Command Palette
Search for a command to run...
论文周报 |微软 MAI-Thinking 探索纯 RL 自我进化,AIME 准确率达 97%;无需架构修改,VLM³凭纯文本坐标实现 3D 任务泛化… 速览一周 AI 前沿论文

人工智能的进步不仅依赖于单一模型的突破,更在于如何构建能够持续自我提升的系统。为此,微软 AI 团队将模型开发视为一个系统级优化问题,提出了一种旨在实现快速且持续性能提升的「爬山机器 (hill-climbing machine) 框架」,并基于此从零开始训练了总参数 1T 、激活参数 35B 的 MoE 推理模型 MAI-Thinking-1 。
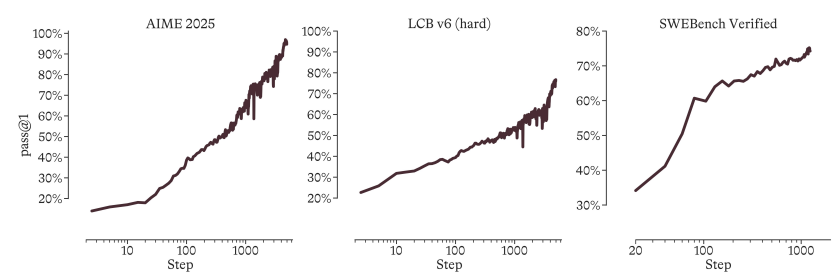
该模型在预训练阶段完全摒弃了第三方模型的蒸馏数据,并在强化学习(RL)阶段引入了带有自适应熵控制的 GRPO 算法与自蒸馏机制。实验结果显示,即使在没有任何先验推理轨迹的情况下起步,MAI-Thinking-1 也能实现长期且稳定的对数线性性能增长,最终在 AIME 2025 (97.0%) 和 SWE-Bench Pro (52.8%) 等核心基准上均达到了同级前沿的复杂推理与代码生成水平。
论文链接:https://go.hyper.ai/QeSWd
最新 AI 论文:https://go.hyper.ai/hzChC
为了让更多用户了解学术界在人工智能领域的最新动态,HyperAI 官网(hyper.ai)现已上线「最新论文」板块,定时更新 AI 前沿研究论文。以下是我们为大家推荐的 9 篇热门 AI 论文,一起来速览本周 AI 前沿成果吧 ⬇️
本周论文推荐
1. MAI-Thinking-1
论文题目:
MAI-Thinking-1: Building a Hill-Climbing Machine
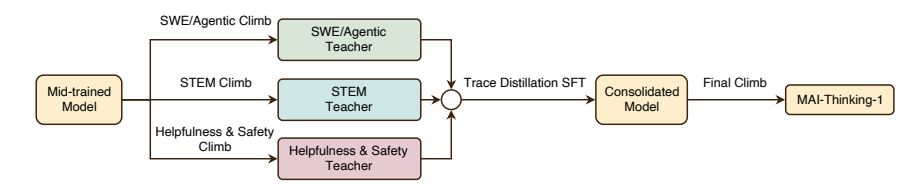
微软 AI 团队提出将模型开发视为系统级优化问题的「爬山」方法,从零训练了 总参数 1T 、激活参数 35B 的 MoE 推理模型 MAI-Thinking-1 。该模型的预训练完全基于纯净数据,未使用任何第三方蒸馏数据。在强化学习阶段,团队通过带有自适应熵控制的 GRPO 算法和自蒸馏机制,在无初始推理轨迹的情况下实现了稳定且长期的性能增长。模型最终融合了 STEM 、代码智能体和安全性三个专家方向的能力,在 AIME 2025(97.0%)和 SWE-Bench Pro(52.8%)等基准上展现出同级领先的推理与代码水平。
论文及详细解读:https://go.hyper.ai/QeSWd
2. VLM³
论文题目:
VLM³: Vision Language Models Are Native 3D Learners
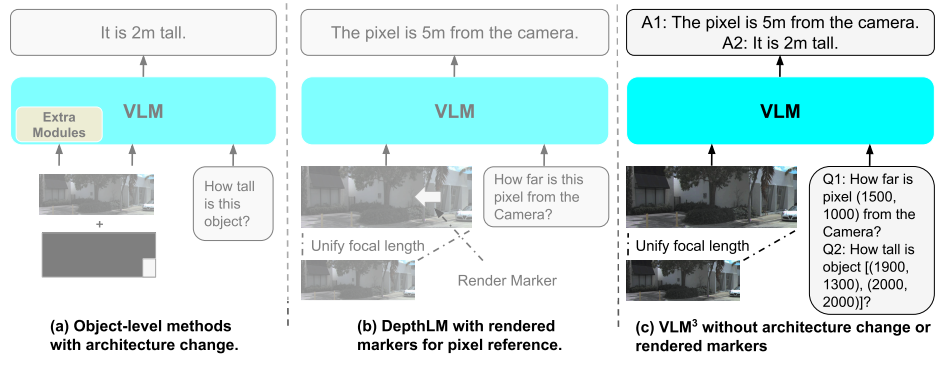
Meta 等团队通过大规模实验发现,让 VLM 具备高效 3D 学习能力并不需要复杂架构或专门设计,只需统一焦距、引入基于文本的像素参考以及合理的数据混合与扩展策略。基于这一发现,研究团队提出 VLM³,以极简设计让标准 VLM 同时掌握深度估计、像素级对应、相机位姿估计和对象级 3D 理解等任务。在保持原有架构和文本训练方式的前提下,VLM³ 的性能已接近甚至媲美专家级视觉模型,为通用视觉模型学习 3D 世界提供了一条更简单且可扩展的新路径。
论文及详细解读:https://go.hyper.ai/5ks6r
3. LocateAnything
论文题目:
LocateAnything: Fast and High-Quality Vision-Language Grounding with Parallel Box Decoding
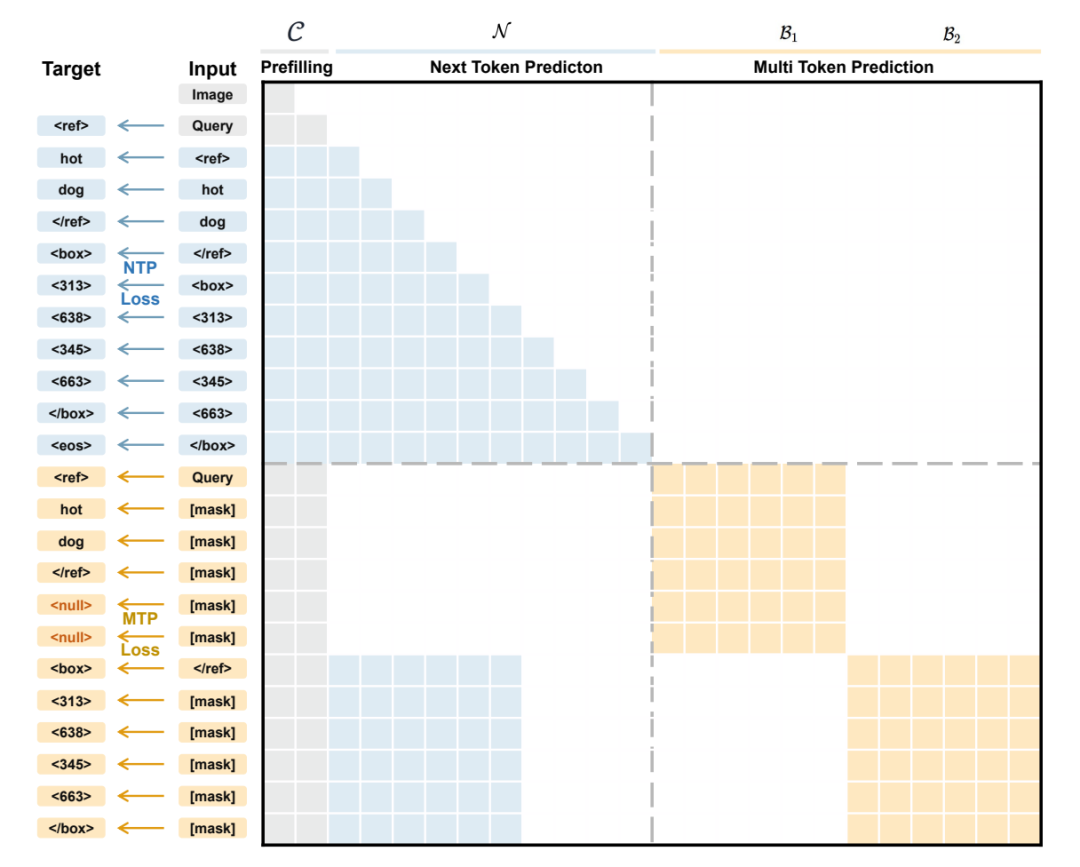
现有视觉语言模型通常将目标定位建模为坐标 token 的逐步生成过程,需要依次预测边界框坐标,不仅忽略了框内部的几何关联性,也限制了推理速度。针对这一问题,NVIDIA 团队提出 LocateAnything,通过并行框解码(PBD)机制,将边界框视为一个原子单元,在单步内并行生成其完整的坐标集 。配合包含 1.38 亿查询的超大规模数据集以及遇错智能回退的混合推理模式,该模型在多个基准测试中同时实现了更高的解码吞吐量和更优的高 IoU 定位精度,推动了统一视觉定位与检测任务的速度与精度上限。
论文及详细解读:https://go.hyper.ai/C8jXC
数据集构成与来源:研究团队构建了 LocateAnything-Data,这是一个包含 1200 万张独立图像、 1.38 亿条自然语言查询及 7.85 亿个标注边界框的大规模语料库。

4. Qwen-VLA
论文题目:
Qwen-VLA: Unifying Vision-Language-Action Modeling across Tasks, Environments, and Robot Embodiments
具身智能研究长期依赖针对单一任务的专业模型,导致能力碎片化且泛化受限。千问团队提出 Qwen-VLA,一种统一的视觉-语言-动作基础模型,通过基于 DiT 的动作解码器,将视觉-语言感知、理解与推理扩展至连续动作与轨迹生成。模型采用大规模联合预训练,涵盖机器人操作轨迹、人类第一人称演示、仿真数据、导航任务及辅助视觉-语言信号,并通过具身感知提示条件化机制适配多种机器人平台。 Qwen-VLA 将操作、导航与轨迹预测纳入统一框架,实现任务、环境与机器人形态间的可迁移能力。实验表明,模型在多项操作与导航基准上均展现出稳定的多任务性能与分布外泛化能力。
