Command Palette
Search for a command to run...
F5-E2 TTS Klont Jeden Ton in Nur 3 Sekunden
Datum
Paper-URL
Lizenz
CC BY-NC-SA 3.0
GitHub
1. Einführung in das Tutorial

Dieses Tutorial umfasst zwei Modelle zur Demo-Nutzung, nämlich F5-TTS und E2 TTS.
F5-TTS ist ein leistungsstarkes Text-to-Speech-System (TTS), das 2024 von der Shanghai Jiao Tong University, der Universität Cambridge und dem Geely Automobile Research Institute (Ningbo) Co., Ltd. als Open Source veröffentlicht wurde. Es basiert auf einem nicht-autoregressiven Generierungsverfahren mit Stream-Matching in Kombination mit Diffusion Transformer (DiT)-Technologie. Zugehörige Forschungsarbeiten sind verfügbar. F5-TTS: Ein Märchenerzähler, der mit Flow Matching flüssige und getreue Sprache vortäuscht Dieses System generiert mithilfe von Zero-Shot-Learning ohne zusätzliche Überwachung schnell natürliche, flüssige und originalgetreue Sprache aus dem Originaltext. F5-TTS unterstützt die mehrsprachige Sprachsynthese, darunter Chinesisch und Englisch, und kann auch längere Texte effektiv vertonen. Darüber hinaus bietet F5-TTS eine Emotionskontrolle, die den emotionalen Ausdruck der synthetisierten Sprache an den Textinhalt anpasst, sowie eine Geschwindigkeitsregelung, mit der Benutzer die Wiedergabegeschwindigkeit nach Bedarf anpassen können. Das System wurde mit einem umfangreichen Datensatz von 100.000 Stunden trainiert und demonstrierte dabei hervorragende Leistung und Generalisierungsfähigkeit. Zu den Hauptfunktionen von F5-TTS gehören Zero-Shot-Sprachklonierung, Geschwindigkeitsregelung, Emotionskontrolle, die Synthese langer Texte und die Unterstützung mehrerer Sprachen. Die technischen Grundlagen umfassen Stream-Matching, Diffusion Transformer (DiT), die Verbesserung der Textdarstellung durch ConvNeXt V2, die Sway-Sampling-Strategie und ein durchgängiges Systemdesign. F5-TTS bietet ein breites Anwendungsspektrum, darunter Hörbücher, Sprachassistenten, Sprachenlernen, Nachrichtenübertragungen und Videospielsynchronisation, und stellt leistungsstarke Sprachsynthesefunktionen für verschiedene kommerzielle und nichtkommerzielle Zwecke bereit.
E2 TTS, kurz für „Embarrassingly Easy Text-to-Speech“, ist ein fortschrittliches Text-to-Speech-System (TTS), das durch einen vereinfachten Prozess eine natürliche und sprecherähnliche Aussprache auf menschlichem Niveau erreicht. Der Kern von E2 TTS liegt in seiner vollständig nicht-autoregressiven Funktionsweise. Das bedeutet, dass es die gesamte Sprachsequenz auf einmal generieren kann, ohne schrittweise Generierung, wodurch die Generierungsgeschwindigkeit deutlich erhöht wird, während gleichzeitig eine hohe Sprachausgabequalität gewährleistet bleibt. Verwandte Forschungsarbeiten umfassen… E2 TTS: Peinlich einfaches, vollständig nicht-autoregressives Zero-Shot-TTSE2 TTS, akzeptiert von SLT 2024, wandelt Texteingaben in eine Zeichenfolge mit Füllzeichen um. Anschließend wird ein Mel-Spektrogramm-Generator auf Basis von Stream-Matching für die Audio-Auffüllung trainiert. Im Gegensatz zu vielen früheren Ansätzen benötigt E2 TTS keine zusätzlichen Komponenten (z. B. Dauermodelle, Zeichen-zu-Phonem-Konvertierung) oder komplexe Techniken (z. B. monotone Ausrichtungssuche). Trotz seiner Einfachheit erreicht E2 TTS modernste Zero-Shot-TTS-Funktionalität, vergleichbar mit oder sogar besser als frühere Ansätze wie Voicebox und NaturalSpeech 3. Die Einfachheit von E2 TTS ermöglicht zudem Flexibilität bei der Eingabedarstellung.
