HyperAI
HyperAI
主区域
首页
GPU
控制台
文档
价格
Pulse
报道
资源
论文
教程
数据集
百科
基准测试
SOTA
大语言模型(LLM)
GPU 排行榜
社区
活动
开源
实用工具
搜索
关于
服务条款
隐私政策
中文
HyperAI
HyperAI
Toggle Sidebar
⌘
K
Command Palette
Search for a command to run...
登录
HyperAI
论文
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势
HyperAI
HyperAI
主区域
首页
GPU
控制台
文档
价格
Pulse
报道
资源
论文
教程
数据集
百科
基准测试
SOTA
大语言模型(LLM)
GPU 排行榜
社区
活动
开源
实用工具
搜索
关于
服务条款
隐私政策
中文
HyperAI
HyperAI
Toggle Sidebar
⌘
K
Command Palette
Search for a command to run...
登录
HyperAI
论文
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势
迈向自主数学研究
数学
LLM
Tony Feng, Trieu H. Trinh, Garrett Bingham, et al.
何时记忆,何时停止:面向长上下文推理的门控循环记忆
LLM
智能问答
Leheng Sheng, Yongtao Zhang, Wenchang Ma, et al.
ASA:面向工具调用领域适应的激活控制
智能问答
LLM
Youjin Wang, Run Zhou, Rong Fu, et al.
PhyCritic:面向物理AI的多模态批评者模型
多模态
视觉问答
Tianyi Xiong, Shihao Wang, Guilin Liu, et al.
GENIUS:生成式流体智能评估套件
多模态
统一多模态
Ruichuan An, Sihan Yang, Ziyu Guo, et al.
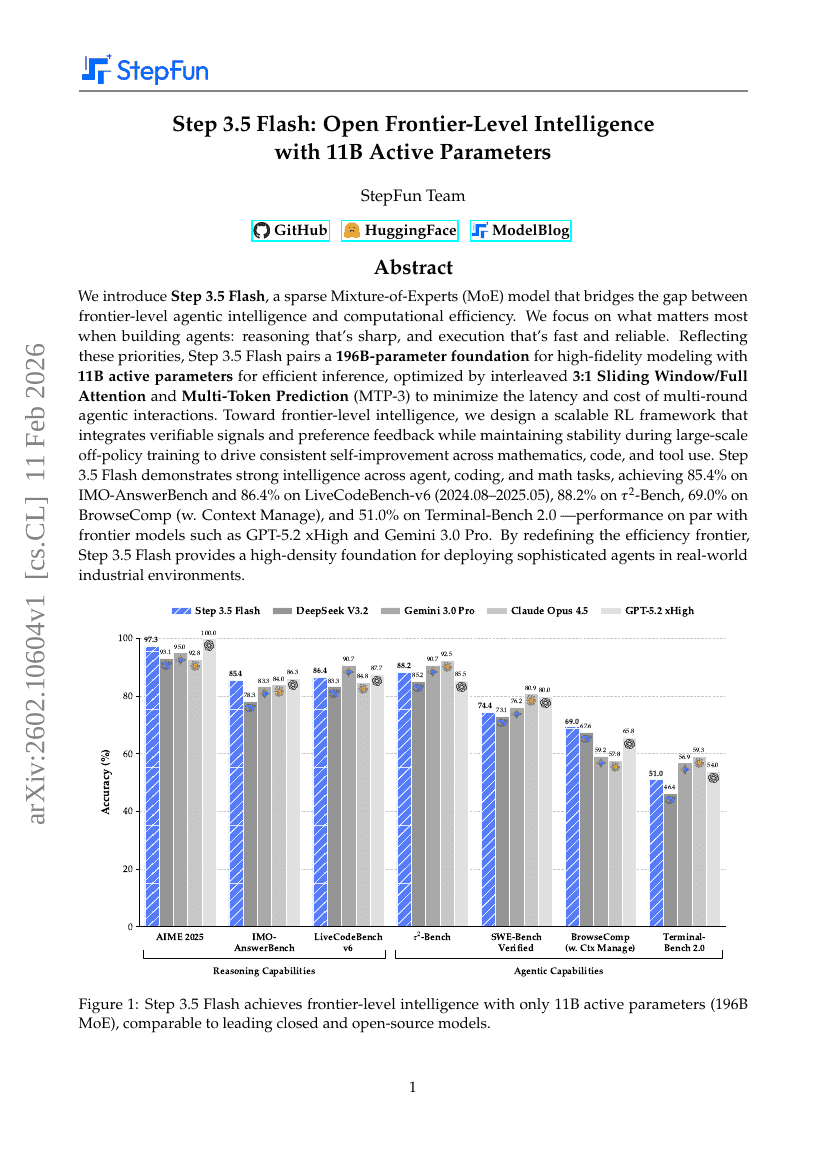
步骤 3.5 快闪:以 11B 激活参数开启前沿级智能
Agent
模型训练
Ailin Huang, Ang Li, Aobo Kong, et al.
