Command Palette
Search for a command to run...
Supertonic: Ein Auf ONNX Basierendes Hochgeschwindigkeits-TTS-Sprachsynthesemodell.
1. Einführung in das Tutorial

Dieses Tutorial basiert auf dem offiziellen Open-Source-Projekt Supertone.SupertonicVielen Dank an das Supertone-Team für seinen Beitrag zur Open-Source-Community! ❤️
Supertonic ist eine native Text-to-Speech-Engine (TTS), die vom Supertone-Team im Januar 2025 veröffentlicht wurde. Ihre Kernschicht für die Sprachsynthese basiert auf der ONNX Runtime, die speziell für Szenarien mit geringer Latenz und hoher Parallelität entwickelt wurde. Im Gegensatz zu herkömmlichen, skalierbaren TTS-Modellen senkt Supertonic die Hardwareanforderungen deutlich und gewährleistet gleichzeitig eine hohe Sprachqualität. Die Engine unterstützt vollständig offline Echtzeit-Sprachsynthese auf Desktop-Computern, Servern und sogar Edge-Geräten. Sie eignet sich besonders für Szenarien mit hohen Datenschutz- und Sicherheitsanforderungen oder für die Integration in interaktive Echtzeitanwendungen (wie z. B. digitale Charaktere und Voice-Chat in Spielen).
Bitte beachten Sie: Dieses Projekt unterstützt derzeit nur die Sprachausgabe von englischem Text.
Dieses Tutorial demonstriert die Rechenleistung einer einzelnen RTX 5090 GPU auf der OpenBayes-Plattform. Dabei werden die Hardwarebeschleunigung onnxruntime-gpu und Grado verwendet, um eine visuelle Weboberfläche zu erstellen, die eine englische Sprachsynthese im Millisekundenbereich ermöglicht.
2. Projektbeispiele
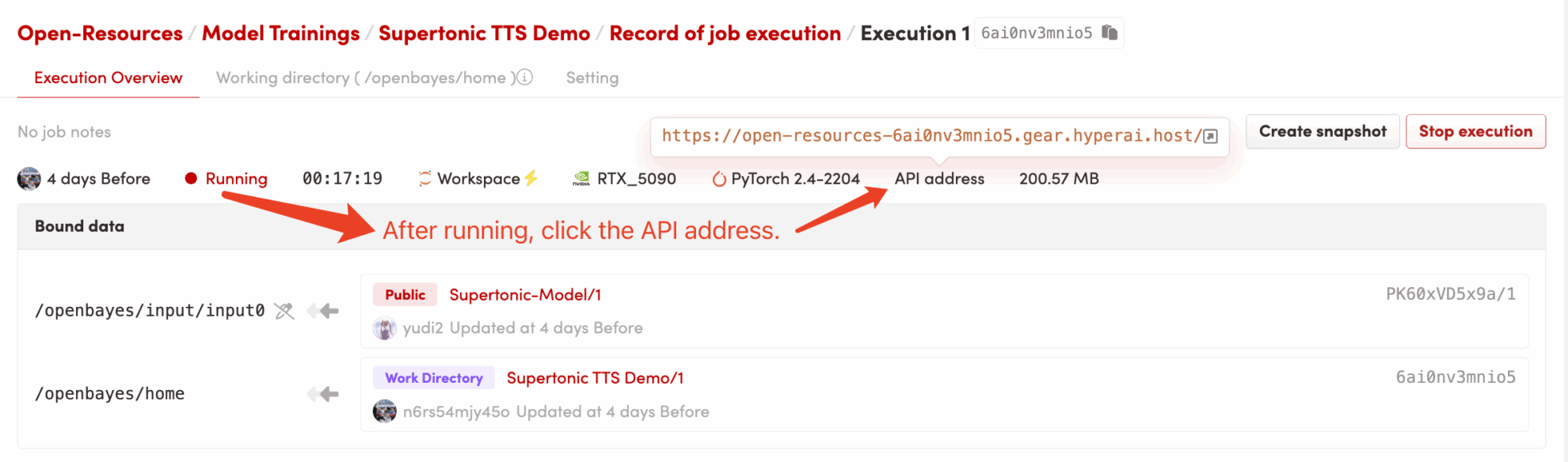
3. Bedienungsschritte
1. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen
- Klonen Sie dieses öffentliche Tutorial in der OpenBayes-Konsole.
- Starten Sie den Container: Das System weist Ihnen automatisch RTX 5090-Ressourcen zu.
- Warten auf den Start: Nachdem der Container gestartet wurde, wird das Hintergrundskript ausgeführt.
dependencies.shDie CUDA-Umgebung wird automatisch konfiguriert und das Modell geladen. Da die wichtigsten Abhängigkeiten vorinstalliert sind, ist dieser Vorgang sehr schnell und dauert in der Regel nur 1–2 Minuten. - Zugriff auf die Anwendung: Nachdem sich der Containerstatus auf „Wird ausgeführt“ geändert hat, klicken Sie auf die Schaltfläche „API-Adresse“ in der oberen rechten Ecke der Containerdetailseite, um die Grado-Weboberfläche zu öffnen.
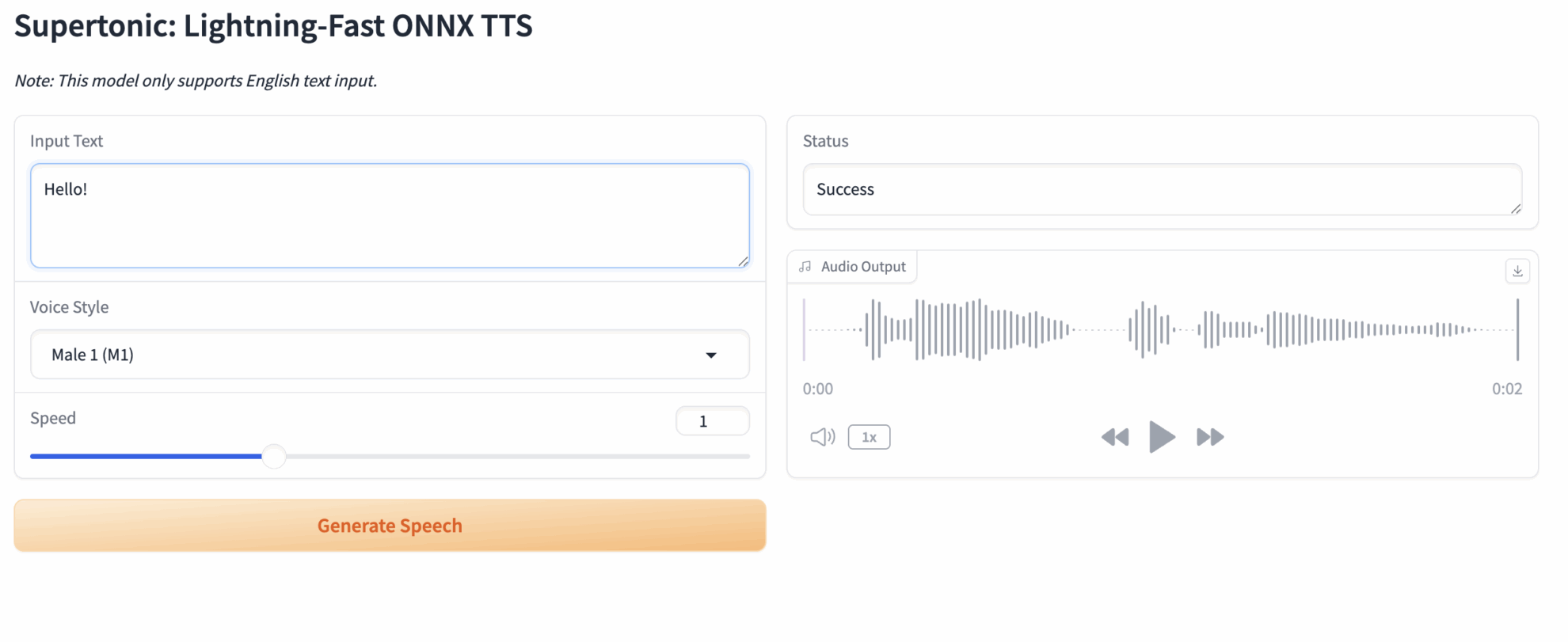
2. Text in eine Webseite eingeben und Sprache synthetisieren.
Wird „Bad Gateway“ angezeigt, bedeutet dies, dass der Dienst gerade gestartet wird. Da das Laden des Modells einige Zeit in Anspruch nimmt, warten Sie bitte 1–2 Minuten und aktualisieren Sie dann die Seite.
Bei Verwendung des Safari-Browsers wird der Ton möglicherweise nicht direkt abgespielt und muss vor der Wiedergabe heruntergeladen werden.
Nach dem Aufrufen der Webseite sehen Sie eine interaktive Benutzeroberfläche, die vollständig in Englisch ist.
Grundlegende Anwendungsschritte:
- Eingabetext: Geben Sie den englischen Text, den Sie synthetisieren möchten, in das Textfeld links ein. Beispiel: Supertonic ist ein blitzschnelles Text-zu-Sprache-Modell.
- Sprachstil: Wählen Sie einen voreingestellten Stil aus dem Dropdown-Menü (z. B. ...).
Male 1Männerstimme oderFemale 1(Weibliche Stimme) - Geschwindigkeit: Ziehen Sie den Schieberegler, um die Sprechgeschwindigkeit anzupassen. Der Standardwert ist 1,0.
- Sprachausgabe generieren: Klicken Sie auf die Schaltfläche „Generieren“.
- Audioausgabe: Bitte warten Sie einen Moment. Der Player rechts spielt die generierte Audiodatei automatisch ab. Sie können die Datei auch über die Schaltfläche „Herunterladen“ oben rechts speichern.
.wavdokumentieren.

