Command Palette
Search for a command to run...
在线教程丨最高 4 倍生成速度提升,DiffusionGemma 可同时生成整块文本,基于多轮并行去噪持续优化结果

6 月 11 日,Google 正式开源了基于离散扩散(Discrete Diffusion)技术构建的文本生成模型 DiffusionGemma 。其基于 Gemma 4 系列领先行业的「参数效率智能性」(intelligence-per-parameter)以及前沿的 Gemini Diffusion 研究成果打造,并集成了全新的扩散解码头(Diffusion Head),以最大化生成速度。与传统大模型逐 Token 输出文本不同,其能够同时生成整个文本块,并通过多轮并行去噪不断优化结果,从而实现最高 4 倍的生成速度提升。
官方数据显示,DiffusionGemma 在单张 NVIDIA H100 GPU 上可实现超过 1100 Token/s 的生成速度,在 GeForce RTX 5090 上也能达到 700 Token/s 以上,远超同级别自回归模型。
从架构来看,DiffusionGemma 采用 26B 参数级别的混合专家(MoE)设计,总参数量约为 252 亿,但推理过程中仅激活 3.8B 参数,在保持较强推理能力的同时显著降低计算开销。模型基于编码器-解码器结构构建,结合双向注意力机制,能够一次并行处理 256 个 Token,并支持文本内联编辑、代码补全、数学结构生成等对全局上下文依赖较强的任务。
此外,DiffusionGemma 还支持最高 256K Token 长上下文、多模态图文输入以及通过 <|think|> 激活的推理模式,为开发者探索新一代高效率 AI 应用提供了全新的技术选择。
尽管 Google 仍强调标准版 Gemma 4 在生成质量上更适合作为生产环境方案,但 DiffusionGemma 所展示的扩散式文本生成能力,或许正在为大语言模型的发展打开另一条值得关注的新路线。
