Command Palette
Search for a command to run...
论文周报丨 ProgramBench 让 AI 从零写软件,9 大模型集体翻车;无需额外真实世界数据,ExoActor 展现强场景泛化能力……速览一周 AI 前沿论文

随着语言模型逐渐被用于长期软件开发,现有基准测试已难以衡量模型在系统架构设计、模块划分和整体工程实现方面的表现。为此,SWE-Bench 团队提出了 ProgramBench 基准:仅向模型提供程序可执行文件和使用文档,要求其重新编写代码并复现程序行为。
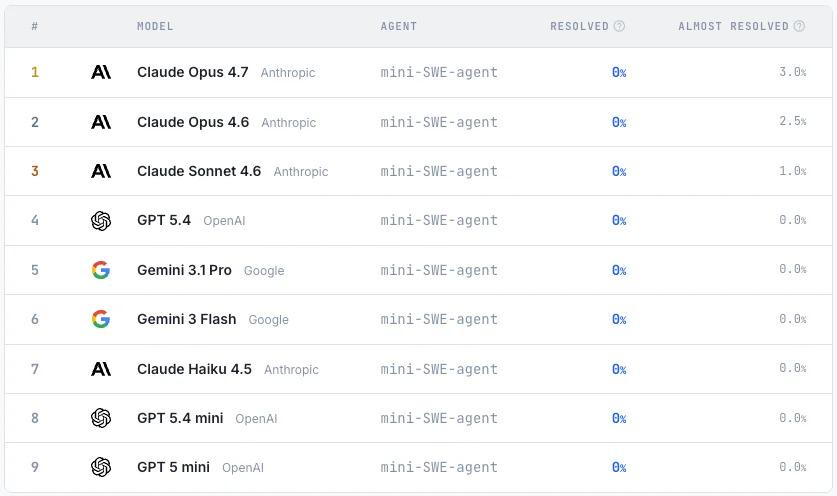
研究共构建了 200 个任务,涵盖数据库、编译器和命令行工具等多种软件类型,并通过行为测试评估模型生成程序与原程序的一致性。实验结果显示,目前主流模型仍难以完成复杂的软件重建任务,没有模型能够完全通过所有测试。表现最好的 Claude Opus 4.7 也仅在少数任务中达到较高通过率,说明大语言模型在完整软件工程能力上仍存在明显不足。
论文链接:https://go.hyper.ai/wExzR
最新 AI 论文:https://go.hyper.ai/hzChC
为了让更多用户了解学术界在人工智能领域的最新动态,HyperAI 官网(hyper.ai)现已上线「最新论文」板块,定时更新 AI 前沿研究论文。以下是我们为大家推荐的 8 篇热门 AI 论文,一起来速览本周 AI 前沿成果吧 ⬇️
本周论文推荐
1. ProgramBench
论文题目:
ProgramBench: Can Language Models Rebuild Programs From Scratch?
