Command Palette
Search for a command to run...
Online-Tutorial丨Shiji Niangniang Verwandelt Sich Sofort in Ein „Mädchen Aus Sichuan Und Chongqing“? Step-Audio-TTS Realisiert Sprachklonen/Musiksynthese/Sprachsynthese drei-in-eins

Die weltweite Begeisterung für die Open Source-Lösung DeepSeek ist nach wie vor vorhanden. Vor Kurzem haben Step Star und Geely Auto Group erneut einen Schritt nach vorne gemacht und das Modell Step-Audio-TTS-3B als Open Source freigegeben, was in der Branche erneut zu breiten Diskussionen geführt hat.
Es war einmal,Aufgrund der Vielfalt und Komplexität der Dialektdaten und der hohen Anforderungen an die Modellgeneralisierung weist das Stimmklonmodell bei Dialekten eine schlechte Leistung auf.Das Step-Audio-TTS-3B kann die Besonderheiten lokaler Sprachen anschaulich interpretieren. Es wird auf Grundlage eines umfangreichen synthetischen Datensatzes des LLM-Chat-Paradigmas trainiert und verfügt über einen tiefen Einblick in die Struktur der Sprache. Es kann die subtilen Veränderungen in der Sprache zwischen den Zeilen erfassen. Ob es sich um den leidenschaftlichen Sichuan-Dialekt oder das neun- und sechsstimmige Kantonesisch handelt, es kann dessen Rhythmus und Ton präzise einfangen und so die starken lokalen Bräuche zum Ausdruck bringen.
