Command Palette
Search for a command to run...
在线教程丨 16GB 笔记本跑出接近 26B MoE 性能,Gemma 4 12B 基于创新架构统一处理文本/图像/声音三种模态

当大模型竞争仍在围绕参数规模展开时,Google DeepMind 再次证明,性能提升未必只能依靠更大的模型。
近日,Google DeepMind 正式发布 Gemma 4 家族最新成员——Gemma 4 12B 。这是一款仅有 120 亿参数的统一多模态模型,却在多项基准测试中展现出接近 260 亿参数混合专家(MoE)模型的性能。官方数据显示,Gemma 4 12B 在推理、代码生成以及多模态理解等任务上的表现已逼近 Gemma 4 26B,同时在部分视觉理解和 Agent 任务中达到当前同级别开源模型中的 SOTA 水平。更重要的是,该模型仅需 16GB 显存或统一内存即可在消费级笔记本电脑上本地运行,实现了性能与部署成本之间的罕见平衡。
作为 Gemma 系列首个原生支持音频输入的中等规模模型,Gemma 4 12B 最大的突破并非参数规模,而是架构创新。长期以来,多模态模型普遍采用「编码器 + 语言模型」的方案:图像由视觉编码器处理,音频由语音编码器处理,再将结果传递给大语言模型进行推理。