该教程支持如下模型和功能: 2 个模型检查点: F5-TTS E2 TTS 3 个功能:单人语音生成(Batched TTS): 根据上传的音频进行文本生成。 双人语音生成(Podcast Generation):根据双人音频模拟双人对话。多种语音类型生成(Multiple Speech-Type Generation):可根据同一讲话人不同情绪下的音频,生成不同情绪的音频。
Dieses Tutorial verwendet eine einzelne RTX 5090-Karte als Ressource.
2. Projektbeispiele
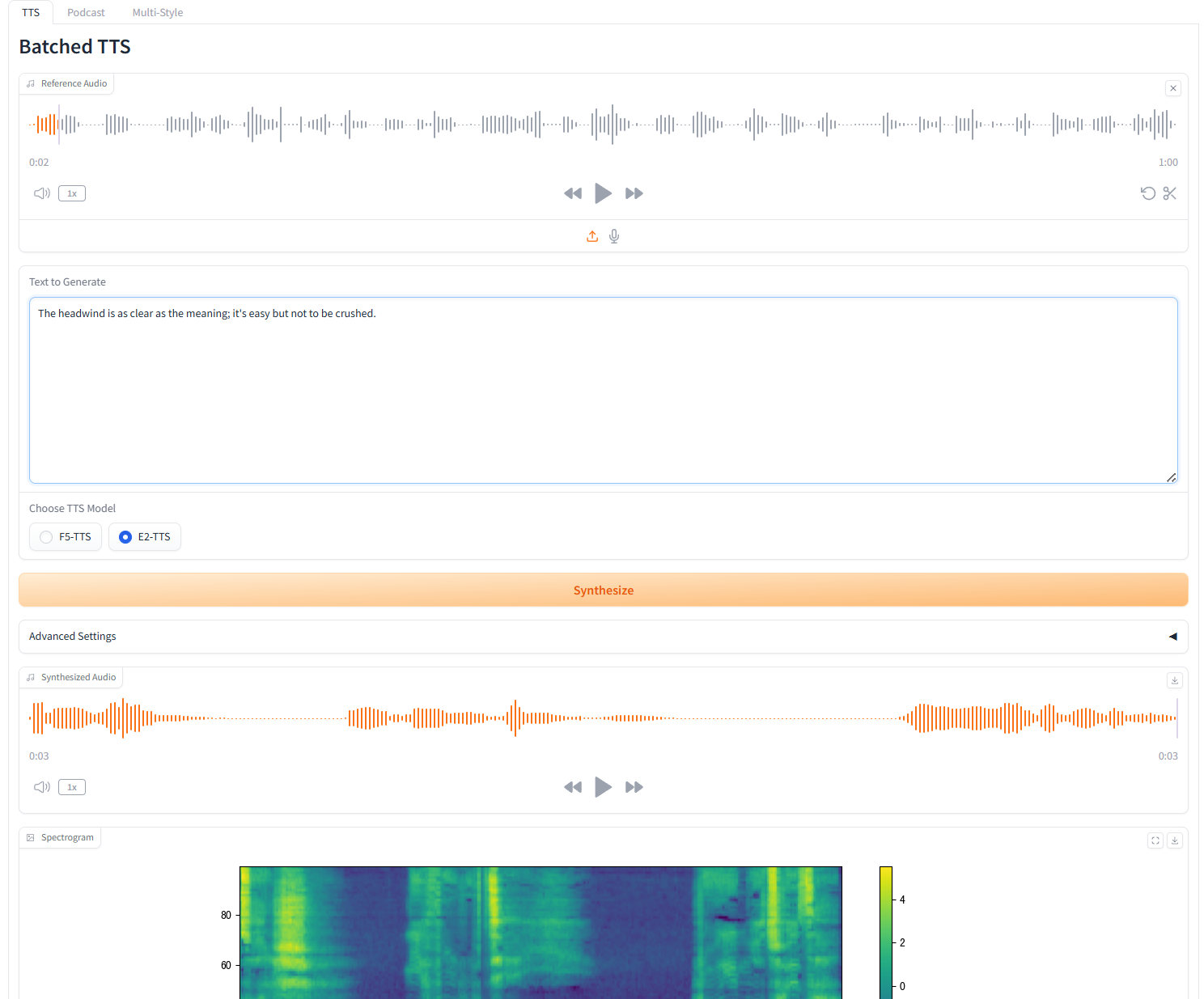
1. Gebündeltes TTS