Darüber hinaus ist es das erste TTS-Modell, das RAP und Summengenerierung realisiert und so die Lücke in der Musik-Sprachsynthese schließt. Früher waren für die Erstellung rhythmischer Rap-Inhalte professionelle Sänger erforderlich. Mithilfe von Step-Audio-TTS-3B können Benutzer jetzt schnell einen RAP-Gesang mit präzisem Rhythmus und flüssigem Fluss erzeugen, der zu endlosen Möglichkeiten inspiriert.
Derzeit wurde das „Step-Audio-TTS-3B-Modell zur Dialektsprachgenerierung auf Produktionsniveau“ im Abschnitt „Tutorial“ der offiziellen Website von HyperAI veröffentlicht.Dieses Tutorial umfasst drei Funktionen: Sprachsynthese, Musiksynthese und Stimmklonen. Kommen Sie und erleben Sie es selbst~
Adresse des Tutorials:
Demolauf
1. Melden Sie sich bei hyper.ai an, wählen Sie auf der Tutorial-Seite „Step-Audio-TTS-3B Production-Level Dialect Speech Generation Model“ und klicken Sie auf „Dieses Tutorial online ausführen“.
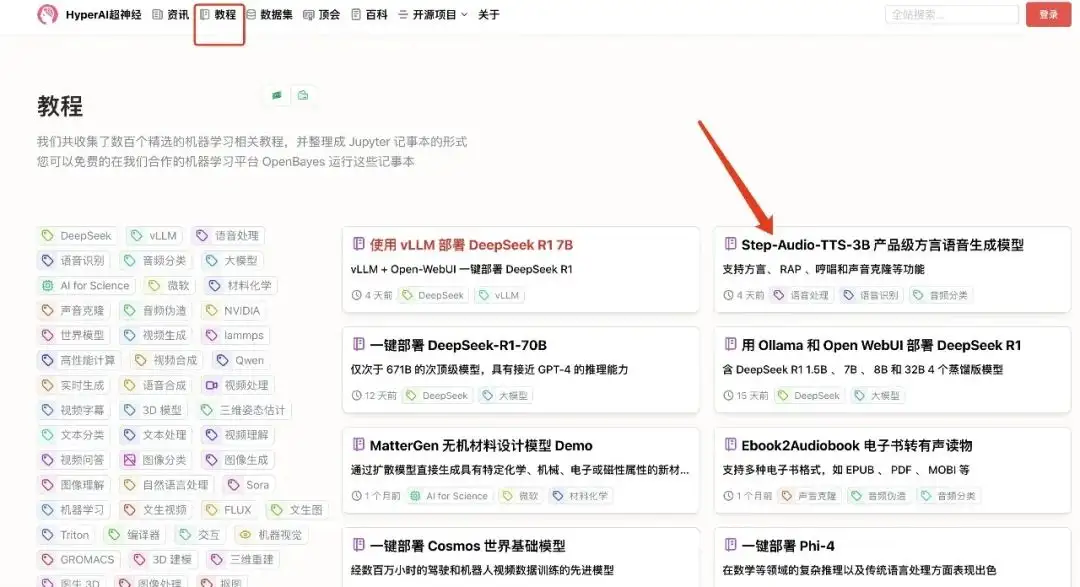
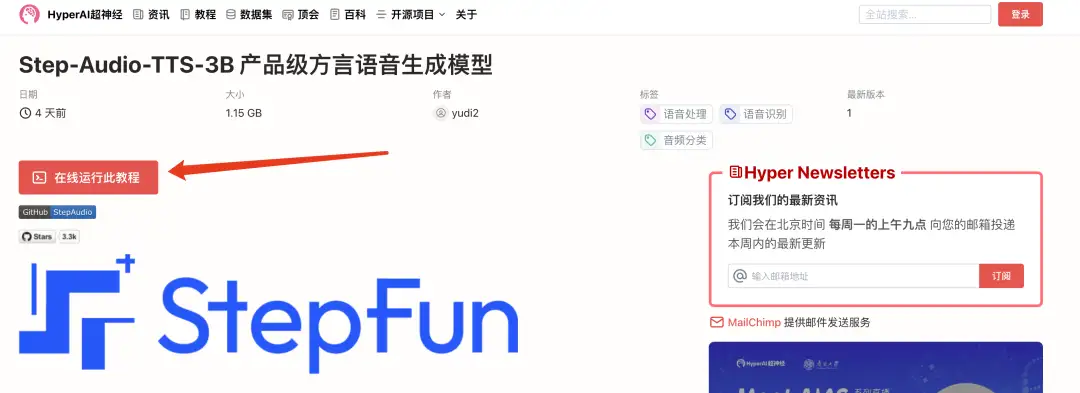