世界-VLA-环:视频世界模型与VLA策略的闭环学习
扩散模型
视频生成
Xiaokang Liu, Zechen Bai, Hai Ci, et al.
迈向自主数学研究
数学
检索增强生成
Tony Feng, Trieu H. Trinh, Garrett Bingham, et al.
Agent世界模型:用于智能体强化学习的无限合成环境
Agent
LLM
Zhaoyang Wang, Canwen Xu, Boyi Liu, et al.
P1-VL:连接视觉感知与物理奥赛中的科学推理
多模态
多模态表征
Yun Luo, Futing Wang, Qianjia Cheng, et al.
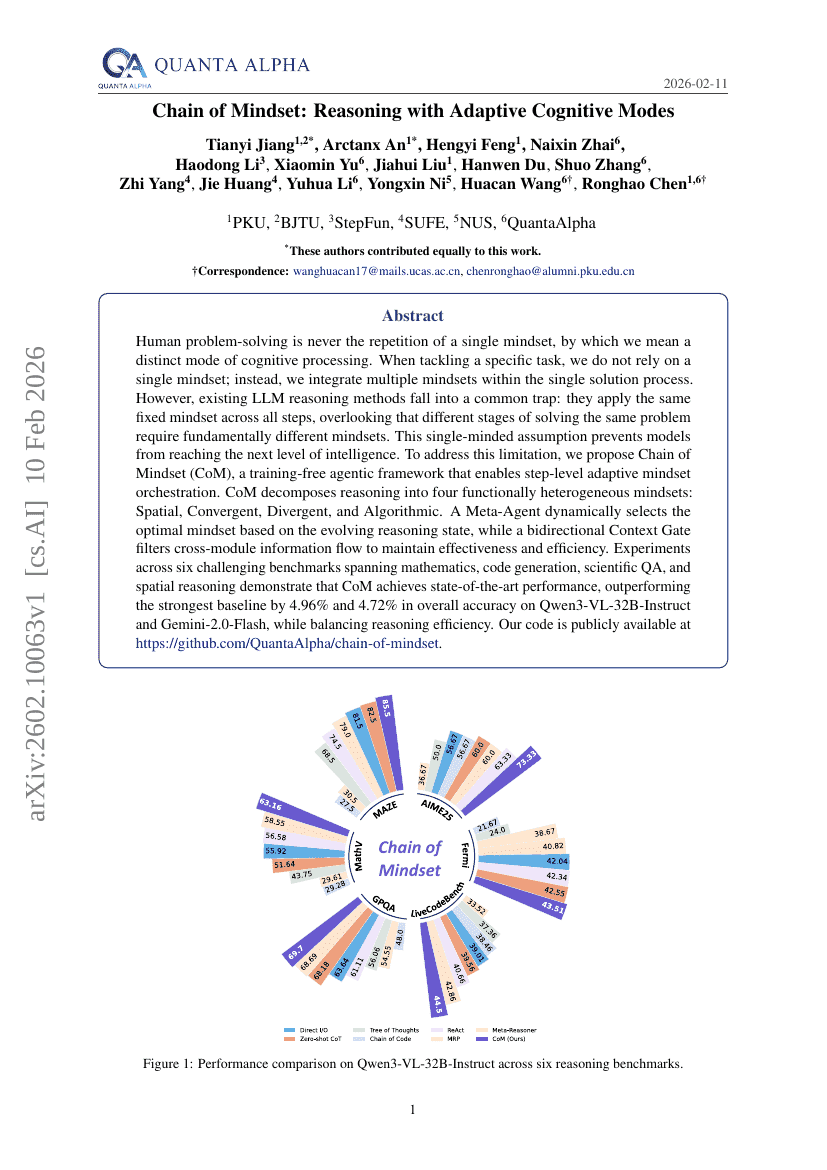
思维链:基于自适应认知模式的推理
Agent
推理
Tianyi Jiang, Arctanx An, Hengyi Feng, et al.