研究团队提出 ProgramBench,用于评估软件工程智能体从零构建完整软件项目的能力。该基准要求智能体仅依据程序及文档,实现与参考可执行文件行为一致的代码库,并通过智能体驱动的模糊测试进行端到端评估。
ProgramBench 共包含 200 个任务,覆盖 CLI 工具、 FFmpeg 、 SQLite 、 PHP 解释器等多类软件。对 9 个语言模型的实验表明,当前模型整体表现有限,最佳模型仅在 3% 的任务中通过 95% 的测试,且生成代码普遍呈现单体化、单文件结构,与人类软件工程实践存在明显差异。
论文及详细解读:https://go.hyper.ai/wExzR
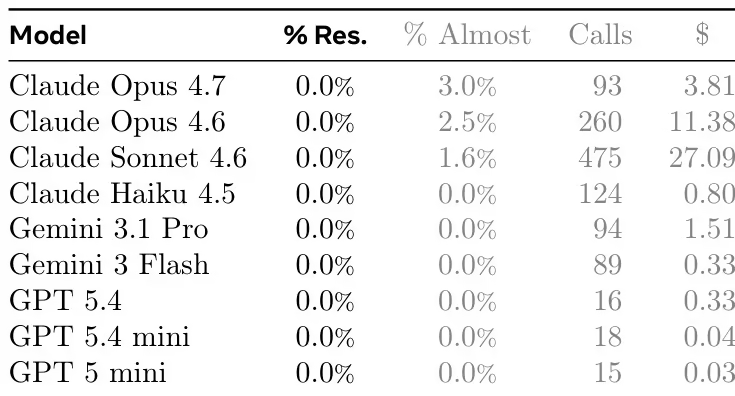
数据集构成与来源:作者从开源 GitHub 仓库中整理了 200 个任务实例。来源经过筛选,针对生产独立可执行文件的项目,主要在 Rust 、 Go 或 C/C++ 中。该集合包括多样化的功能类别,如文本处理、系统实用程序和语言解释器。

2. Uni-OPD
论文题目:
Uni-OPD: Unifying On-Policy Distillation with a Dual-Perspective Recipe
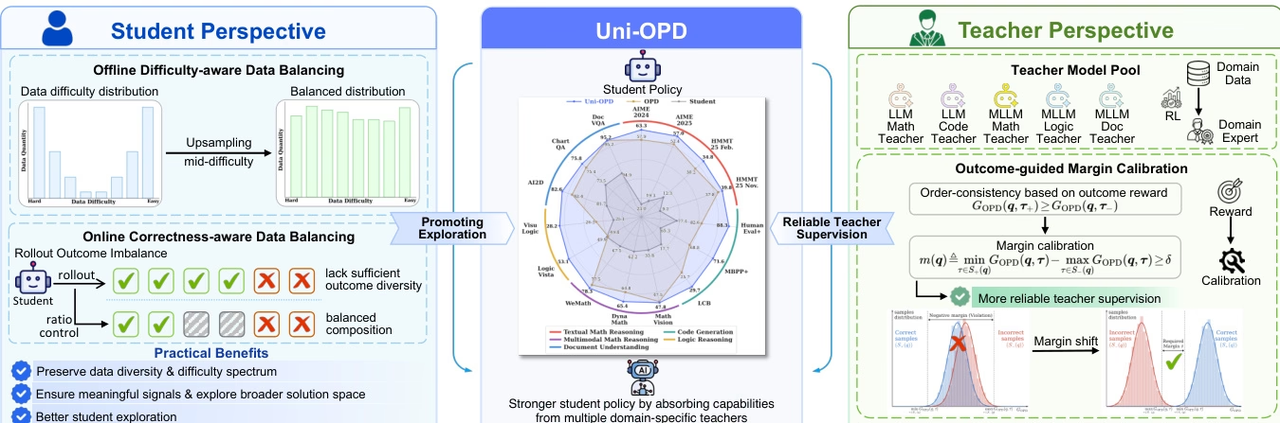
Uni-OPD 一个面向 LLMs 与 MLLMs 的统一在线蒸馏框架,用于提升多专家知识向学生模型的迁移效果。研究指出,现有 OPD 主要受限于高信息量状态探索不足以及教师监督信号不可靠两大问题。
