BAGEL-7B-MoT ist ein Open-Source-Multimodalmodell, das am 22. Mai 2025 vom Seed-Team von ByteDance veröffentlicht wurde. Es zielt darauf ab, das Verstehen und Generieren multimodaler Daten wie Text, Bilder und Videos zu vereinheitlichen. BAGEL demonstriert umfassende Fähigkeiten im multimodalen Verstehen und Generieren, im komplexen Schließen und Bearbeiten, in der Weltmodellierung und Navigation sowie in weiteren multimodalen Aufgaben. Zu seinen Hauptfunktionen gehören visuelles Verständnis, Text-zu-Bild-Konvertierung und Bildbearbeitung. Verwandte Forschungsarbeiten sind verfügbar. Neue Eigenschaften im einheitlichen multimodalen Vortraining .
Dieses Tutorial verwendet die Rechenressourcen der Dual-Card-A6000 und bietet zum Testen die Funktionen „Bildgenerierung“, „Bildgenerierung mit Think“, „Bildbearbeitung“, „Bildbearbeitung mit Think“ und „Bildverständnis“.
2. Effektanzeige
3. Bedienungsschritte
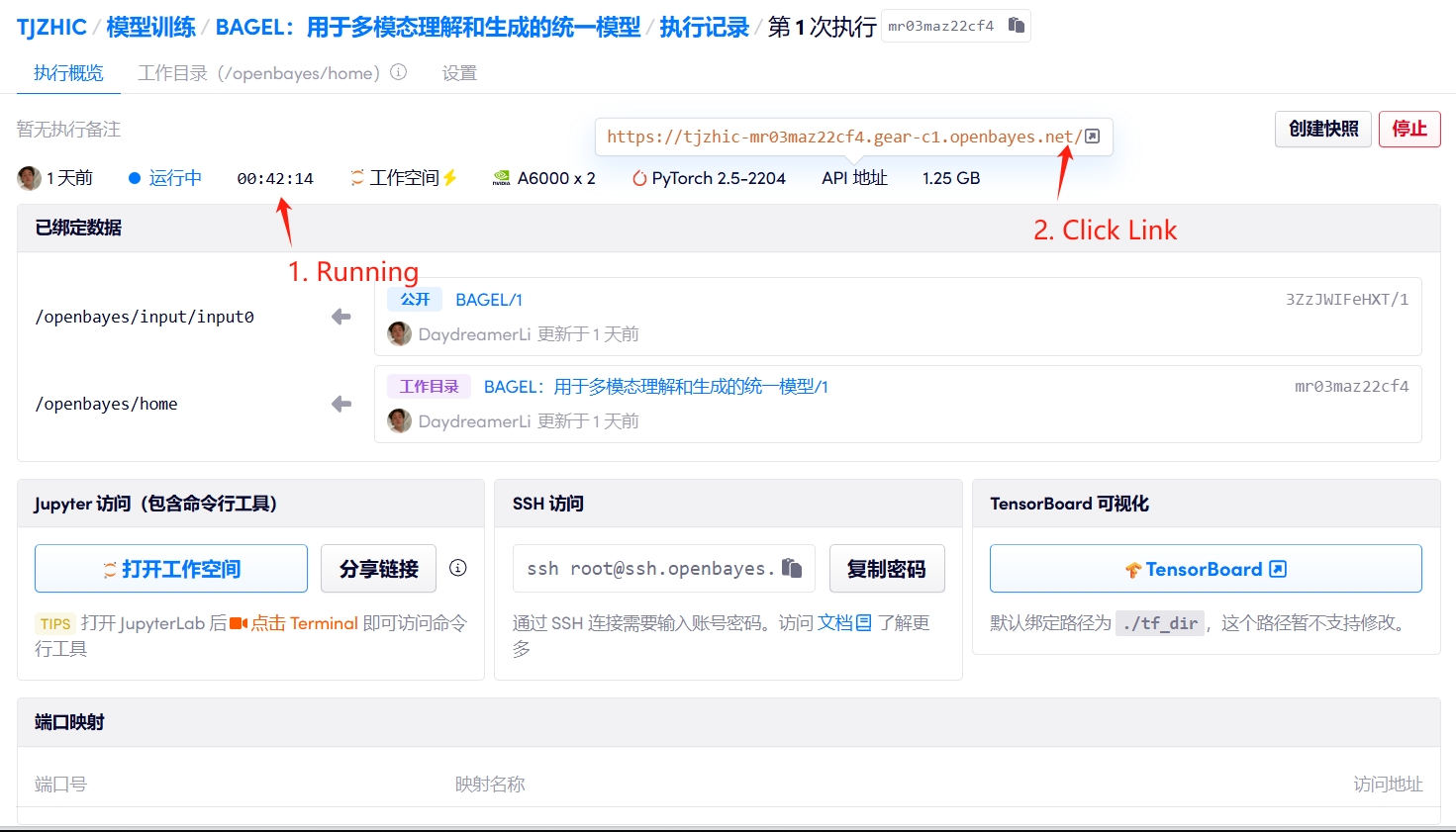
1. Starten Sie den Container
Wenn „Bad Gateway“ angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 2–3 Minuten und aktualisieren Sie die Seite.