UI-Venus-1.5 技术报告
Agent
LLM
Veuns-Team, Changlong Gao, Zhangxuan Gu, et al.
Code2World:一种通过可渲染代码生成的GUI世界模型
代码生成
多模态
Yuhao Zheng, Li'an Zhong, Yi Wang, et al.
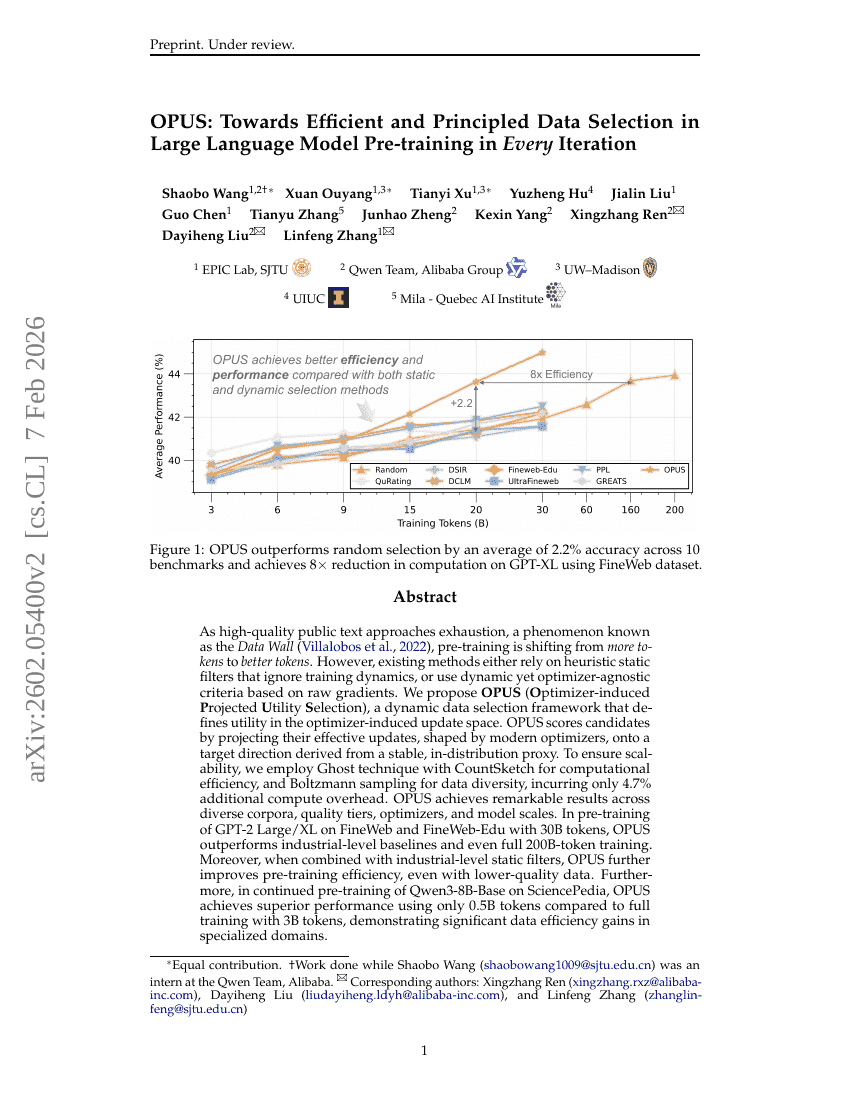
OPUS:面向大语言模型预训练中每轮迭代的高效且原则性数据选择
LLM
Transformer
Shaobo Wang, Xuan Ouyang, Tianyi Xu, et al.
BagelVLA:通过交错视觉-语言-动作生成提升长时程操作能力
Agent
统一多模态
Yucheng Hu, Jianke Zhang, Yuanfei Luo, et al.
THINGS-data,一个用于研究人类大脑与行为中物体表征的多模态大规模数据集
多模态表征
数据集
Martin N Hebart Oliver Contier, Lina Teichmann, Adam H Rockter, et al.