这种架构虽然成熟,却带来了额外的计算开销、显存占用和推理延迟。
为了解决这一问题,Google DeepMind 为 Gemma 4 12B 设计了一套全新的 Encoder-Free(无编码器)架构。图像经过轻量级嵌入模块后直接进入 LLM 主干网络,而音频则被直接投射到与文本 Token 相同的表示空间,由同一个 Decoder-Only Transformer 统一处理文本、图像和声音三种模态。官方表示,这种设计显著降低了多模态推理延迟,同时减少了系统复杂度和内存占用。
除了统一多模态架构之外,Gemma 4 12B 还支持 256K 超长上下文窗口、可切换的 Thinking 深度推理模式、原生 Function Calling 以及 Agent 工作流能力。在标准评测中,其综合性能已接近体量超过两倍的 Gemma 4 26B MoE 模型,而运行成本却不到后者的一半。对于希望在本地部署先进 AI 能力的开发者而言,这意味着无需昂贵 GPU,也能够获得接近当前顶级多模态模型的推理与 Agent 体验。
目前,HyperAI 官网(hyper.ai)的教程板块已经上线了「一键部署 Gemma 4 12B-it」,以 notebook 的形式降低部署门槛,便于广大开发者快速验证模型。
在线运行:https://go.hyper.ai/1Jrdl
更多在线教程:
Demo 运行
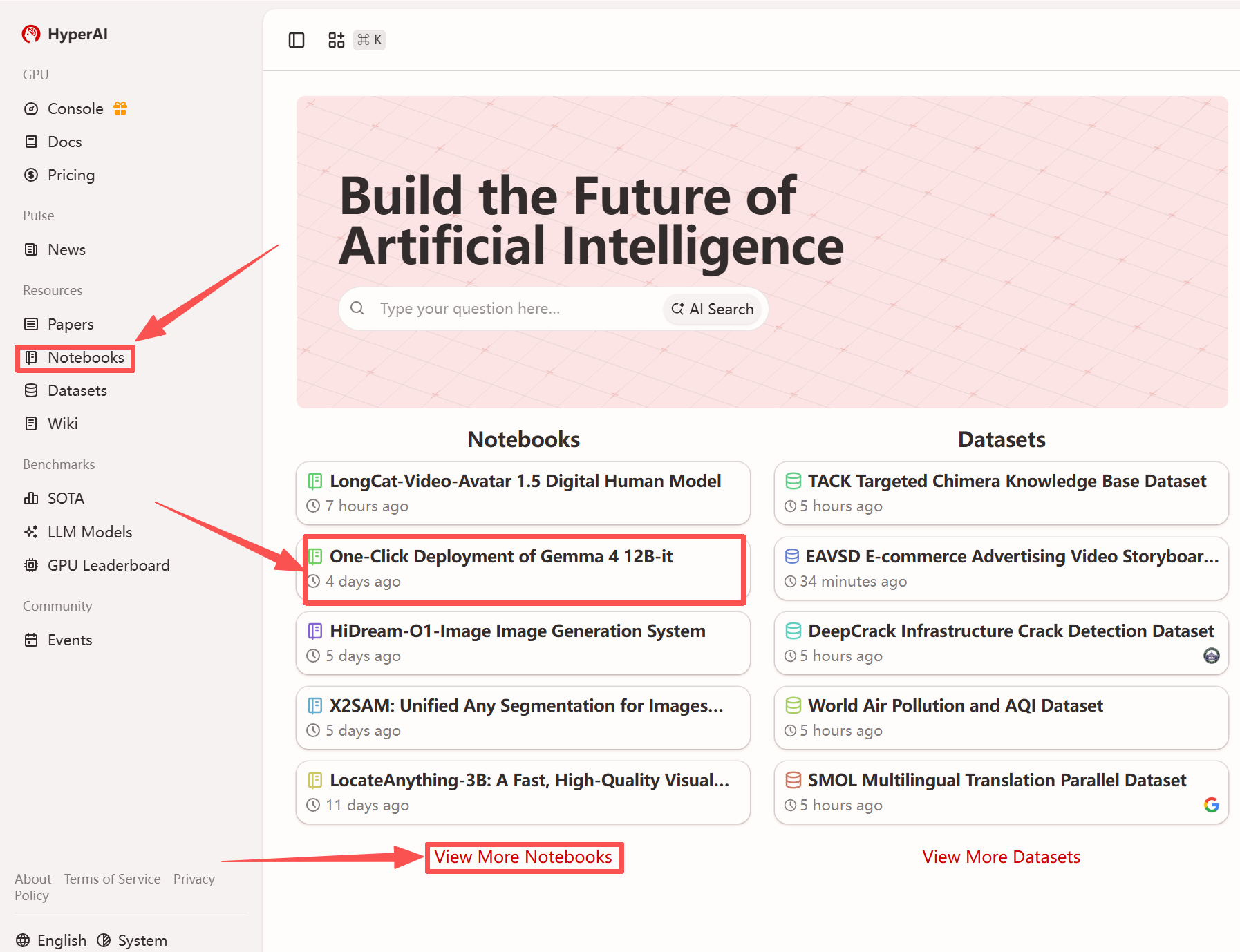
1. 进入 hyper.ai 首页后,选择「教程」页面,或点击「查看更多教程」,选择「一键部署 Gemma 4 12B-it」,点击「运行此教程」。
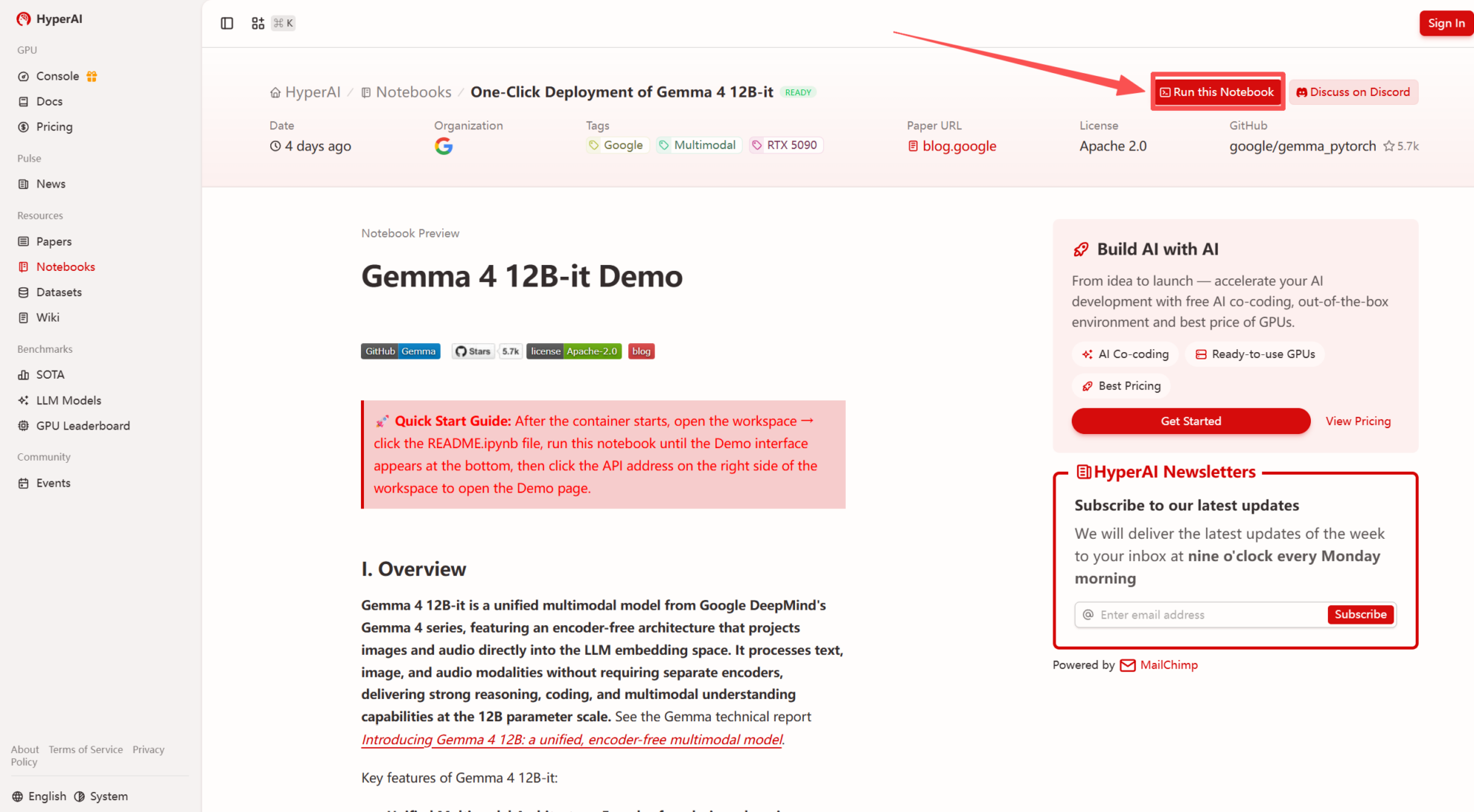
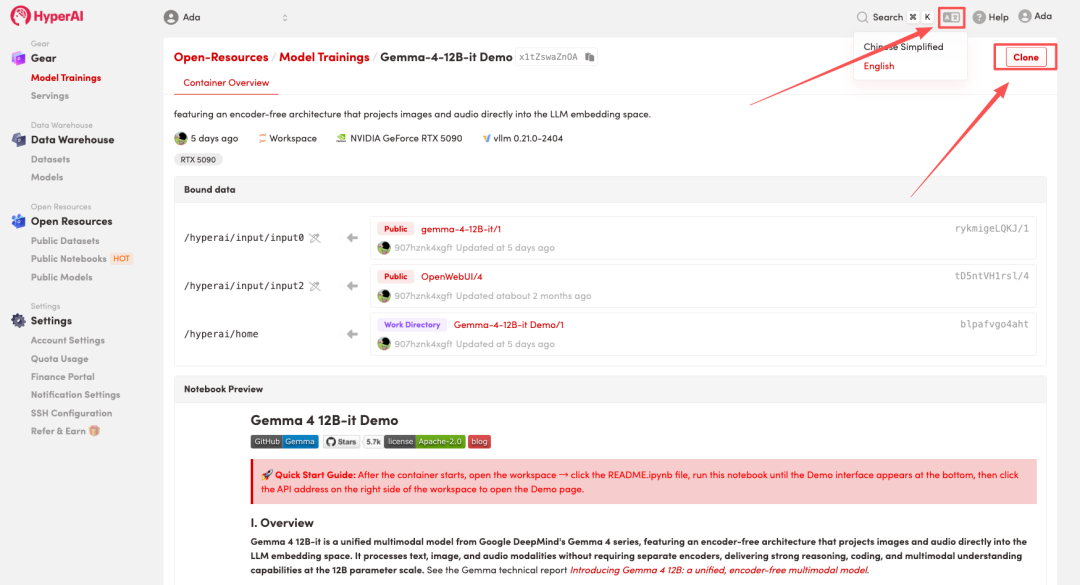
2. 页面跳转后,点击右上角「Clone」,将该教程克隆至自己的容器中。