为了便于开发者低门槛体验 DiffusionGemma,HyperAI 在模型开源后快速跟进,目前已经上线了易于部署的 Notebook,基于单卡 NVIDIA RTX Pro 6000 即可验证模型强大能力。
在线运行:https://go.hyper.ai/879dB
更多在线教程:
Demo 运行
1. 进入 hyper.ai 首页后,选择「教程」页面,或点击「查看更多教程」,选择「DiffusionGemma:基于离散扩散的高速文本生成模型」,点击「运行此教程」。
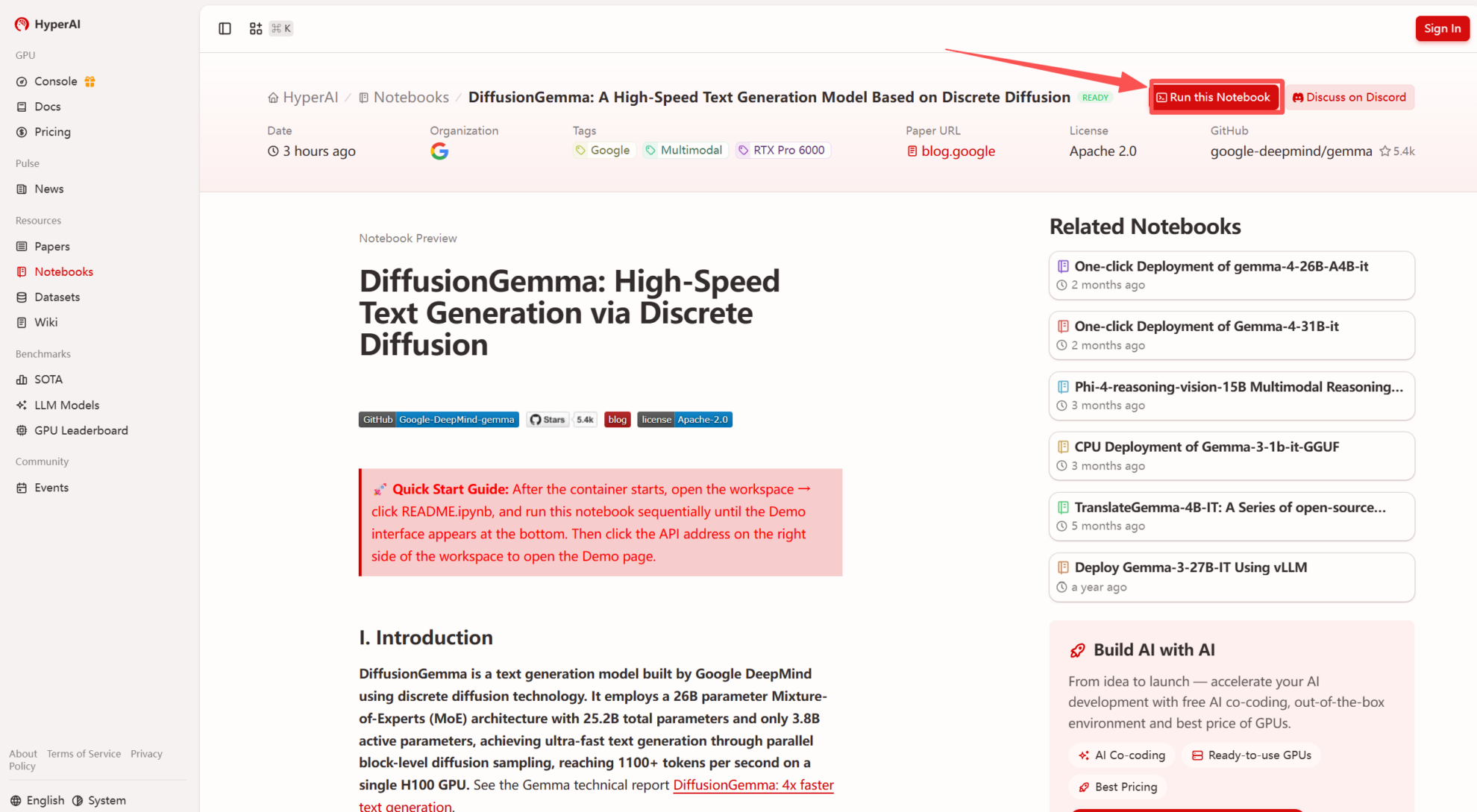
2. 页面跳转后,点击右上角「Clone」,将该教程克隆至自己的容器中。
注:页面右上角支持切换语言,目前提供中文及英文两种语言,本教程文章以英文为例进行步骤展示。