论文及详细解读:https://go.hyper.ai/5x2Tj
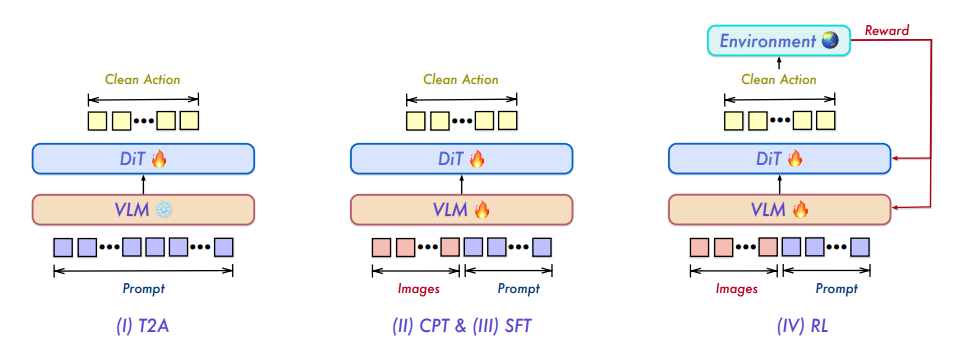
数据集构成与来源:研究团队构建了一个大规模异构预训练语料库,旨在统一视觉、语言与动作建模。数据来源涵盖十余个公开机器人基准测试、大规模人类视频语料库、专有内部收集数据以及内部生成的仿真流水线。

5. SDPG
论文题目:
Self-Distilled Policy Gradient
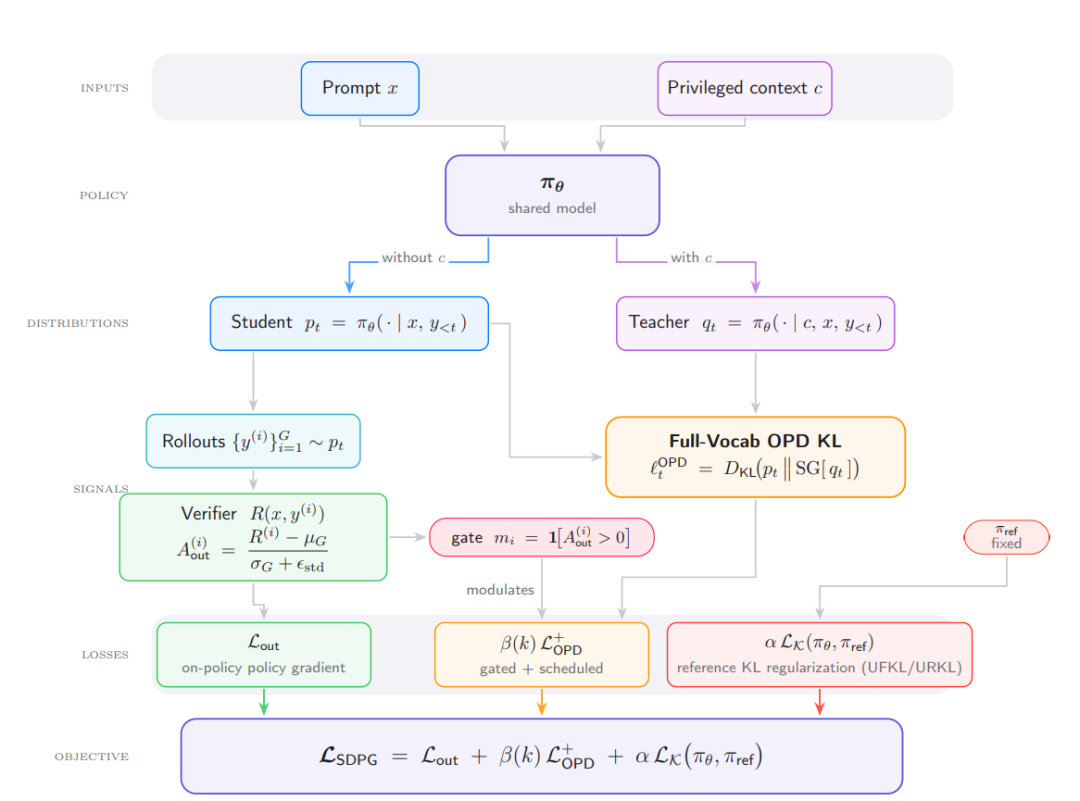
基于策略的自我蒸馏(on-policy self-distillation)利用模型的特权上下文对自身生成结果进行监督,为稀疏奖励强化学习提供更密集的学习信号,并可形式化为全词表的反向 KL 学生-教师损失。在此基础上,UCLA 与普林斯顿大学的研究人员共同提出 SDPG 框架,将组相对验证器优势、标准差归一化、在线全词表自蒸馏及参考策略 KL 正则化相结合。实验表明,SDPG 相较 RLVR 与现有自蒸馏方法在稳定性与性能上均有提升。
论文及详细解读:https://go.hyper.ai/p5irp
6. GSM-Symbolic
论文题目:
GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models
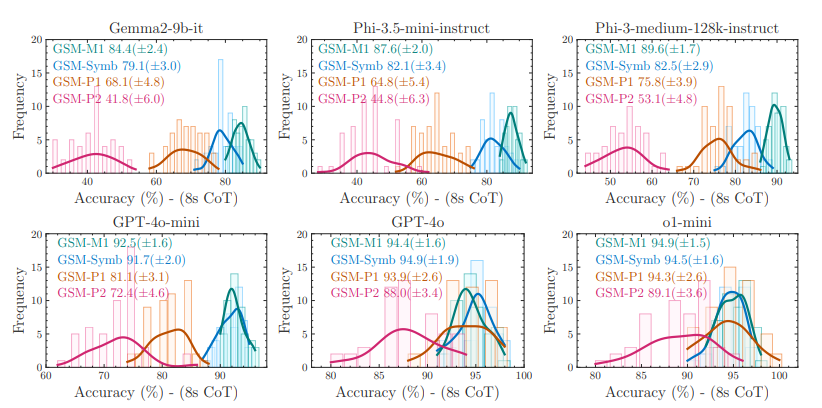
