Command Palette
Search for a command to run...
Flow-GRPO-Flow-Matching-Textgraphenmodell-Demo
Datum
Größe
1.88 GB
Lizenz
MIT
GitHub
Paper-URL
1. Einführung in das Tutorial

Flow-GRPO ist ein Flow-Matching-Modell, das am 13. Mai 2025 vom Multimedia-Labor der Chinesischen Universität Hongkong, der Tsinghua-Universität und dem Team um Kuaishou Keling veröffentlicht wurde. Dieses Modell integriert auf innovative Weise ein Online-Reinforcement-Learning-Framework mit der Flow-Matching-Theorie und erzielte damit einen Durchbruch im GenEval-2025-Benchmark: Die kombinierte Generierungsgenauigkeit des SD-3.5-Medium-Modells stieg von 631 TP3T auf 951 TP3T im Benchmark, und die Metrik zur Bewertung der Generierungsqualität übertraf erstmals GPT-40. Zugehörige Forschungsarbeiten sind verfügbar. Flow-GRPO: Trainieren von Flow-Matching-Modellen über Online-RL .
Dieses Tutorial verwendet eine einzelne RTX 4090-Karte als Ressource und die Eingabeaufforderungen zur Bildgenerierung unterstützen nur Englisch.
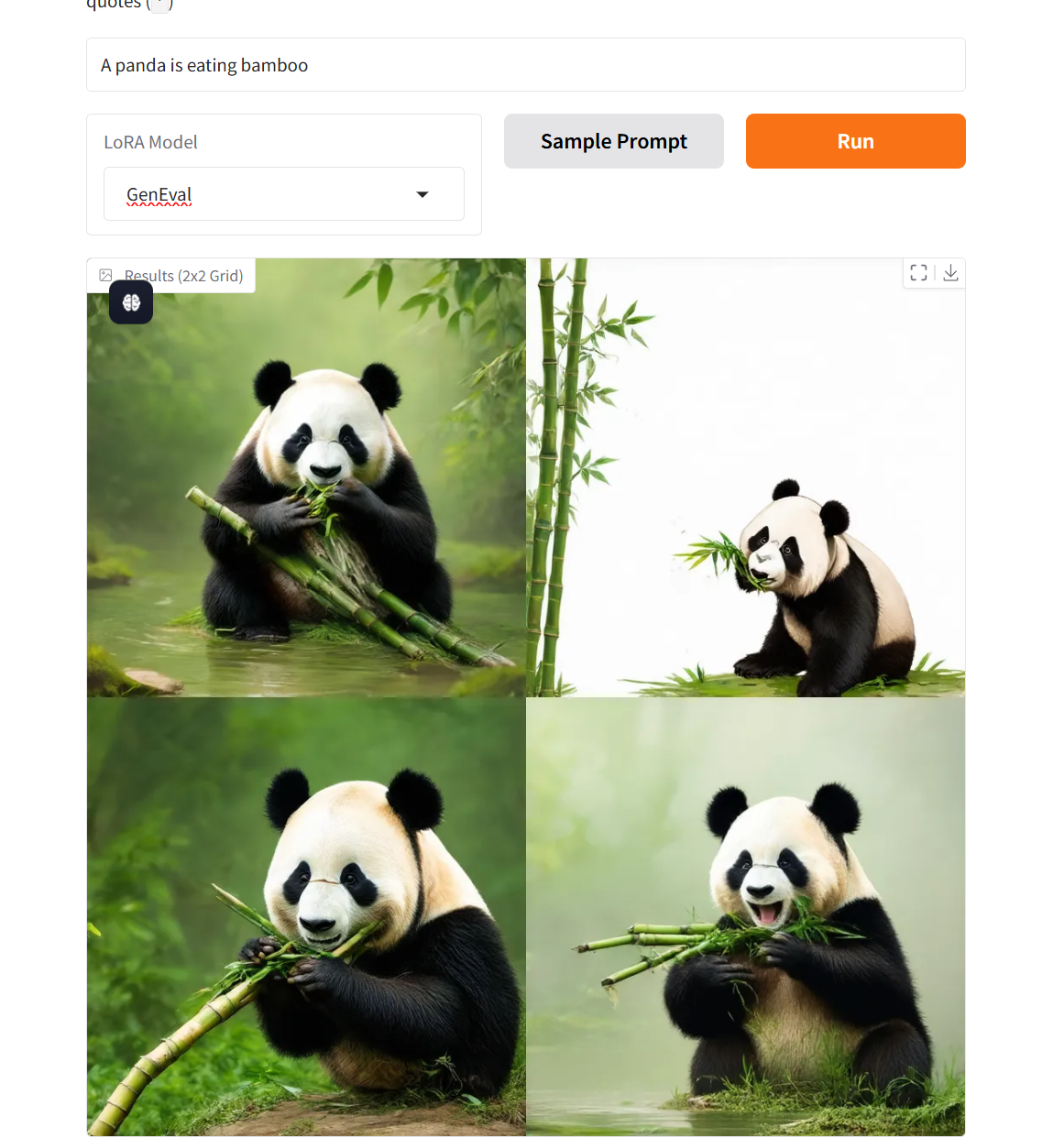
2. Projektbeispiele
3. Bedienungsschritte
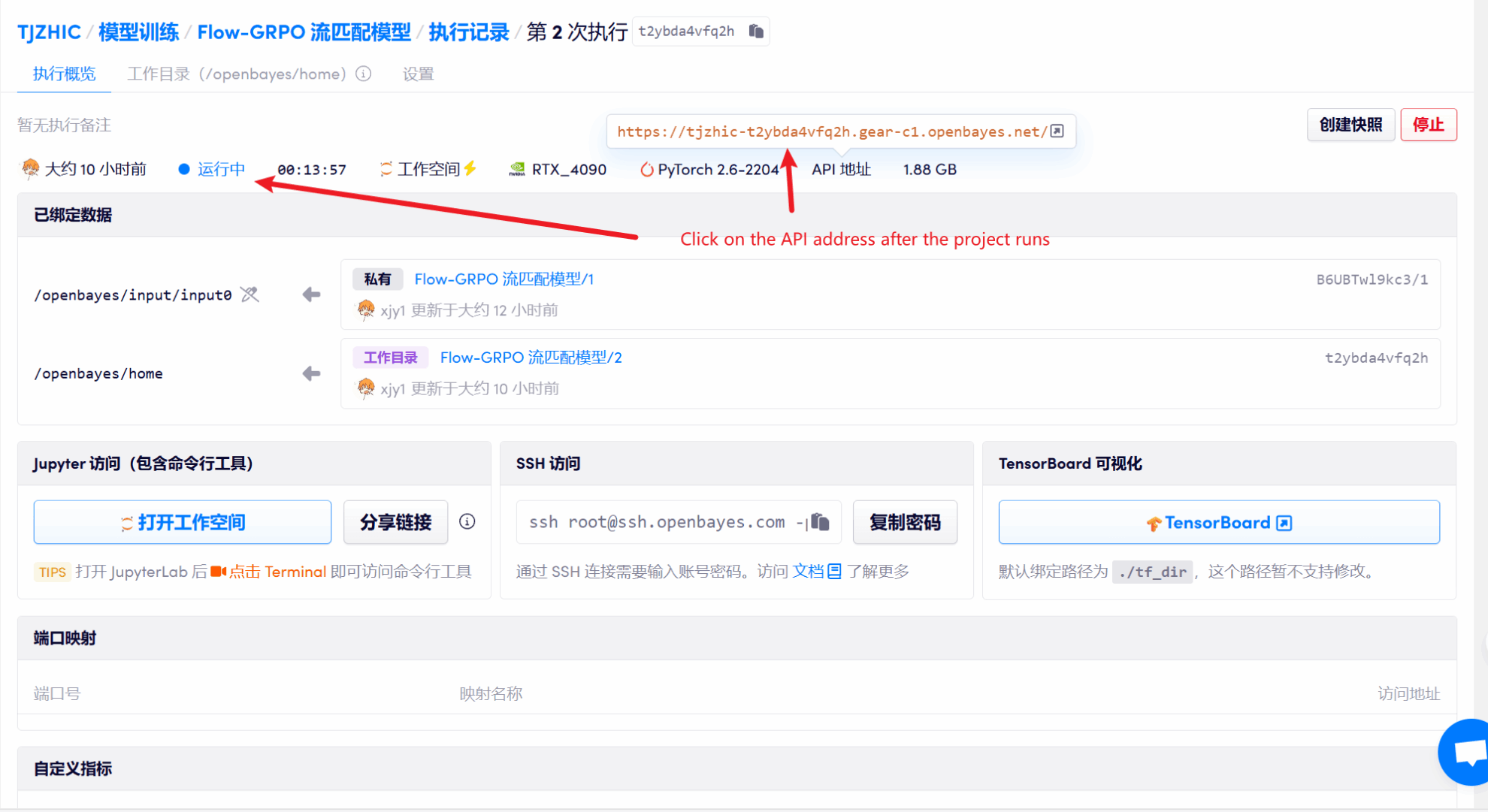
1. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen
Wenn „Bad Gateway“ angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 1–2 Minuten und aktualisieren Sie die Seite.
2. Nachdem Sie die Webseite aufgerufen haben, können Sie ein Gespräch mit dem Modell beginnen
Anwendung
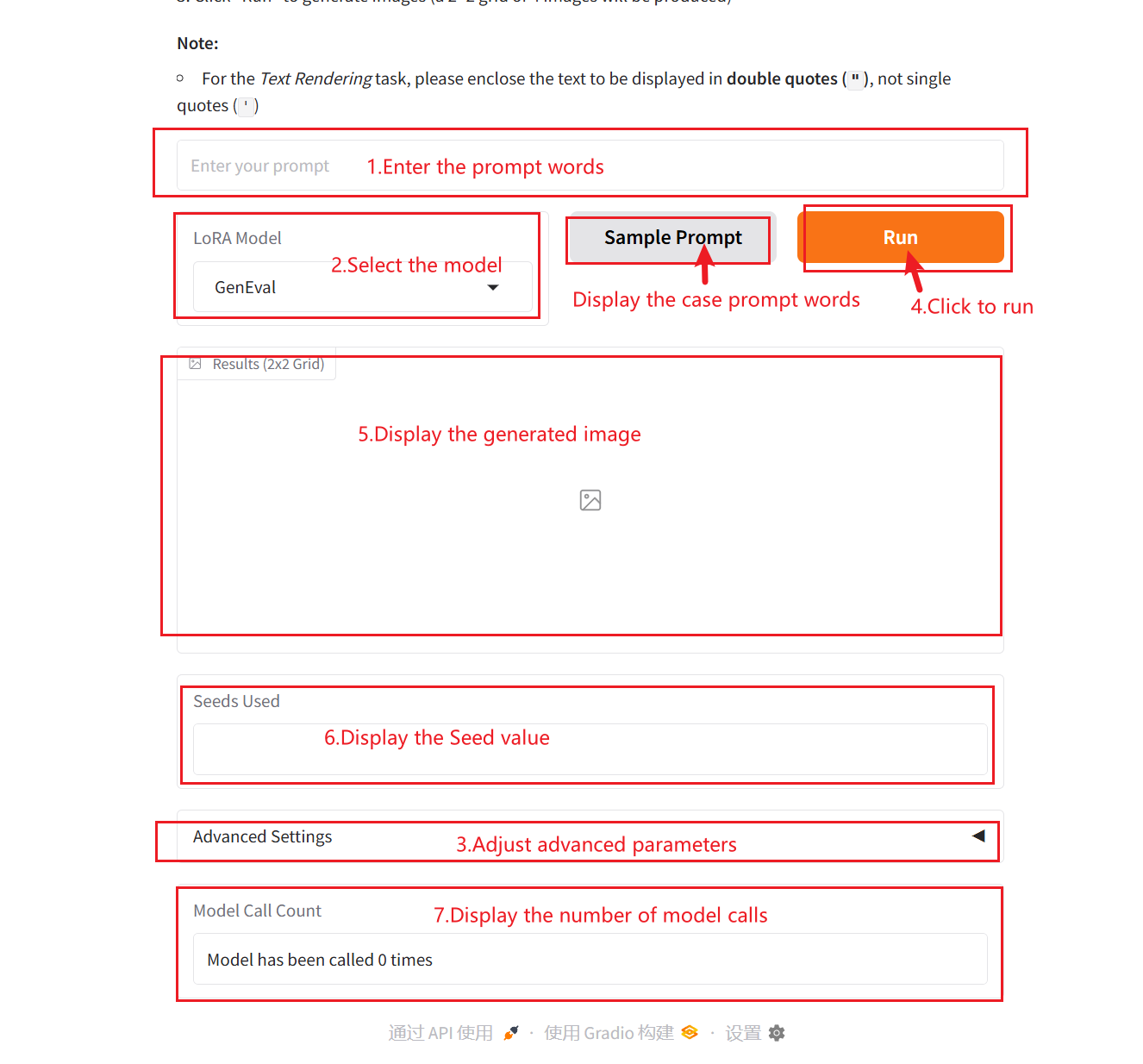
Parameterbeschreibung:
- LoRA-Modell:
- Keiner: Das Basismodell wird nativ aufgerufen und es wird keine Optimierungsstrategie eingeführt.
- Allgemeine Bewertung: Zur Unterstützung der Generierung und Verifizierung komplexer Szenarien wird ein sechsdimensionales Bewertungssystem aufgebaut.
- Textwiedergabe: Durch die präzise Textvisualisierung ist eine präzise Abbildung von Grafik- und Textinhalten möglich.
