HyperAI
Command Palette
Search for a command to run...
Papers
Täglich aktualisierte hochmoderne KI-Forschungsarbeiten, um Sie über die neuesten KI-Trends auf dem Laufenden zu halten

VLM-SlideEval: Bewertung von VLMs hinsichtlich strukturierter Verständnisfähigkeit und Störungsempfindlichkeit in Präsentationen

TeraSim-Welt: Weltweite Synthese sicherheitskritischer Daten für autonome Fahrsysteme mit end-to-end-Architektur



























VLM-SlideEval: Bewertung von VLMs hinsichtlich strukturierter Verständnisfähigkeit und Störungsempfindlichkeit in Präsentationen
TeraSim-Welt: Weltweite Synthese sicherheitskritischer Daten für autonome Fahrsysteme mit end-to-end-Architektur
Vorausschauendes Ankerung: Beibehaltung der Charakteridentität bei audiogetriebener menschlicher Animation
VITA-E: Natürliche körperliche Interaktion mit gleichzeitiger Wahrnehmung, Hören, Sprechen und Handeln
FARMER: Fluss-automatische rekursive Transformatoren über Pixel
Eine Übersicht über Datenagenten: Emerging Paradigm oder überzogene Hype?
ReCode: Plan und Aktion für eine universelle Steuerung der Granularität vereinheitlichen
Concerto: Gemeinsame 2D-3D selbstüberwachtes Lernen ergibt räumliche Darstellungen
Magellan: Geführter MCTS für die Erkundung latenter Räume und die Generierung von Neuheiten
DEEDEE: Schnelle und skalierbare Erkennung von Ausreißern in der Dynamik
Sparsifikation von Block-Sparse Attention durch Token-Permutation
Eine Definition von AGI
Von der Rauschunterdrückung zur Verfeinerung: Ein korrigierender Rahmen für visuell-sprachliche Diffusionsmodelle
Schritt für Schritt proben, chunkweise optimieren: Chunk-orientiertes GRPO für die Text-zu-Bild-Generierung
Video-As-Prompt: Einheitliche semantische Steuerung für die Videogenerierung
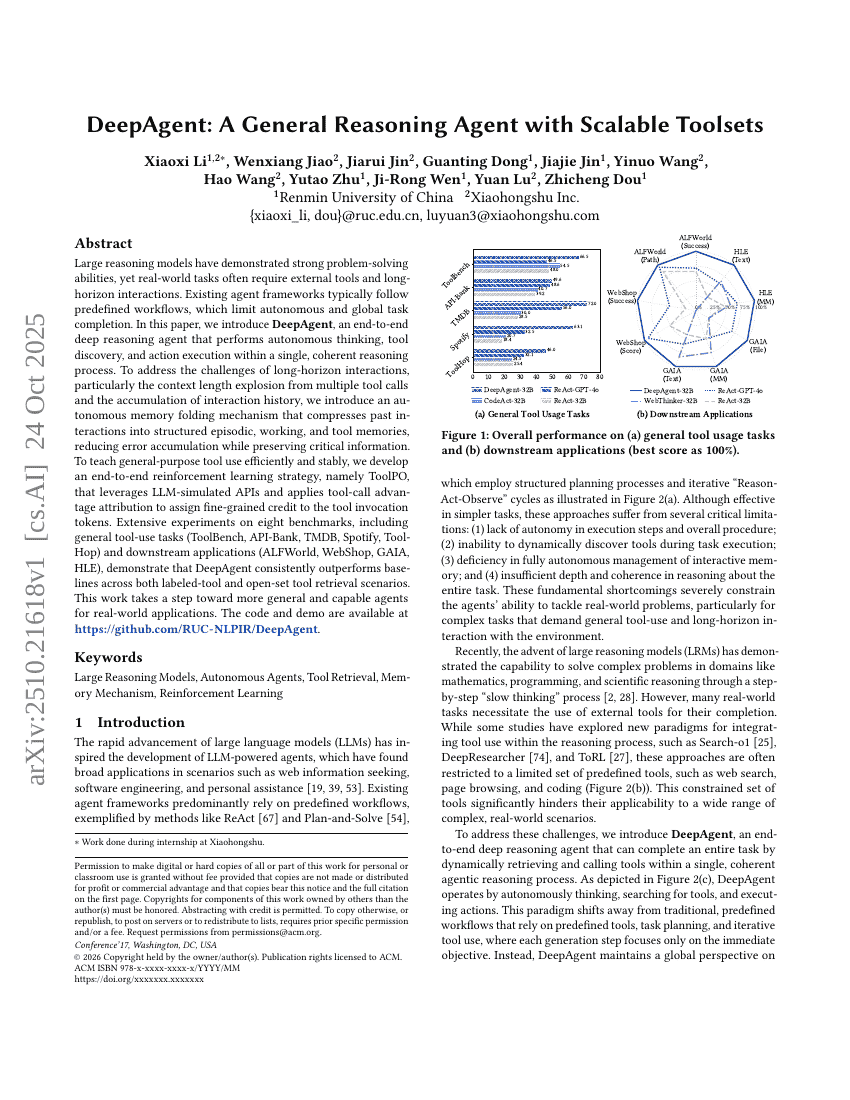
DeepAgent: Ein allgemeiner Schlussfolgerungs-Agent mit skalierbaren Werkzeugen