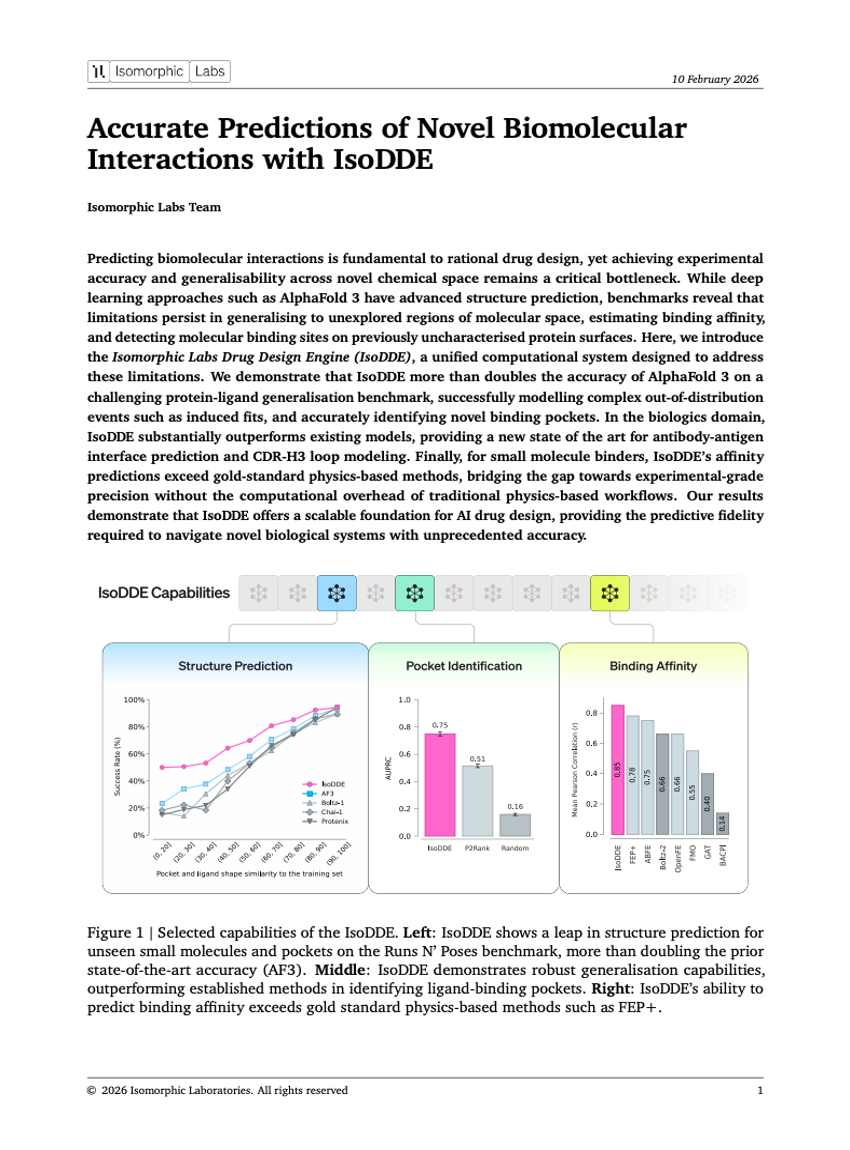
使用IsoDDE进行新型生物分子相互作用的精准预测
深度学习
AI for Science
Isomorphic Labs Team
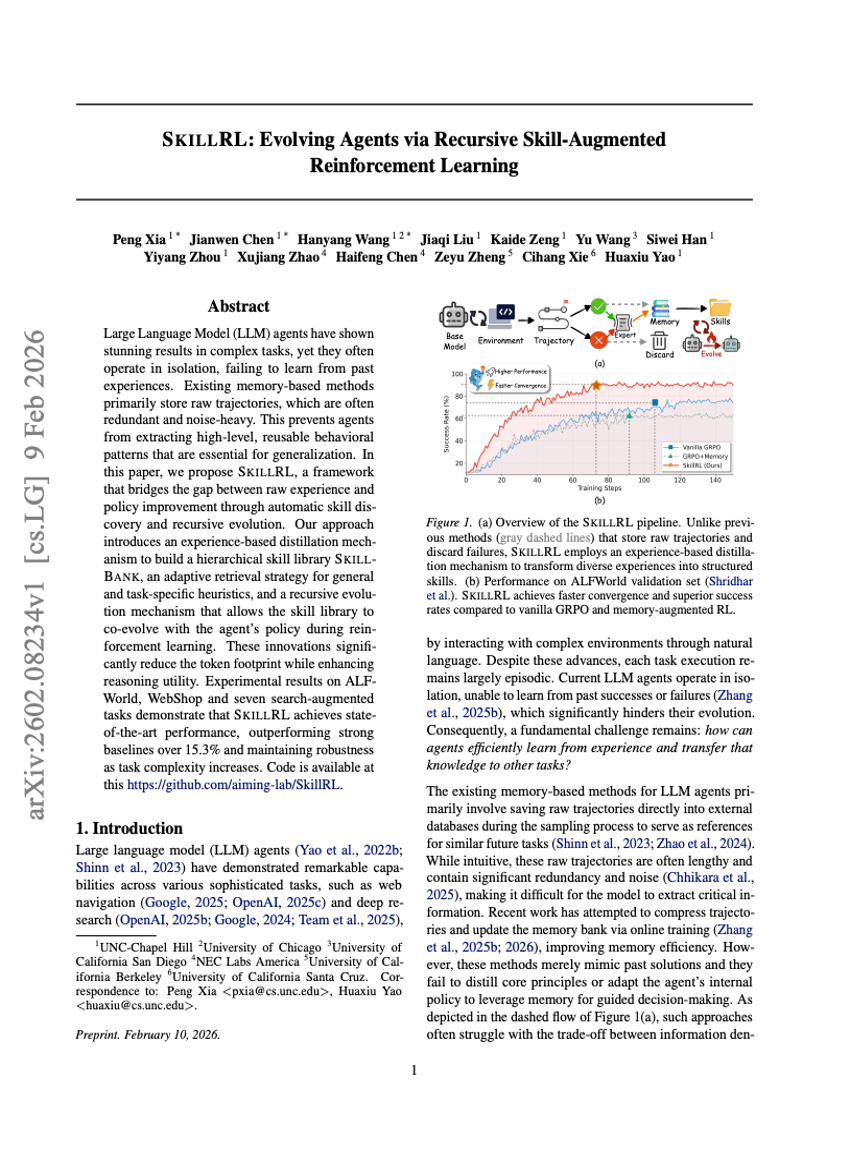
SkillRL:通过递归技能增强的强化学习进化Agent
强化学习
Agent
Peng Xia, Jianwen Chen, Hanyang Wang, et al.
LLaDA2.1:通过Token编辑加速文本扩散
扩散模型
LLM
Tiwei Bie, Maosong Cao, Xiang Cao, et al.
通过建模基于流的GRPO中的步骤级与长期采样效应缓解稀疏奖励问题
扩散模型
图像生成
Yunze Tong, Mushui Liu, Canyu Zhao, et al.
循环深度视觉-语言-动作模型:通过潜在迭代推理实现视觉-语言-动作模型的隐式测试时计算扩展
多模态
LLM
Yalcin Tur, Jalal Naghiyev, Haoquan Fang, et al.
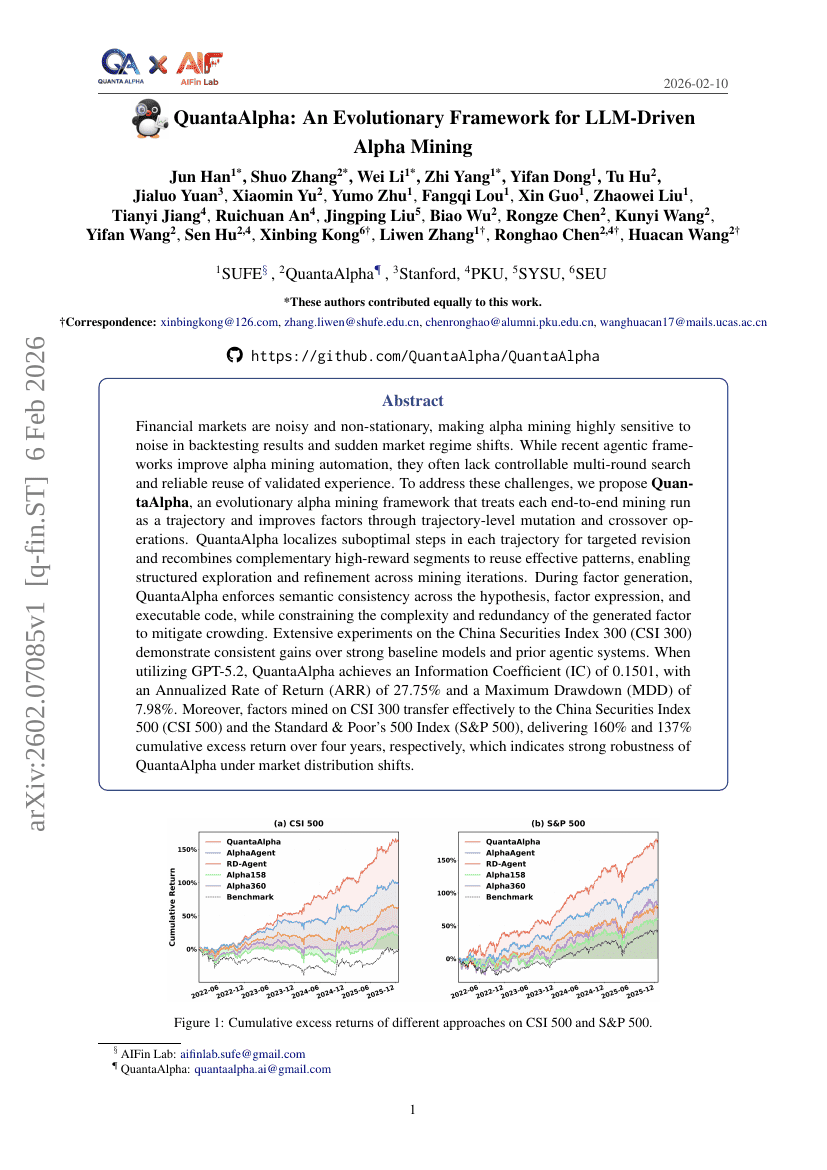
QuantaAlpha:一种面向LLM驱动的Alpha挖掘的进化框架
金融
LLM
Jun Han, Shuo Zhang, Wei Li, et al.
模态间隙驱动的子空间对齐训练范式用于多模态大语言模型
多模态
多模态表征