2. Klicken Sie nach dem Seitensprung oben rechts auf „Klonen“, um das Tutorial in Ihren eigenen Container zu klonen.
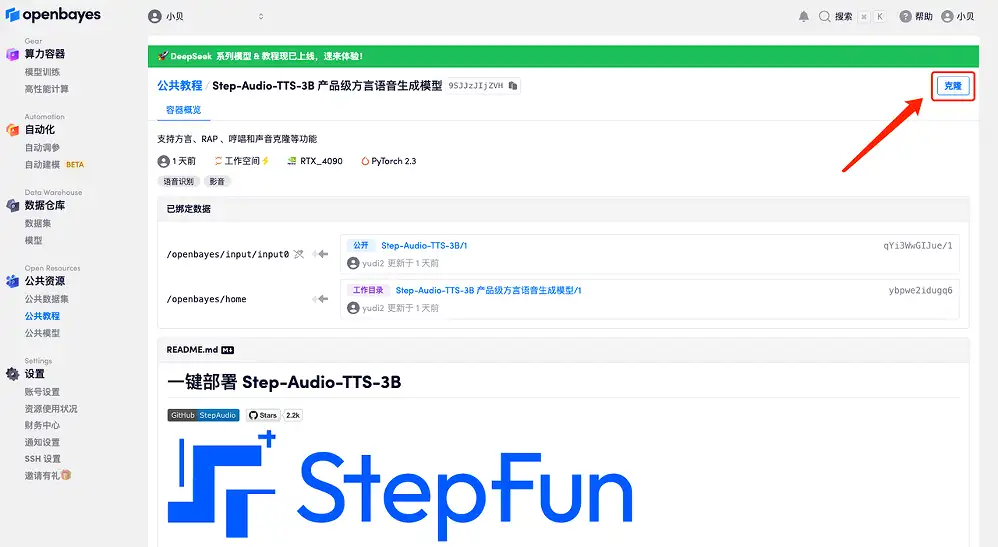
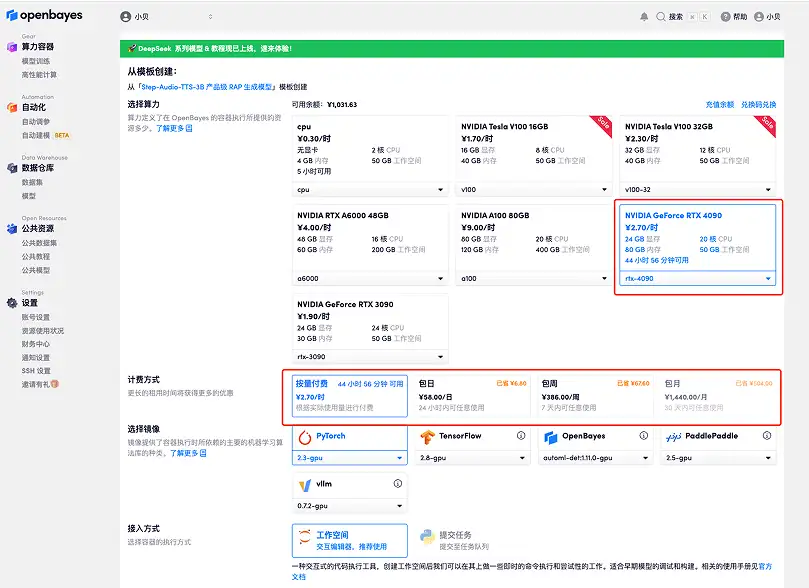
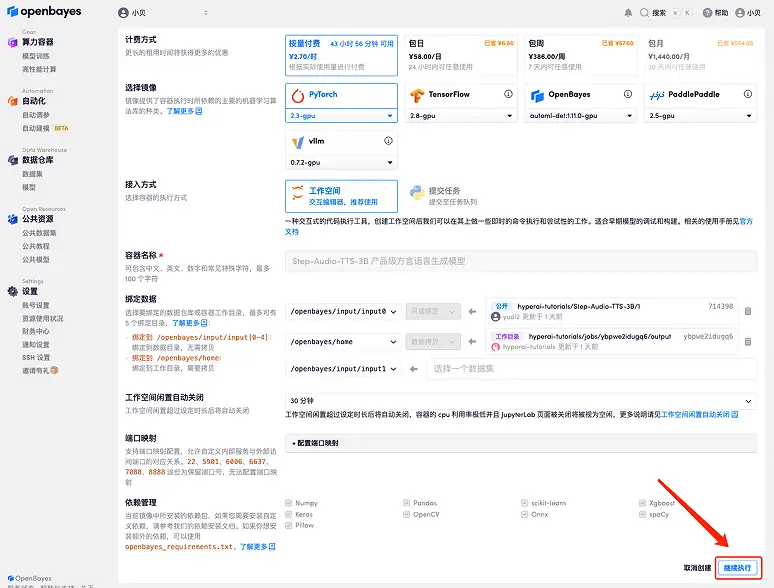
3. Wählen Sie die Bilder „NVIDIA RTX A6000“ und „PyTorch“ aus. Die OpenBayes-Plattform hat eine neue Abrechnungsmethode eingeführt. Sie können je nach Bedarf zwischen „Pay as you go“ oder „Tages-/Wochen-/Monatspaket“ wählen. Klicken Sie auf „Weiter“. Neue Benutzer können sich über den unten stehenden Einladungslink registrieren, um 4 Stunden RTX 4090 + 5 Stunden CPU-freie Zeit zu erhalten!
Exklusiver Einladungslink von HyperAI (kopieren und im Browser öffnen):
https://openbayes.com/console/signup?r=Ada0322_QZy7
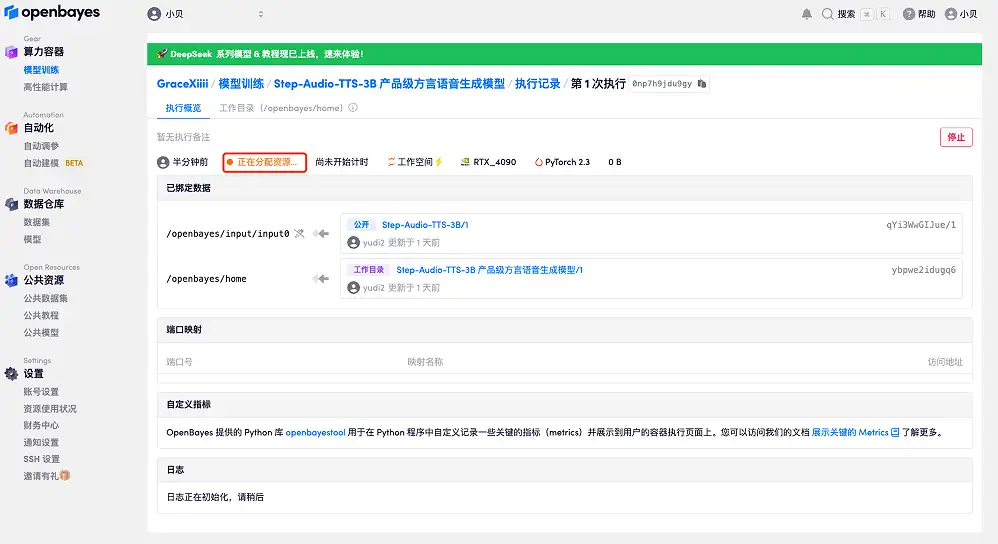
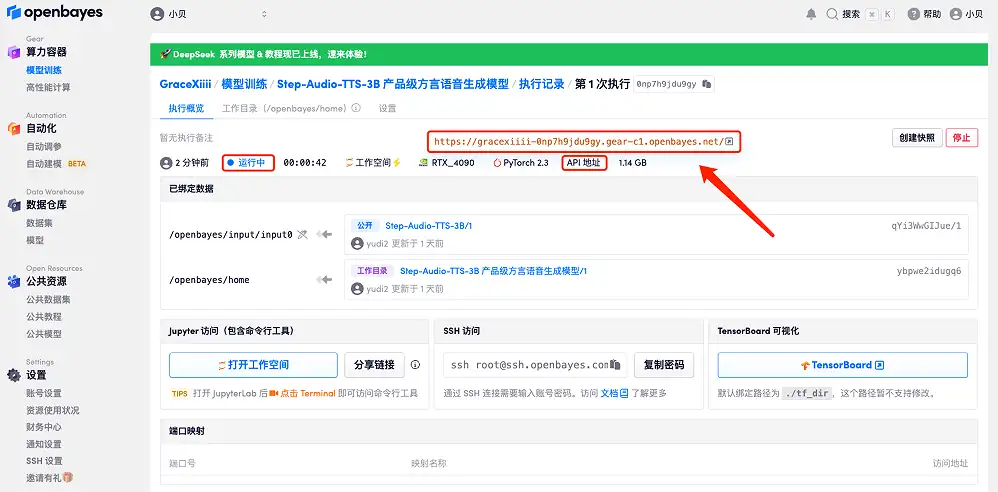
4. Warten Sie, bis die Ressourcen zugewiesen wurden. Der erste Klonvorgang dauert etwa 2 Minuten. Wenn sich der Status in „Läuft“ ändert, klicken Sie auf den Sprungpfeil neben „API-Adresse“, um zur Demoseite zu springen. Bitte beachten Sie, dass Benutzer vor der Verwendung der API-Adresszugriffsfunktion eine Echtnamenauthentifizierung durchführen müssen.

Effektanzeige