注:页面右上角支持切换语言,目前提供中文及英文两种语言,本教程文章以英文为例进行步骤展示。
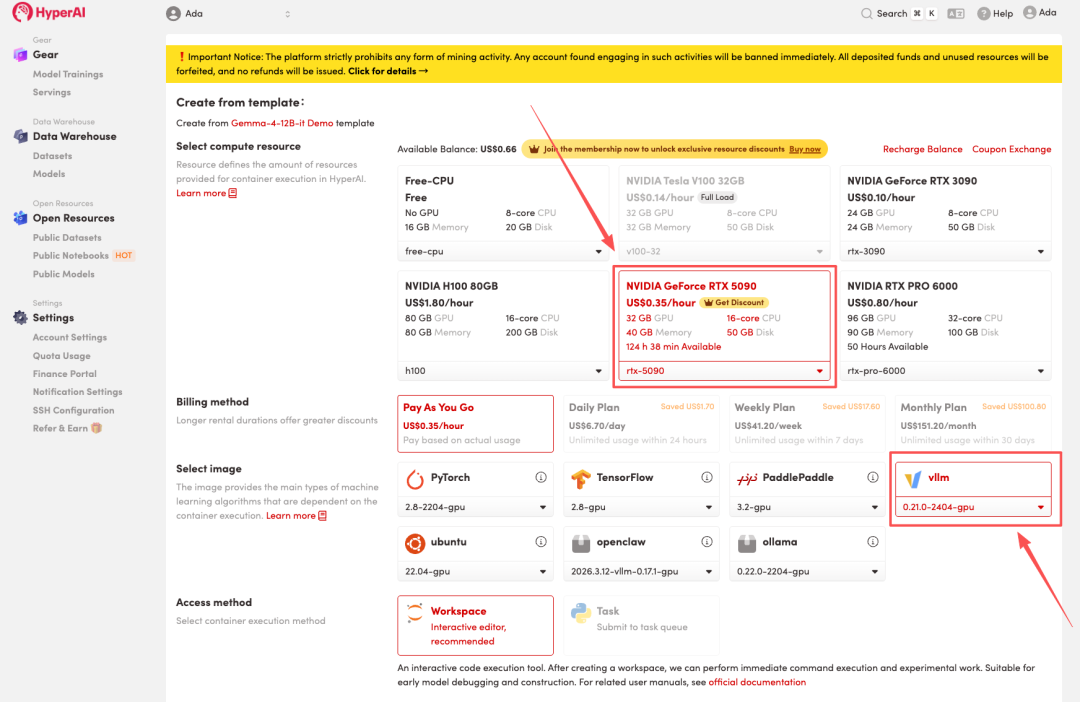
3. 选择「NVIDIA RTX 5090」以及「vLLM」镜像,点击「Continue job execution(继续执行)」。
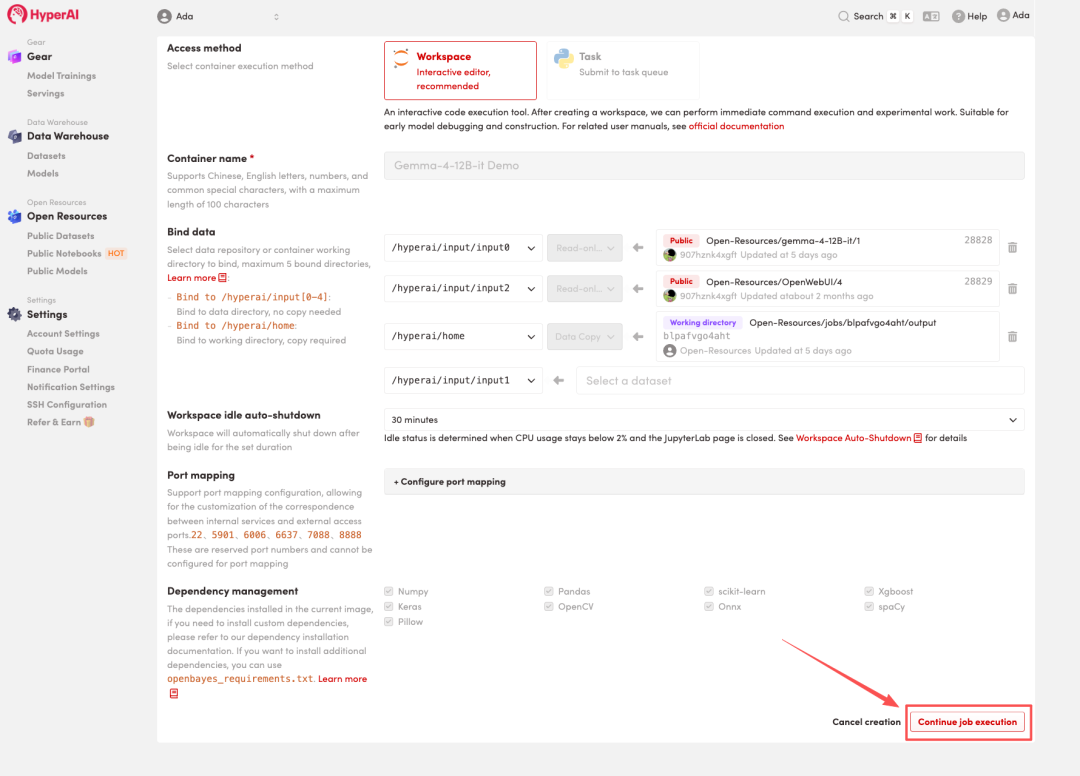
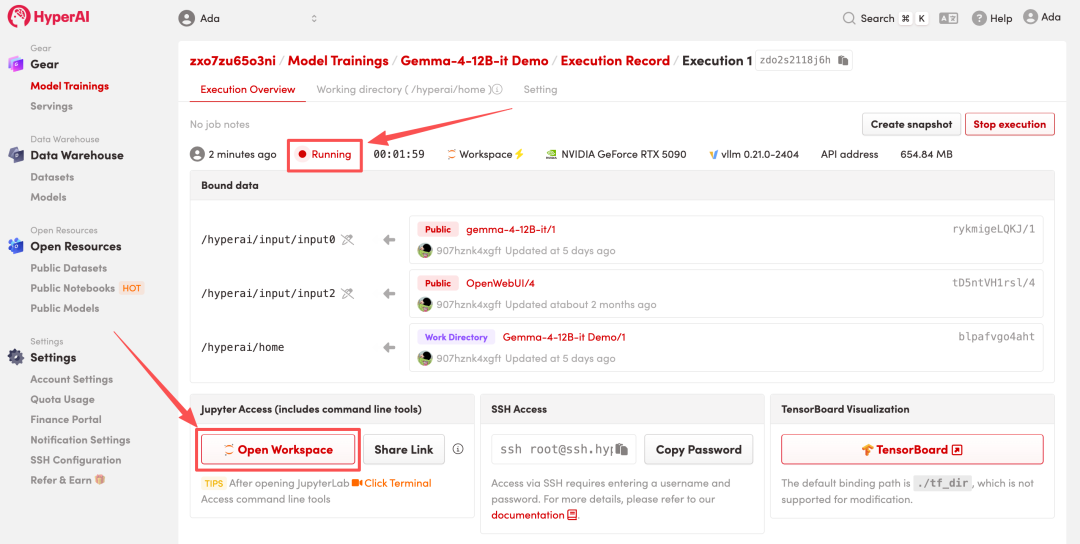
4. 等待分配资源,当状态变为「Running(运行中)」后,点击「Open Workspace」进入 Jupyter Workspace 。