Xiaomin Yu, Yi Xin, Wenjie Zhang, et al.
MOVA:迈向可扩展且同步的视频-音频生成
视频生成
多模态
SII-OpenMOSS Team, Donghua Yu, Mingshu Chen, et al.
MemoryLLM:即插即用的可解释前馈记忆机制用于Transformer
Transformer
LLM
Ajay Jaiswal, Lauren Hannah, Han-Byul Kim, et al.
DreamDojo:基于大规模人类视频的通用机器人世界模型
多模态
视频理解
Shenyuan Gao, William Liang, Kaiyuan Zheng, et al.
F-GRPO:别让你的策略学习到显而易见的内容却遗忘稀有情况
强化学习
LLM
Daniil Plyusov, Alexey Gorbatovski, Boris Shaposhnikov, et al.
MSign:通过稳定秩恢复防止大语言模型训练不稳定的优化器
模型训练
LLM
Lianhai Ren, Yucheng Ding, Xiao Liu, et al.
AudioSAE:基于稀疏自编码器的音频处理模型理解
音频和语音处理
深度学习
Georgii Aparin, Tasnima Sadekova, Alexey Rukhovich, et al.
大型语言模型强化微调中的熵动态研究
强化学习
LLM
Shumin Wang, Yuexiang Xie, Wenhao Zhang, et al.
OdysseyArena:面向长时程、主动式与归纳性交互的大型语言模型基准测试
Agent
LLM
Fangzhi Xu, Hang Yan, Qiushi Sun, et al.
百川-M3:面向可靠医疗决策的临床问诊建模
LLM
医学
Baichuan-M3 Team, Chengfeng Dou, Fan Yang, et al.
1
2
3
4
50
迈向自主数学研究
数学
LLM
Tony Feng, Trieu H. Trinh, Garrett Bingham, et al.
何时记忆,何时停止:面向长上下文推理的门控循环记忆
LLM
智能问答
Leheng Sheng, Yongtao Zhang, Wenchang Ma, et al.
ASA:面向工具调用领域适应的激活控制
智能问答
LLM
Youjin Wang, Run Zhou, Rong Fu, et al.
PhyCritic:面向物理AI的多模态批评者模型
多模态
视觉问答
Tianyi Xiong, Shihao Wang, Guilin Liu, et al.
GENIUS:生成式流体智能评估套件
多模态
统一多模态
Ruichuan An, Sihan Yang, Ziyu Guo, et al.
步骤 3.5 快闪:以 11B 激活参数开启前沿级智能
Agent
模型训练
Ailin Huang, Ang Li, Aobo Kong, et al.