Dieses Tutorial umfasst drei Funktionen: allgemeine Sprachsynthese, Musiksynthese und Sprachklonen.
1. Allgemeine Sprachsynthese
Diese Funktion stellt den offiziellen Standard-Stimmcharakter Tingting und die neu hinzugefügte Stimme Nezha vorein und unterstützt die Generierung mehrerer Sprachen, Emotionen, Dialekte und andere Einstellungen.
Tonbeschreibung der Sprachsynthese
* Der Ton Tingting wird durch die offizielle 4s-Audio-Prompt-Datei generiert
* Der Ton von Nezha wird aus der 14-sekündigen Audio-Eingabeaufforderung „Ich bin Nezha, der dritte Prinz, ich bin hemmungslos und liebe es, Gedichte zu schreiben, ich gehe mit den Händen in den Taschen und kann eine kurvige Straße gerade machen“ generiert.
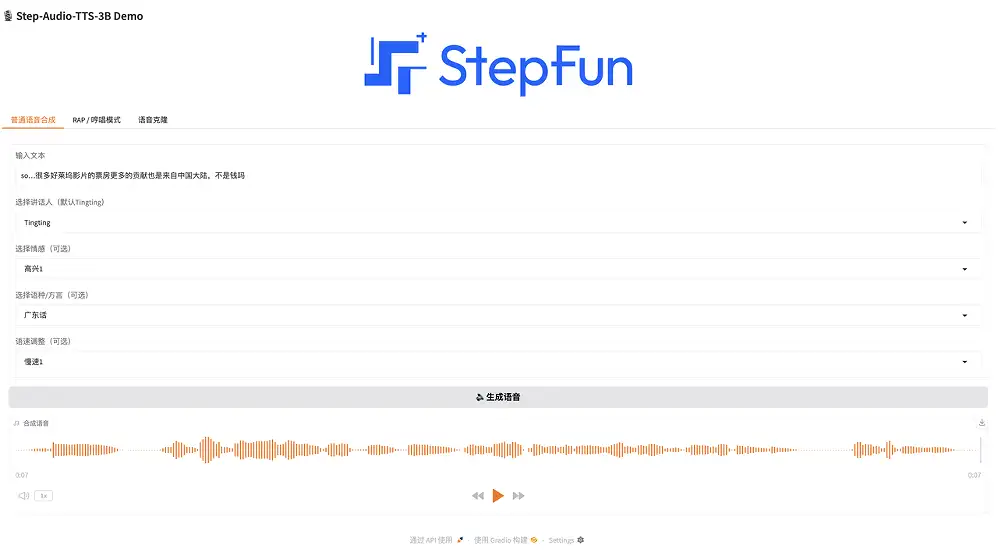
Wählen Sie auf der Demoseite „Normale Sprachsynthese“ aus, geben Sie Text ein, wählen Sie den Sprecher aus (Standard ist Tingting), wählen Sie die Emotion aus (glücklich, wütend, traurig und kokett), wählen Sie die Sprache/den Dialekt aus (Chinesisch, Englisch, Japanisch, Mandarin, Sichuanesisch, Kantonesisch und Guangdong-Dialekt) und wählen Sie die Sprechgeschwindigkeit (schnell oder langsam). Klicken Sie einfach auf „Sprache generieren“.