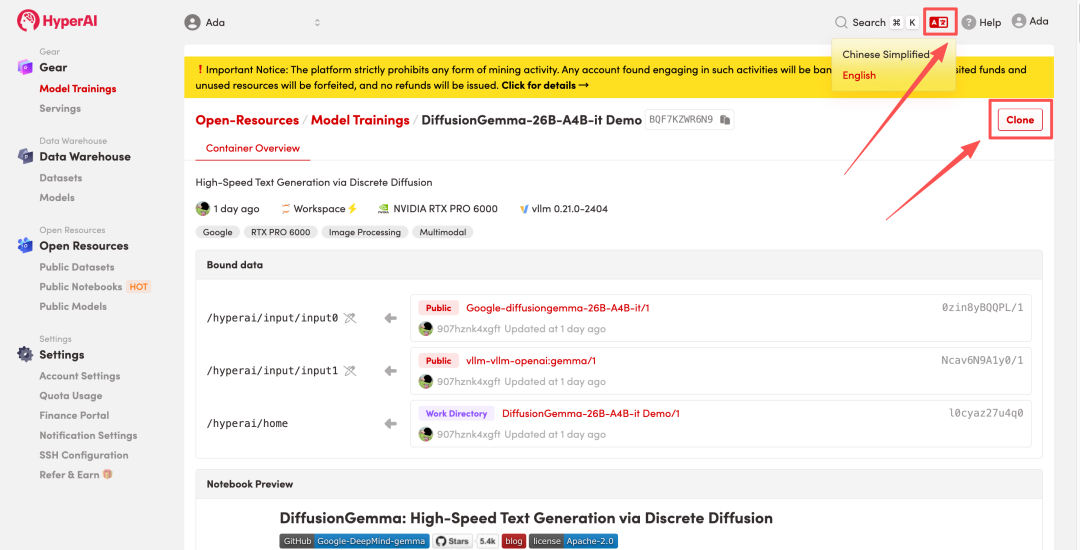
3. 选择「NVIDIA RTX Pro 6000」以及「vLLM」镜像,点击「Continue job execution(继续执行)」。
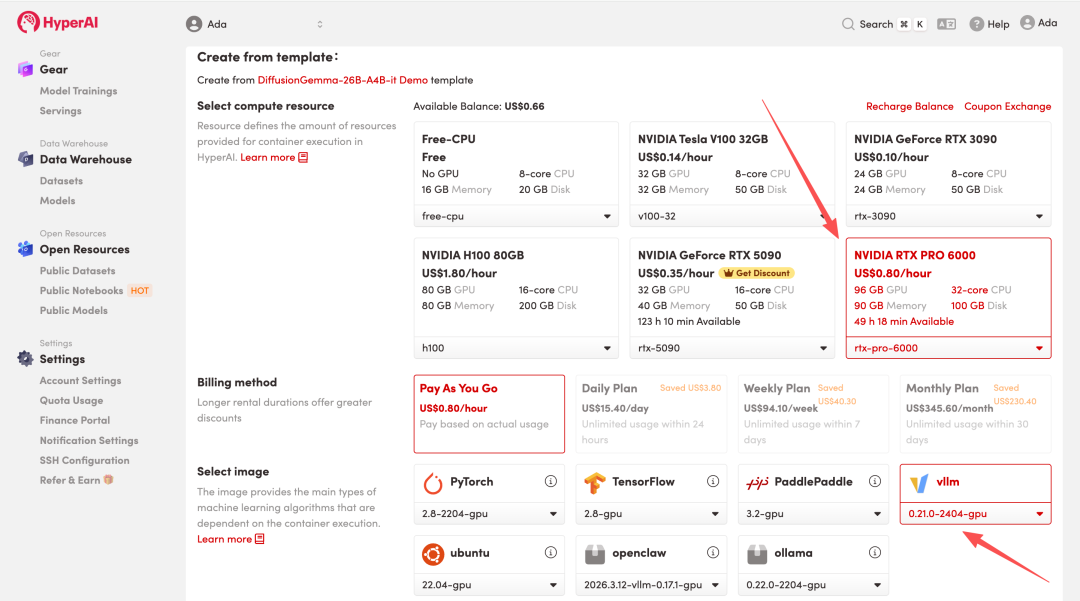
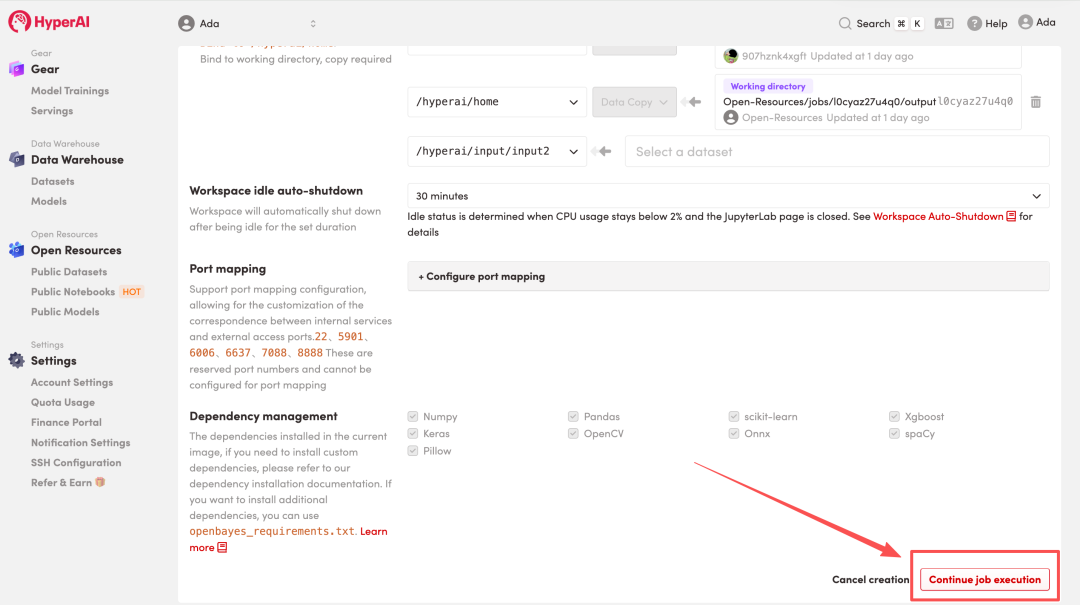
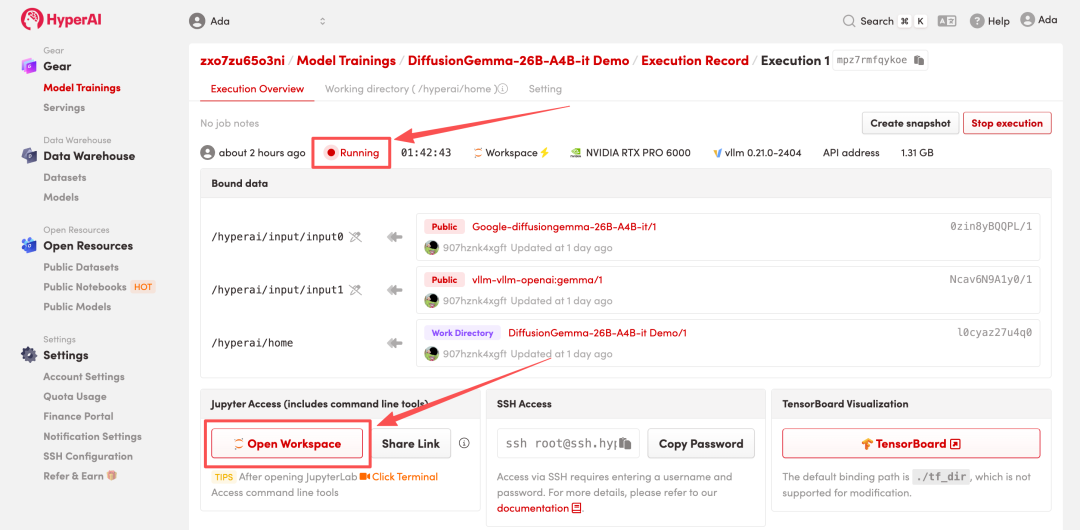
4. 等待分配资源,当状态变为「Running(运行中)」后,点击「Open Workspace」进入 Jupyter Workspace 。
