Command Palette
Search for a command to run...
One-click Deployment of LLaMA 3 Chinese Chat, Including Chinese Training Dataset; Food2K Dataset Download, Including 2,000 Categories and 1 Million Images

The recent open source release of Llama 3 made everyone in the AI community excited, but its support for pure Chinese is not very good, and it cannot flexibly switch to the corresponding language to answer questions in Chinese.
This week, hyper.ai launched the deployment and reasoning tutorial of Llama 3 Chinese Chat, the Chinese version of Llama 3.It effectively solves the awkwardness of "answering Chinese questions in English" and makes the conversation more natural and smooth.The tutorial has deployed the model and environment. You only need to open the API address to experience the inference!
Can't wait, I'm gonna try it:
The same Chinese training data set:
From May 27 to May 31, hyper.ai official website updates:
* High-quality public datasets: 10
* Selected high-quality tutorials: 2
* Community article selection: 4 articles
* Popular encyclopedia entries: 5
* Top conferences with deadline in June: 4
Visit the official website:hyper.ai
Selected public datasets
1. Llama 3 Chinese version dataset
This dataset is a collection of Llama 3 Chinese datasets. The data has been uniformly processed into the firefly format, and can be used with the firefly tool to directly train the Llama 3 Chinese model.
Direct use:https://go.hyper.ai/uJlfk
2. LCCC Large Clean Chinese Conversational Corpus
The dataset mainly consists of two parts: LCCC-base (6.8 million conversations) and LCCC-large (12 million conversations). The research team designed a strict data filtering process to ensure the quality of the conversation data in the dataset. The filtered dataset can promote the research of short text conversation modeling.
Direct use:https://go.hyper.ai/bDzEG
3. Food2K Large Food Recognition Dataset
Food2K is a large-scale food recognition dataset containing 2,000 food categories and over 1 million images.
Direct use: https://go.hyper.ai/TpfUJ
4. COYO-700M Image-Text Pair Dataset
COYO-700M contains 747 million image-text pairs and many other meta-attributes, collecting many informative alternative texts and their associated image pairs in HTML documents.
Direct use: https://go.hyper.ai/fWI1i
5. GLH-Bridge Large-scale Remote Sensing Image Bridge Target Detection Dataset
The dataset contains 6,000 large-format ultra-high-resolution remote sensing images, with nearly 60,000 bridge instances across different backgrounds manually annotated. The image format is 2048×2048-16384×16384 pixels, and has two sets of target detection labels: rotation box and horizontal box.
Direct use: https://go.hyper.ai/cHPeb
6. MMDialog Multimodal Open Domain Multi-turn Dialogue Dataset
The dataset is a large-scale multimodal open-domain dialogue dataset, containing 1.08 million complete dialogue sessions, more than 4,000 dialogue topics, and 1.53 million non-repeated images, with an average of 2.59 images per dialogue session.
Direct use: https://go.hyper.ai/iAbI2
7. Pima Indian Diabetes Dataset
The dataset originally came from the National Institute of Diabetes and Digestive and Kidney Diseases, and its purpose was to diagnostically predict whether a patient had diabetes based on certain diagnostic measurements included in the dataset.
Direct use: https://go.hyper.ai/XqJXe
8. LamaH-CE Large Sample Dataset of Central European Hydrology and Environmental Sciences
LamaH-CE contains runoff and meteorological time series for 859 measured catchments along with various (catchment) attributes. The hydrometeorological time series have daily and hourly temporal resolution and include quality markers. All meteorological and most runoff time series span more than 35 years.
Direct use:https://go.hyper.ai/UPZvA
9. CAMELS-GB UK catchment properties and hydrometeorological time series dataset
This dataset provides hydrometeorological time series and landscape attributes for 671 catchments in the UK. It collates river flows, catchment attributes and catchment boundaries from the UK National River Flow Archive together with a new set of meteorological time series and catchment attributes.
Direct use:https://go.hyper.ai/KA29l
10. HQ-Edit Instruction-based Image Editing Dataset
HQ-Edit contains about 200,000 editing examples, each with an input image, an output image, and detailed editing instructions.
Direct use:https://go.hyper.ai/xjahh
For more public datasets, please visit:
Selected Public Tutorials
1. One-click deployment of Llama 3-Chinese-Chat-8b Demo
The model used in this tutorial is the first Chinese version of Llama 3, which is a language model with fine-tuned instructions for Chinese and English users, with multiple capabilities such as role-playing and tool use. Simply clone and start the container, and directly copy the generated API address to experience the model inference.
Run online:https://go.hyper.ai/i3r7D
Latte is an innovative model for video generation that was open sourced in November 2023. As the world's first open source video DiT, Latte has achieved promising results. This tutorial is a demo of the Latte project's effect implementation.
