Command Palette
Search for a command to run...
WenetSpeech-Chuan Sichuan-Chongqing Dialekt-Sprachdatensatz
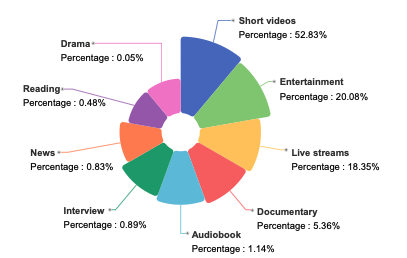
WenetSpeech-Chuan ist ein umfangreicher Sprachdatensatz im Sichuan-Chongqing-Dialekt, der 2025 von der Northwestern Polytechnical University in Zusammenarbeit mit Hillbeak, dem China Telecom Artificial Intelligence Research Institute und anderen Institutionen veröffentlicht wurde. Die zugehörige Forschungsarbeit trägt den Titel „WenetSpeech-Chuan: Ein umfangreiches Sichuan-Korpus mit reichhaltigen Annotationen für die Verarbeitung dialektaler Sprache". Dieser Datensatz umfasst 10.013 Stunden authentische Sprachaufnahmen aus den Dialekten Sichuan und Chongqing, darunter 3.714 Stunden stark annotierte und 6.299 Stunden schwach annotierte Daten. Die Daten decken neun reale Szenarien ab, wobei kurze Videos 52.831 TP3T ausmachen. Der Rest umfasst Unterhaltung, Live-Streaming, Hörbücher, Dokumentationen, Interviews, Nachrichten, Lesungen und Fernsehserien und bietet somit eine äußerst vielfältige und realistische Sprachverteilung. Alle Sprachaufnahmen sind mit umfangreichen Annotationsinformationen versehen, darunter Textinhalt, Konfidenzniveau, Sprachqualitätsbewertung, Geschlecht und Alter des Sprechers sowie Emotionskennzeichnungen.
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.