Unsicherheitsbewusste mehrzielorientierte Verstärkungslern-geleitete Diffusionsmodelle für die 3D-De-novo-Moleküldesign
Reac-Discovery: Eine künstliche Intelligenz-getriebene Plattform zur kontinuierlichen Stromreaktor-Entdeckung und -Optimierung
BoltzGen: Ein Schritt hin zu einer universellen Designstrategie für Bindemittel
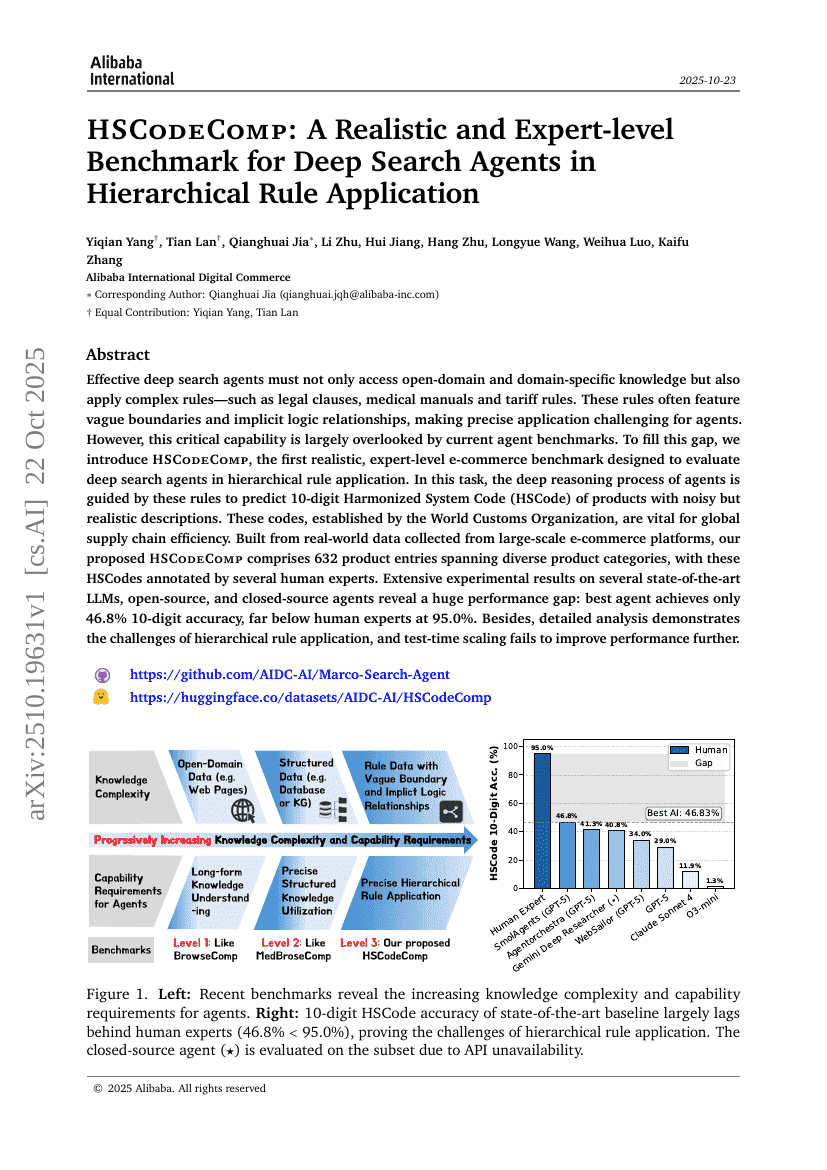
HSCodeComp: Ein realistischer und fachlich anspruchsvoller Benchmark für Deep-Search-Agenten bei hierarchischer Regelanwendung
DyPE: Dynamische Positionsextrapolation für Diffusionen mit ultrahocher Auflösung
HoloCine: Holistische Generierung kinematografischer, mehrfach geschnittener, langer Videonarrativen
Open-o3 Video: Grundlegende Video-Reasoning mit expliziten räumlich-zeitlichen Beweisen
AdaSPEC: Selektive Wissensvermittlung für effiziente spekulative Decoder
Mensch-Agenten-Kooperation zur Papier-zu-Seite-Generierung für unter 0,10 $
Richtungsorientierte Reasoning-Injektion zur Feinabstimmung von MLLMs
Sprachmodelle sind injektiv und daher invertierbar
Der freie Transformer
Vorhersage der Verarbeitungszeit einer Quantenverarbeitungseinheit (QPU) mit maschinellem Lernen
Beobachtung konstruktiver Interferenz am Rand der quanten-ergodischen Phase
VideoAgentTrek: Computer-Verwendung-Vortrainierung aus unlabeled Videos
GigaBrain-0: Ein visionssprachlich-handelndes Modell angetrieben durch ein Weltenmodell
Vorausschauendes Ankerung: Beibehaltung der Charakteridentität bei audiogetriebener menschlicher Animation
VITA-E: Natürliche körperliche Interaktion mit gleichzeitiger Wahrnehmung, Hören, Sprechen und Handeln
FARMER: Fluss-automatische rekursive Transformatoren über Pixel
Eine Übersicht über Datenagenten: Emerging Paradigm oder überzogene Hype?
ReCode: Plan und Aktion für eine universelle Steuerung der Granularität vereinheitlichen
Concerto: Gemeinsame 2D-3D selbstüberwachtes Lernen ergibt räumliche Darstellungen
Magellan: Geführter MCTS für die Erkundung latenter Räume und die Generierung von Neuheiten