研究指出传统的 GSM8K 基准难以准确反映模型的真实水平,因此 Apple 团队构建了基于符号模板的可控测试基准 GSM-Symbolic 。实验表明,仅仅改变题目中的数字或实体名称,大模型的表现就会出现显著波动;而一旦加入无关的干扰从句,其准确率更会大幅崩塌。研究团队猜想当前的 LLM 并不具备真正的逻辑推理能力,而是试图复现其训练数据中观察到的推理步骤。
论文及详细解读:https://go.hyper.ai/n3UfJ
7. MUSE-Autoskill
论文题目:
MUSE-Autoskill: Self-Evolving Agents via Skill Creation, Memory, Management, and Evaluation
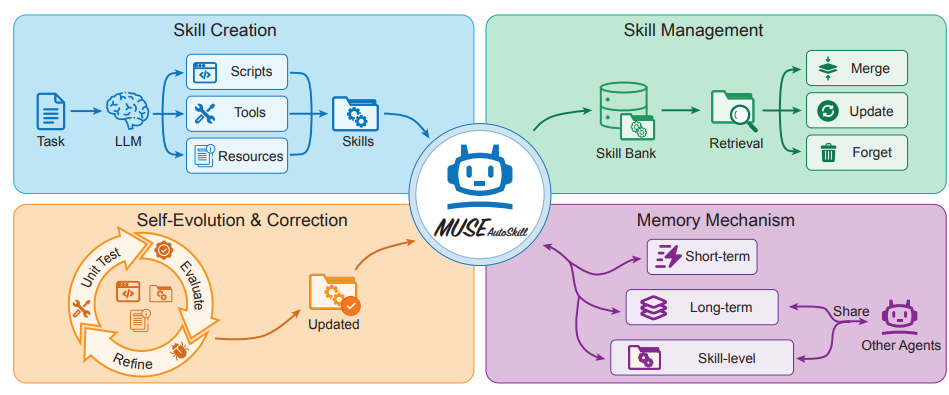
字节跳动等团队提出了 MUSE-Autoskill 智能体框架,将技能的创建、记忆、管理、评估与优化统一为完整的生命周期。该框架通过引入技能级记忆(skill-level memory)跨任务积累经验,打破了传统技能静态孤立的局限。在 SkillsBench 上的实验提供了初步证据,表明通过生命周期管理的技能能够提高任务成功率、执行效率、复用率以及跨智能体迁移能力,突显了将技能视为具有长生命周期、具备经验感知能力且可测试的资产的重要性。
论文及详细解读:https://go.hyper.ai/mdgB2
8. Nemotron 3 Ultra
论文题目:
Nemotron 3 Ultra: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
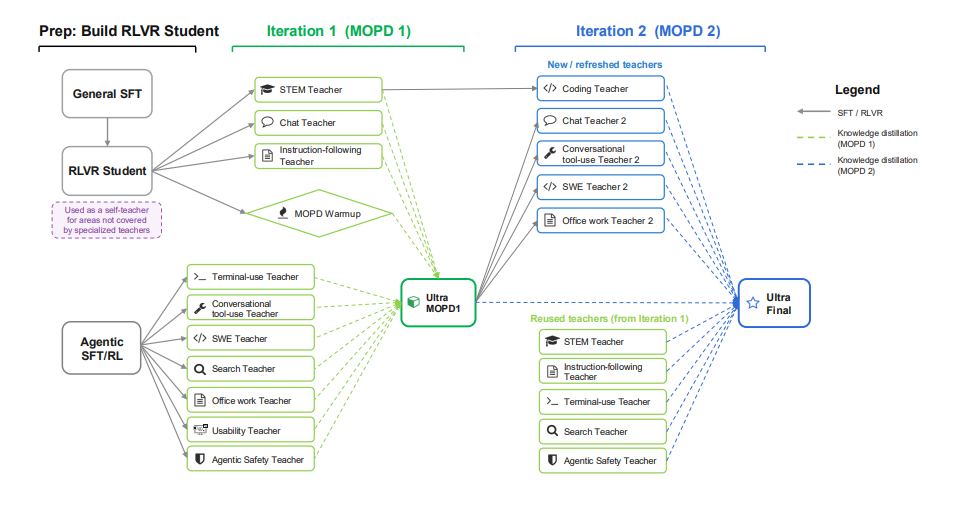
