Command Palette
Search for a command to run...
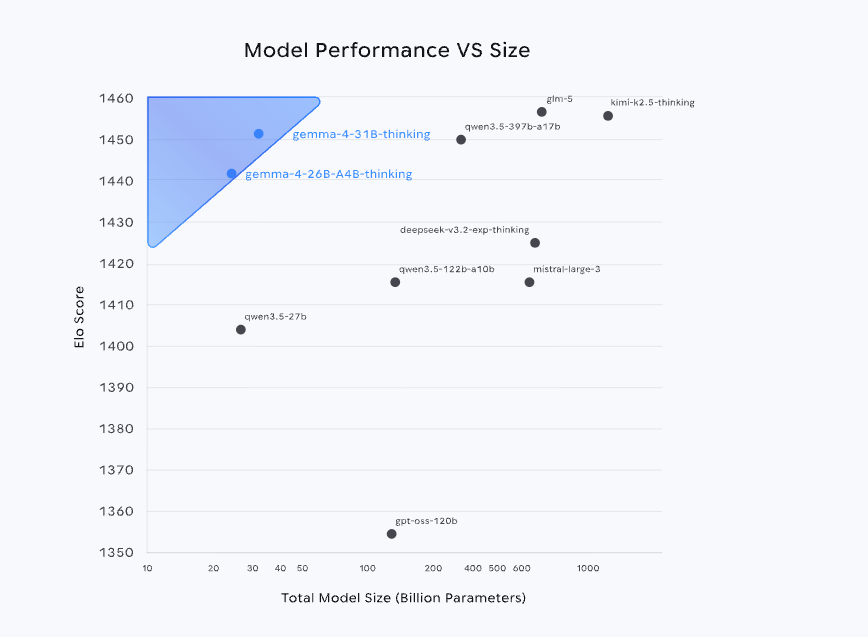
一键部署 Gemma 4 31B,最高 256K 上下文,能力媲美 Qwen3.5 397B

近期,Google DeepMind 开源了 Gemma 4 系列模型,依托与 Gemini 3 同源的技术体系,其不仅在 