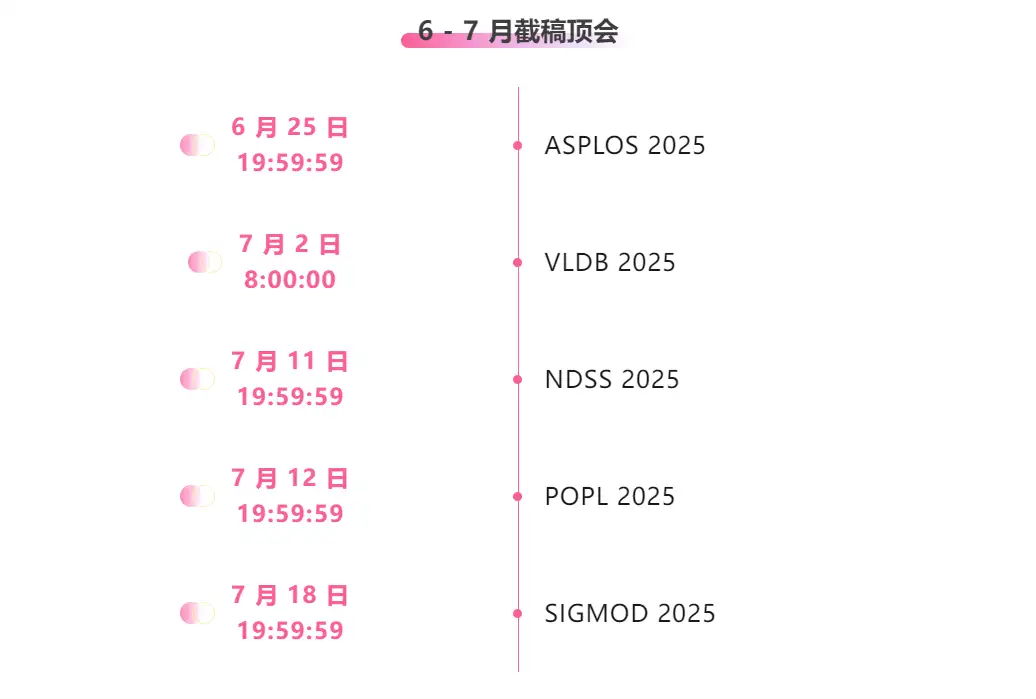
* Top conferences with deadlines in June and July: 5
Visit the official website:hyper.ai
Selected public datasets
1. InfInstruct-3M launches a dataset of 10 million instructions for fine-tuning
This dataset was launched by the Beijing Zhiyuan Artificial Intelligence Research Institute. The goal of the project is to develop a dataset containing millions of instructions to support the instruction tracking capabilities of large language models and thus improve model performance. This version is the InfinityInstruct-3M instruction dataset, and the final version is expected to be released at the end of June.
Direct use:https://go.hyper.ai/iG7gN
2. LooGLE Long Context Understanding Benchmark Dataset
This dataset is a benchmark dataset designed to evaluate and improve the ability of artificial intelligence systems in long-context understanding. The related achievement paper has been accepted by ACL2024.
Direct use:https://go.hyper.ai/S6dSZ
3. InternVid-Full High-quality Large-scale Video-Text Dataset
The dataset contains more than 7 million videos with detailed text descriptions, covering 16 scenes and about 6,000 action descriptions, with a total duration of nearly 760,000 hours. The related paper received Spotlight at the 2024 International Conference on Representation Learning (ICLR 2024).
Direct use:https://go.hyper.ai/AnaLl
4. LoveDA Remote Sensing Land Cover Dataset for Domain Adaptive Semantic Segmentation
This dataset is a land cover dataset for remote sensing, specially designed for domain adaptive semantic segmentation, containing 5,987 high-resolution images and 166,768 annotated semantic objects.
Direct use:https://go.hyper.ai/ShKyN
5. CityGen urban building image dataset
This dataset is an image dataset focusing on urban buildings. It usually contains a large number of urban building images. These images can be used to train and evaluate computer vision models, especially in tasks such as building detection, semantic segmentation, and instance segmentation. The relevant results have been included in CVPR 2024.
Direct use:https://go.hyper.ai/ddNqv
6. Waste Classification Recyclables and domestic waste classification dataset
The dataset contains 15,000 images (256×256 pixels each) covering various recyclable materials, general waste, and household items in 30 different categories, providing a rich and diverse resource for research and development in the field of waste sorting and recycling.
Direct use:https://go.hyper.ai/kOiKG
7. BIRDS 525 SPECIES 525 bird image dataset
The dataset contains 525 bird species, 84,635 training images, 2,625 test images, and 2,625 validation images.
Direct use:https://go.hyper.ai/pfw5d
8. OpenEarthMap Global High-Resolution Land Cover Mapping Benchmark Dataset
The dataset consists of 2.2 million clips from 5,000 aerial and satellite images, covering 97 regions in 44 countries on 6 continents, with manually annotated 8 types of land cover labels and a ground sampling distance of 0.25-0.5 meters. The relevant paper results have been included in WACV 2023.
Direct use:https://go.hyper.ai/ubxmO
9. OpenMantra comic machine translation evaluation dataset
This dataset is a machine translation evaluation dataset for Japanese comics. It contains comics of five different styles (fantasy, romance, fighting, suspense, and life). The dataset contains a total of 1,593 sentences, 848 scenes, and 214 pages of comics. It was released by the Mantra team of the University of Tokyo.