2. Anwendungsbeispiele
2.1 Bilderzeugung
Spezifische Parameter:
Eingabeaufforderung: Sie können hier Text eingeben, um den Inhalt des Bildes zu beschreiben. Das Modell generiert dann basierend auf diesem Text ein Bild.
Textführungsskala: Steuert, wie stark sich die Eingabeaufforderung auf die Ausgabe auswirkt. Höhere Werte haben eine größere Wirkung.
Generierungsschritte: Mehr Schritte bedeuten bessere Qualität, aber geringere Geschwindigkeit.
Zeitschrittverschiebung: Steuert den Generierungsprozess.
Ergebnis
2.2 Bilderzeugung durch Denken
Spezifische Parameter:
Kreativ-Eingabeaufforderung: Sie können hier Text eingeben, um den Inhalt des Bildes zu beschreiben, und das Modell generiert basierend auf diesem Text ein Bild.
Max. Denk-Token: Kontrollieren Sie die Tiefe der Argumentation.
Textführungsskala: Steuert, wie stark sich die Eingabeaufforderung auf die Ausgabe auswirkt. Höhere Werte haben eine größere Wirkung.
Generierungsschritte: Mehr Schritte bedeuten bessere Qualität, aber geringere Geschwindigkeit.
Zeitschrittverschiebung: Steuert den Generierungsprozess.
Ergebnis
2.3 Bildbearbeitung
Spezifische Parameter:
Bild hochladen: Laden Sie das Bild hoch, das bearbeitet werden soll.
Anweisung bearbeiten: Anweisung bearbeiten.
Textführungsskala: Steuert, wie stark sich die Eingabeaufforderung auf die Ausgabe auswirkt. Höhere Werte haben eine größere Wirkung.
Bearbeitungsschritte: Mehr Schritte bedeuten bessere Qualität, aber geringere Geschwindigkeit.
Bearbeitungsfortschritt: Steuern Sie den Generierungsprozess.
Bildtreue: Eine höhere Bildtreue bedeutet, dass mehr vom Originalbild erhalten bleibt.
Ergebnis
2.4 Bildbearbeitung mit Think
Spezifische Parameter:
Bild hochladen: Laden Sie das Bild hoch, das bearbeitet werden soll.
Anweisung bearbeiten: Anweisung bearbeiten.
Argumentationstiefe: Argumentationstiefe.
Textführungsskala: Steuert, wie stark sich die Eingabeaufforderung auf die Ausgabe auswirkt. Höhere Werte haben eine größere Wirkung.
Verarbeitungsschritte: Mehr Schritte bedeuten bessere Qualität, aber geringere Geschwindigkeit.
Bearbeitungsfortschritt: Steuern Sie den Generierungsprozess.
Originalerhaltung: Bildtreue, höher bedeutet, dass mehr Original erhalten bleibt.
Ergebnis
2.5 Bildverständnis
Spezifische Parameter:
Bild hochladen: Laden Sie das Bild hoch, das bearbeitet werden soll.
Ihre Frage: Ihre Frage.
Ergebnis
4. Diskussion
🖌️ Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um es weiterzuempfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen ↓
Zitationsinformationen
Die Zitationsinformationen für dieses Projekt lauten wie folgt:
@article{deng2025bagel,
title = {Emerging Properties in Unified Multimodal Pretraining},
author = {Deng, Chaorui and Zhu, Deyao and Li, Kunchang and Gou, Chenhui and Li, Feng and Wang, Zeyu and Zhong, Shu and Yu, Weihao and Nie, Xiaonan and Song, Ziang and Shi, Guang and Fan, Haoqi},
journal = {arXiv preprint arXiv:2505.14683},
year = {2025}
}
Dieses Notebook wurde von Community-Nutzern beigesteuert und dient ausschließlich Bildungs- und Informationszwecken. Bei urheberrechtlichen Bedenken kontaktieren Sie uns bitte unter [email protected] zur umgehenden Prüfung und Entfernung.
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.
BAGEL-7B-MoT ist ein Open-Source-Multimodalmodell, das am 22. Mai 2025 vom Seed-Team von ByteDance veröffentlicht wurde. Es zielt darauf ab, das Verstehen und Generieren multimodaler Daten wie Text, Bilder und Videos zu vereinheitlichen. BAGEL demonstriert umfassende Fähigkeiten im multimodalen Verstehen und Generieren, im komplexen Schließen und Bearbeiten, in der Weltmodellierung und Navigation sowie in weiteren multimodalen Aufgaben. Zu seinen Hauptfunktionen gehören visuelles Verständnis, Text-zu-Bild-Konvertierung und Bildbearbeitung. Verwandte Forschungsarbeiten sind verfügbar. Neue Eigenschaften im einheitlichen multimodalen Vortraining .