Arena AI 排行榜中跻身全球前三,更以远小于同级竞品的参数规模,实现了接近甚至超越更大尺寸模型的能力表现。同时,基于 Apache 2.0 许可证的开源策略,也进一步降低了应用门槛,使其在实际生产环境中的落地潜力大幅提升。
从产品形态来看,Gemma 4 并非单一模型,而是覆盖 E2B 、 E4B 、 26B A4B 到 31B 的多尺寸体系,分别对应移动端、本地部署到高性能算力环境等不同场景。这种分层设计的核心逻辑在于:以「规模—性能—成本」的平衡,满足差异化需求——小模型强调轻量与实时性,而大模型则专注复杂推理与高精度任务。
其中,31B 版本作为当前系列中的性能上限,其能力水平甚至可以媲美 Qwen 3.5 397B,应用场景上,31B 版支持图文输入与文本输出,具备最高达 256K tokens 的上下文窗口,并原生支持推理、函数调用以及系统提示(system prompts),同时还支持超过 140 种语言,因此在高质量问答、代码辅助以及智能体(agent)服务等场景中表现出色。
目前,HyperAI 官网(hyper.ai)的教程版块已经上线了「一键部署 Gemma-4-31B-it」,助力开发者低门槛体验先进模型。
在线运行:
Demo 运行
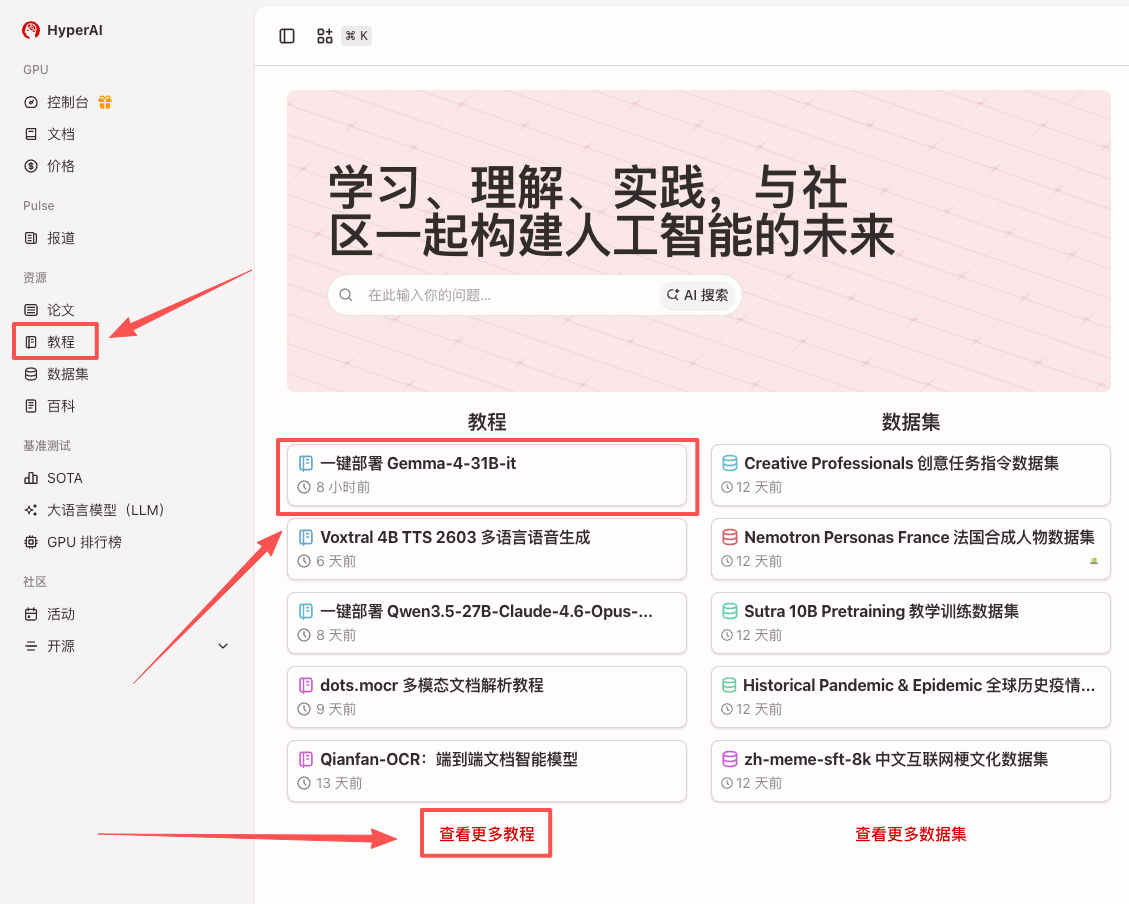
