Command Palette
Search for a command to run...
在线教程丨英伟达开源 LocateAnything,3B 模型可实现图像+视频的目标指向/开放词汇目标检测/指代表达定位/OCR 文本定位等功能

随着视觉语言模型(VLM)持续向 Agent 、多模态交互和现实世界任务演进,「看懂图片」已经不再是终点,更重要的是「准确找到目标在哪里」。无论是开放词汇目标检测、 GUI Agent 的界面操作、文档理解,还是机器人与自动驾驶系统中的环境感知,都对视觉定位(Visual Grounding)能力提出了越来越高的要求。
然而,现有主流视觉语言模型在处理定位任务时普遍采用「坐标 Token 生成」方案,即将一个二维目标框拆分为多个一维坐标 Token,再逐个生成和解码。这种方式不仅难以充分保持目标框内部几何结构的一致性,还会因为严格的顺序生成机制限制推理速度。当模型需要同时处理大量目标时,定位效率和精度往往难以兼顾。
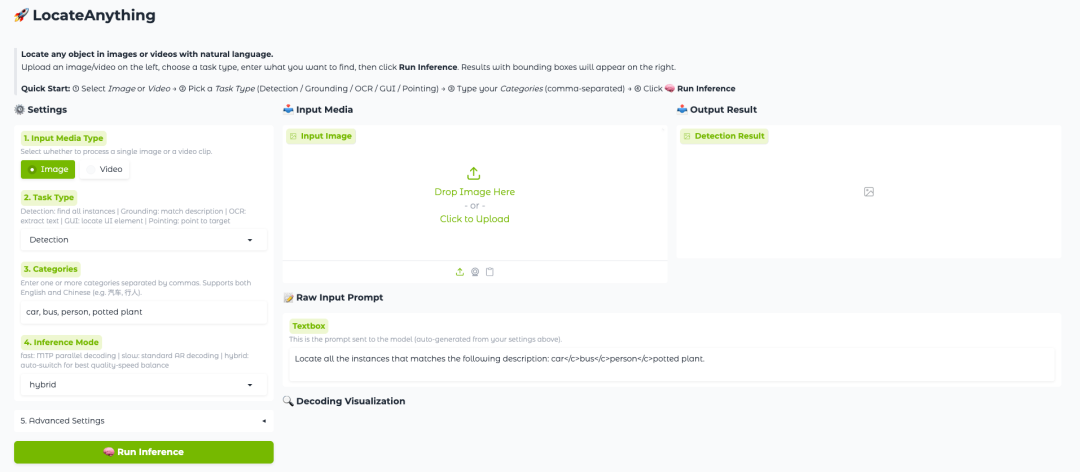
针对这一长期存在的瓶颈,NVIDIA 于近期开源了 Eagle VLM 系列中的新成员——LocateAnything-3B 。这是一款拥有 30 亿参数的视觉语言定位模型,支持开放词汇目标检测、指代表达定位、 OCR 文本定位、 GUI 元素定位以及图像和视频中的目标指向等多种任务,旨在构建统一的视觉定位与检测框架。
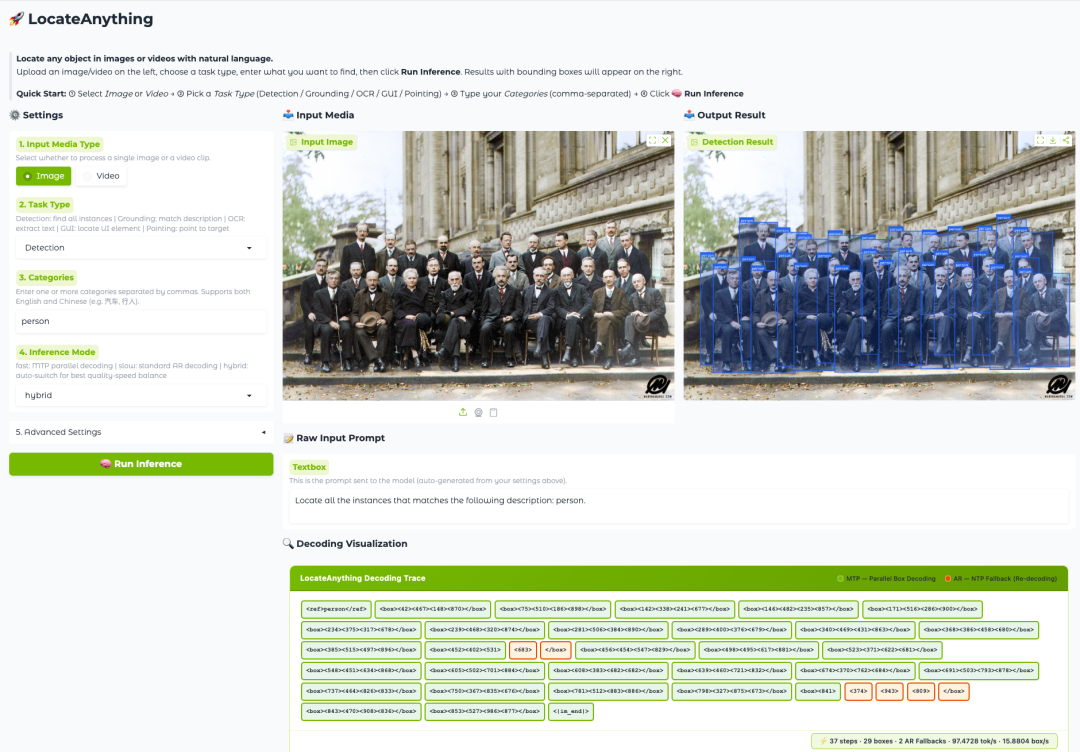