世界-VLA-环:视频世界模型与VLA策略的闭环学习
扩散模型
视频生成
Xiaokang Liu, Zechen Bai, Hai Ci, et al.
迈向自主数学研究
数学
检索增强生成
Tony Feng, Trieu H. Trinh, Garrett Bingham, et al.
Agent世界模型:用于智能体强化学习的无限合成环境
Agent
LLM
Zhaoyang Wang, Canwen Xu, Boyi Liu, et al.
P1-VL:连接视觉感知与物理奥赛中的科学推理
多模态
多模态表征
Yun Luo, Futing Wang, Qianjia Cheng, et al.
思维链:基于自适应认知模式的推理
Agent
推理
Tianyi Jiang, Arctanx An, Hengyi Feng, et al.
UI-Venus-1.5 技术报告
Agent
LLM
Veuns-Team, Changlong Gao, Zhangxuan Gu, et al.
Code2World:一种通过可渲染代码生成的GUI世界模型
代码生成
多模态
Yuhao Zheng, Li'an Zhong, Yi Wang, et al.
OPUS:面向大语言模型预训练中每轮迭代的高效且原则性数据选择
LLM
Transformer
Shaobo Wang, Xuan Ouyang, Tianyi Xu, et al.
BagelVLA:通过交错视觉-语言-动作生成提升长时程操作能力
Agent
统一多模态
Yucheng Hu, Jianke Zhang, Yuanfei Luo, et al.
THINGS-data,一个用于研究人类大脑与行为中物体表征的多模态大规模数据集
多模态表征
数据集
Martin N Hebart Oliver Contier, Lina Teichmann, Adam H Rockter, et al.
使用IsoDDE进行新型生物分子相互作用的精准预测
深度学习
AI for Science
Isomorphic Labs Team
SkillRL:通过递归技能增强的强化学习进化Agent
强化学习
Agent
Peng Xia, Jianwen Chen, Hanyang Wang, et al.
LLaDA2.1:通过Token编辑加速文本扩散
扩散模型
LLM
Tiwei Bie, Maosong Cao, Xiang Cao, et al.
通过建模基于流的GRPO中的步骤级与长期采样效应缓解稀疏奖励问题
扩散模型
图像生成
Yunze Tong, Mushui Liu, Canyu Zhao, et al.
循环深度视觉-语言-动作模型:通过潜在迭代推理实现视觉-语言-动作模型的隐式测试时计算扩展
多模态
LLM
Yalcin Tur, Jalal Naghiyev, Haoquan Fang, et al.
QuantaAlpha:一种面向LLM驱动的Alpha挖掘的进化框架
金融
LLM
Jun Han, Shuo Zhang, Wei Li, et al.
模态间隙驱动的子空间对齐训练范式用于多模态大语言模型
多模态
多模态表征
Xiaomin Yu, Yi Xin, Wenjie Zhang, et al.
MOVA:迈向可扩展且同步的视频-音频生成
视频生成
多模态
SII-OpenMOSS Team, Donghua Yu, Mingshu Chen, et al.
MemoryLLM:即插即用的可解释前馈记忆机制用于Transformer
Transformer
LLM
Ajay Jaiswal, Lauren Hannah, Han-Byul Kim, et al.
DreamDojo:基于大规模人类视频的通用机器人世界模型
多模态
视频理解
Shenyuan Gao, William Liang, Kaiyuan Zheng, et al.
F-GRPO:别让你的策略学习到显而易见的内容却遗忘稀有情况
强化学习
LLM
Daniil Plyusov, Alexey Gorbatovski, Boris Shaposhnikov, et al.
MSign:通过稳定秩恢复防止大语言模型训练不稳定的优化器
模型训练
LLM
Lianhai Ren, Yucheng Ding, Xiao Liu, et al.
AudioSAE:基于稀疏自编码器的音频处理模型理解
音频和语音处理
深度学习
Georgii Aparin, Tasnima Sadekova, Alexey Rukhovich, et al.
大型语言模型强化微调中的熵动态研究
强化学习
LLM
Shumin Wang, Yuexiang Xie, Wenhao Zhang, et al.
OdysseyArena:面向长时程、主动式与归纳性交互的大型语言模型基准测试
Agent
LLM
Fangzhi Xu, Hang Yan, Qiushi Sun, et al.
百川-M3:面向可靠医疗决策的临床问诊建模
LLM
医学
Baichuan-M3 Team, Chengfeng Dou, Fan Yang, et al.
1
2
3
4
50