1. 进入 hyper.ai 首页后,选择「教程」页面,或点击「查看更多教程」,选择「一键部署 Gemma-4-31B-it」,点击「运行此教程」。
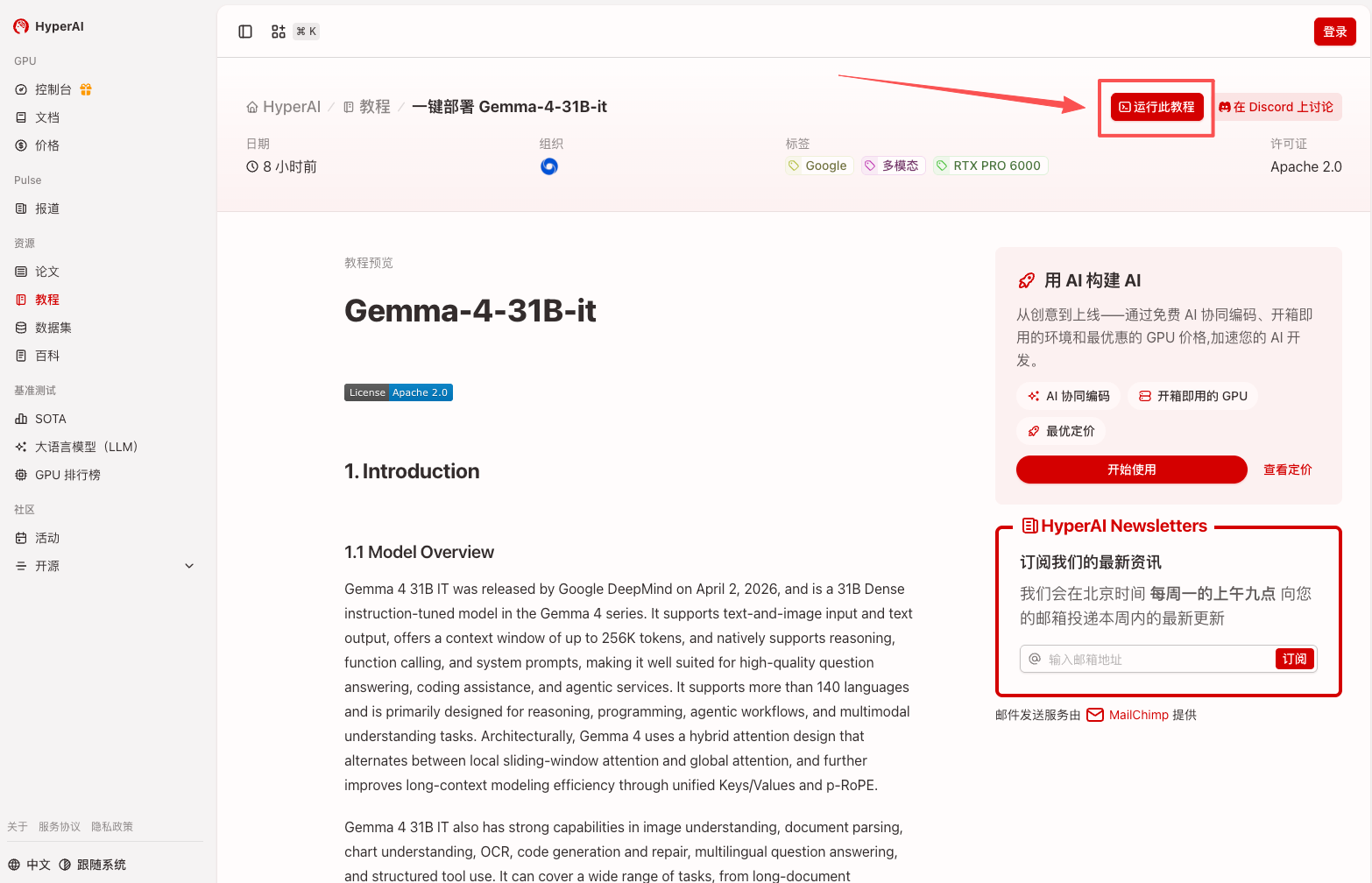
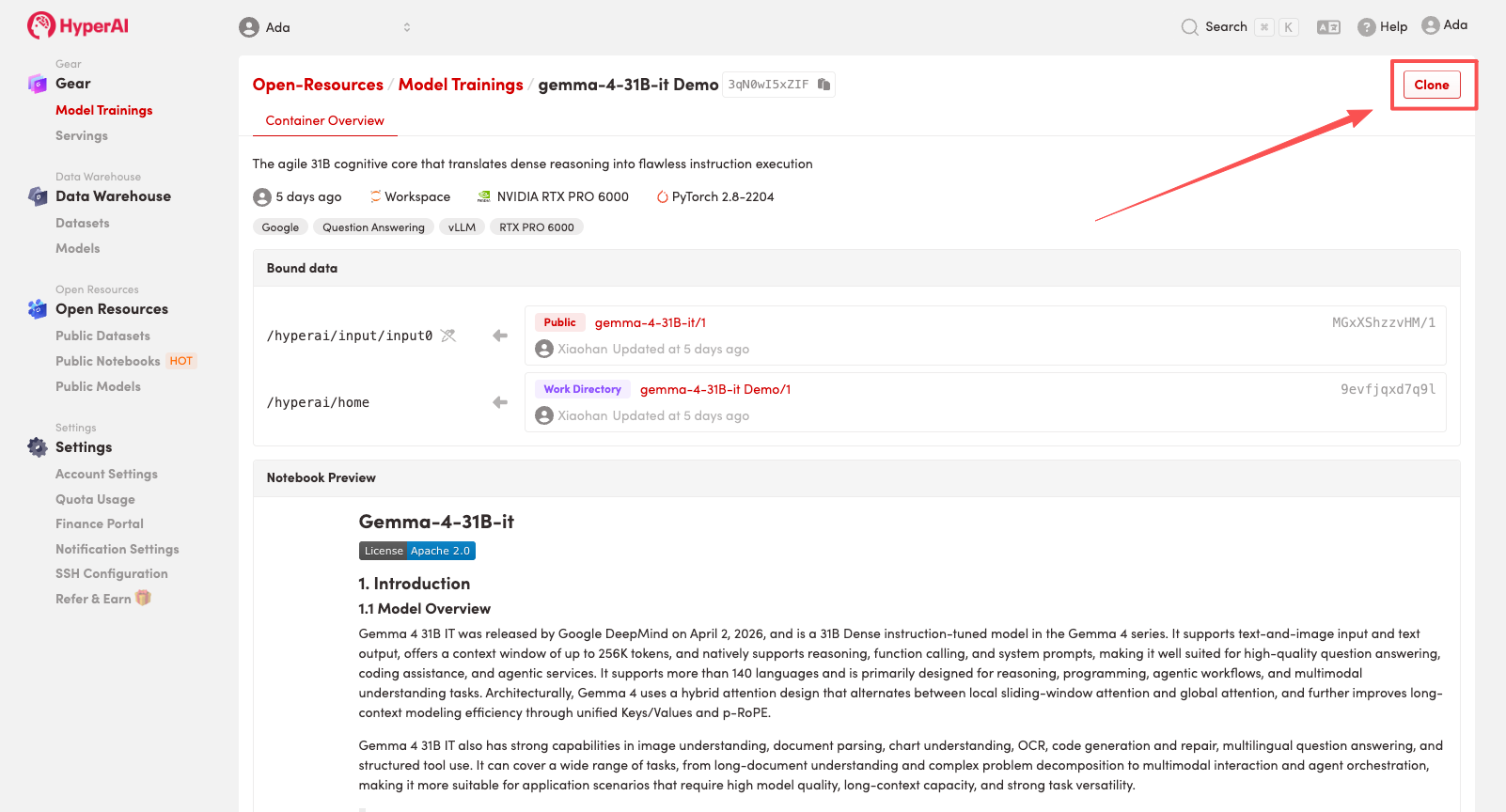
2. 页面跳转后,点击右上角「Clone」,将该教程克隆至自己的容器中。
注:页面右上角支持切换语言,目前提供中文及英文两种语言,本教程文章以英文为例进行步骤展示。