为此,Uni-OPD 采用双视角优化策略:从学生侧引入数据平衡策略,增强对高信息量状态的探索;从教师侧提出基于结果引导的边际校准机制,恢复正确与错误轨迹间的顺序一致性,从而提升监督可靠性。实验覆盖五大领域和 16 个基准,涵盖单教师、多教师、强到弱及跨模态蒸馏等多种设置,验证了方法的有效性。
论文及详细解读:https://go.hyper.ai/8k4du
3. Faithful Uncertainty
论文题目:
Hallucinations Undermine Trust; Metacognition is a Way Forward
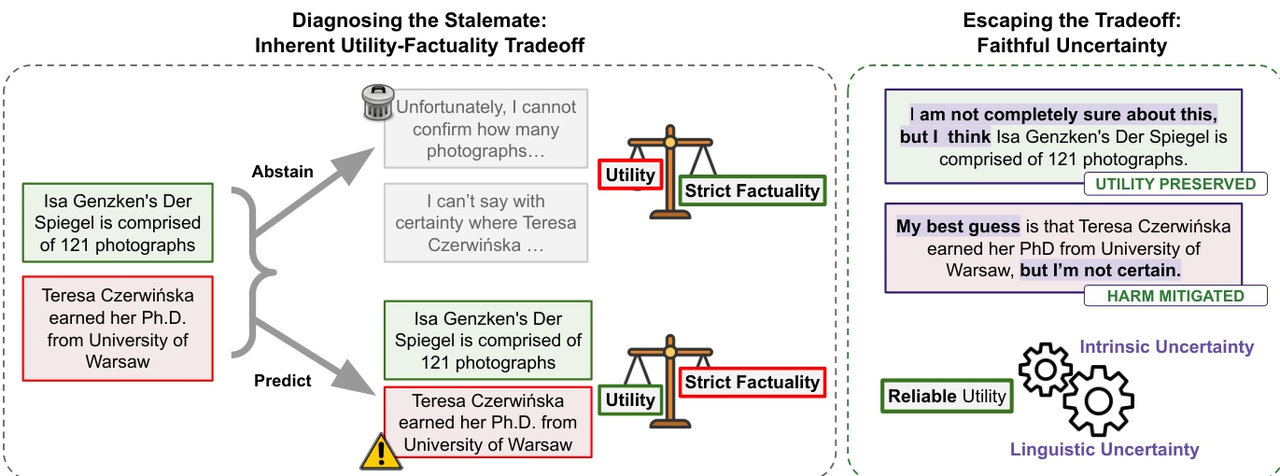
研究团队指出,尽管大语言模型在事实可靠性方面不断提升,但「幻觉」问题依然普遍存在,尤其是在缺乏外部工具支持的事实问答场景中。研究认为,现有进展更多来自知识规模扩展,而非模型真正具备区分「已知」与「未知」的能力,因此完全消除幻觉可能会与模型实用性形成天然权衡。
基于这一观点,研究提出「忠实的不确定性」概念,强调模型应真实表达自身的不确定性,使语言层面的不确定性与内部认知保持一致。这种元认知能力不仅有助于提升模型可信度,也能够为智能体系统中的搜索与决策提供更可靠的控制机制。
论文及详细解读:https://go.hyper.ai/G77rj
数据集构成与来源: 作者构建了一个包含 25,000 个样本的合成数据集,旨在复现 Nakkiran 等人(2025)记录的实证置信度分布特征。

4. PRISM
论文题目:
Beyond SFT-to-RL: Pre-alignment via Black-Box On-Policy Distillation for Multimodal RL
针对大型多模态模型在微调中因分布偏移影响后续强化学习的问题,研究团队提出了一种三阶段流程 PRISM 。该方法在监督微调与强化学习之间插入了基于策略内蒸馏的分布对齐阶段,利用混合专家(MoE)判别器提供解耦的修正信号。
结合 11.3 万条高质量 Gemini 演示数据,PRISM 在 Qwen3-VL 实验中显著提升了下游强化学习的性能,使 4B 和 8B 模型的准确率分别提升了 4.4 和 6.0 个点。
论文及详细解读:https://go.hyper.ai/5fsD3
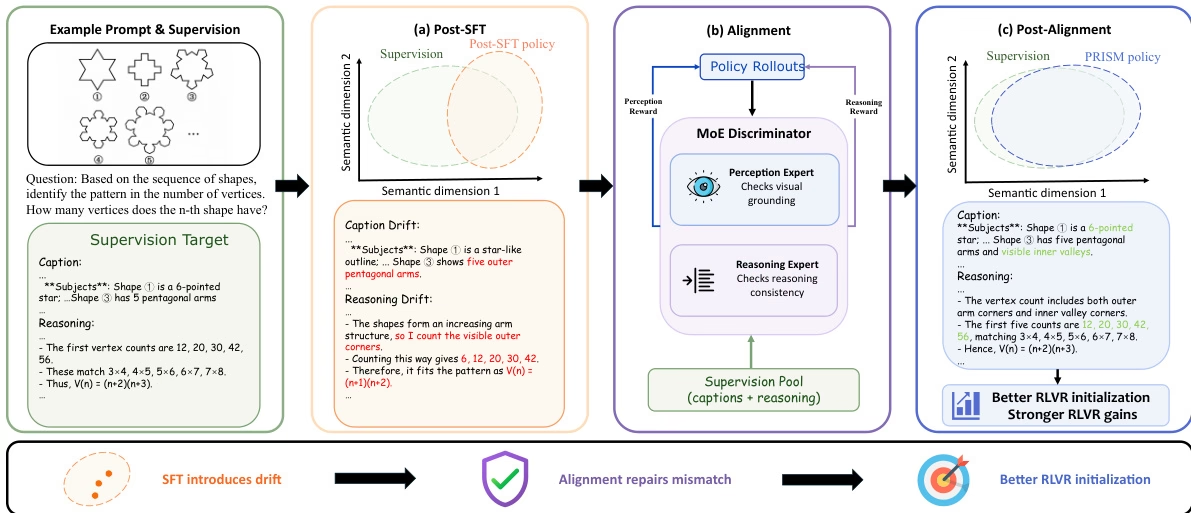
数据集构成与来源: 该论文构建了一个多模态推理语料库,数据源自涵盖数学推理、科学图表理解、图表解读与空间推理的公开基准测试。为扩展覆盖范围与稳定性,在此精选集合基础上补充了由同系列 Gemini 模型生成的 126 万条公开演示数据。
5. ExoActor
论文题目:
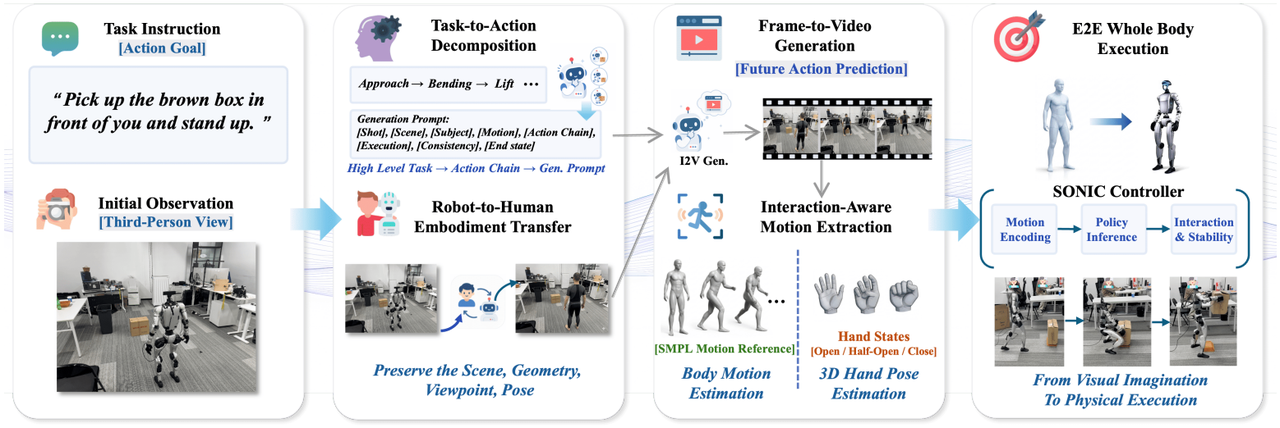
