Command Palette
Search for a command to run...
Selbsterzwingende Echtzeit-Videogenerierung
Datum
Paper-URL
GitHub
1. Einführung in das Tutorial

Self Forcing, ein von Xun Huangs Team am 9. Juni 2025 vorgeschlagenes neuartiges Trainingsparadigma für autoregressive Videodiffusionsmodelle, adressiert das seit Langem bestehende Problem des Belichtungsbias. Dieses Problem tritt auf, wenn Modelle, die mit realen Kontexten trainiert wurden, während der Inferenz Sequenzen basierend auf ihren eigenen unvollkommenen Ausgaben generieren müssen. Im Gegensatz zu bisherigen Methoden, die zukünftige Frames anhand realer Kontextframes entrauschen, setzt Self Forcing die Generierungsbedingungen für jeden Frame auf die zuvor generierte Ausgabe. Dies geschieht durch einen autoregressiven Rollout mit Key-Value-Caching (KV-Caching) während des Trainings. Diese Strategie wird durch eine globale Verlustfunktion auf Videoebene überwacht, die die Qualität der gesamten generierten Sequenz direkt bewertet, anstatt sich ausschließlich auf eine traditionelle Frame-für-Frame-Zielfunktion zu stützen. Um eine effiziente Trainingssteuerung zu gewährleisten, werden ein mehrstufiges Diffusionsmodell und eine stochastische Gradientenabschneidung eingesetzt, wodurch Rechenaufwand und Leistung effektiv ausbalanciert werden. Zusätzlich wird ein rollierender Key-Value-Caching-Mechanismus eingeführt, um eine effiziente autoregressive Videoextrapolation zu erreichen. Umfangreiche Experimente belegen, dass ihre Methode die Generierung von Streaming-Videos in Echtzeit mit Latenzzeiten im Subsekundenbereich auf einer einzelnen GPU ermöglicht und dabei die Generierungsqualität deutlich langsamerer und nicht-kausaler Diffusionsmodelle erreicht oder sogar übertrifft. Die Ergebnisse der zugehörigen Veröffentlichung lauten wie folgt: Selbsterzwingung: Überbrückung der Train-Test-Lücke bei der autoregressiven Videodiffusion .