LocateAnything-3B 的核心创新来自一种名为 Parallel Box Decoding(PBD,并行框解码)的新机制。与传统方法逐个生成坐标 Token 不同,PBD 可以将边界框、关键点等几何元素作为完整结构一次性并行预测。这样的设计不仅保留了目标框内部的几何一致性,也显著提升了解码吞吐量,使模型能够在保持高精度定位能力的同时实现更快的推理速度。
除了架构创新,NVIDIA 还围绕该模型构建了大规模训练体系。研究团队开发了可扩展的数据引擎,并推出包含超过 1.38 亿训练样本的 LocateAnything-Data 数据集,覆盖自然场景、机器人、自动驾驶、 GUI 交互、文档理解以及 OCR 等多个领域,大幅提升了模型在复杂场景下的泛化能力。
实验结果显示,LocateAnything 在多个视觉定位基准测试中同时实现了更高的定位质量和更快的解码速度,推动统一视觉定位模型突破传统速度与精度之间的权衡。对于正在快速发展的 GUI Agent 、自动标注系统以及下一代多模态智能体而言,这种高效且精准的空间理解能力,正在成为基础设施级别的关键能力。
目前,HyperAI 官网(hyper.ai)的教程版块已经上线了「LocateAnything-3B:快速高质量视觉语言定位模型」,以 Notebook 的形式降低部署门槛。
在线运行:https://go.hyper.ai/4l9jB
更多在线教程:

欢迎登录官网查看更多内容:
Demo 运行
