HyperAI
Command Palette
Search for a command to run...
IndexTTS-2:突破自回归 TTS 时长与情感控制瓶颈
一、教程简介

IndexTTS-2 是由哔哩哔哩语音团队于 2025 年 6 月开源的新型文本转语音(TTS)模型。模型在情感表达和时长控制方面实现了重大突破,是首个支持精确时长控制的自回归 TTS 模型。支持零样本声音克隆,仅需一个音频文件即可精准复制音色、节奏和说话风格,支持多语言。 IndexTTS-2 实现了情感音色分离控制,用户可以独立指定音色来源和情绪来源。模型具备多模态情感输入功能,支持通过情感参考音频、情感描述文本或情感向量来控制情感。相关论文成果为 IndexTTS2: A Breakthrough in Emotionally Expressive and Duration-Controlled Auto-Regressive Zero-Shot Text-to-Speech 。
该教程算力资源采用单卡 RTX 5090 。
二、效果展示
Same as the voice reference
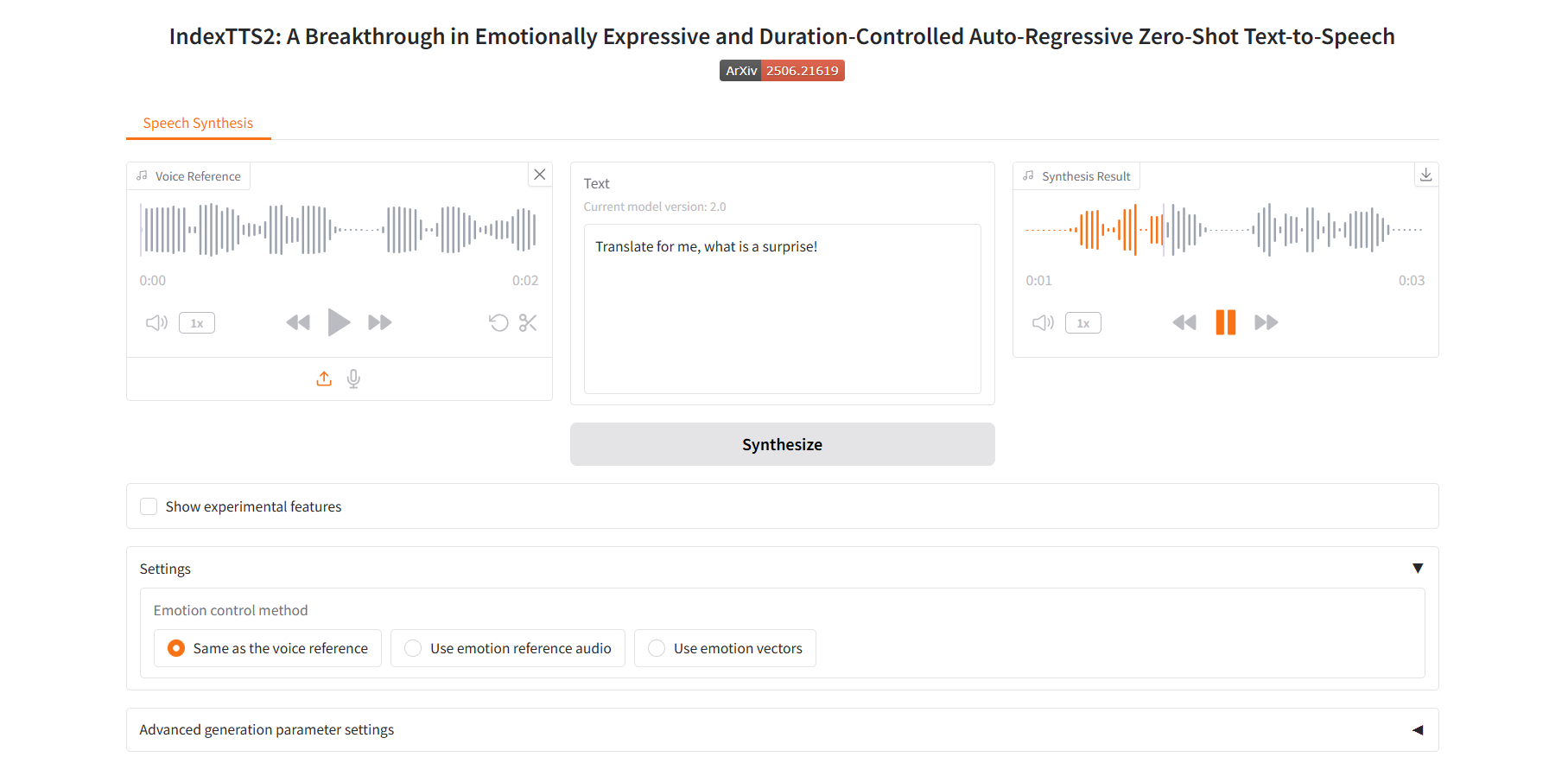
Use emotion reference audio
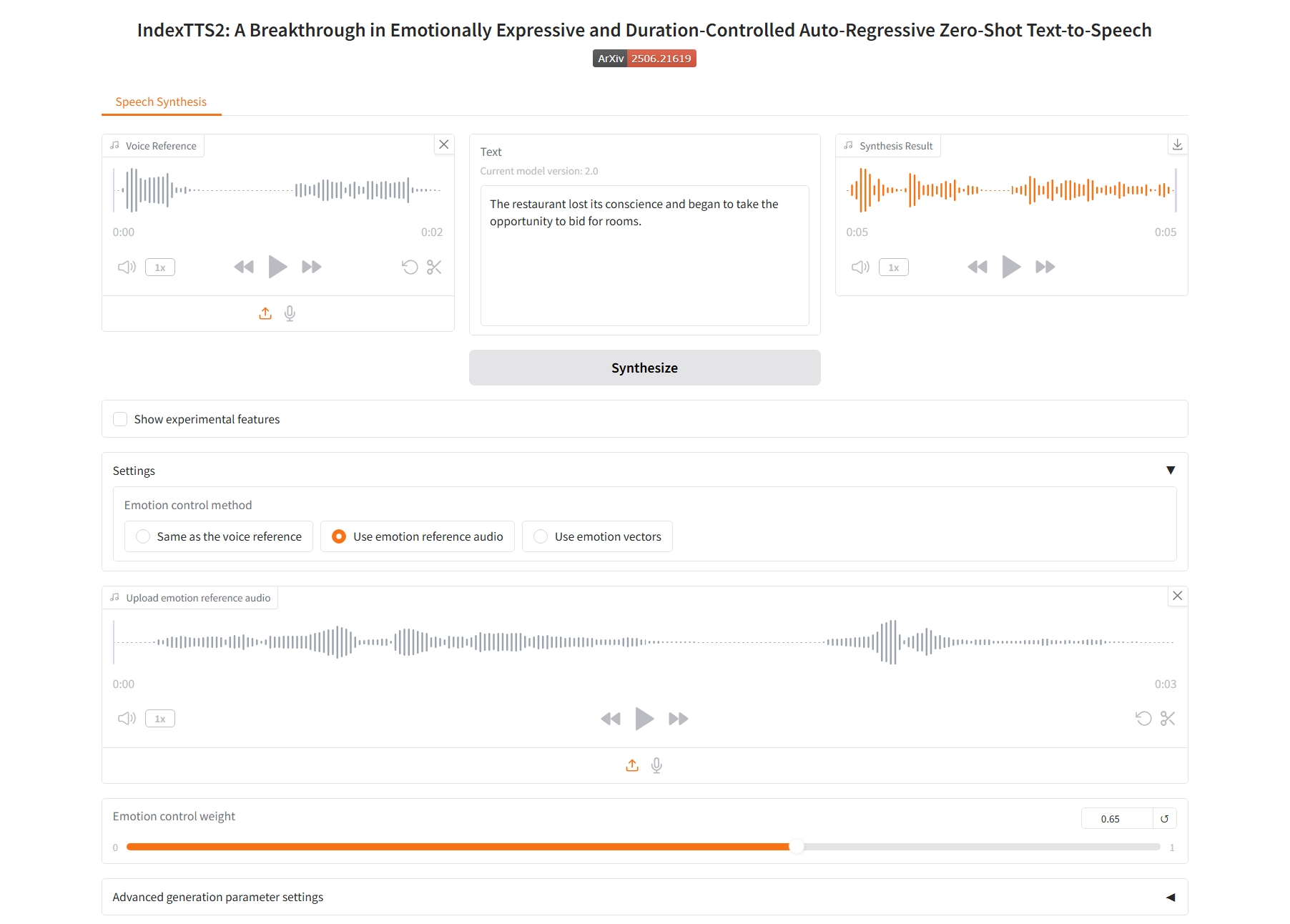
Use emotion vectors
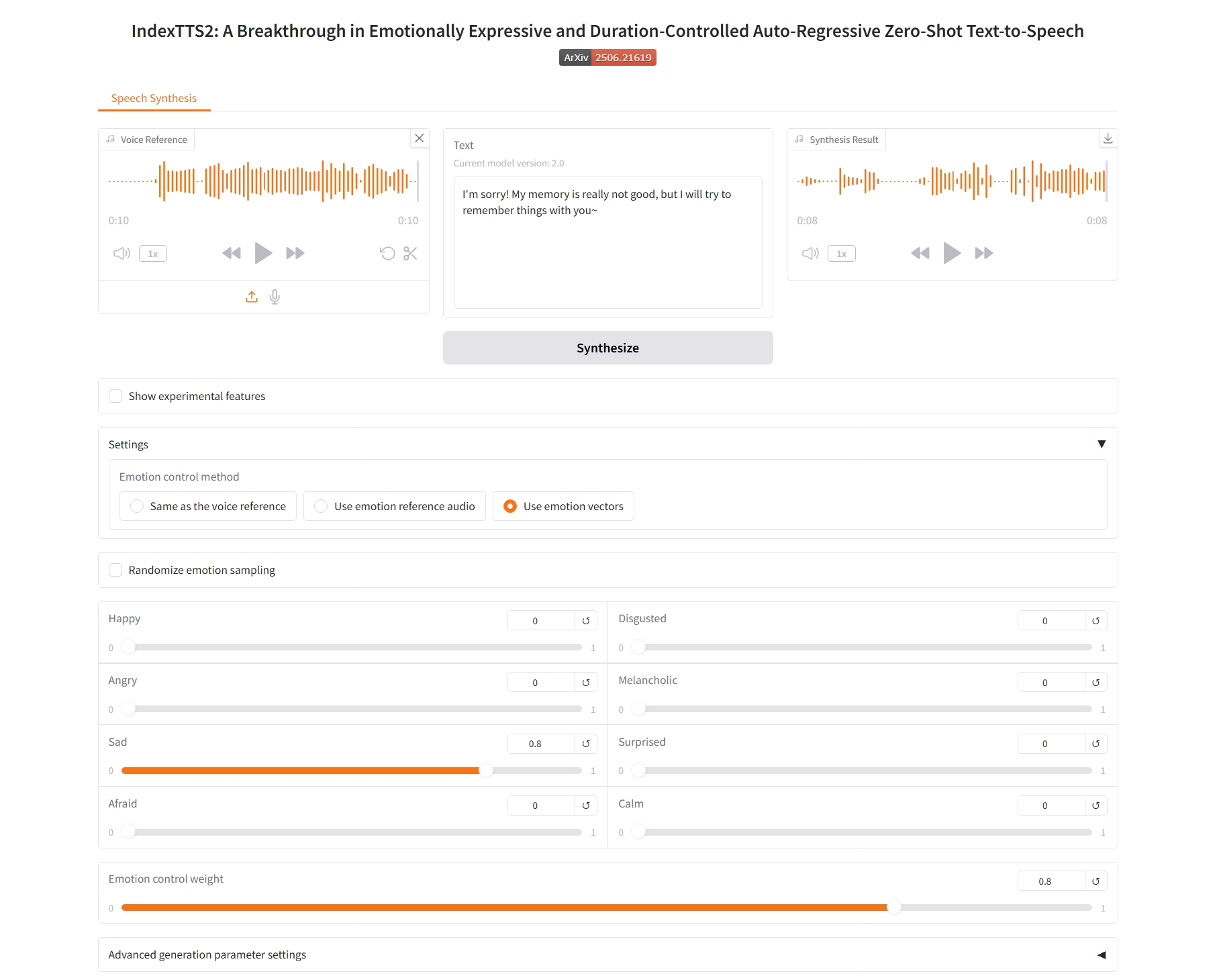
Use text description to control emotion
三、运行步骤
1. 启动容器
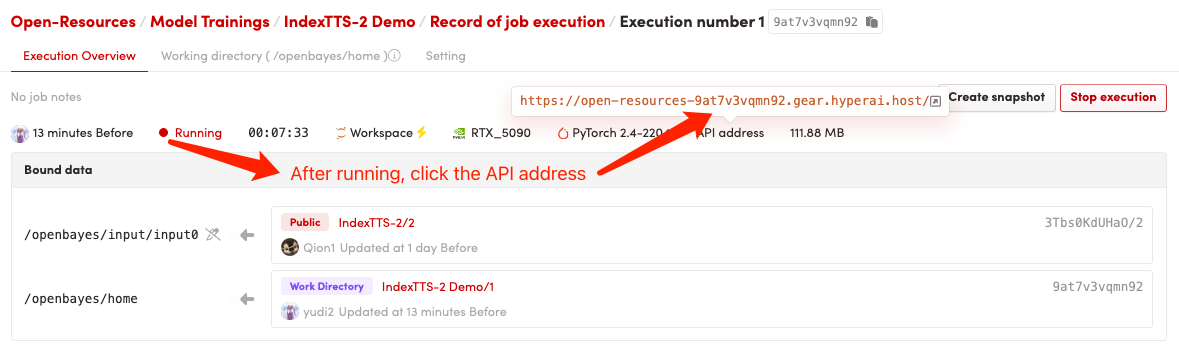
2. 使用步骤
若显示「Bad Gateway」,这表示模型正在初始化,由于模型较大,请等待约 2-3 分钟后刷新页面。
使用 Safari 浏览器时,音频可能无法直接播放,需要下载后进行播放。
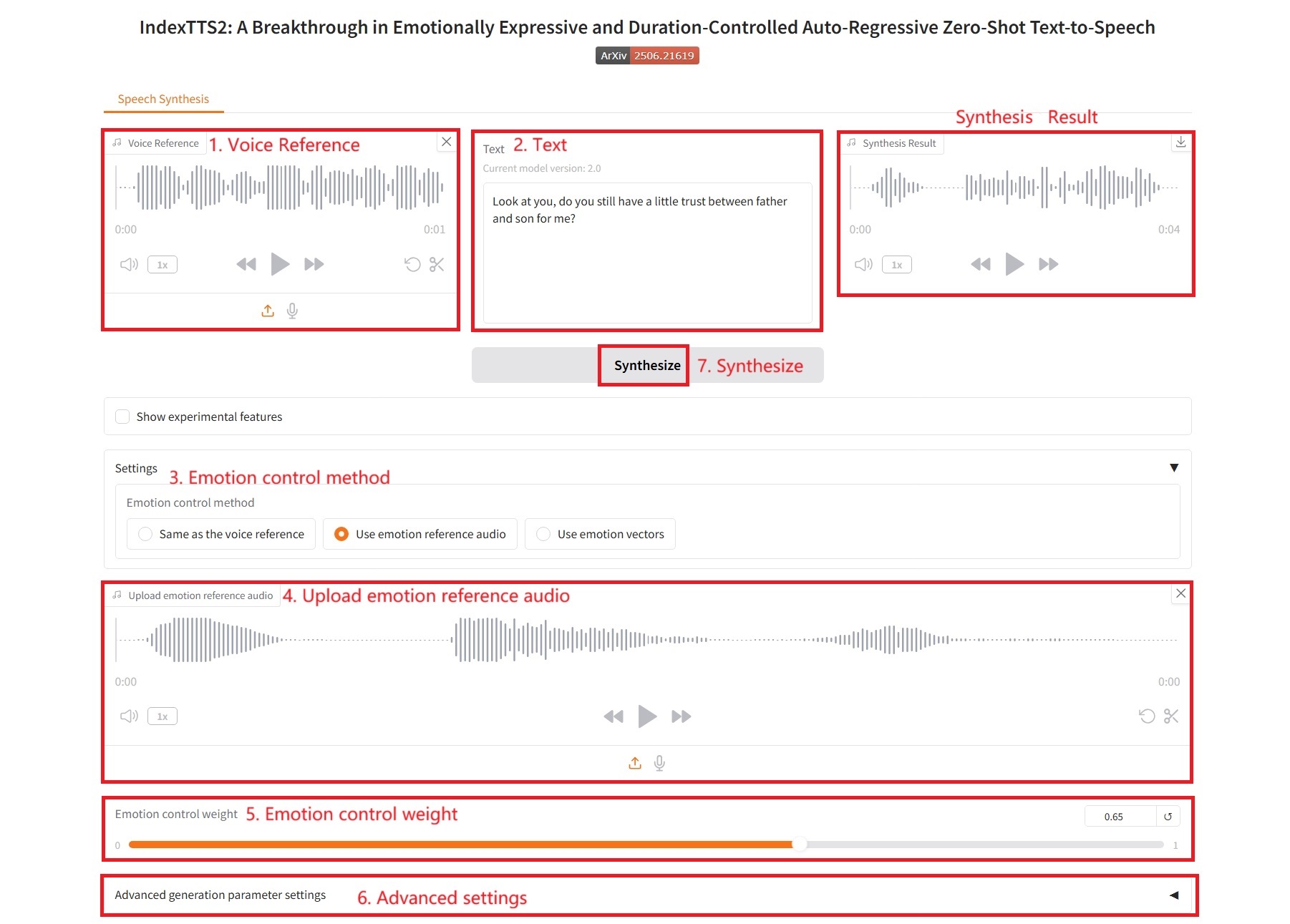
1. Same as the voice reference

具体参数:
- 高级参数设置:
- do_sample:是否进行采样。