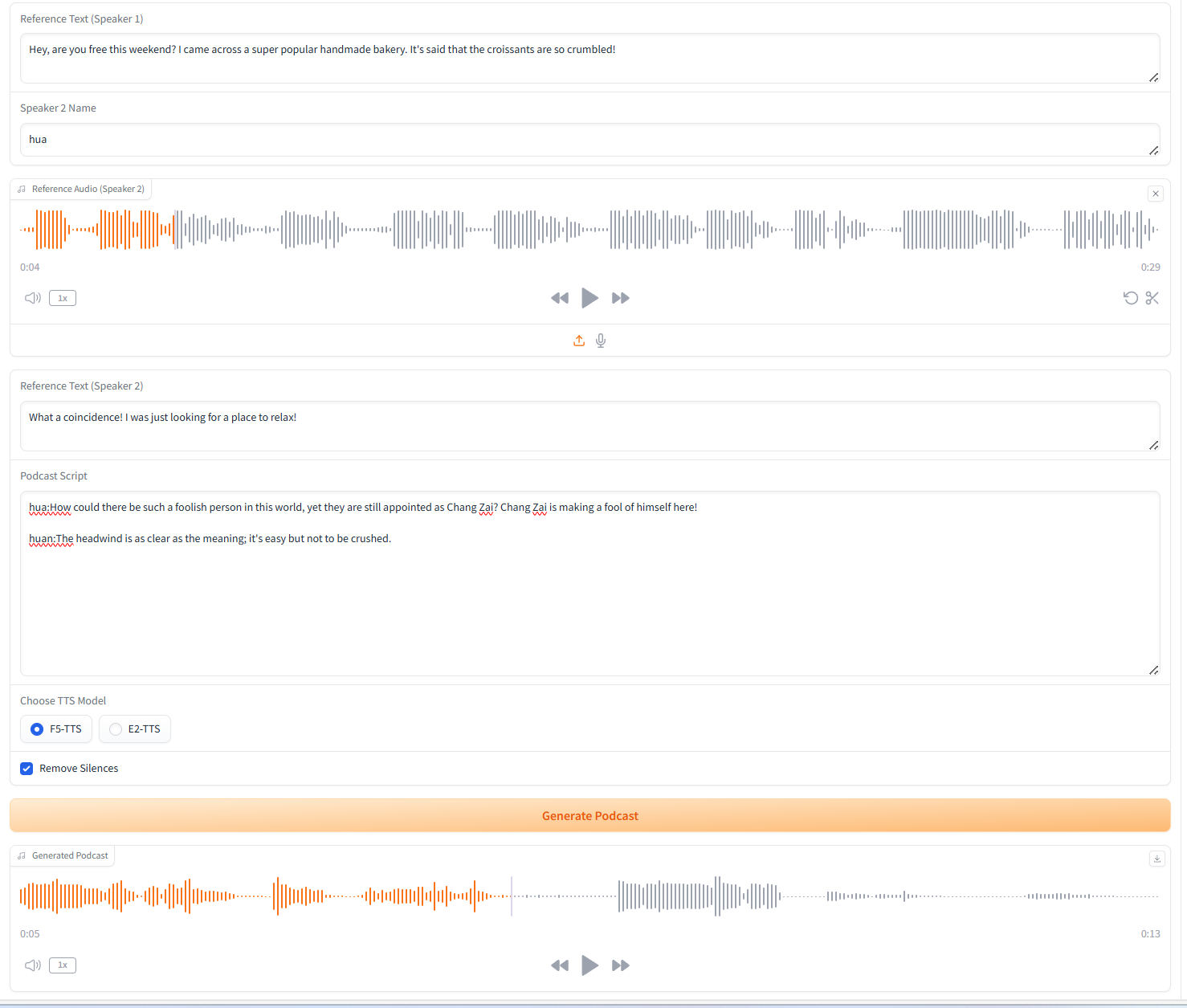
2. Podcast-Generierung
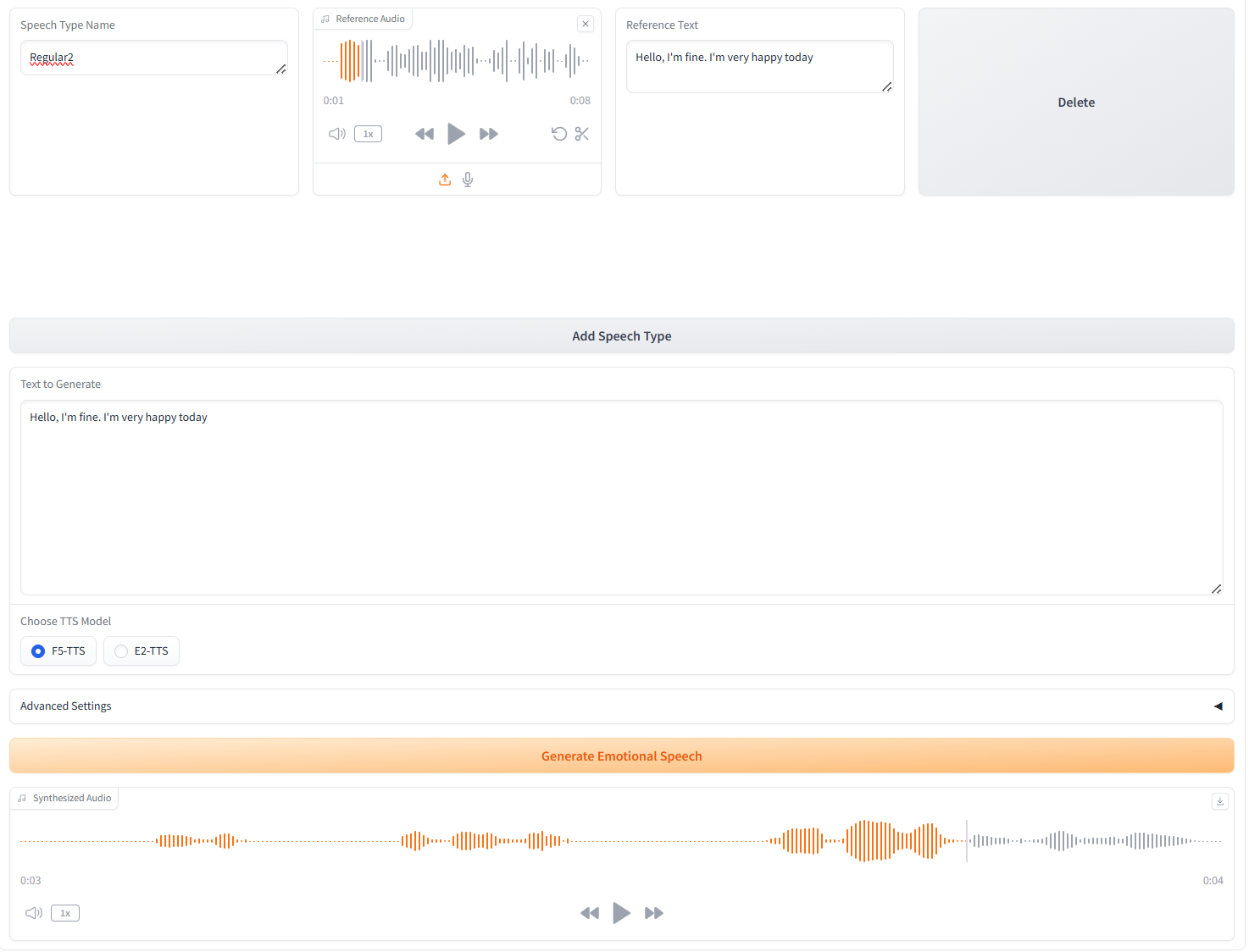
3. Generierung mehrerer Sprachtypen
3. Bedienungsschritte
1. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen
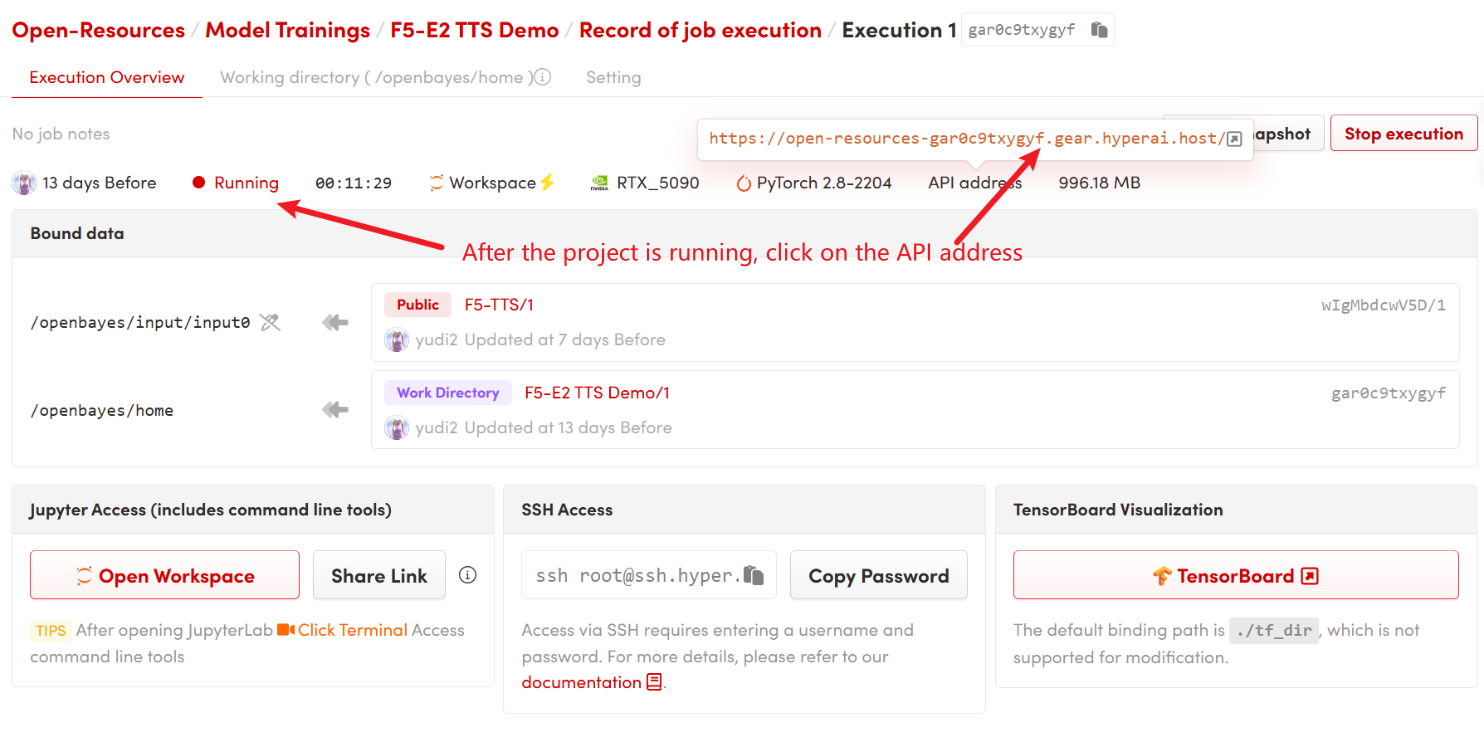
2. Anwendungsschritte