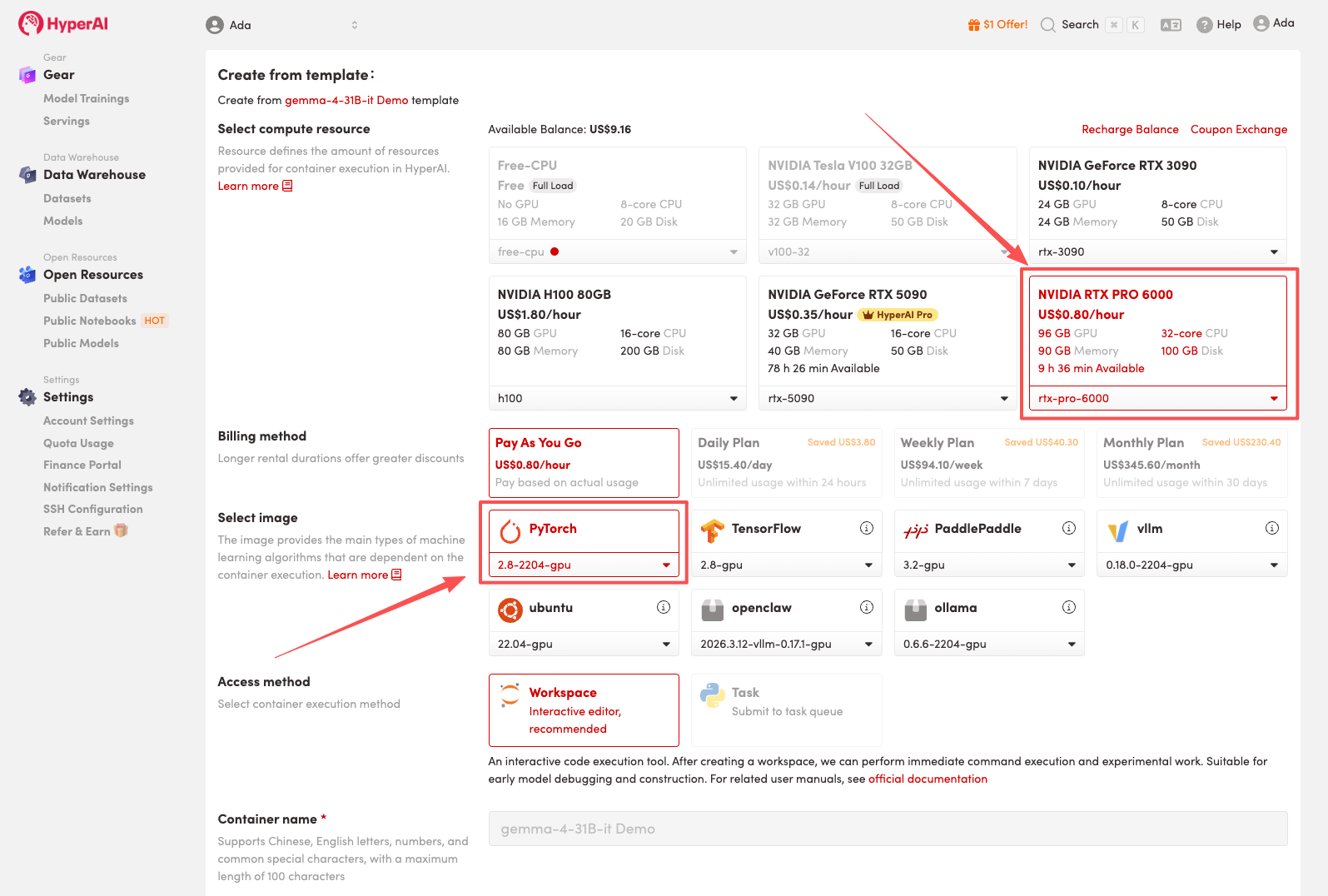
3. 选择「NVIDIA RTX PRO 6000」以及「PyTorch」镜像,点击「Continue job execution(继续执行)」。
HyperAI 为新用户准备了注册福利,仅需 $1,即可获得 20 小时 RTX 5090 算力(原价 $7),资源永久有效。