Direct use:https://go.hyper.ai/ISqUR
10. DTD Texture Recognition Dataset
The dataset consists of 5,640 images, which are divided into 47 categories according to human perception, with 120 images in each category, and a list of key attributes and joint attributes is also provided for each image.
Direct use:https://go.hyper.ai/aUYi3
For more public datasets, please visit:
Selected Public Tutorials
1. Run TripoSR model Demo online
TripoSR is jointly developed by Stability AI and Tripo AI. It can generate high-quality 3D models from a single image within 1 second, and has low computing power requirements, so ordinary users can easily use it on local devices. This tutorial has set up the environment for everyone to run and experience.
Run online:https://go.hyper.ai/is9qe
2. LGM Large Multi-view Gaussian Model Generation Demo
LGM, or Large Multi-View Gaussian Model, is an innovative framework for generating high-resolution 3D models from textual prompts or single-view images. This method can generate 3D objects within 5 seconds and increase the training resolution to 512, thus achieving high-resolution 3D content generation. This tutorial is a demo implementation of LGM.
Run online:https://go.hyper.ai/pFnhg
We have also established a Stable Diffusion tutorial exchange group. Welcome friends to scan the QR code and remark [SD tutorial] to join the group to discuss various technical issues and share application results~
Community Articles
1. Event Preview | 2024 Meet AI Compiler Beijing premiere scheduled for July 6!
The first Meet AI Compiler Beijing will be held on July 6, 2024 in the lecture hall on the first floor of the Institute of Computing Technology, Chinese Academy of Sciences! We are fortunate to have invited many senior AI compiler experts from Shanghai Jiao Tong University, the Institute of Computing Technology, Chinese Academy of Sciences, Microsoft Research Asia, etc. They will bring you wonderful keynote speeches and roundtable discussions, and discuss with you the application and breakthroughs of AI compiler technology in landing scenarios.Click "Read original text" to sign up and participate!
View full event information:https://go.hyper.ai/EA1uw
Last week, Apple released Apple Intelligence and introduced major updates to iOS 18 and Siri. The previously rumored collaboration between Apple and OpenAI was finally officially announced. Siri, which integrates ChatGPT, has become more natural, more contextual, and more personalized, and can simplify and speed up daily tasks. This article introduces the updates to Apple Intelligence, Siri, and iOS 18, and also sorts out the development history of Siri, which can further demonstrate the importance of the upgrade of Apple's AI capabilities to Siri.
View the full report:https://go.hyper.ai/kWmHC
A team jointly formed by the School of Computer Science and Software of Shenzhen University and the Intelligent Health Research Center of Hong Kong Polytechnic University proposed a novel echocardiogram video segmentation model MemSAM. The model achieved state-of-the-art performance with a small number of point prompts and achieved comparable performance to fully supervised methods with limited annotations, greatly reducing the prompt and annotation requirements required for video segmentation tasks. This article is a detailed interpretation and sharing of the research.
View the full report:https://go.hyper.ai/2s73Q
Dr. Jianmin Wang and others from Yonsei University combined deep learning with generative AI, using Transformer-based generative neural networks to learn and explore the conformational set of protein-protein complexes, and learn the key residues that affect the conformation and dynamic mechanism of protein-protein complexes from multiple molecular dynamics trajectories, providing mechanistic insights into protein-protein binding. This article is a detailed interpretation and sharing of the research.
View the full report:https://go.hyper.ai/MdgoV
Popular Encyclopedia Articles
1. Reciprocal ranking fusion RRF
2. Masked Language Modeling (MLM)
3. Learning Rate
4. YOLOv10 Real-time End-to-End Object Detection
5. Kolmogorov-Arnold Representation Theorem
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:
Station B live broadcast preview
Jeff Dean is a senior researcher and computer scientist at Google, known for his pioneering work in distributed systems and artificial intelligence, including the development of MapReduce and TensorFlow. He is one of the key figures in Google's technological development. This week, Super Neural TV will broadcast Jeff Dean's speeches and interviews.
The following table is a preview of the content selected by the editor↓↓↓
| date | time | content |
| Monday, June 17 | 18:00 | Jeff Dean on the five trends in machine learning |
| Tuesday, June 18 | 18:00 | Let AI serve everyone |
| Wednesday, June 19 | 18:00 | Jeff Dean's positive outlook on the future of AI |
| Thursday, June 20 | 18:00 | Jeff Dean's speech at the Stanford Medical Big Data Conference |
| Friday, June 21 | 18:00 | Jeff Dean's talk on deep learning |
| Saturday, June 22 | 18:00 | Google Brain & Brain Residency |
| Sunday, June 23 | 18:00 | Jeff Dean discusses how to use deep learning to solve problems |
Super Neuro TV broadcasts live 24/7. Click to get the "electronic pickles" in the AI field:
http://live.bilibili.com/26483094
One-stop tracking of top AI academic conferences:https://hyper.ai/events
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!
See you next week!
About HyperAI
HyperAI (hyper.ai) is the leading artificial intelligence and high-performance computing community in China.We are committed to becoming the infrastructure in the field of data science in China and providing rich and high-quality public resources for domestic developers. So far, we have:
* Provide domestic accelerated download nodes for 1300+ public data sets
* Includes 400+ classic and popular online tutorials
* Interpretation of 100+ AI4Science paper cases
* Support 500+ related terms search
* Hosting the first complete Apache TVM Chinese documentation in China
Visit the official website to start your learning journey:








