HyperAI
Command Palette
Search for a command to run...
OpenAudio-s1-mini:高效 TTS 生成工具
一、教程简介

本教程采用资源为单卡 RTX 4090 。
二、项目示例
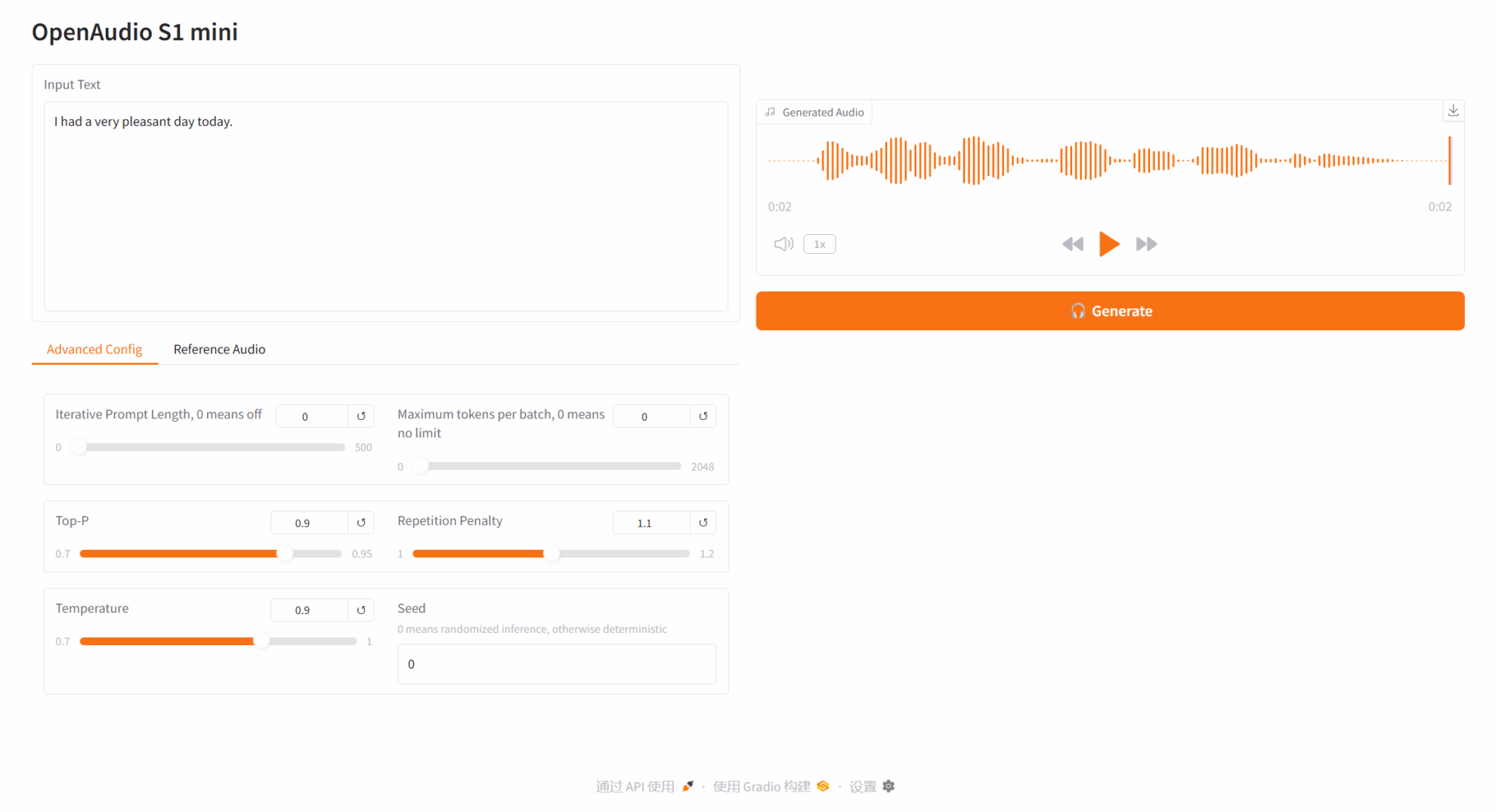
文本转语音

三、运行步骤
1. 启动容器后点击 API 地址即可进入 Web 界面
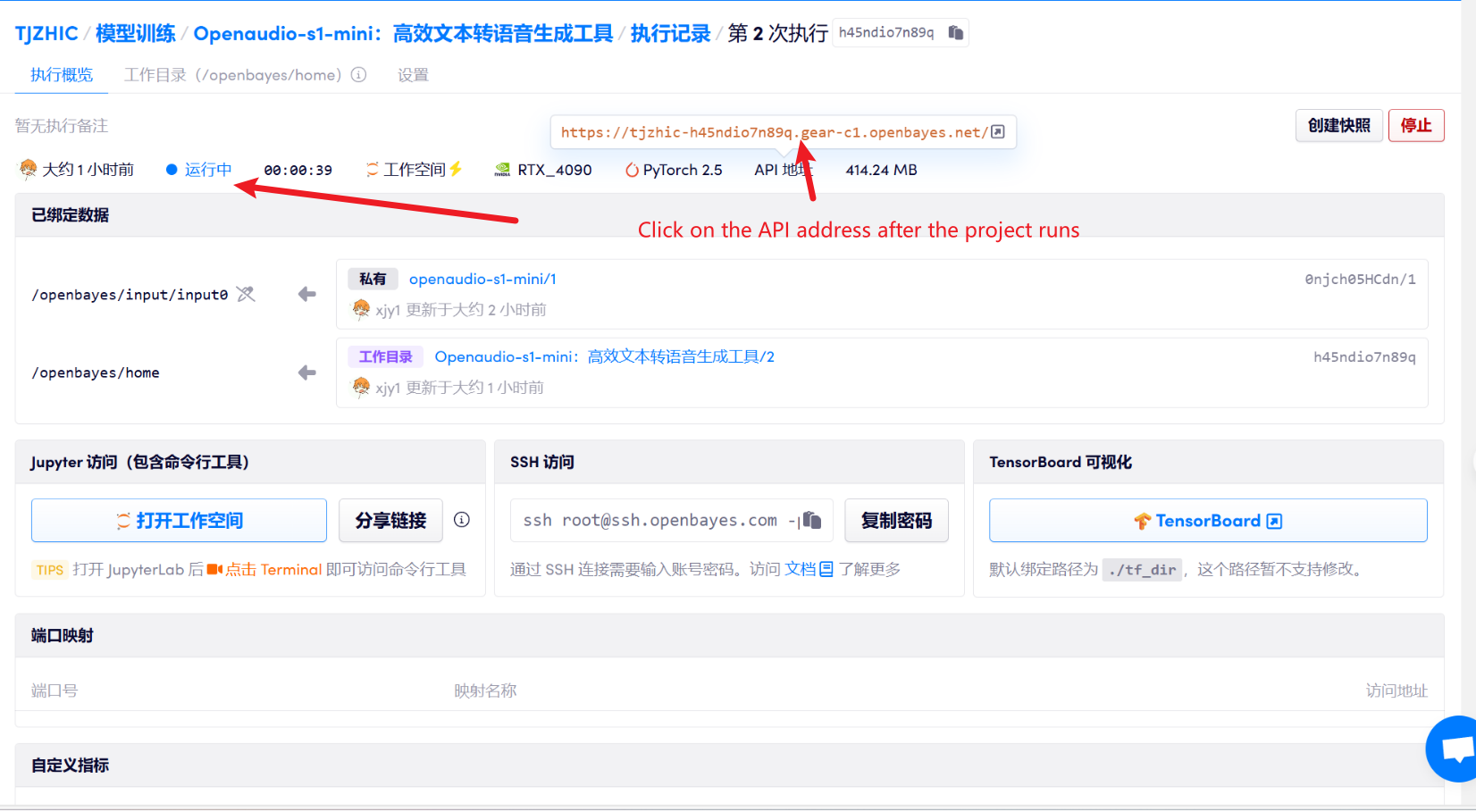
2. 进入网页后,即可使用模型
若显示「Bad Gateway」,这表示模型正在初始化,由于模型较大,请等待约 1-2 分钟后刷新页面。 使用 Safari 浏览器时,音频可能无法直接播放,需要下载后进行播放。
使用步骤
2.1 文本转音频
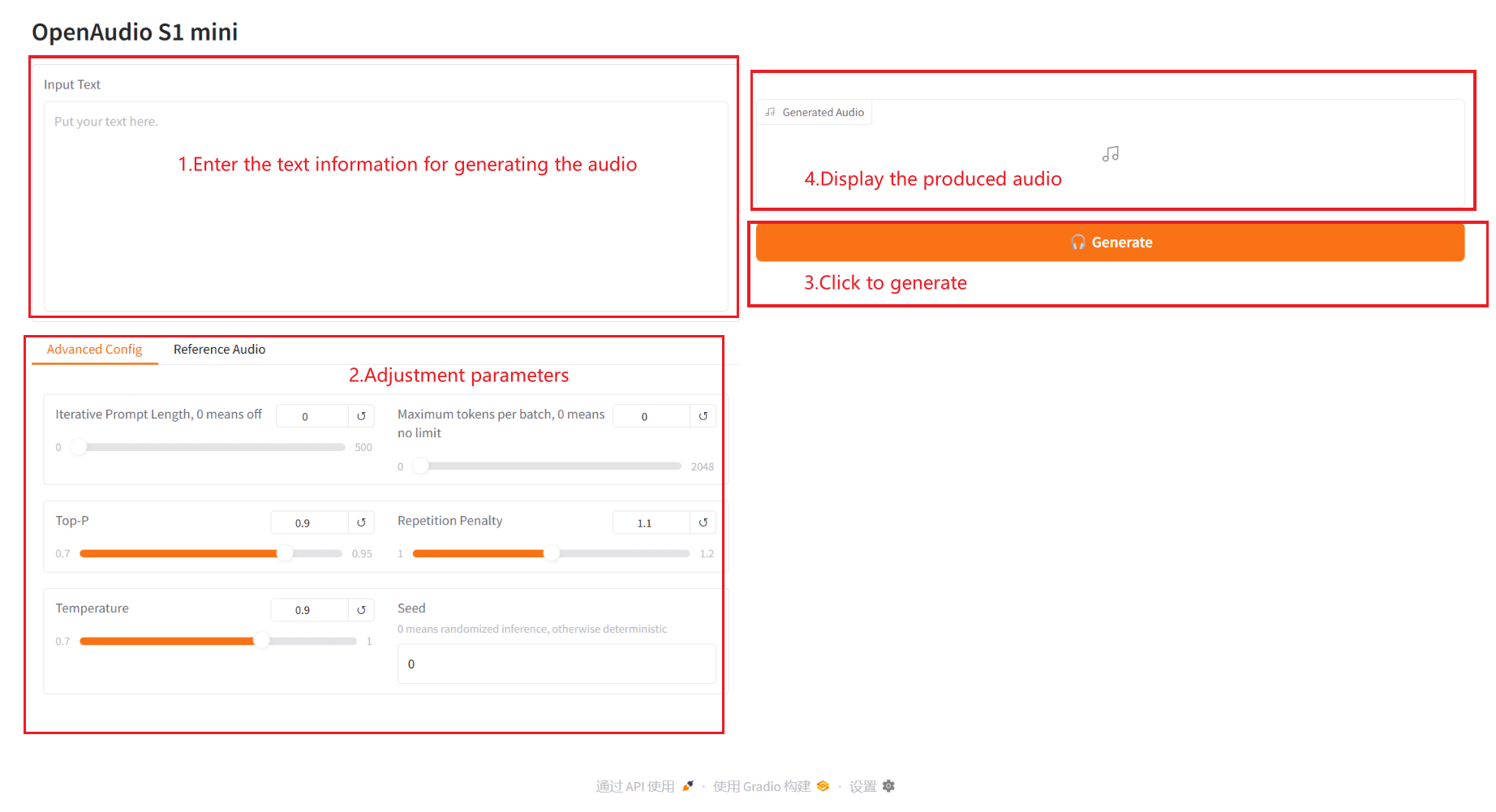
参数说明:
- Advanced Config:
- Iterative Prompt Length:迭代提示长度,0 表示关闭,非零值控制迭代生成语音时每次使用的提示文本长度。
- Maximum tokens per batch:每批次最大令牌数,0 表示无限制,非零值限制每批处理的最大令牌数。
- Top – P:核采样概率,控制生成文本的多样性和确定性。
- Repetition Penalty:重复惩罚系数,用于控制生成文本中重复内容的频率,值越大越避免重复。
- Temperature:温度系数,调节生成文本的随机性,值越大越随机。
- Seed:随机种子,用于固定随机数生成,保证结果可复现。
- Reference Audio:
- Use Memory Cache:选择是否使用内存缓存。
- Reference Audio:上传音频文件(wav 文件),是被用作参考的音色内容。
- Reference Text:输入上传的音频的文本内容。
四、交流探讨
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【SD 教程】入群探讨各类技术问题、分享应用效果↓

引用信息
本项目引用信息如下:
@misc{fish-speech-v1.4,
title={Fish-Speech: Leveraging Large Language Models for Advanced Multilingual Text-to-Speech Synthesis},
author={Shijia Liao and Yuxuan Wang and Tianyu Li and Yifan Cheng and Ruoyi Zhang and Rongzhi Zhou and Yijin Xing},
year={2024},
eprint={2411.01156},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2411.01156},
}
本笔记本由社区用户贡献,仅用于教育和信息传播目的。如果任何内容涉及版权侵权,请通过 [email protected] 联系我们,我们将及时审核并删除。