- Ausrichtung menschlicher Präferenzen: Quantitative Abstimmung ästhetischer Präferenzen und integriertes PickScore-Bewertungsframework
- Startsaatgut: Zufallszahlen-Seed, der zur Steuerung der Zufälligkeit des Generierungsprozesses verwendet wird. Derselbe Seed-Wert kann dieselben Ergebnisse erzeugen (vorausgesetzt, dass die anderen Parameter gleich sind), was für die Reproduktion von Ergebnissen sehr wichtig ist.
- Breite: Wird verwendet, um die Breite des generierten Bildes zu steuern.
- Höhe: Wird verwendet, um die Höhe des generierten Bildes zu steuern.
- Orientierungsskala: Es wird verwendet, um zu steuern, inwieweit bedingte Eingaben (wie Text oder Bilder) in generativen Modellen die generierten Ergebnisse beeinflussen. Höhere Richtwerte führen dazu, dass die generierten Ergebnisse besser mit den Eingabebedingungen übereinstimmen, während niedrigere Werte mehr Zufälligkeit beibehalten.
- Anzahl der Inferenzschritte: Stellt die Anzahl der Iterationen des Modells oder die Anzahl der Schritte im Inferenzprozess dar und stellt die Anzahl der Optimierungsschritte dar, die das Modell zum Generieren des Ergebnisses verwendet. Eine höhere Anzahl von Schritten führt im Allgemeinen zu genaueren Ergebnissen, kann aber die Rechenzeit verlängern.
4. Diskussion
🖌️ Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um es weiterzuempfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen ↓

Zitationsinformationen
Dank an den Github-Benutzer xxxjjjyyy1 Bereitstellung dieses Tutorials. Die Zitationsinformationen für dieses Projekt lauten wie folgt:
@misc{liu2025flowgrpo,
title={Flow-GRPO: Training Flow Matching Models via Online RL},
author={Jie Liu and Gongye Liu and Jiajun Liang and Yangguang Li and Jiaheng Liu and Xintao Wang and Pengfei Wan and Di Zhang and Wanli Ouyang},
year={2025},
eprint={2505.05470},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2505.05470},
}KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.