Run online: https://go.hyper.ai/LFfmt
Station B live broadcast preview
Apple will hold WWDC 2024 from June 10th to 14th. In order to help everyone gain in-depth information about Apple, the Super Neurological B Station Live Room will continue to broadcast "Apple Special" videos, covering: WWDC conferences over the years, executive interviews, related documentaries and other rich content.At that time, Chao Shenjing will also broadcast it live on Video Account and Bilibili, so make an appointment now and don’t miss it~

The following table is a preview of next week’s live broadcast content selected by the editor↓↓↓
| date | time | content |
| June 1 Monday | 18:00 | Steve Jobs |
| Tuesday, June 2 | 18:00 | What makes an Apple an Apple |
| Wednesday, June 3 | 18:00 | Interview with Steve Jobs vs Bill Gates |
| Thursday, June 4 | 18:00 | iPhone first release |
| Friday, June 5 | 18:00 | History of Steve Jobs |
| Saturday, June 6 | 18:00 | How Apple survived nearly bankruptcy |
| Sunday, June 7 | 18:00 | Tim Cook's History |
Super Neuro TV broadcasts live 24/7. Click to get the "electronic pickles" in the AI field:
http://live.bilibili.com/26483094
Community Articles
Last week, the China Meteorological Administration released the "Artificial Intelligence Meteorological Large Model Training Special Data Catalog" for the first time, which brings together a large amount of meteorological data. The catalog is now available for download on the official website of the Meteorological Administration. In addition, in order to help everyone understand and use relevant data resources, HyperAI Super Neural Network also compiled 10 high-quality meteorological disaster data sets this week to better promote the progress of related research and open a new chapter in meteorological research.
Get detailed information:https://go.hyper.ai/kK87m
Ouyang Chaojun's team from the Chengdu Institute of Mountain Hazards and Environment, Chinese Academy of Sciences, proposed an AI-based runoff and flood prediction model ED-DLSTM. By encoding the static properties of the basin and meteorological drivers, the model was trained using data from more than 2,000 hydrological stations around the world, attempting to solve the runoff prediction problem in basins with and without monitoring data worldwide. This article is a detailed interpretation and sharing of the research.
View the full report:https://go.hyper.ai/eG6H5
3. Brain-computer interface: a plug-in for modern medicine, and a gamble for paralyzed patients
Tsinghua University, Zhejiang University, Stanford University, Brown University, Johns Hopkins University and other domestic and foreign universities have conducted relevant research on brain-computer interfaces. This article starts with the concept, introduces the three main forms of brain-computer interfaces, specific research cases of famous domestic and foreign universities, and the ethics and safety of brain-computer interfaces.
View the full report:https://go.hyper.ai/W3pPf
The team led by Ge Jian, a researcher at the Shanghai Astronomical Observatory of the Chinese Academy of Sciences, used deep learning methods to search for neutral carbon absorption lines in the data released by the Sloan Sky Survey Phase III, unveiling the mystery of the composition of cold gas clouds in early galaxies and discovering 107 examples of neutral carbon absorption lines in the early universe. This article is a detailed interpretation and sharing of the research.
View the full report:https://go.hyper.ai/qirkz
Popular Encyclopedia Articles
1. Epoch
2. Neural Radiance Field (NeRF)
3. Scaling Law
4. YOLOv10 Real-time End-to-End Object Detection
5. Kolmogorov-Arnold Networks
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:
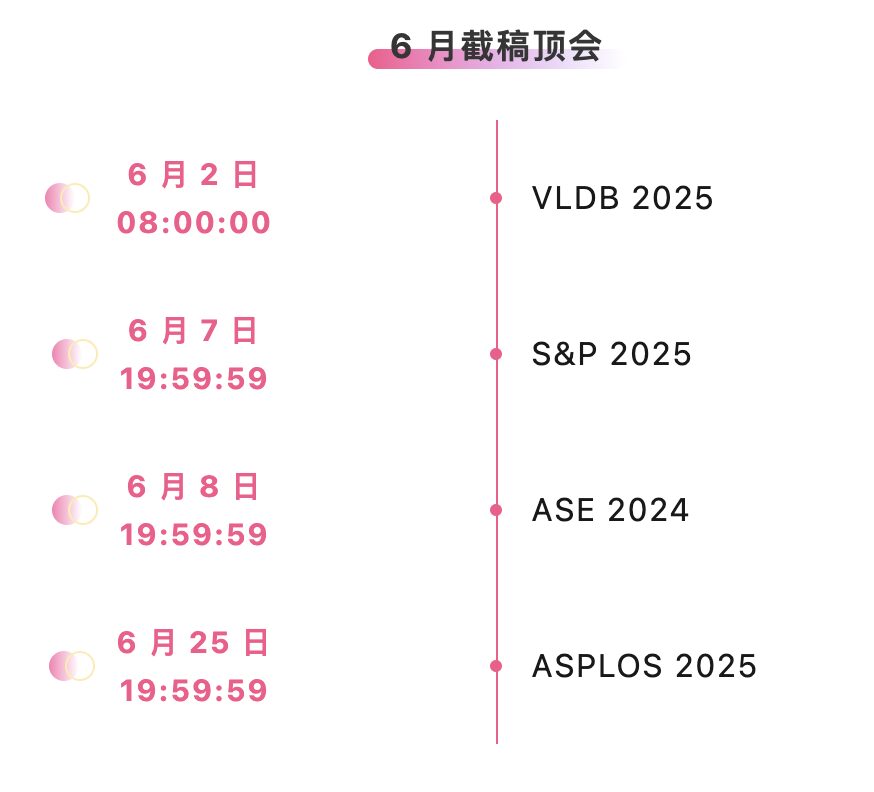
One-stop tracking of top AI academic conferences:
https://hyper.ai/events
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!
See you next week!
About HyperAI
HyperAI (hyper.ai) is the leading artificial intelligence and high-performance computing community in China.We are committed to becoming the infrastructure in the field of data science in China and providing rich and high-quality public resources for domestic developers. So far, we have:
* Provide domestic accelerated download nodes for 1200+ public data sets
* Includes 300+ classic and popular online tutorials
* Interpretation of 100+ AI4Science paper cases
* Support 500+ related terms search
* Hosting the first complete Apache TVM Chinese documentation in China
Visit the official website to start your learning journey:








