Command Palette
Search for a command to run...
论文汇总 | 大模型强化学习最新进展,微软/谷歌/斯坦福/人大/小红书等发布信用分配/复杂推理/智能体强化学习重磅成果

纵观当前强化学习领域的发展,无论是提升长链路推理中的信用分配能力,增强模型在复杂环境中的自主探索,还是构建具备长期规划与反馈学习能力的智能体系统,其核心目标都指向同一个方向——突破稀疏奖励与静态监督的限制,赋予模型通过交互持续学习与自我进化的能力。
强化学习本质上是一种让智能体通过「感知—决策—执行—反馈」闭环不断优化行为策略的方法。与传统监督学习依赖固定数据分布不同,强化学习强调模型在环境交互中的试错学习能力,使其能够在动态任务中逐步形成长期收益最大化的决策机制。简而言之,强化学习正在推动人工智能从「会回答问题」迈向「会自主行动」,完成从「被动生成」到「主动智能」的重要跨越。
本周,HyperAI 为大家精选了 6 篇大模型强化学习领域的最新研究。其背后的团队涵盖斯坦福大学、中国人民大学等顶尖学府,以及微软、谷歌、快手、小红书等科技巨头。相关论文为构建下一代具备强推理、自学习能力的大模型提供了极具启发性的新解法。一起来学习吧 ⬇️
此外,为了让更多用户了解学术界在人工智能领域的最新动态,HyperAI 官网现已上线「最新论文」板块,及时跟进前沿 AI 研究。
最新 AI 论文:https://go.hyper.ai/hzChC
本周论文推荐
1 ECHO
论文题目:
ECHO: Terminal Agents Learn World Models for Free
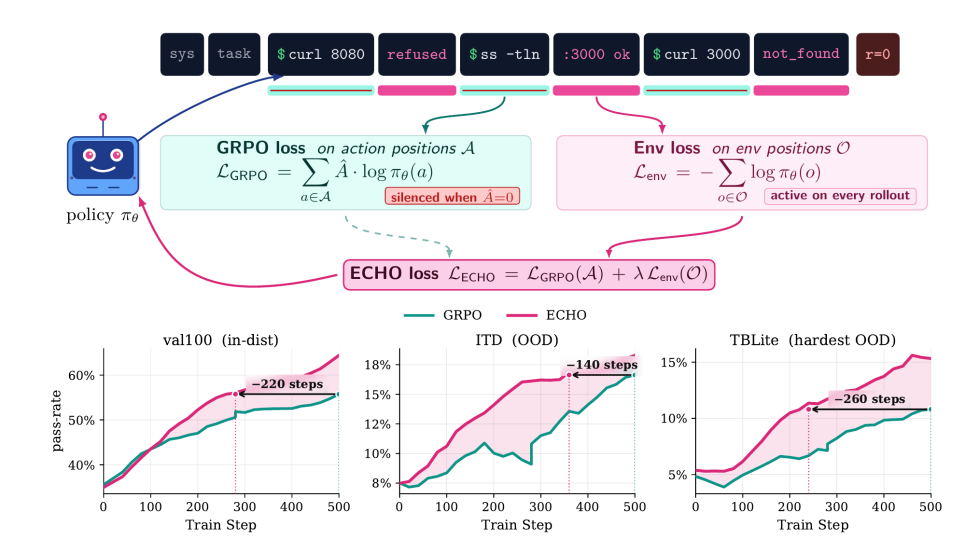
终端智能体交互会产生海量环境反馈,但常规强化学习仅利用稀疏奖励更新动作标记,严重浪费了观测数据。研究提出 ECHO 方法,在保留动作损失的同时,对环境反馈标记额外计算交叉熵预测损失。该机制无需增加前向传播开销,促使策略在训练中同步预测终端对指令的响应,相当于免费习得世界模型。
实测表明,该方法在终端控制基准上的首答准确率实现翻倍,显著增强了对未见终端动态的预测能力,大幅降低了专家演示依赖,甚至能在无外部验证时实现自我进化。
论文及详细解读:https://go.hyper.ai/qma4O
2 DelTA
论文题目:
DelTA: Discriminative Token Credit Assignment for Reinforcement Learning from Verifiable Rewards
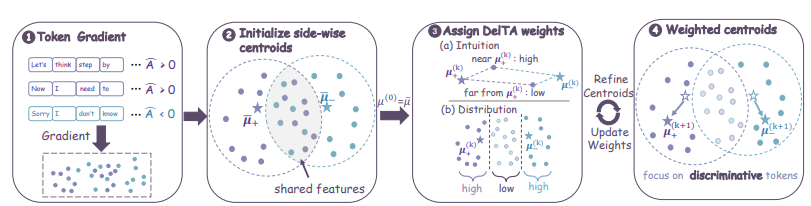
基于可验证奖励的强化学习常面临信用分配粒度过粗的困境。常规更新极易被排版等高频共享模式主导,无法有效定位真正带来高收益的关键推理标记。针对该问题,研究提出 DelTA,通过计算专属系数重新加权自归一化目标函数。该机制能精准放大正负收益侧独有的标记梯度方向,强力抑制共有的弱区分性方向,极大提升了梯度更新的对比度。在数学推理与代码生成评测中,该方法全面超越同规模最强基线,并在不同架构上展现出极佳的泛化能力。
论文及详细解读:https://go.hyper.ai/IdI42
3 GoLongRL
论文题目:
GoLongRL: Capability-Oriented Long Context Reinforcement Learning with Multitask Alignment
长上下文强化学习常受限于同质化的检索训练数据,且常规算法在处理多任务混合奖励时,易因尺度和难度差异导致优势估计失真。研究提出能力导向的 GoLongRL 方案,首创涵盖九大核心能力与定制化奖励的开源数据集。针对优化痛点,设计了 TMN-Reweight 机制,利用任务级归一化对齐不同奖励尺度,并结合难度自适应权重聚焦高价值的困难样本。评测表明,该方案在多项长文本基准上全面超越现有领先模型,且有效避免了通用推理与记忆能力的衰退。
论文及详细解读:https://go.hyper.ai/omy5E
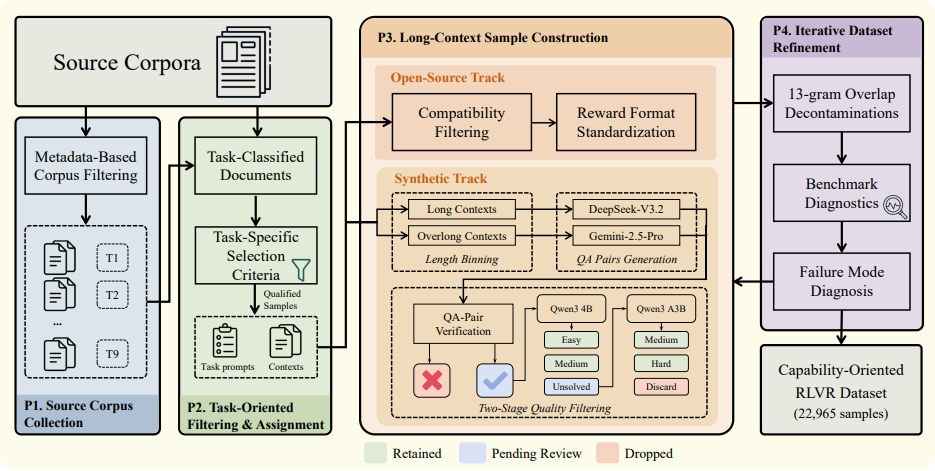
作者构建了一个包含 22,965 个样本的数据集,涵盖 9 种能力导向型任务,上下文长度范围从 0.1K 到 256K tokens 。
4 AntiSD
论文题目:
Anti-Self-Distillation for Reasoning RL via Pointwise Mutual Information
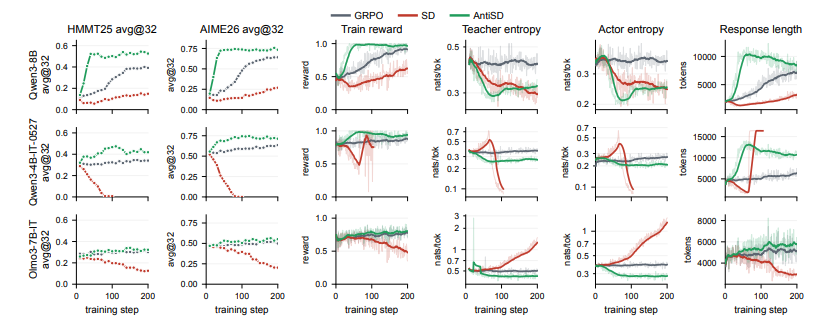
常规自蒸馏在数学推理任务中极易让模型「走捷径」,过度依赖已知答案而抑制真正驱动多步搜索的思考过程。针对此问题,研究提出反向自蒸馏方法(AntiSD),不再被动缩小师生模型差距,而是通过最大化 JS 散度反转梯度信号,专门奖励探索性的思考标记,并辅以基于熵的门控机制维持训练稳定。在多款不同参数规模的大模型测试中,该方法仅需基线五分之一到一半的训练步数即可达标,同时在多项数学推理基准上将最终准确率最高提升了 11.5 个百分点。