Dieses Tutorial verwendet die Rechenressourcen der Dual-Card-A6000 und bietet zum Testen die Funktionen „Bildgenerierung“, „Bildgenerierung mit Think“, „Bildbearbeitung“, „Bildbearbeitung mit Think“ und „Bildverständnis“.
2. Effektanzeige
3. Bedienungsschritte
1. Starten Sie den Container
Wenn „Bad Gateway“ angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 2–3 Minuten und aktualisieren Sie die Seite.
2. Anwendungsbeispiele
2.1 Bilderzeugung
Spezifische Parameter:
Eingabeaufforderung: Sie können hier Text eingeben, um den Inhalt des Bildes zu beschreiben. Das Modell generiert dann basierend auf diesem Text ein Bild.
Textführungsskala: Steuert, wie stark sich die Eingabeaufforderung auf die Ausgabe auswirkt. Höhere Werte haben eine größere Wirkung.
Generierungsschritte: Mehr Schritte bedeuten bessere Qualität, aber geringere Geschwindigkeit.
Zeitschrittverschiebung: Steuert den Generierungsprozess.
Ergebnis
2.2 Bilderzeugung durch Denken
Spezifische Parameter:
Kreativ-Eingabeaufforderung: Sie können hier Text eingeben, um den Inhalt des Bildes zu beschreiben, und das Modell generiert basierend auf diesem Text ein Bild.
Max. Denk-Token: Kontrollieren Sie die Tiefe der Argumentation.
Textführungsskala: Steuert, wie stark sich die Eingabeaufforderung auf die Ausgabe auswirkt. Höhere Werte haben eine größere Wirkung.
Generierungsschritte: Mehr Schritte bedeuten bessere Qualität, aber geringere Geschwindigkeit.
Zeitschrittverschiebung: Steuert den Generierungsprozess.
Ergebnis
2.3 Bildbearbeitung
Spezifische Parameter:
Bild hochladen: Laden Sie das Bild hoch, das bearbeitet werden soll.
Anweisung bearbeiten: Anweisung bearbeiten.
Textführungsskala: Steuert, wie stark sich die Eingabeaufforderung auf die Ausgabe auswirkt. Höhere Werte haben eine größere Wirkung.
Bearbeitungsschritte: Mehr Schritte bedeuten bessere Qualität, aber geringere Geschwindigkeit.
Bearbeitungsfortschritt: Steuern Sie den Generierungsprozess.
Bildtreue: Eine höhere Bildtreue bedeutet, dass mehr vom Originalbild erhalten bleibt.
Ergebnis
2.4 Bildbearbeitung mit Think
Spezifische Parameter:
Bild hochladen: Laden Sie das Bild hoch, das bearbeitet werden soll.
Anweisung bearbeiten: Anweisung bearbeiten.
Argumentationstiefe: Argumentationstiefe.
Textführungsskala: Steuert, wie stark sich die Eingabeaufforderung auf die Ausgabe auswirkt. Höhere Werte haben eine größere Wirkung.
Verarbeitungsschritte: Mehr Schritte bedeuten bessere Qualität, aber geringere Geschwindigkeit.
Bearbeitungsfortschritt: Steuern Sie den Generierungsprozess.
Originalerhaltung: Bildtreue, höher bedeutet, dass mehr Original erhalten bleibt.
Ergebnis
2.5 Bildverständnis
Spezifische Parameter:
Bild hochladen: Laden Sie das Bild hoch, das bearbeitet werden soll.
Ihre Frage: Ihre Frage.
Ergebnis
4. Diskussion
🖌️ Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um es weiterzuempfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen ↓
Zitationsinformationen
Die Zitationsinformationen für dieses Projekt lauten wie folgt:
@article{deng2025bagel,
title = {Emerging Properties in Unified Multimodal Pretraining},
author = {Deng, Chaorui and Zhu, Deyao and Li, Kunchang and Gou, Chenhui and Li, Feng and Wang, Zeyu and Zhong, Shu and Yu, Weihao and Nie, Xiaonan and Song, Ziang and Shi, Guang and Fan, Haoqi},
journal = {arXiv preprint arXiv:2505.14683},
year = {2025}
}
Dieses Notebook wurde von Community-Nutzern beigesteuert und dient ausschließlich Bildungs- und Informationszwecken. Bei urheberrechtlichen Bedenken kontaktieren Sie uns bitte unter [email protected] zur umgehenden Prüfung und Entfernung.
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.