效果展示
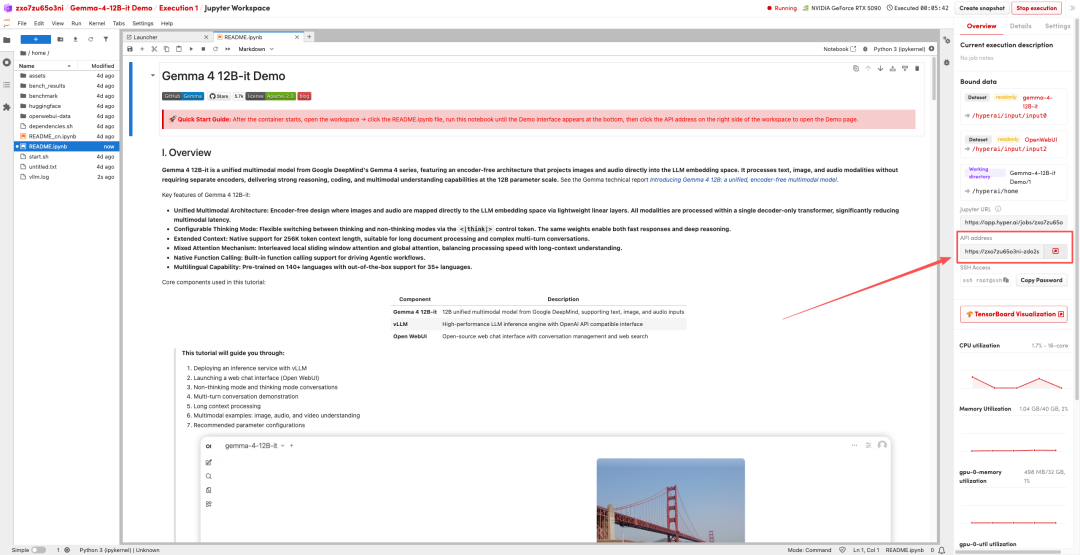
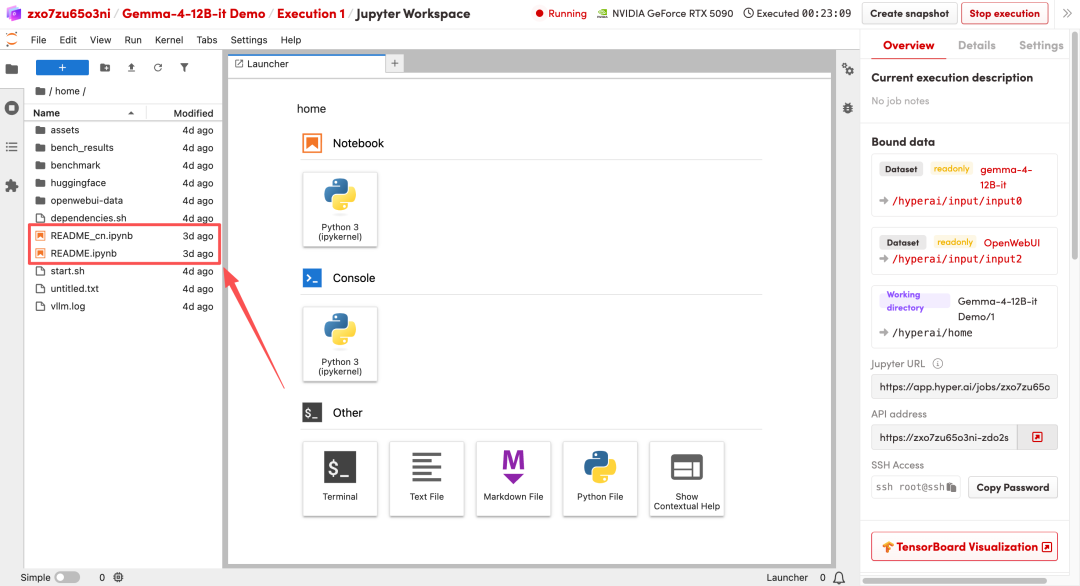
1. 页面跳转后,点击左侧 README 文件,进入后点击上方 Run(运行)。
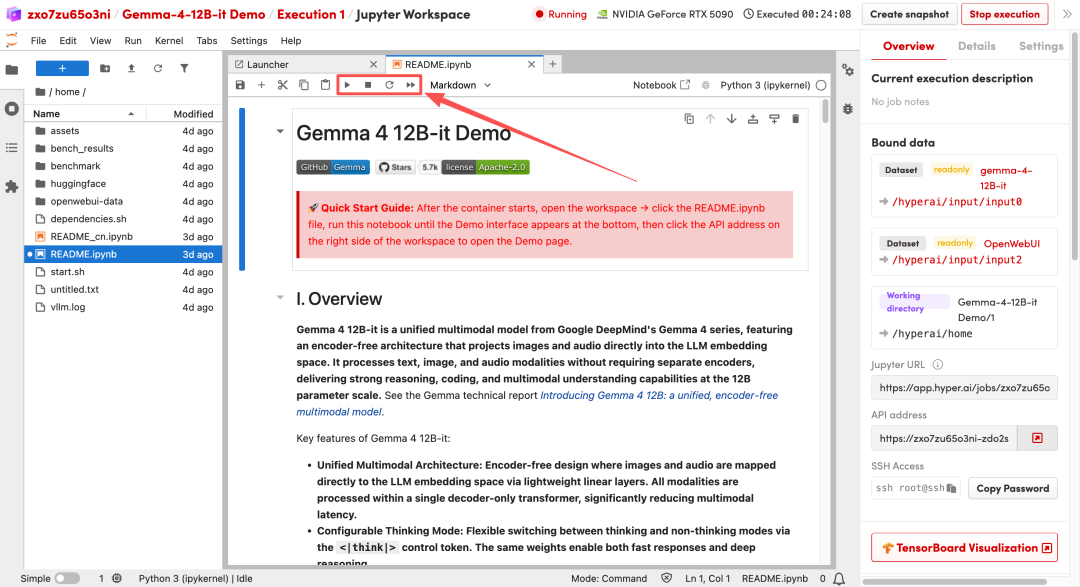
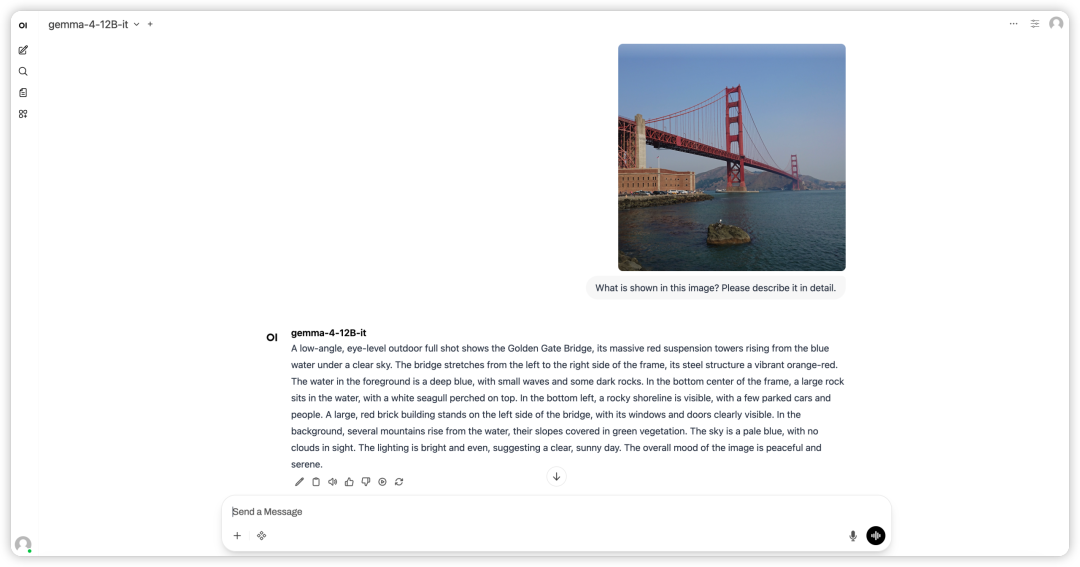
2. 待运行完毕后,点击右侧 API 地址即可打开 Demo 界面。