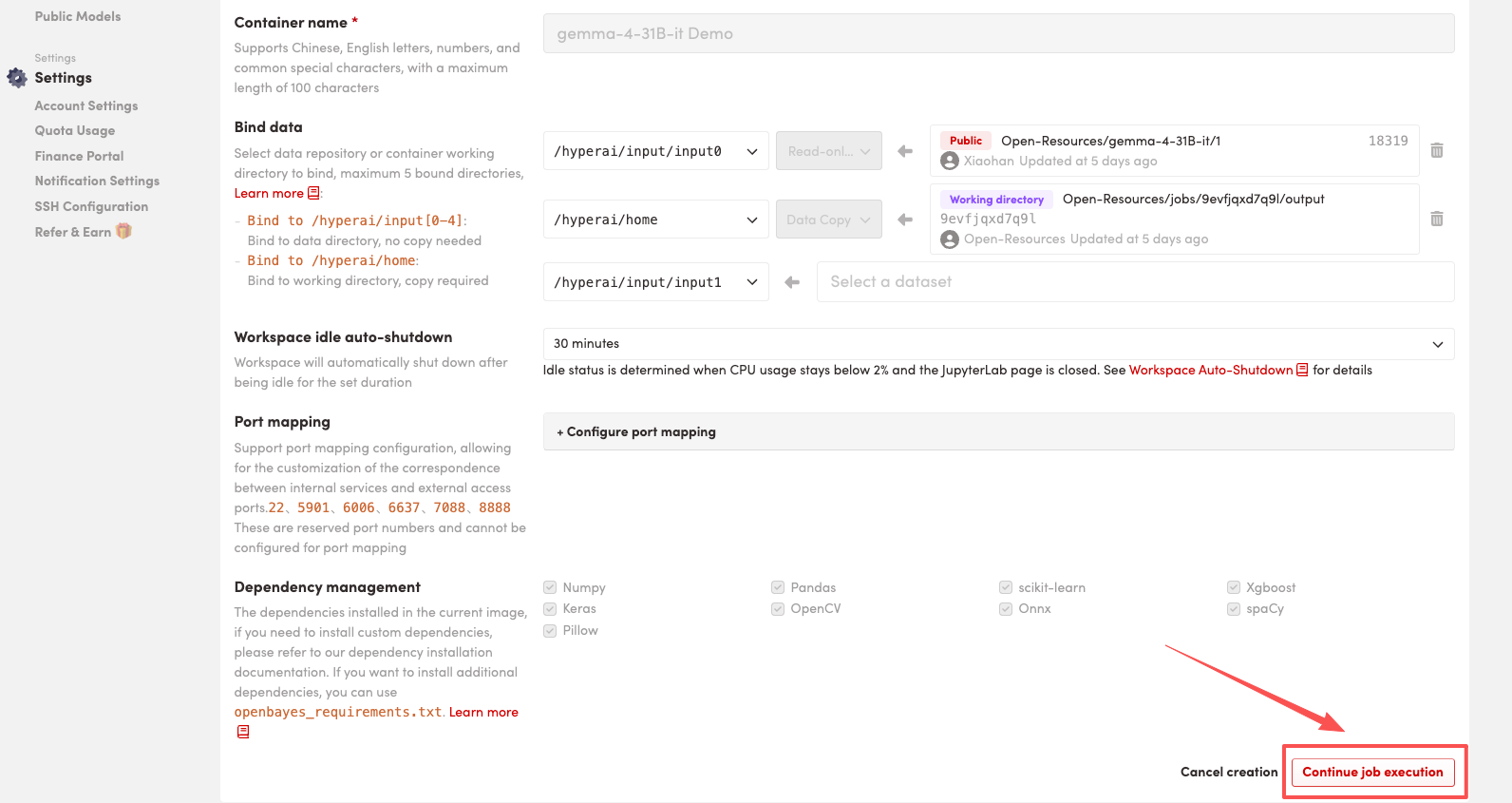
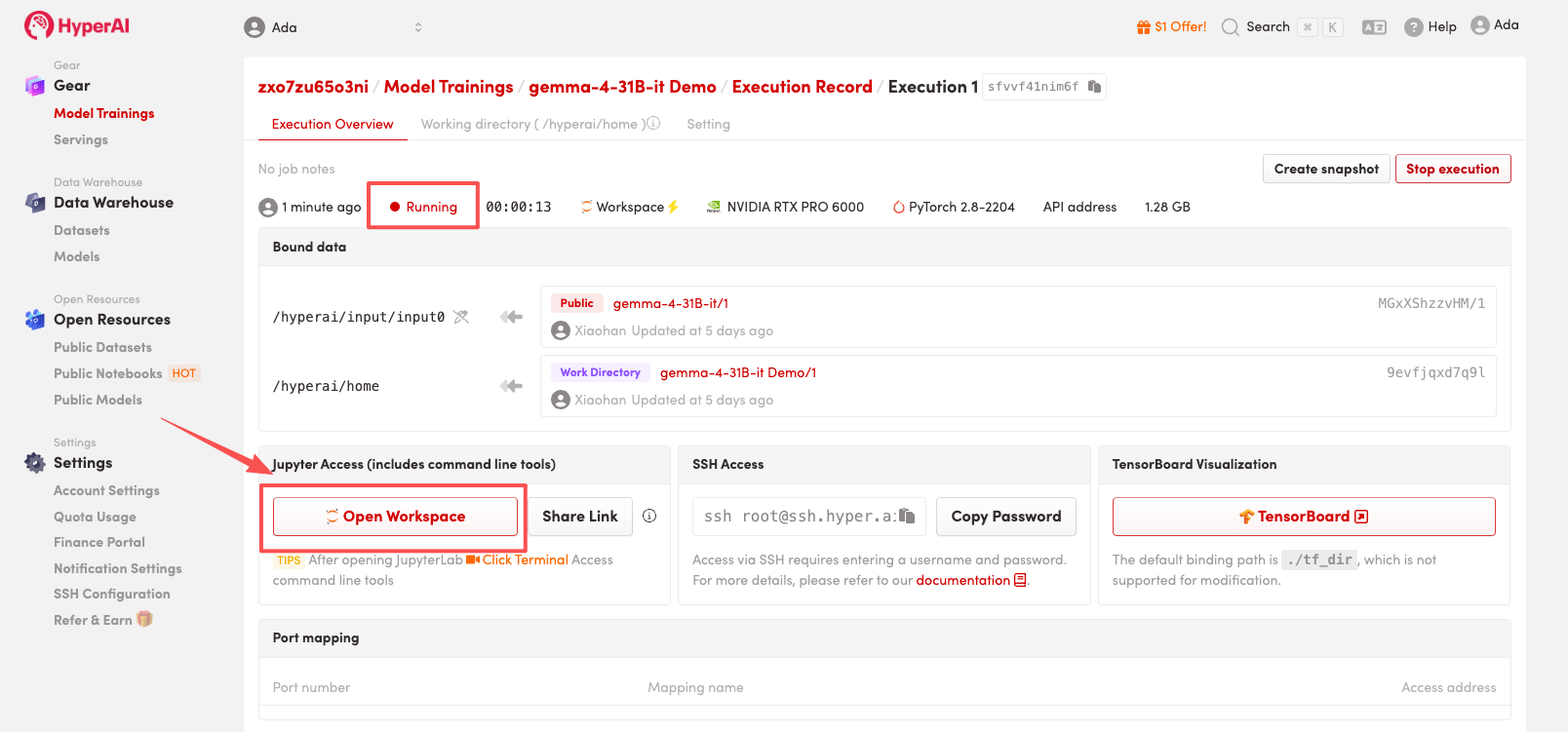
4. 等待分配资源,当状态变为「Running(运行中)」后,点击「Open Workspace」进入 Jupyter Workspace 。
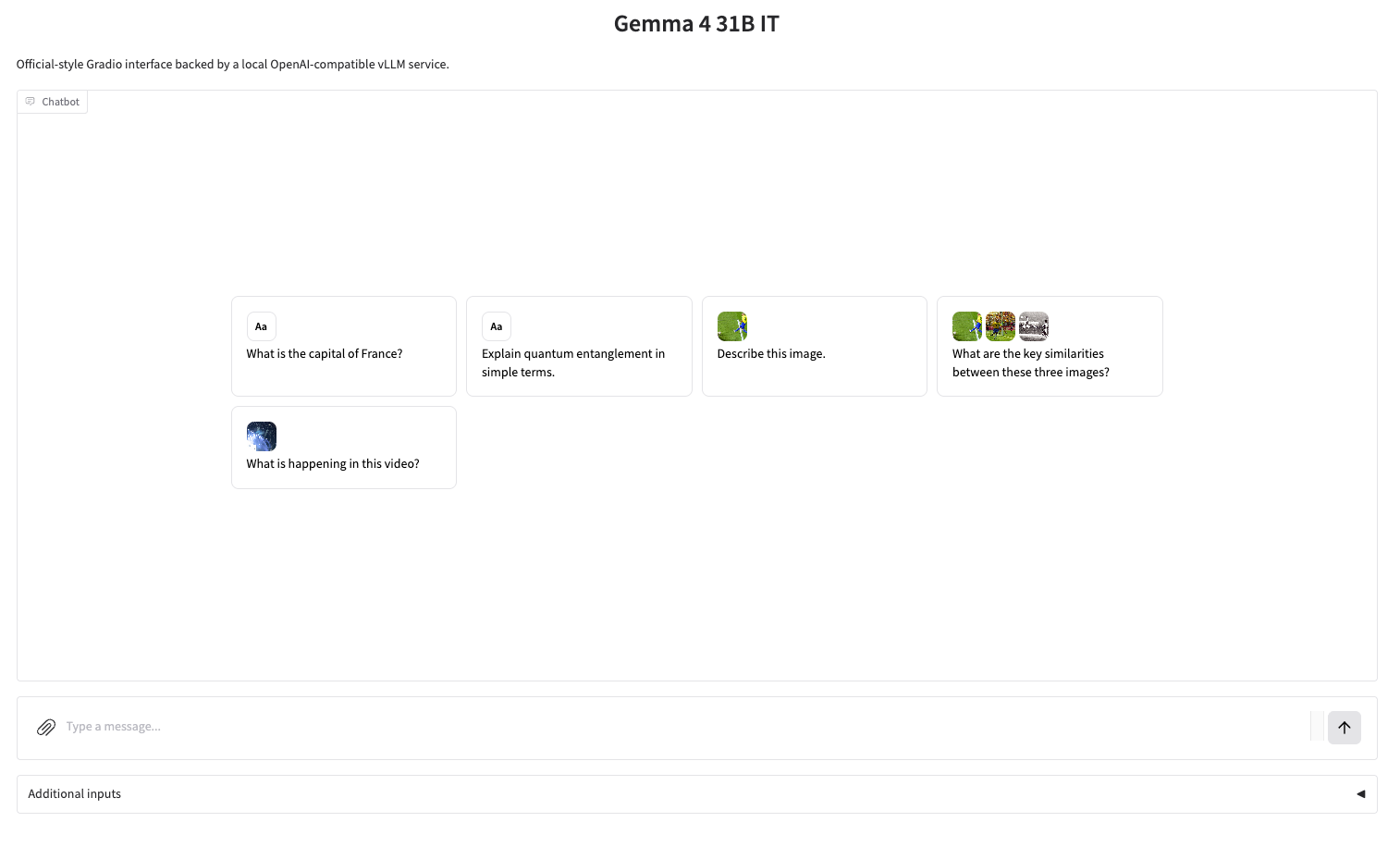
效果展示
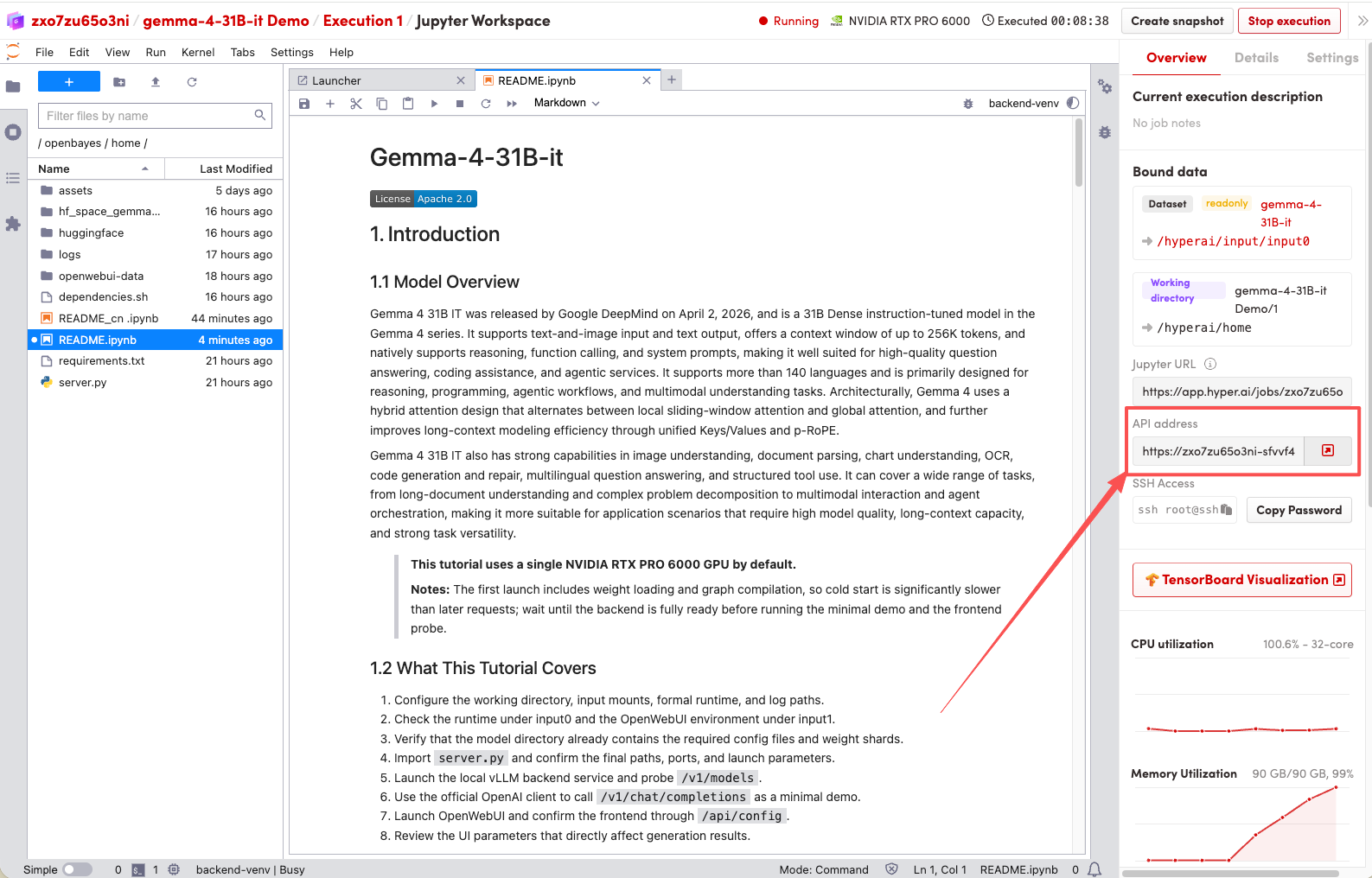
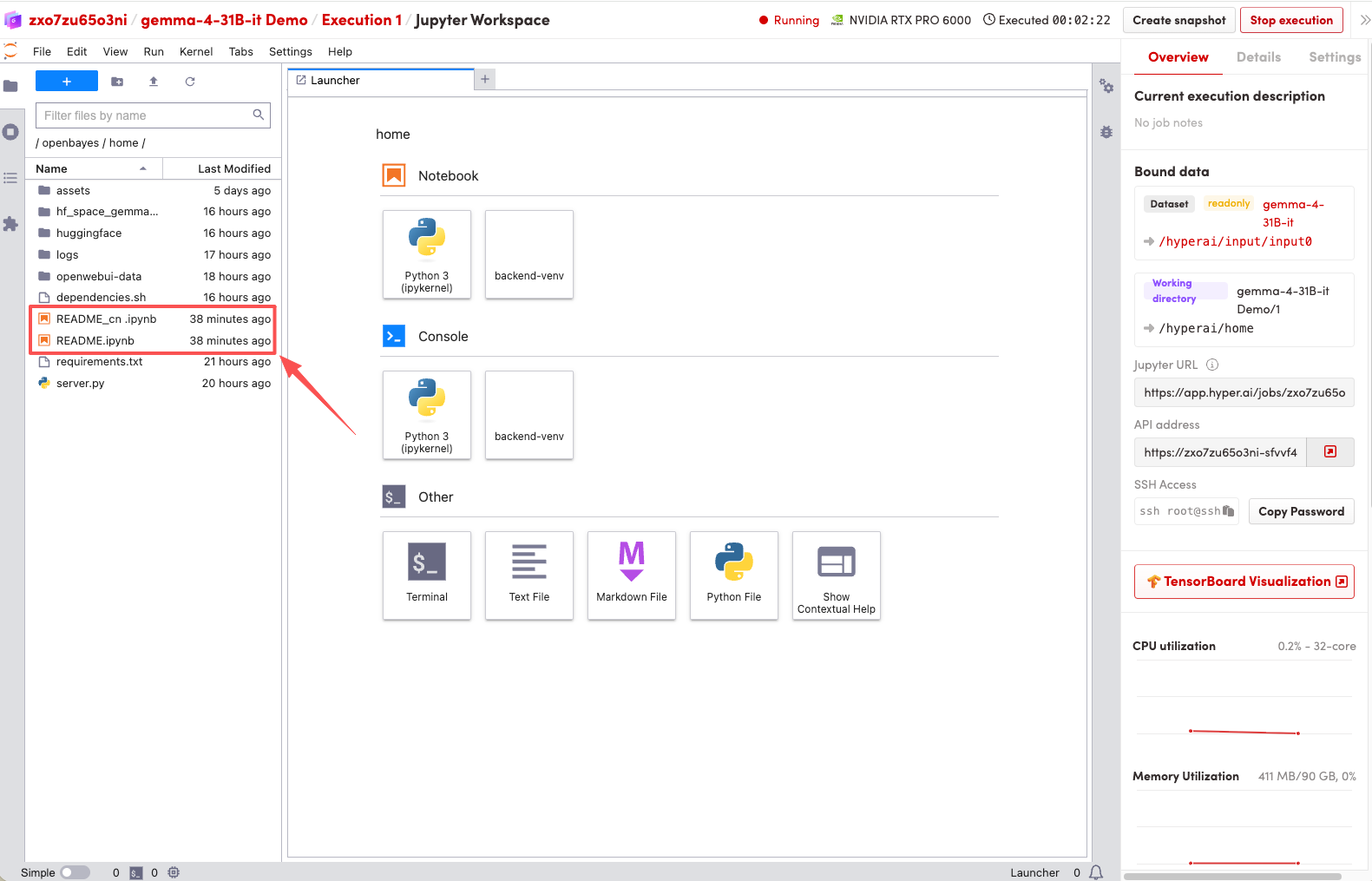
1. 页面跳转后,点击左侧 README 文件,进入后点击上方 Run(运行)。
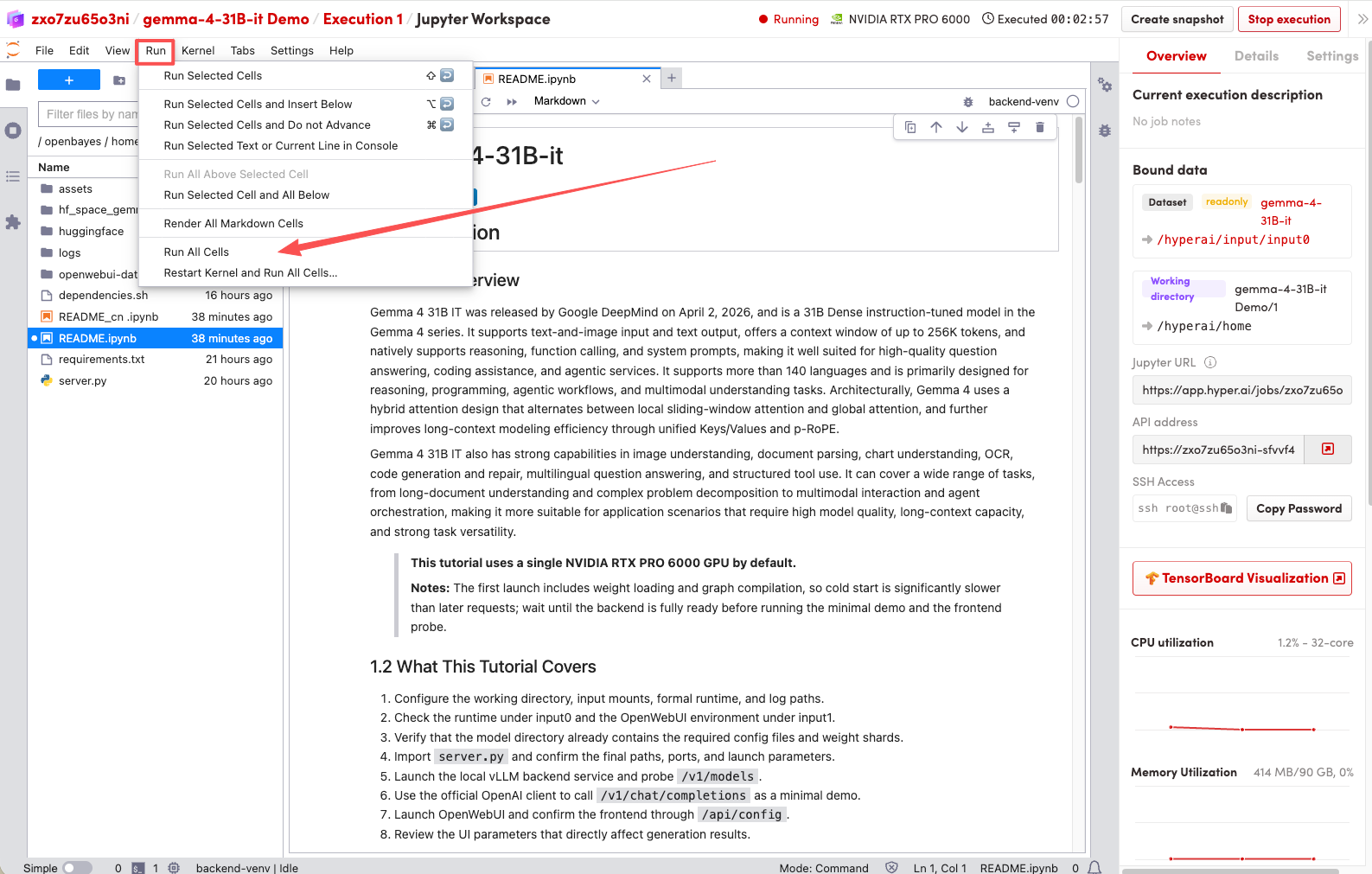
2. 待运行完成,即可点击右侧 API 地址跳转至 demo 页面。