ExoActor: Exocentric Video Generation as Generalizable Interactive Humanoid Control
研究团队提出了 ExoActor 框架,该框架利用外中心视频生成作为统一接口,隐式编码机器人、环境与物体之间的协同交互,并通过人体运动估计与通用运动控制器将合成的执行视频转换为可执行的人形机器人行为,从而在无需额外实地数据采集的情况下,展示向新场景的泛化能力。
论文及详细解读:https://go.hyper.ai/OE5IH
6. Edit-R1
论文题目:
Leveraging Verifier-Based Reinforcement Learning in Image Editing
研究团队提出 Edit-R1,是一种用于图像编辑的强化学习框架。与传统仅输出整体分数的奖励模型不同,Edit-R1 将编辑指令拆解为多个原则,并基于思维链推理逐项验证编辑结果,从而生成更细粒度、可解释的奖励信号。研究进一步结合监督微调与 GCPO 强化学习策略,提升奖励模型对人类偏好的建模能力,并利用 GRPO 训练下游编辑模型。
实验结果表明,Edit-RRM 在图像编辑评估上超过了 Seed-1.5-VL 、 Seed-1.6-VL 等强大 VLM,并显著提升了 FLUX.1-kontext 等编辑模型的表现,同时展现出明显的参数扩展收益。
论文及详细解读:https://go.hyper.ai/MtBLB
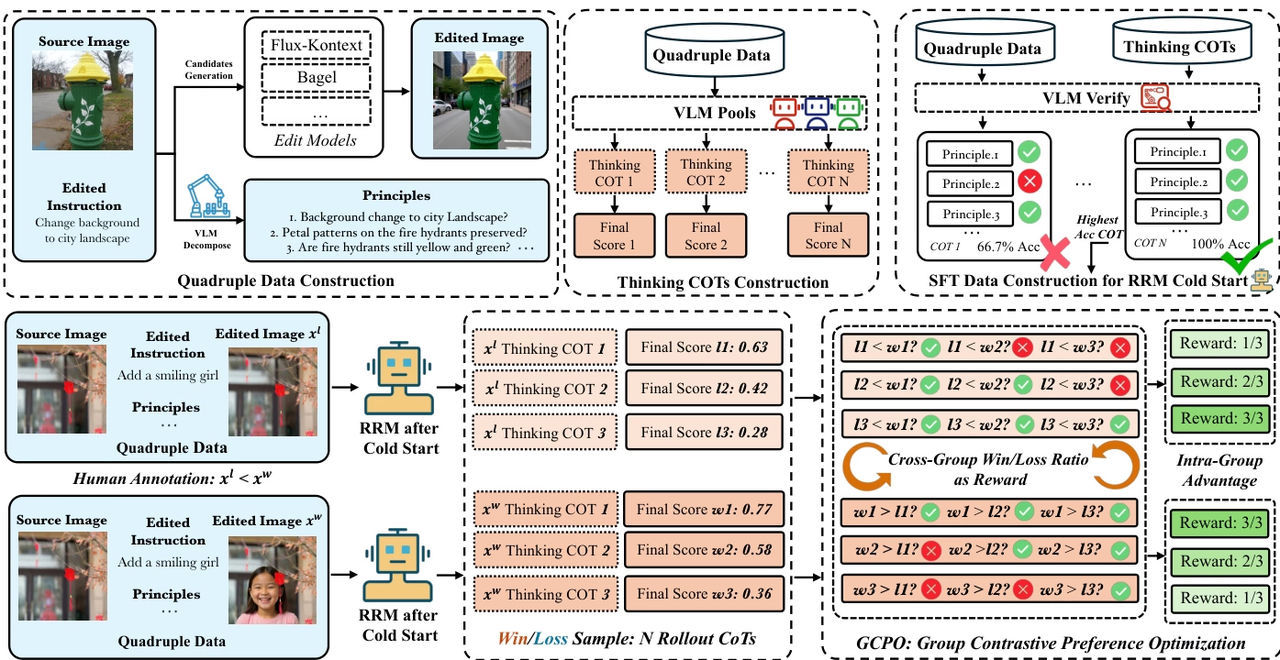
数据集构成与来源: 研究团队通过整理公开图像编辑基准中的 20 万条样本,构建了一个用于冷启动推理奖励模型的监督数据集。该初始集合通过多模型生成与系统性验证,扩展至约 200 万条数据四元组。

7. Co-Evolving Policy Distillation
论文题目:
Co-Evolving Policy Distillation
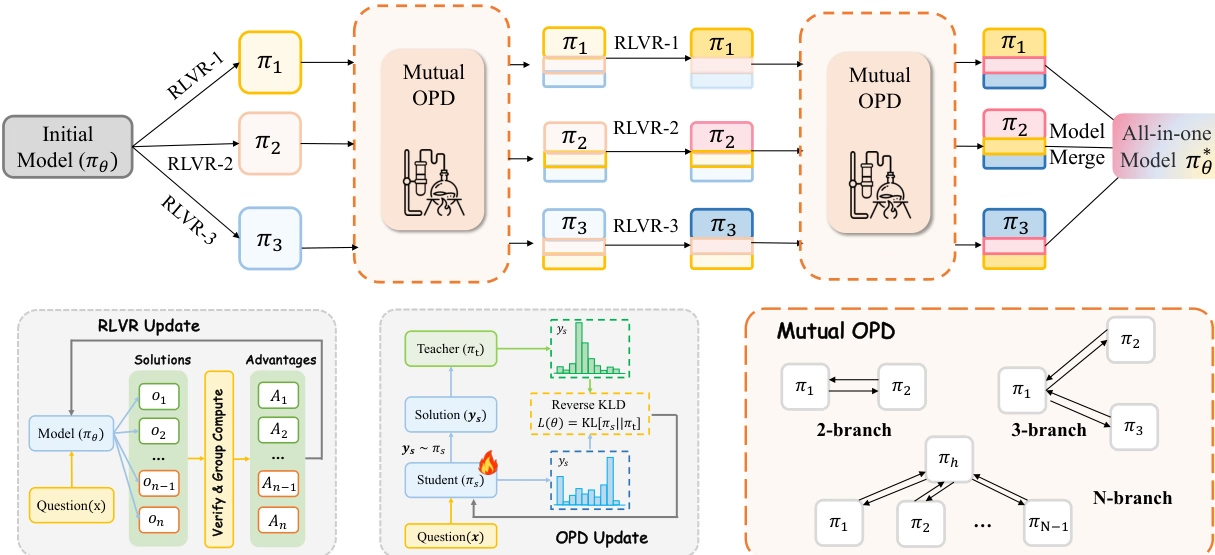
研究团队对 RLVR 与 OPD 两种主流后训练范式进行了统一分析,指出二者在多专家能力融合过程中存在不同局限:混合 RLVR 容易产生「跨能力发散代价」,而传统「先训练专家、再执行 OPD」的流程虽然避免了能力冲突,却因教师与学生之间行为模式差异过大,难以充分继承专家能力。
为解决这一问题,研究提出协同演化策略蒸馏 CoPD,在专家持续进行 RLVR 训练的同时同步引入双向 OPD,使各专家互为教师并协同演化,从而在保持能力互补性的同时提升行为一致性。实验结果表明,CoPD 能够有效整合文本、图像与视频推理能力,性能不仅显著优于混合 RLVR 与 MOPD 等强基线,甚至在部分任务上超过领域专家模型。
论文及详细解读:https://go.hyper.ai/cCyrG

8. ClawGym
论文题目:
ClawGym: A Scalable Framework for Building Effective Claw Agents
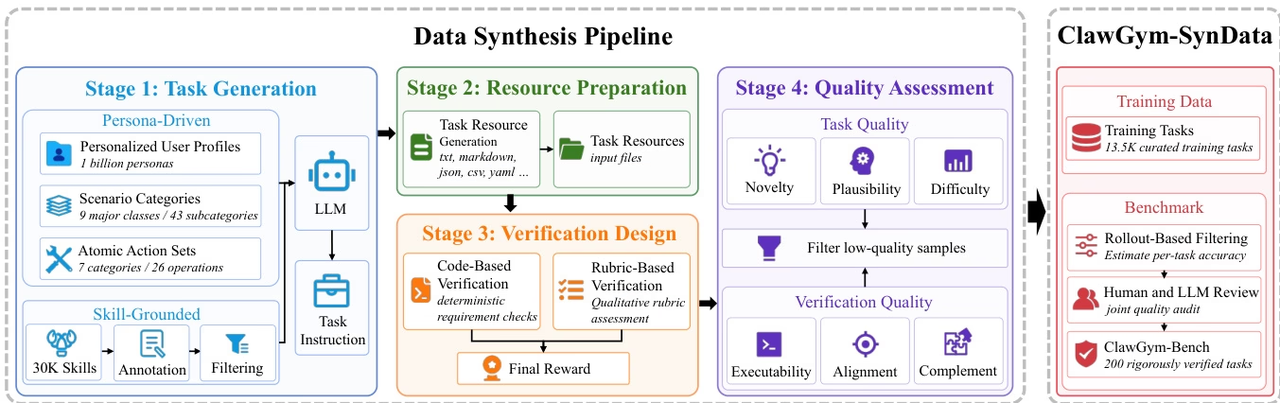
研究团队提出 ClawGym,一个面向 Claw-style personal agent 开发全生命周期的可扩展框架,用于支持本地文件、工具调用与持久化工作区状态下的复杂多步工作流。
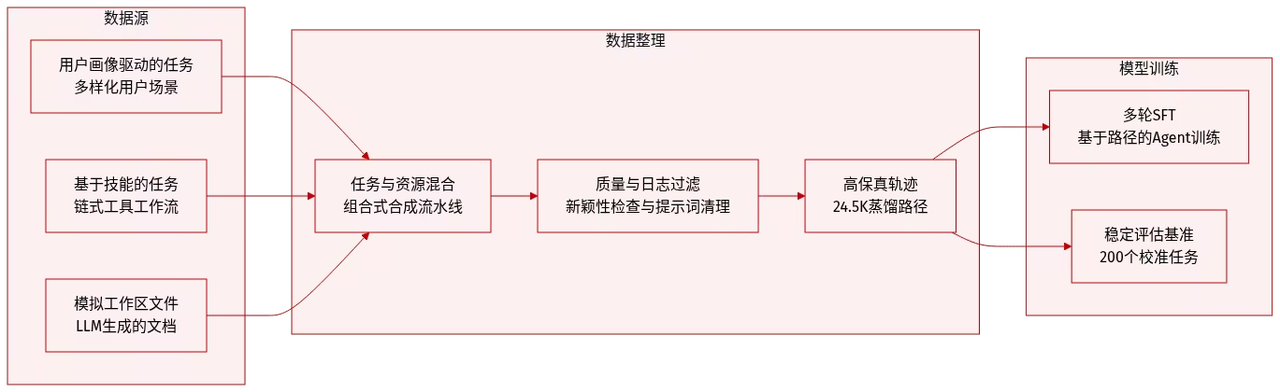
框架包含合成数据集 ClawGym-SynData,覆盖 1.35 万个经筛选任务,并结合人设意图、技能操作、模拟工作区与混合验证机制;同时基于黑盒 rollout 轨迹训练 ClawGym-Agents,并通过轻量级强化学习流水线提升能力;此外构建了经自动筛选及人工与 LLM 联合审核校准的基准测试集 ClawGym-Bench,用于可靠评估。
论文及详细解读:https://go.hyper.ai/yZwa5
数据集来源:研究团队通过 ClawGym-SynData 框架生成训练数据,该框架结合面向多样化用户场景的人格驱动自上而下合成,以及将 OpenClaw 能力串联为真实工作流的技术基础自下而上合成。
以上就是本周论文推荐的全部内容,更多 AI 前沿研究论文,详见 hyper.ai 官网「最新论文」板块。
同时也欢迎研究团队向我们投稿高质量成果及论文,有意向者可添加神经星星微信(微信号:Hyperai01)。
下周再见!