- temperature:控制采样时概率分布的平滑程度。
- top_p:核采样,。
- top_k:在每一步生成时,只考虑概率最高的 K 个 token 。
- num_beams:束搜索宽度。
- repetition_penalty:重复惩罚,降低模型重复生成相同 token 的概率。
- length_penalty:长度惩罚,鼓励或抑制模型生成更长或更短的序列。主要在使用 num_beams > 1 时有效。
- max_mel_tokens:生成 Token 最大数量。
2. Use emotion reference audio
3. Use emotion vectors
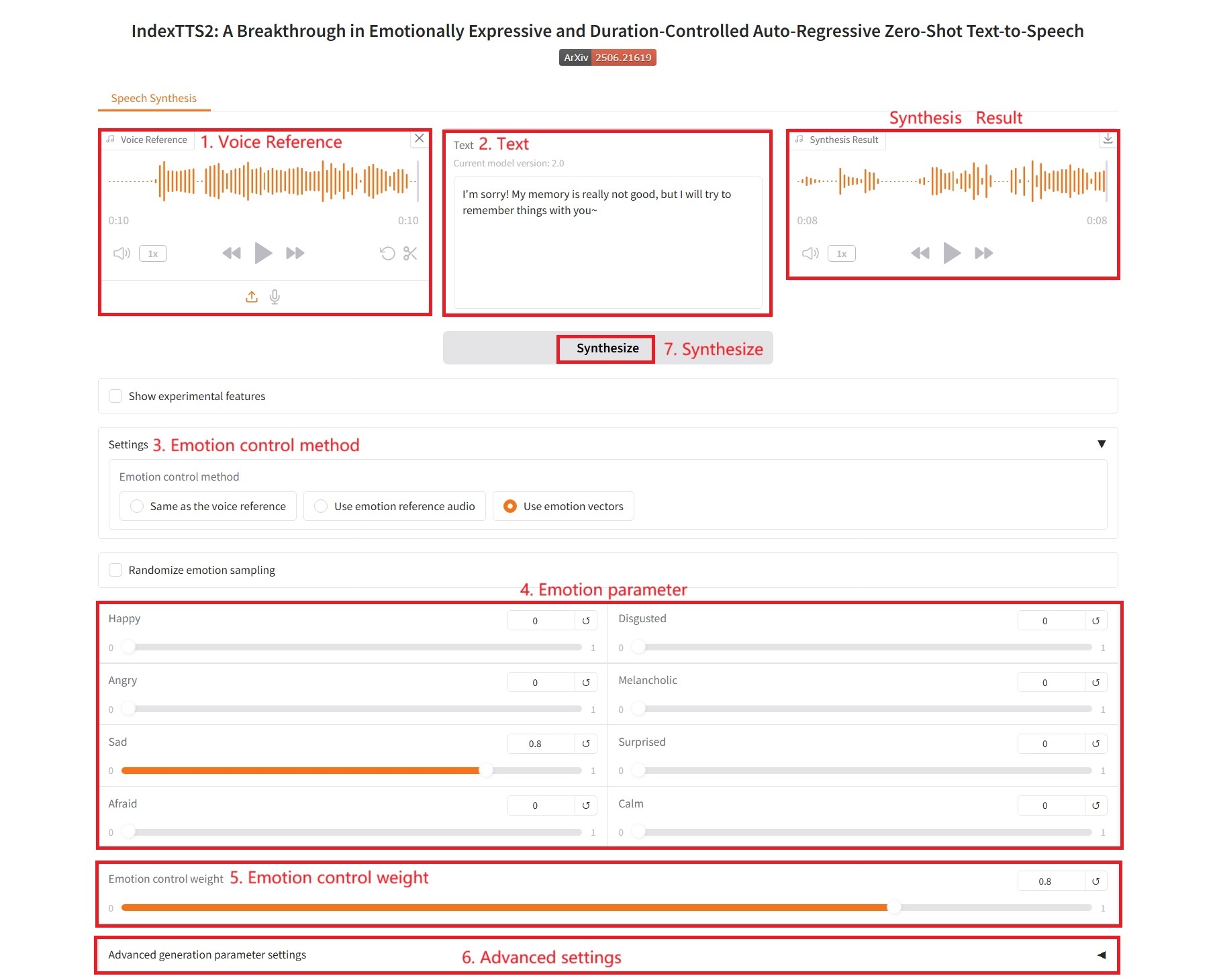
情感控制参数:
- Happy 、 Disgusted 、 Angry 、 Melancholic 、 Sad 、 Surprised 、 Afraid 、 Calm:分别对应 8 个基本情感维度。每个滑块的值(通常在 0.0 到 1.0 之间)表示希望在最终语音中体现该情感的强度。
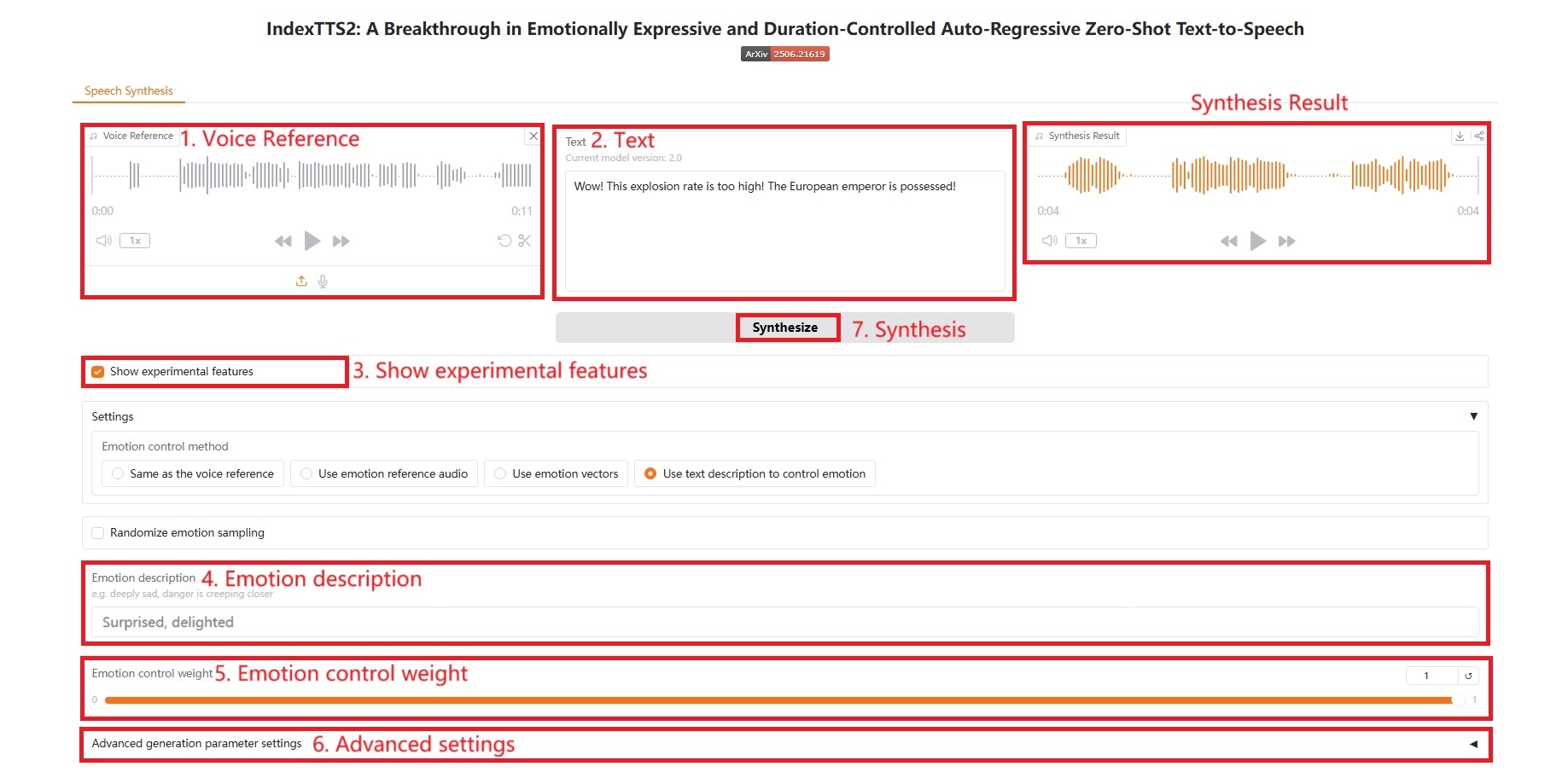
4. Use text description to control emotion
引用信息
本项目引用信息如下:
@article{zhou2025indextts2,
title={IndexTTS2: A Breakthrough in Emotionally Expressive and Duration-Controlled Auto-Regressive Zero-Shot Text-to-Speech},
author={Siyi Zhou, Yiquan Zhou, Yi He, Xun Zhou, Jinchao Wang, Wei Deng, Jingchen Shu},
journal={arXiv preprint arXiv:2506.21619},
year={2025}
}
@article{deng2025indextts,
title={IndexTTS: An Industrial-Level Controllable and Efficient Zero-Shot Text-To-Speech System},
author={Wei Deng, Siyi Zhou, Jingchen Shu, Jinchao Wang, Lu Wang},
journal={arXiv preprint arXiv:2502.05512},
year={2025},
doi={10.48550/arXiv.2502.05512},
url={https://arxiv.org/abs/2502.05512}
}本笔记本由社区用户贡献,仅用于教育和信息传播目的。如果任何内容涉及版权侵权,请通过 [email protected] 联系我们,我们将及时审核并删除。