论文及详细解读:https://go.hyper.ai/Vax3f
5 RubricEM
论文题目:
RubricEM: Meta-RL with Rubric-guided Policy Decomposition beyond Verifiable Rewards
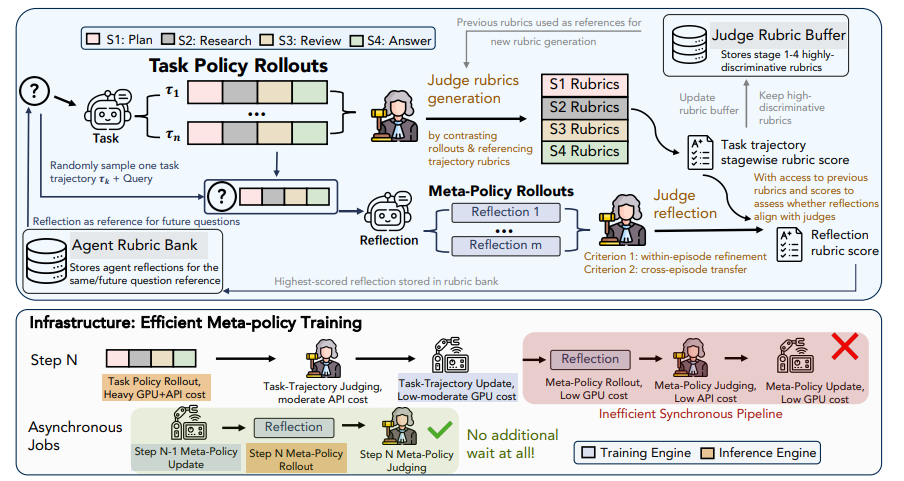
长周期深度研究任务缺乏客观奖励,常规强化学习反馈粗糙且难以沉淀有效经验。研究提出 RubricEM 框架,创新性地将「评分量表」作为核心接口。模型按自建量表将长轨迹拆分为规划、检索、审查和作答阶段,借此实现细粒度信用分配;同时框架异步训练元策略,将历史交互提炼为可复用的反思记忆。在多项长篇研究评测中,该 8B 模型一举超越众多开源方案并逼近顶尖闭源系统,通过极少的训练步数实现了高效的长上下文学习与出色的跨任务泛化。
论文及详细解读:https://go.hyper.ai/xSVTh
数据集构成与来源:研究团队构建了一个包含约 11,000 个样本的监督微调数据集。数据源自由 Gemini 教师模型生成的 agent 轨迹,并针对 Qwen3 进行了适配。

6 Poly-EPO
论文题目:
Poly-EPO: Training Exploratory Reasoning Models
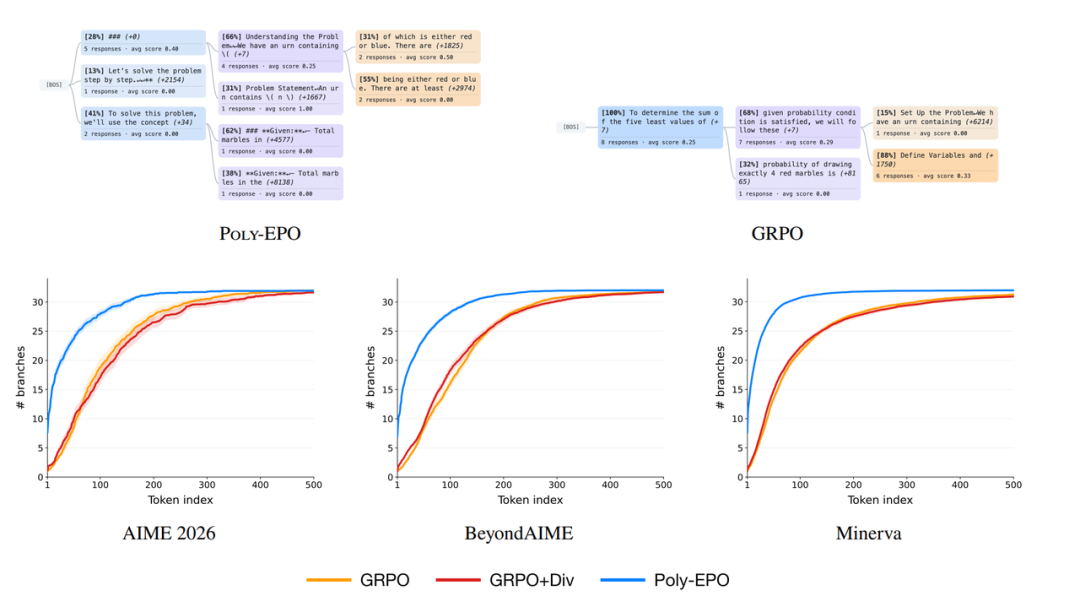
大模型强化学习后训练常导致生成多样性崩塌,阻碍了新推理路径的探索及测试时计算的扩展。为协同探索与利用,研究基于集合强化学习提出 Poly-EPO 算法。该方法打破孤立评估单条回复的传统,将一组回复的平均奖励与推理策略的多样性得分相乘作为联合优化目标,在优势函数中原生植入鼓励多样化探索的信号。在数学推理评测中,该算法成功避免了策略同质化,使 pass@k 覆盖率最高提升 20%,并在多数投票机制下展现出更强劲的扩展潜力。
论文及详细解读:https://go.hyper.ai/j9Z3C
以上就是本周论文推荐的全部内容,更多 AI 前沿研究论文,详见 hyper.ai 官网「最新论文」板块。
同时也欢迎研究团队向我们投稿高质量成果及论文,有意向者可添加神经星星微信(微信号:Hyperai01)。
下周再见!








