Command Palette
Search for a command to run...
Dicht Annotierter Datensatz Des Visuellen Genoms
Datum
Größe
Organisation
Veröffentlichungs-URL
Paper-URL
Lizenz
CC BY 4.0
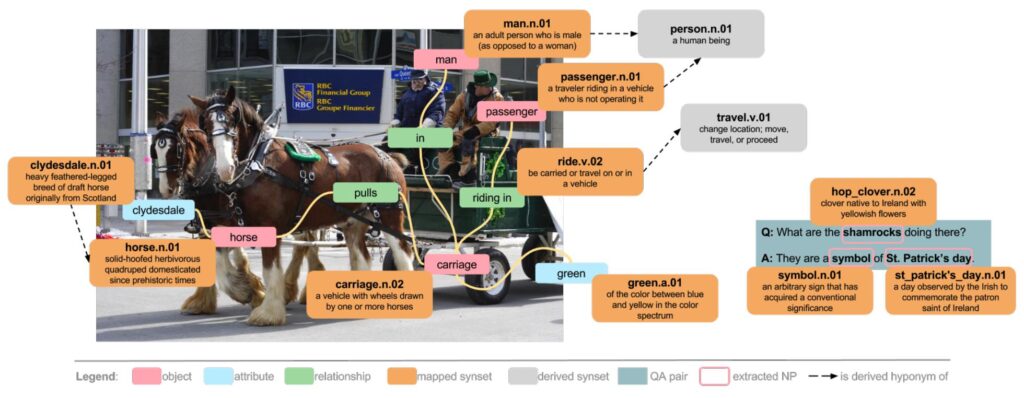
Der Visual Genome Dataset ist ein Datensatz, der Sprache und Sehen durch Crowdsourcing-basierte, dichte Bildannotation verbindet, einschließlich Visual Question Answering-Daten in einer Multiple-Choice-Umgebung. Der Datensatz besteht aus 1,7 Millionen QA-Paaren für 101.174 MSCOCO-Bilder mit durchschnittlich 17 Fragen pro Bild. Im Vergleich zum Visual Question Answering-Datensatz weist der Visual Genome-Datensatz eine ausgewogenere Verteilung von sechs Fragetypen auf: Was, Wo, Wann, Wer, Warum und Wie. Darüber hinaus präsentiert Visual Genome 108.000 Bilder, die dicht mit Objekten, Attributen und Beziehungen versehen sind.
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.