DEEDEE: Schnelle und skalierbare Erkennung von Ausreißern in der Dynamik
Sparsifikation von Block-Sparse Attention durch Token-Permutation
Eine Definition von AGI
Von der Rauschunterdrückung zur Verfeinerung: Ein korrigierender Rahmen für visuell-sprachliche Diffusionsmodelle
Schritt für Schritt proben, chunkweise optimieren: Chunk-orientiertes GRPO für die Text-zu-Bild-Generierung
Video-As-Prompt: Einheitliche semantische Steuerung für die Videogenerierung
DeepAgent: Ein allgemeiner Schlussfolgerungs-Agent mit skalierbaren Werkzeugen
Unsicherheitsbewusste mehrzielorientierte Verstärkungslern-geleitete Diffusionsmodelle für die 3D-De-novo-Moleküldesign
Reac-Discovery: Eine künstliche Intelligenz-getriebene Plattform zur kontinuierlichen Stromreaktor-Entdeckung und -Optimierung
BoltzGen: Ein Schritt hin zu einer universellen Designstrategie für Bindemittel
HSCodeComp: Ein realistischer und fachlich anspruchsvoller Benchmark für Deep-Search-Agenten bei hierarchischer Regelanwendung
DyPE: Dynamische Positionsextrapolation für Diffusionen mit ultrahocher Auflösung
HoloCine: Holistische Generierung kinematografischer, mehrfach geschnittener, langer Videonarrativen
Open-o3 Video: Grundlegende Video-Reasoning mit expliziten räumlich-zeitlichen Beweisen
AdaSPEC: Selektive Wissensvermittlung für effiziente spekulative Decoder
Mensch-Agenten-Kooperation zur Papier-zu-Seite-Generierung für unter 0,10 $
Richtungsorientierte Reasoning-Injektion zur Feinabstimmung von MLLMs
Sprachmodelle sind injektiv und daher invertierbar
Der freie Transformer
Vorhersage der Verarbeitungszeit einer Quantenverarbeitungseinheit (QPU) mit maschinellem Lernen
Beobachtung konstruktiver Interferenz am Rand der quanten-ergodischen Phase
VideoAgentTrek: Computer-Verwendung-Vortrainierung aus unlabeled Videos
GigaBrain-0: Ein visionssprachlich-handelndes Modell angetrieben durch ein Weltenmodell