Hinweis: Beim ersten Klick auf „Generieren“ kann die ONNX-Laufzeitumgebung einige Sekunden für die CUDA-Initialisierung und die Graphoptimierung benötigen. Die nachfolgenden Generierungen erfolgen sehr schnell.

Zitationsinformationen
@article{kim2025supertonic, title={SupertonicTTS: Towards Highly Efficient and Streamlined Text-to-Speech System}, author={Kim, Hyeongju and Yang, Jinhyeok and Yu, Yechan and Ji, Seunghun and Morton, Jacob and Bous, Malek and Lee, Sungjae}, journal={arXiv preprint arXiv:2503.23108}, year={2025}, url={[https://arxiv.org/abs/2503.23108](https://arxiv.org/abs/2503.23108)} } @article{kim2025larope,
title={Length-Aware Rotary Position Embedding for Text-Speech Alignment},
author={Kim, Hyeongju and Lee, Juheon and Yang, Jinhyeok and Morton, Jacob},
journal={arXiv preprint arXiv:2509.11084},
year={2025},
url={https://arxiv.org/abs/2509.11084}
}@article{kim2025spfm,
title={Training Flow Matching Models with Reliable Labels via Self-Purification},
author={Kim, Hyeongju and Yu, Yechan and Yi, June Young and Lee, Juheon},
journal={arXiv preprint arXiv:2509.19091},
year={2025},
url={https://arxiv.org/abs/2509.19091}
}
Notebook-Übersicht
Stufe
Thema
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.