效果展示
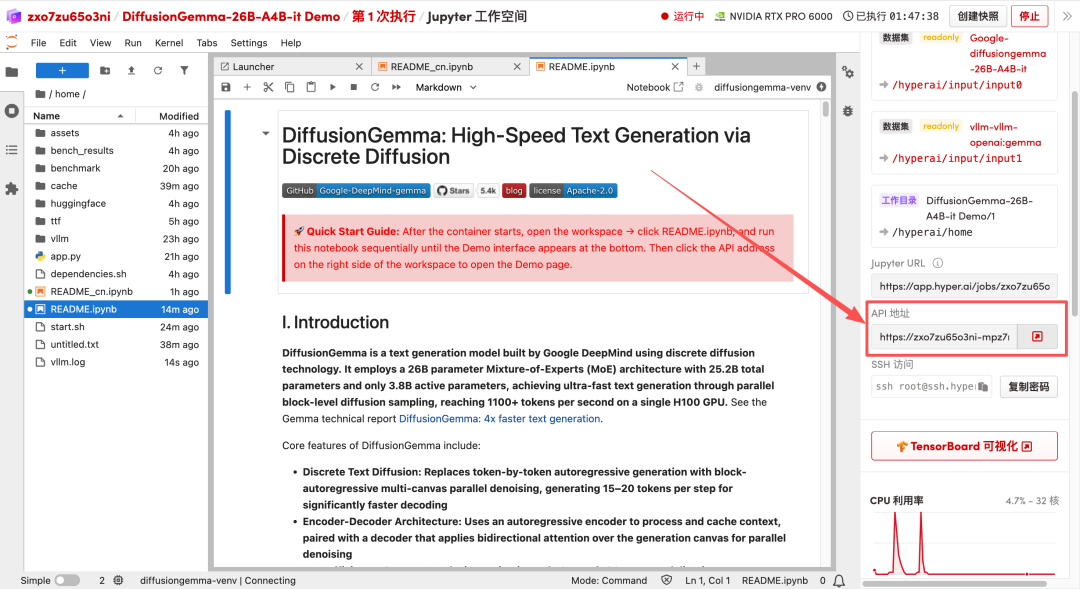
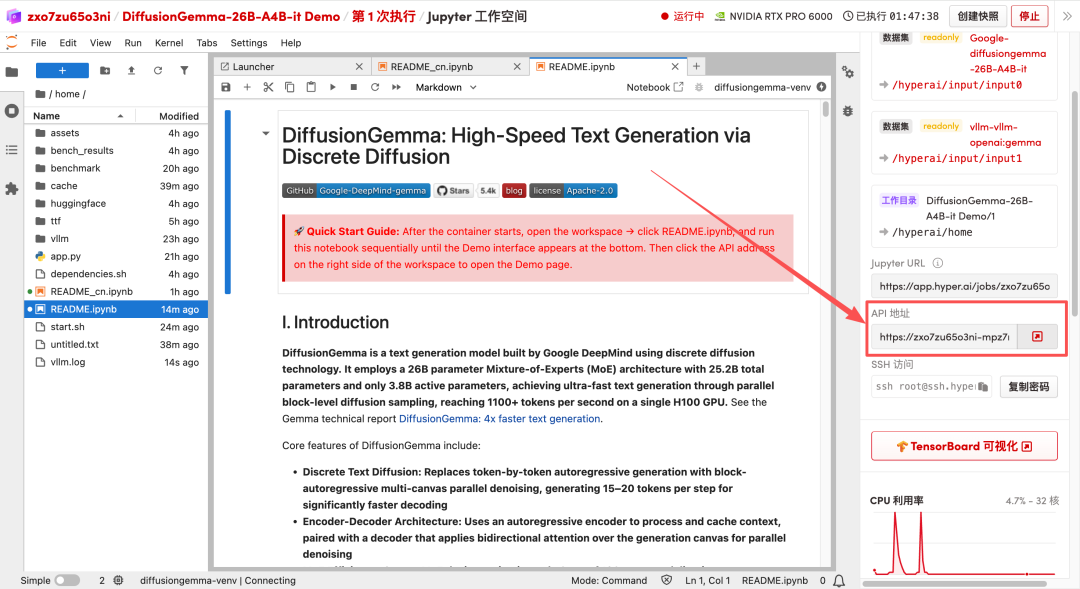
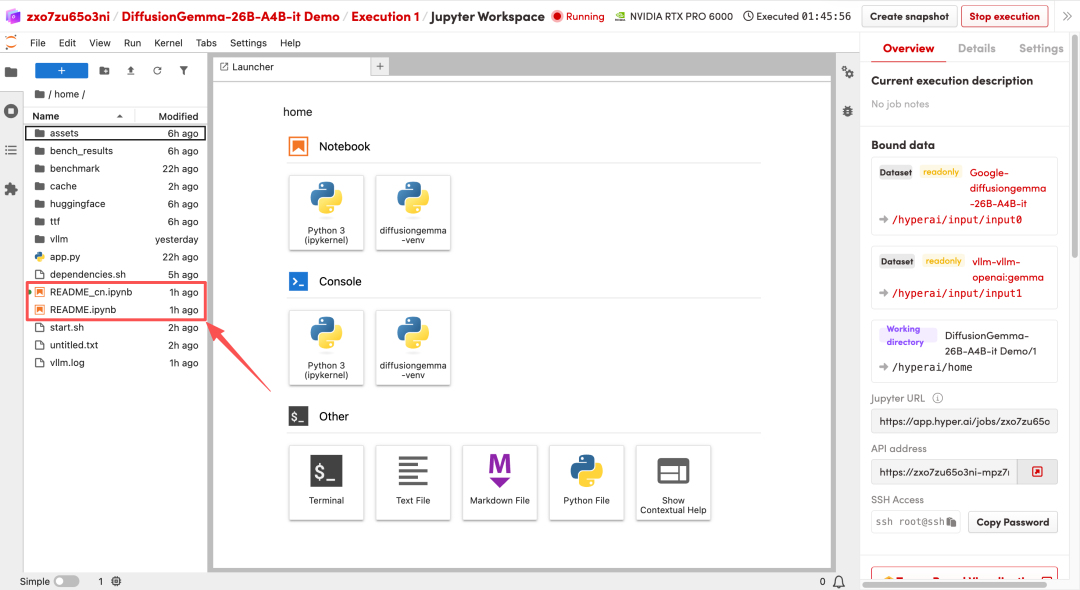
1. 页面跳转后,点击左侧 README 文件,进入后点击上方 Run(运行)。
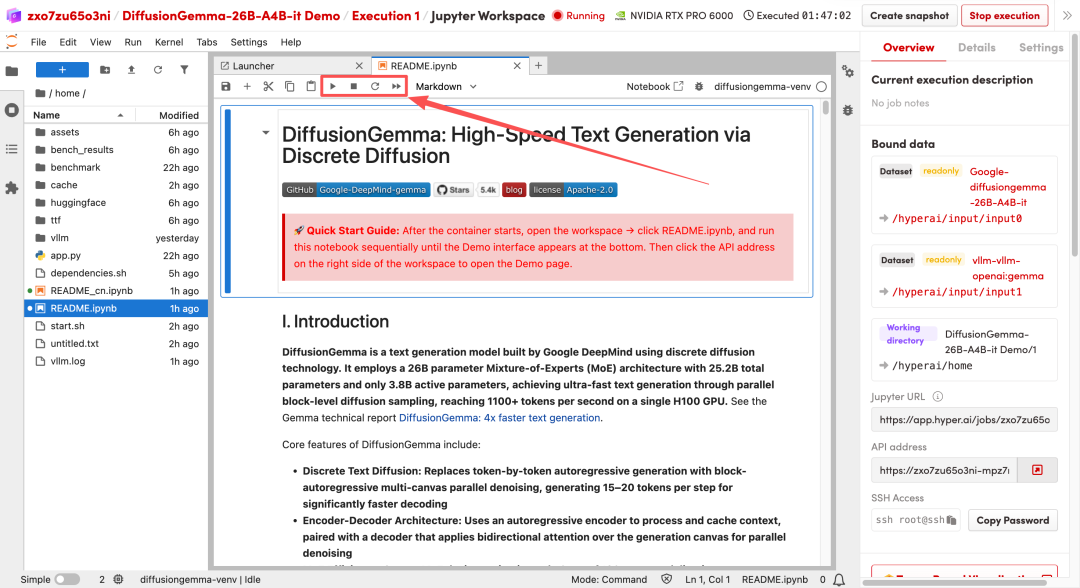
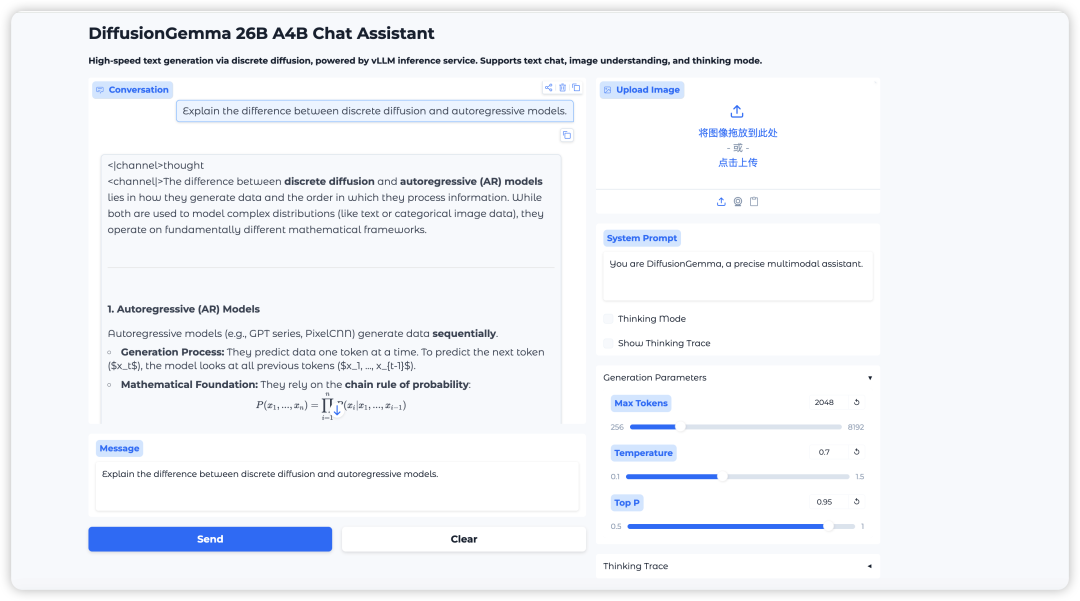
2. 待运行完毕后,点击右侧 API 地址即可打开 Demo 界面。