Dieses Tutorial verwendet Ressourcen für eine einzelne RTX 4090-Karte.
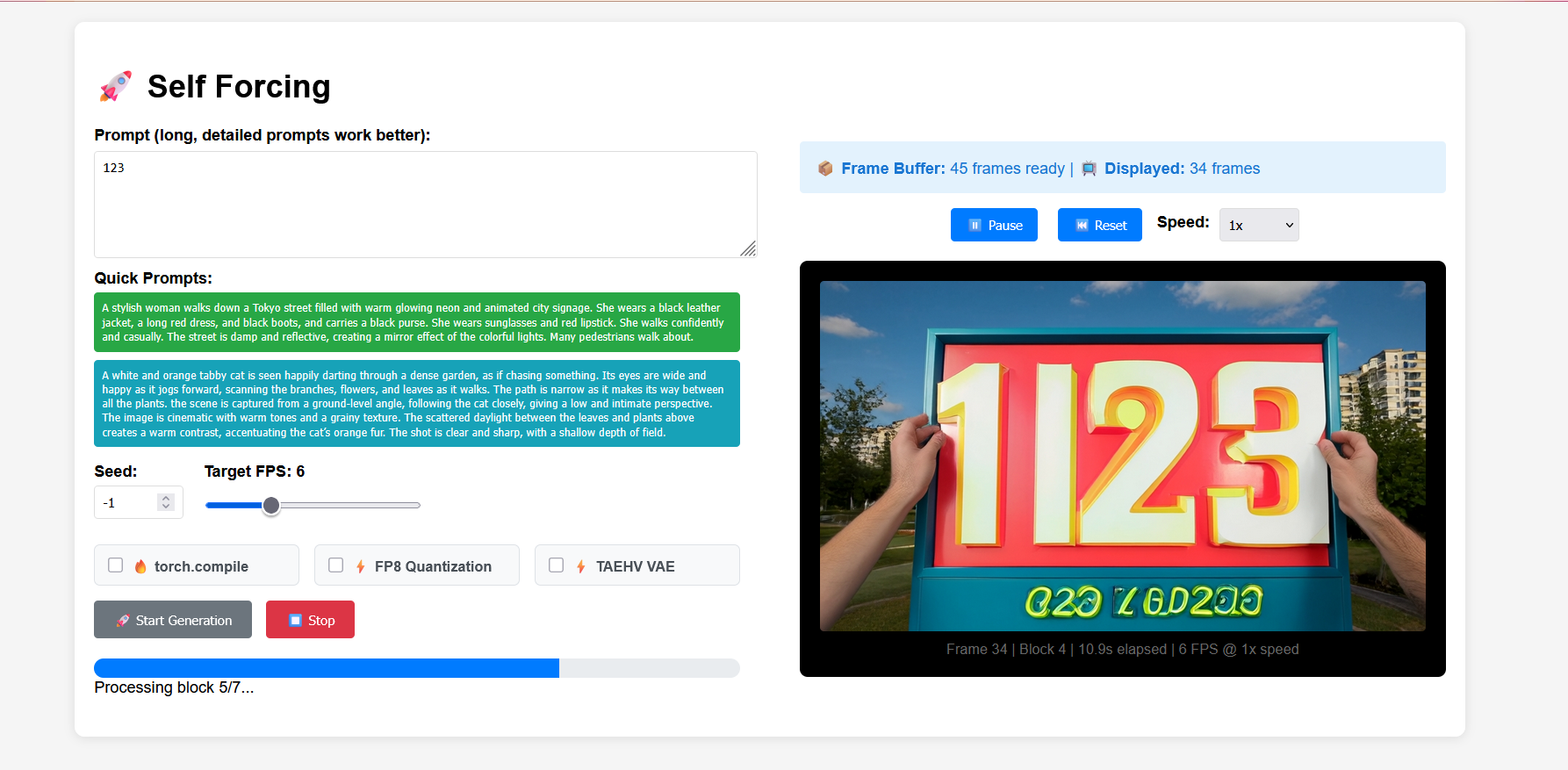
2. Projektbeispiele
3. Bedienungsschritte
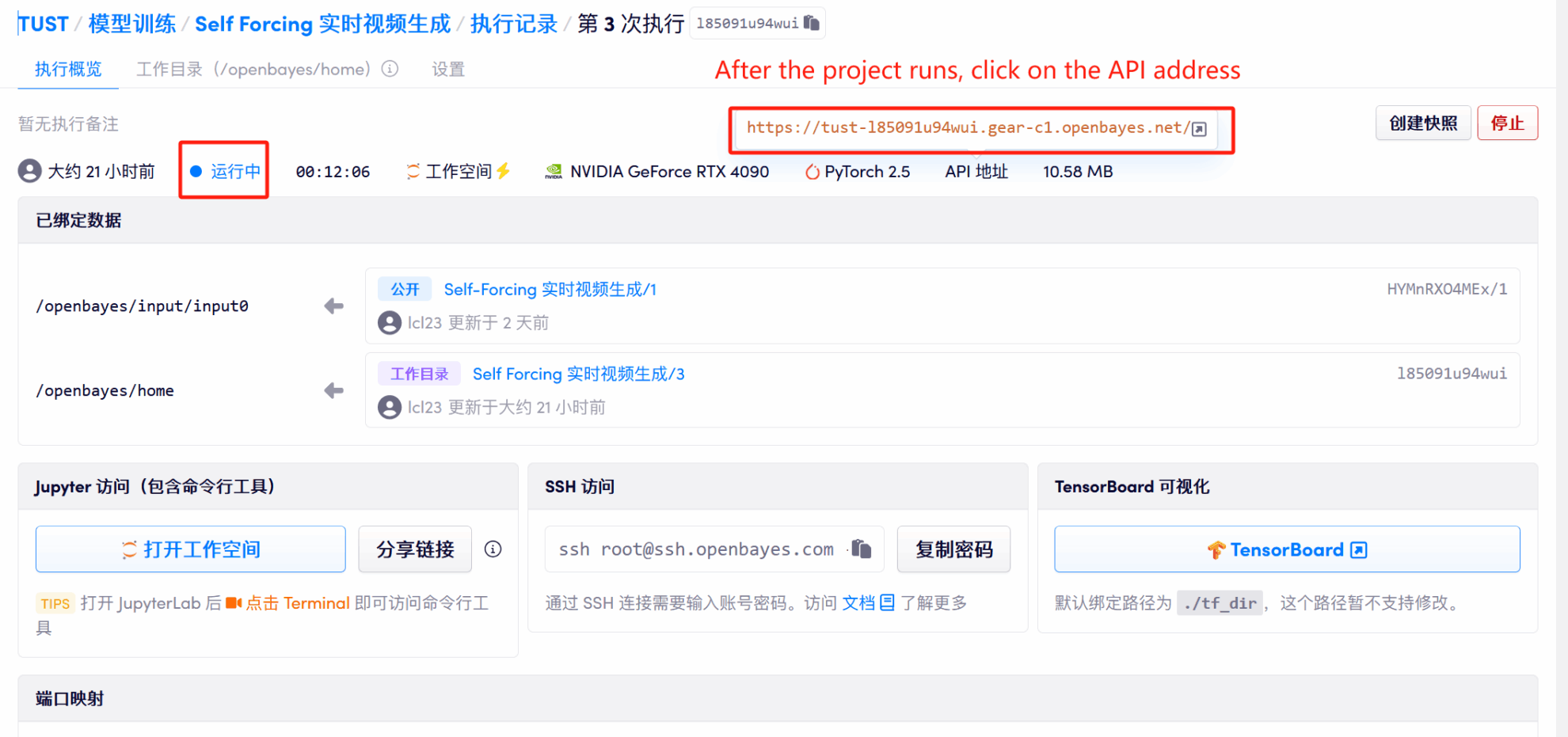
1. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen
2. Anwendungsschritte
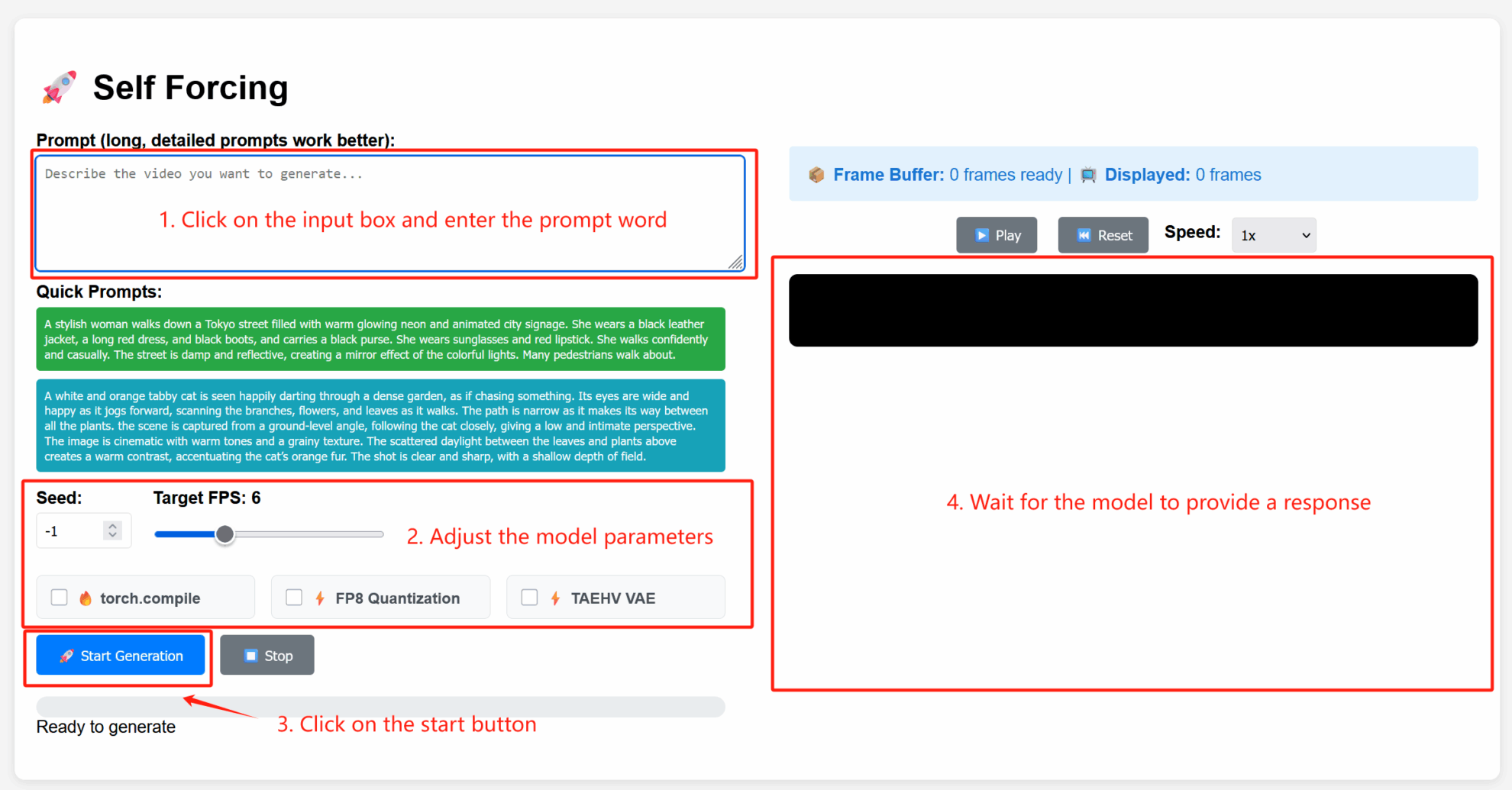
Parameterbeschreibung
- Erweiterte Einstellungen:
- Seed: Zufälliger Seed-Wert, der die Zufälligkeit des Generierungsprozesses steuert. Ein fester Seed kann dieselben Ergebnisse reproduzieren; -1 steht für einen zufälligen Seed.
- Ziel-FPS: Zielbildrate. Der Standardwert ist hier 6, was bedeutet, dass das generierte Video 6 Bilder pro Sekunde hat.
- torch.compile: Aktivieren Sie die PyTorch-Kompilierungsoptimierung, um die Modellinferenz zu beschleunigen (Umgebungsunterstützung erforderlich).
- FP8-Quantisierung: Aktiviert die 8-Bit-Gleitkommaquantisierung und reduziert die Rechenpräzision, um die Generierungsgeschwindigkeit zu erhöhen (kann die Qualität leicht beeinträchtigen).
- TAEHV VAE: Gibt den Typ des verwendeten Variational Autoencoder (VAE)-Modells an, der sich auf die generierten Details oder den Stil auswirken kann.
4. Diskussion
🖌️ Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um es weiterzuempfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen ↓

Zitationsinformationen
Die Zitationsinformationen für dieses Projekt lauten wie folgt:
@article{huang2025selfforcing,
title={Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion},
author={Huang, Xun and Li, Zhengqi and He, Guande and Zhou, Mingyuan and Shechtman, Eli},
journal={arXiv preprint arXiv:2506.08009},
year={2025}
}Notebook-Übersicht
Stufe
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.