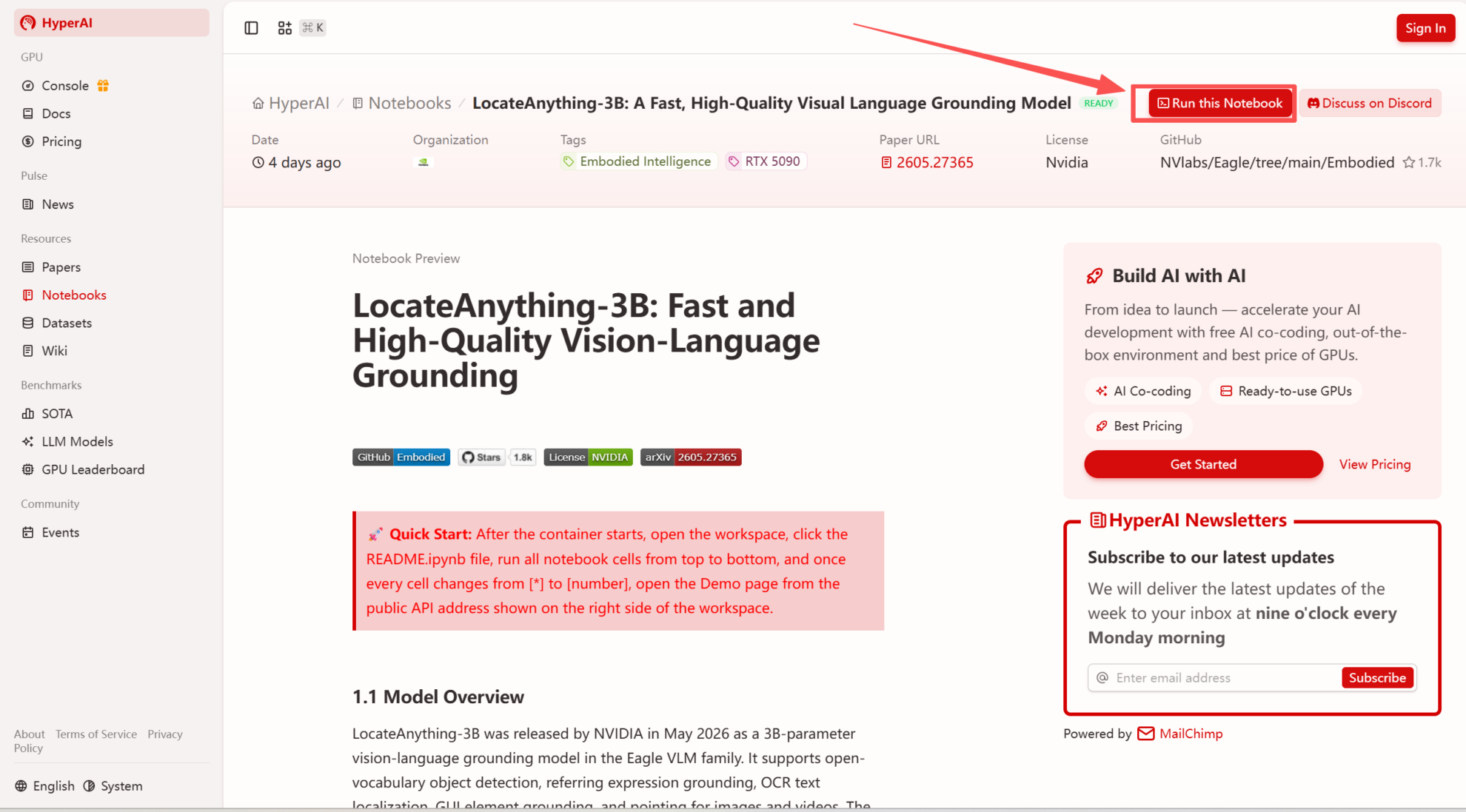
1. 进入 hyper.ai 首页后,选择「教程」页面,或点击「查看更多教程」,选择「LocateAnything-3B:快速高质量视觉语言定位模型」,点击「运行此教程」。
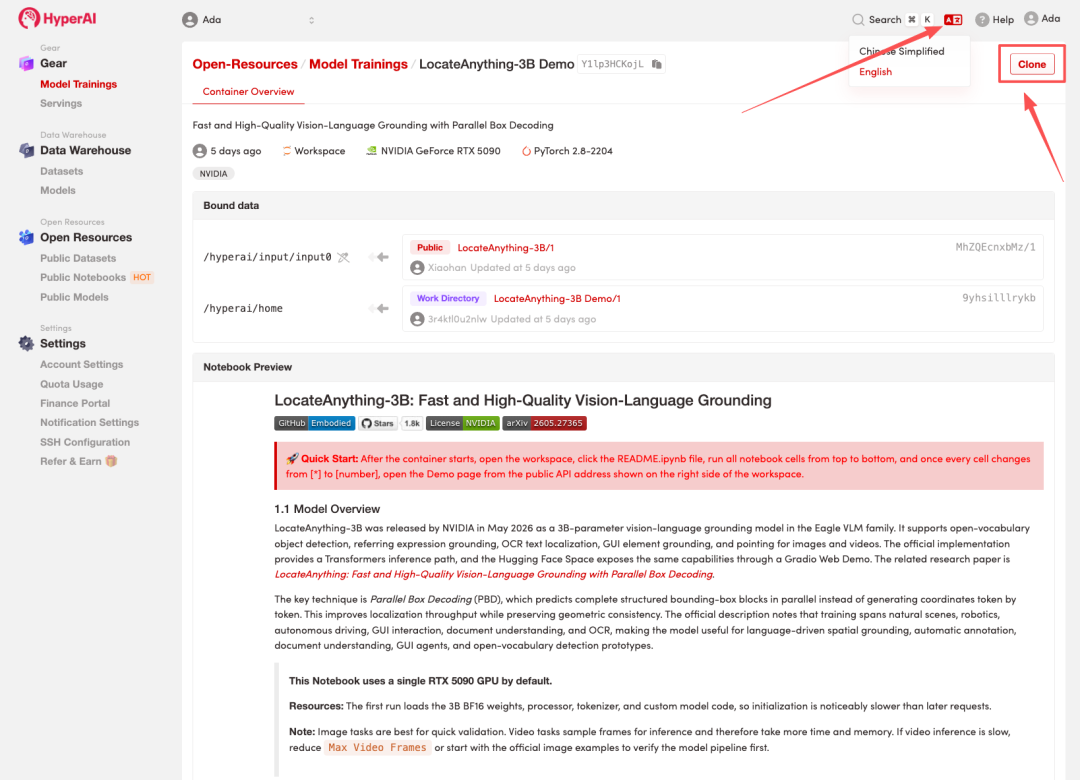
2. 页面跳转后,点击右上角「Clone」,将该教程克隆至自己的容器中。
注:页面右上角支持切换语言,目前提供中文及英文两种语言,本教程文章以英文为例进行步骤展示。
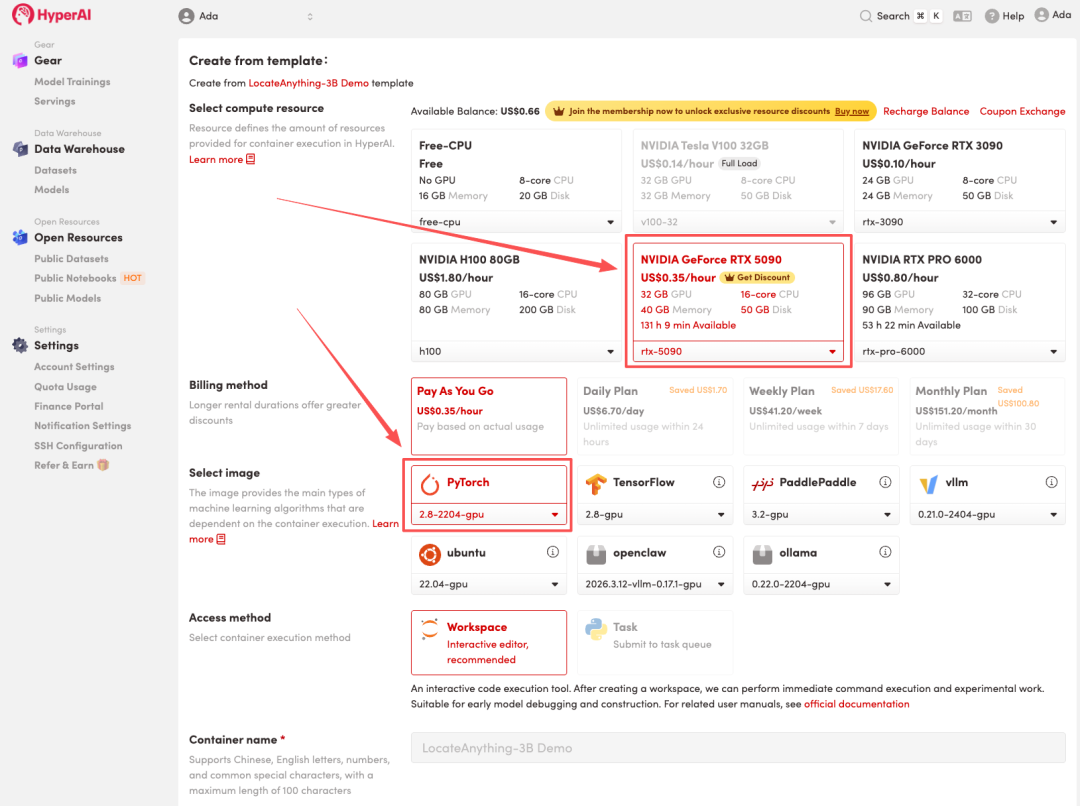
3. 选择「NVIDIA RTX 5090」以及「PyTorch」镜像,点击「Continue job execution(继续执行)」。
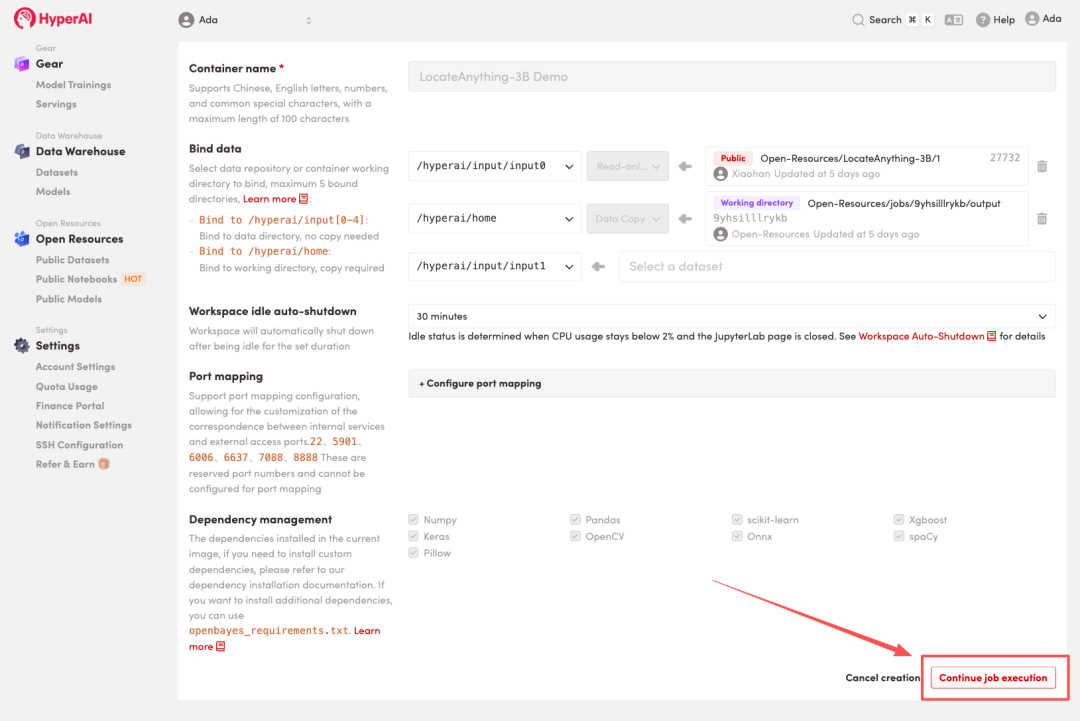
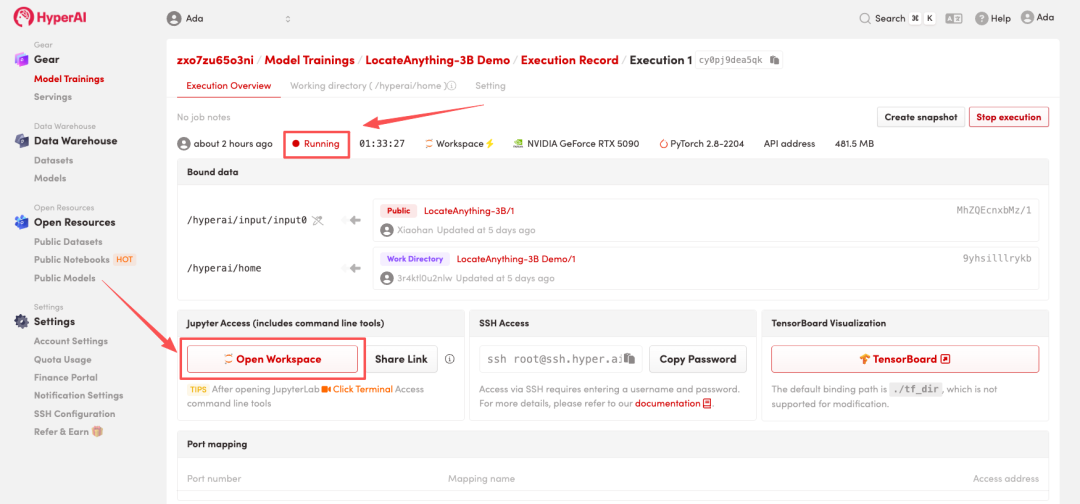
4. 等待分配资源,当状态变为「Running(运行中)」后,点击「Open Workspace」进入 Jupyter Workspace 。
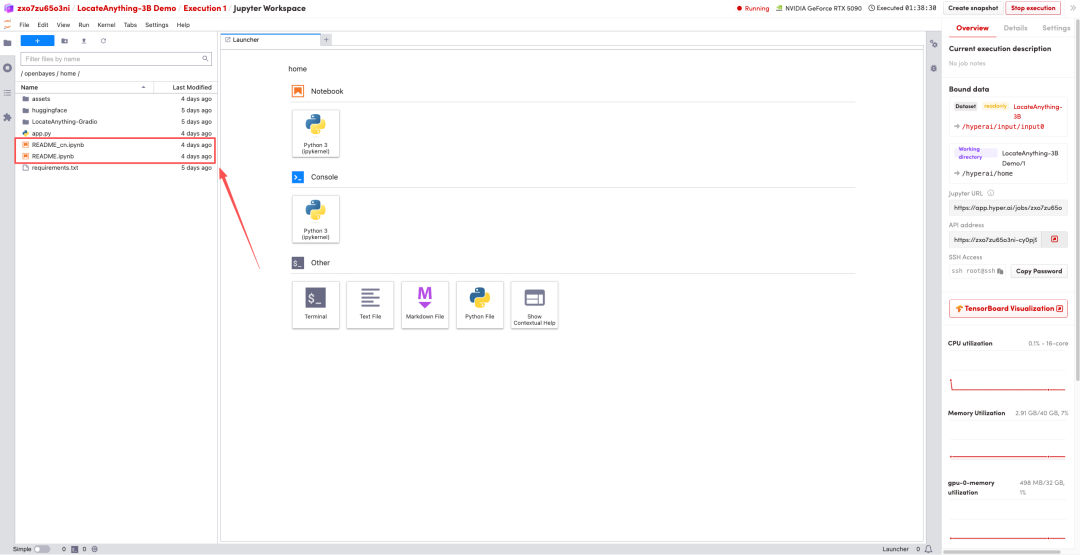
效果展示
1. 页面跳转后,点击左侧 README 文件,进入后点击上方 Run(运行)。
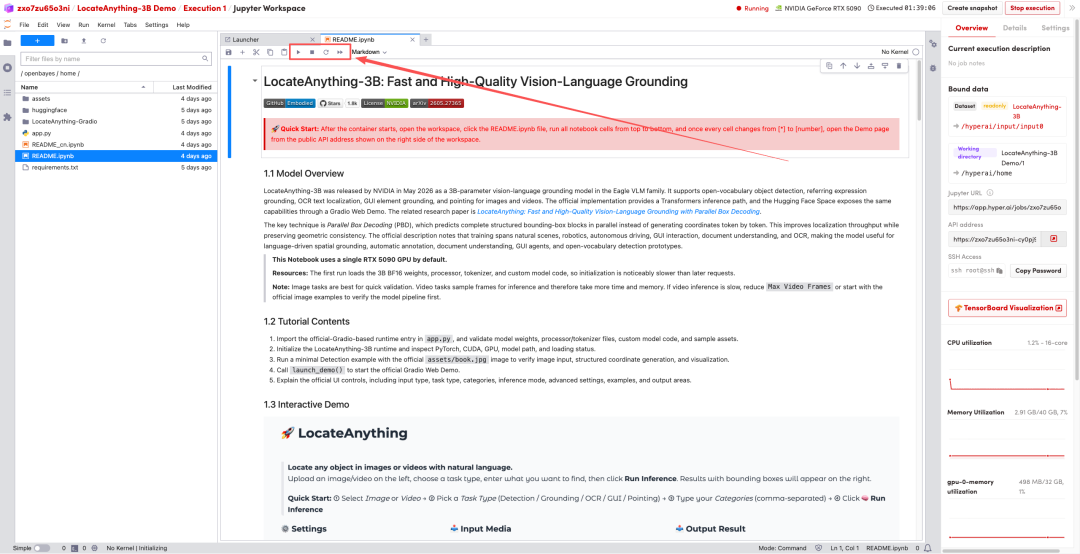
2. 待运行完成后,即可点击右侧 API 地址跳转至 demo 页面。