Wird „Bad Gateway“ angezeigt, bedeutet dies, dass das Modell initialisiert wird. Da das Modell umfangreich ist, warten Sie bitte etwa 9 Minuten und aktualisieren Sie dann die Seite.
Bei Verwendung des Safari-Browsers wird der Ton möglicherweise nicht direkt abgespielt und muss vor der Wiedergabe heruntergeladen werden.
1. Gebündeltes TTS
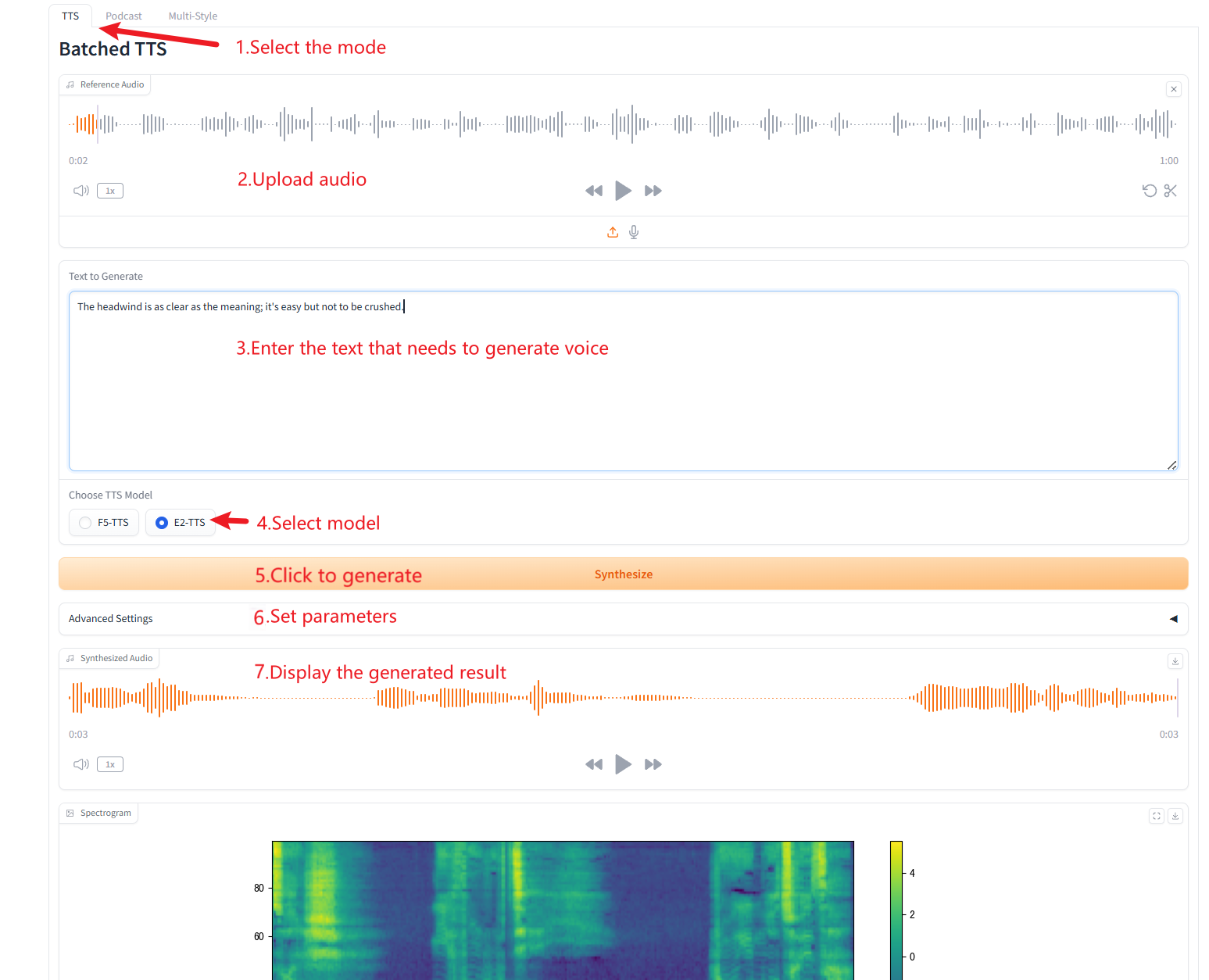