NVIDIA 团队推出 Nemotron 3 Ultra,一款 5500 亿参数、 550 亿激活参数的 Mamba-Attention MoE 语言模型。该模型基于 20 万亿 token 预训练,上下文长度扩展至 100 万 token,并通过 SFT 、 RL 与多教师在线策略蒸馏(MOPD)进行后训练。采用 LatentMoE 、多 token 预测、 NVFP4 、 RLVR 、 MOPD 及推理预算控制等技术,Nemotron 3 Ultra 推理吞吐量比现有公开 LLM 提升约 6 倍,同时保持高准确率,适合长期自主 Agentic 任务。
论文及详细解读:https://go.hyper.ai/lm6S1
9. Cosmos 3
论文题目:
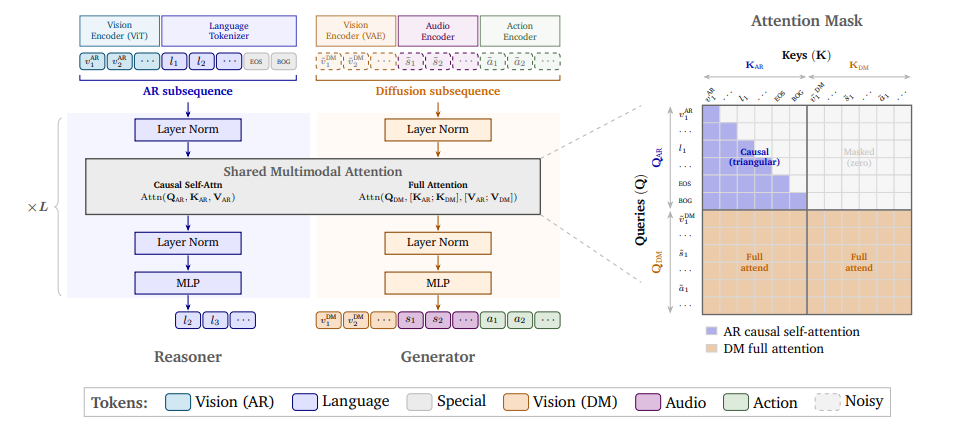
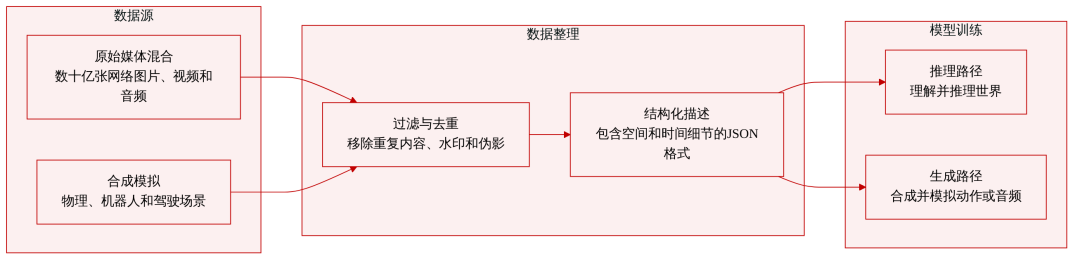
Cosmos 3: Omnimodal World Models for Physical AI
NVIDIA 团队推出 Cosmos 3,一组全模态世界模型,在统一的混合 Transformer 架构中处理与生成语言、图像、视频、音频及动作序列。 Cosmos 3 支持高度灵活的输入输出配置,将视觉语言模型、视频生成器、世界模拟器及动作模型整合为单一框架。评测显示,它在多样化理解与生成任务中创下最先进水平,验证全模态世界模型可作为具身 agents 的通用骨干网络。后训练模型被评为最佳开源文本到图像/图像到视频模型及最佳策略模型。
论文及详细解读:https://go.hyper.ai/RoY2u
以上就是本周论文推荐的全部内容,更多 AI 前沿研究论文,详见 hyper.ai 官网「最新论文」板块。
同时也欢迎研究团队向我们投稿高质量成果及论文,有意向者可添加神经星星微信(微信号:Hyperai01)。
下周再见!