2. Musiksynthese
Diese Funktion stellt den Standard-Stimmcharakter Tingting der offiziellen Website und das neu hinzugefügte Nezha-Timbre vor und unterstützt RAP und Summen.
RAP-Soundbeschreibung
* Der Ton Tingting wird durch die offizielle 11s-Audio-Prompt-Datei generiert
* Der Ton von Nezha wird durch die 14-sekündige Audioaufforderung „Der Donner rollt und ich habe solche Angst, er trifft mich am ganzen Körper, ich blase die Trompete, um mein Schicksal zu ändern, ich lache, um das Unglück zu überstehen, tick-tick-tick-tick-tick“ erzeugt.
Summton Beschreibung
* Der Ton Tingting wird durch eine 12s lange Audio-Prompt-Datei generiert
* Der Ton von Nezha wird durch die 14-sekündige Audioaufforderung „Ich bin furchtlos geboren, egal wer mein Vater oder wer auch immer ist, wenn der Meister den Herrscher herausnimmt, wird er mir niemals Befehle erteilen können“ erzeugt.
Wählen Sie auf der Demoseite „Musiksynthese“, geben Sie den Text ein, wählen Sie den Lautsprecher aus (Standard ist Tingting) und wählen Sie den Modus (RAP oder Humming). Klicken Sie einfach auf „RAP/Humming generieren“.

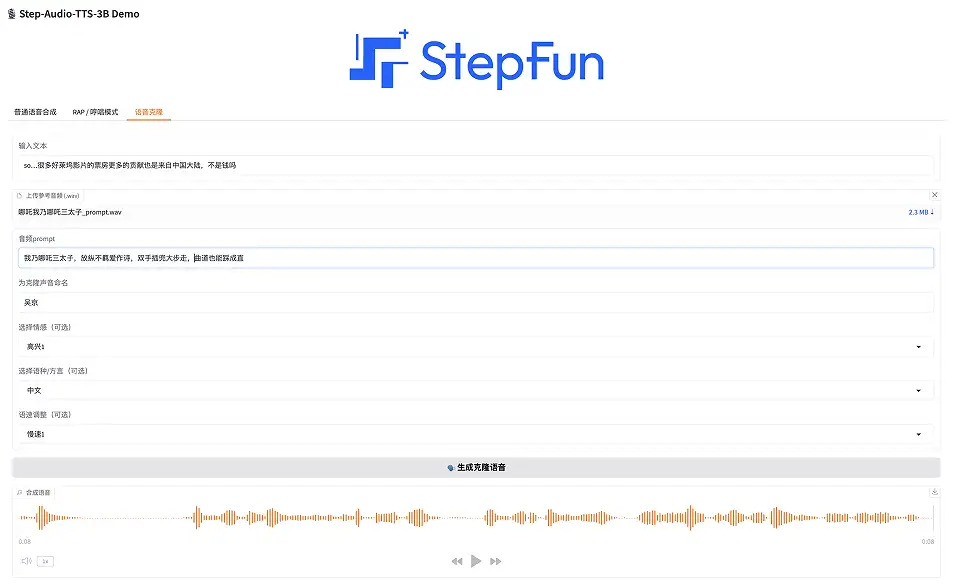
3. Stimmenklonen
Diese Funktion unterstützt Benutzer beim Hochladen von Audio mit benutzerdefinierter Klangfarbe und beim Generieren einer personalisierten Stimme.
Wählen Sie auf der Demoseite „Stimmklonen“ aus, geben Sie Text ein, laden Sie Referenzaudio hoch (WAV-Format), benennen Sie die geklonte Stimme, wählen Sie eine Emotion (glücklich, wütend, traurig und kokett), wählen Sie eine Sprache/einen Dialekt (Chinesisch, Englisch, Japanisch, Mandarin, Sichuanesisch, Kantonesisch und Guangdong-Dialekt) und wählen Sie eine Sprechgeschwindigkeit (schnell oder langsam). Klicken Sie einfach auf „Klonstimme generieren“.