Parameterbeschreibung
- Referenztext: Leer lassen, um das Referenzaudio automatisch zu transkribieren. Wenn Sie Text eingeben, wird die automatische Transkription überschrieben.
- Stille entfernen: Dieses Modell neigt dazu, Stille zu erzeugen, insbesondere bei längeren Audiodateien. Bei Bedarf können wir die Stille manuell entfernen. Bitte beachten Sie, dass es sich hierbei um eine experimentelle Funktion handelt und diese zu merkwürdigen Ergebnissen führen kann. Dies erhöht auch die Bauzeit.
- Benutzerdefinierte Worttrennung: Geben Sie die zu trennenden benutzerdefinierten Wörter durch Kommas getrennt ein. Lassen Sie das Feld leer, um die Standardliste zu verwenden.
- Geschwindigkeit: Steuern Sie die Geschwindigkeit der generierten Sprache
2. Podcast-Generierung
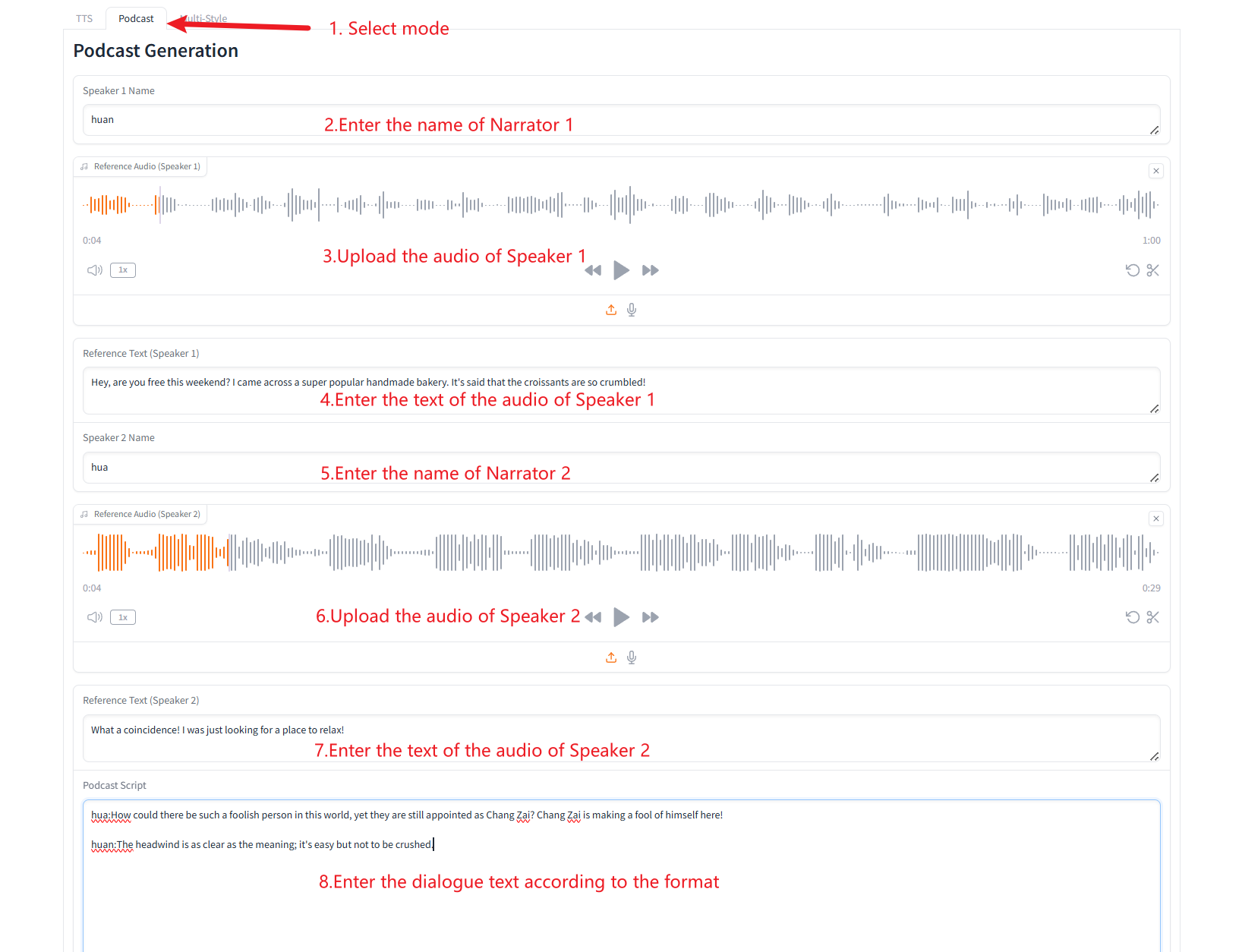
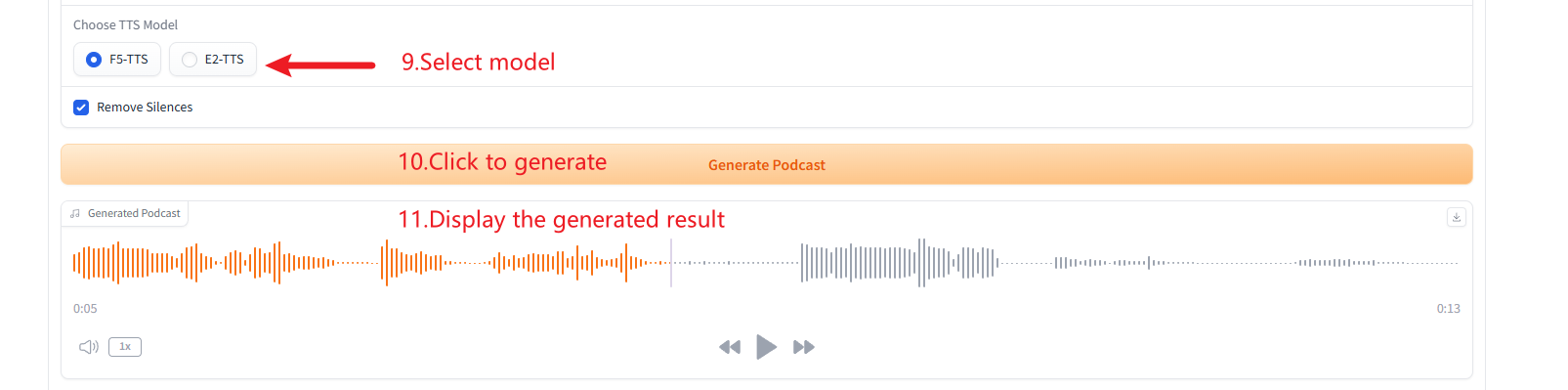
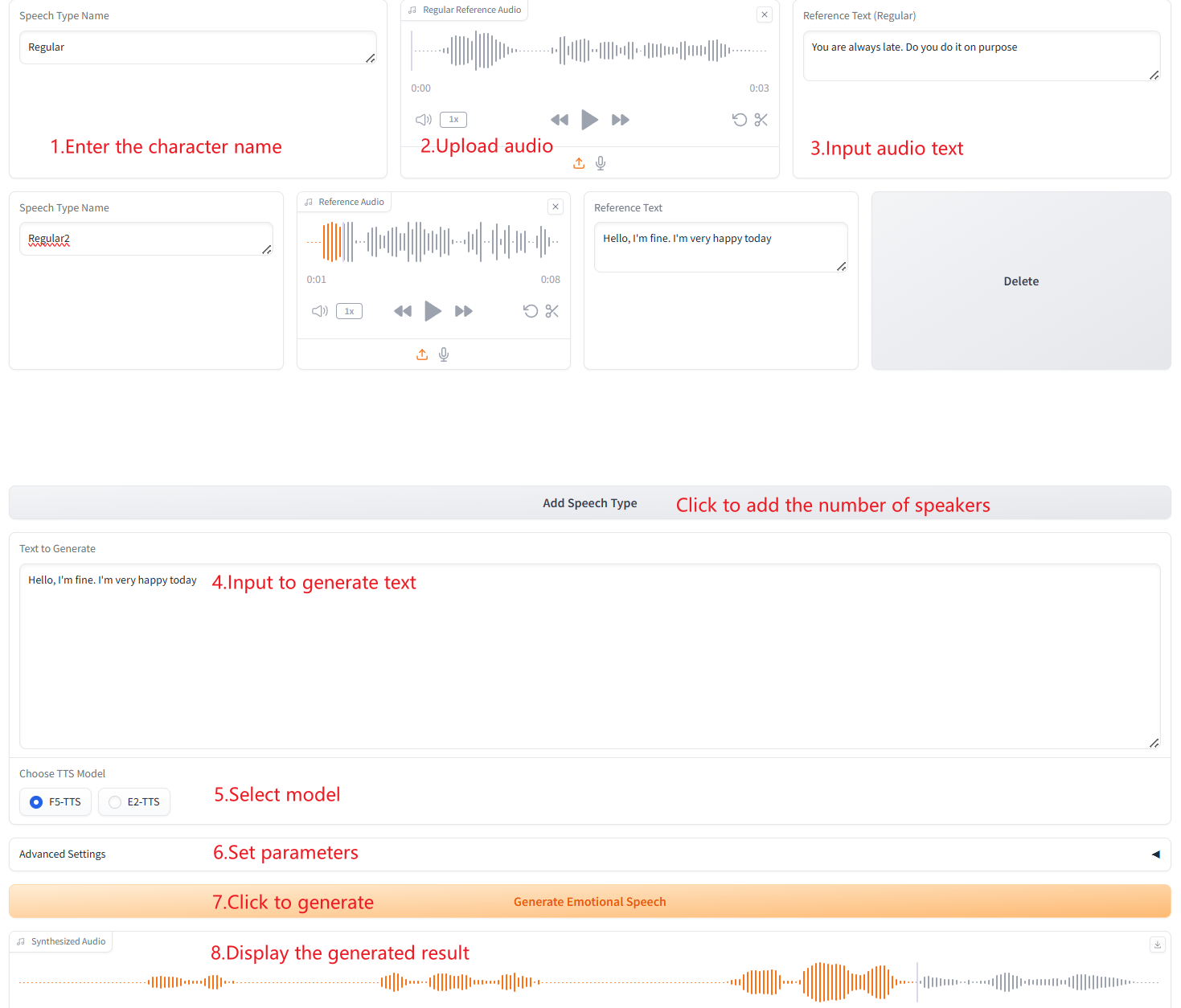
3. Generierung mehrerer Sprachtypen
Zitationsinformationen
@article{chen-etal-2024-f5tts,
title={F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching},
author={Yushen Chen and Zhikang Niu and Ziyang Ma and Keqi Deng and Chunhui Wang and Jian Zhao and Kai Yu and Xie Chen},
journal={arXiv preprint arXiv:2410.06885},
year={2024},
}Notebook-Übersicht
Stufe
Thema
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.