Command Palette
Search for a command to run...
教程汇总丨开源小模型综合智能水平追平 GPT-5,一站测评 Qwen 3.5/Gemma 4 等热门模型

第三方评测机构 Artificial Analysis 于 4 月 14 日发布针对 32B 以下开源模型的对比报告显示,Qwen3.5 27B 与 Gemma 4 31B 两款小尺寸模型,在综合智能水平上已追平 GPT-5 对应档位。其中,Qwen3.5 27B(推理版)在 Intelligence Index 上取得 42 分,对标 GPT-5(medium);Gemma 4 31B(推理版)以 39 分匹配 GPT-5(low)。
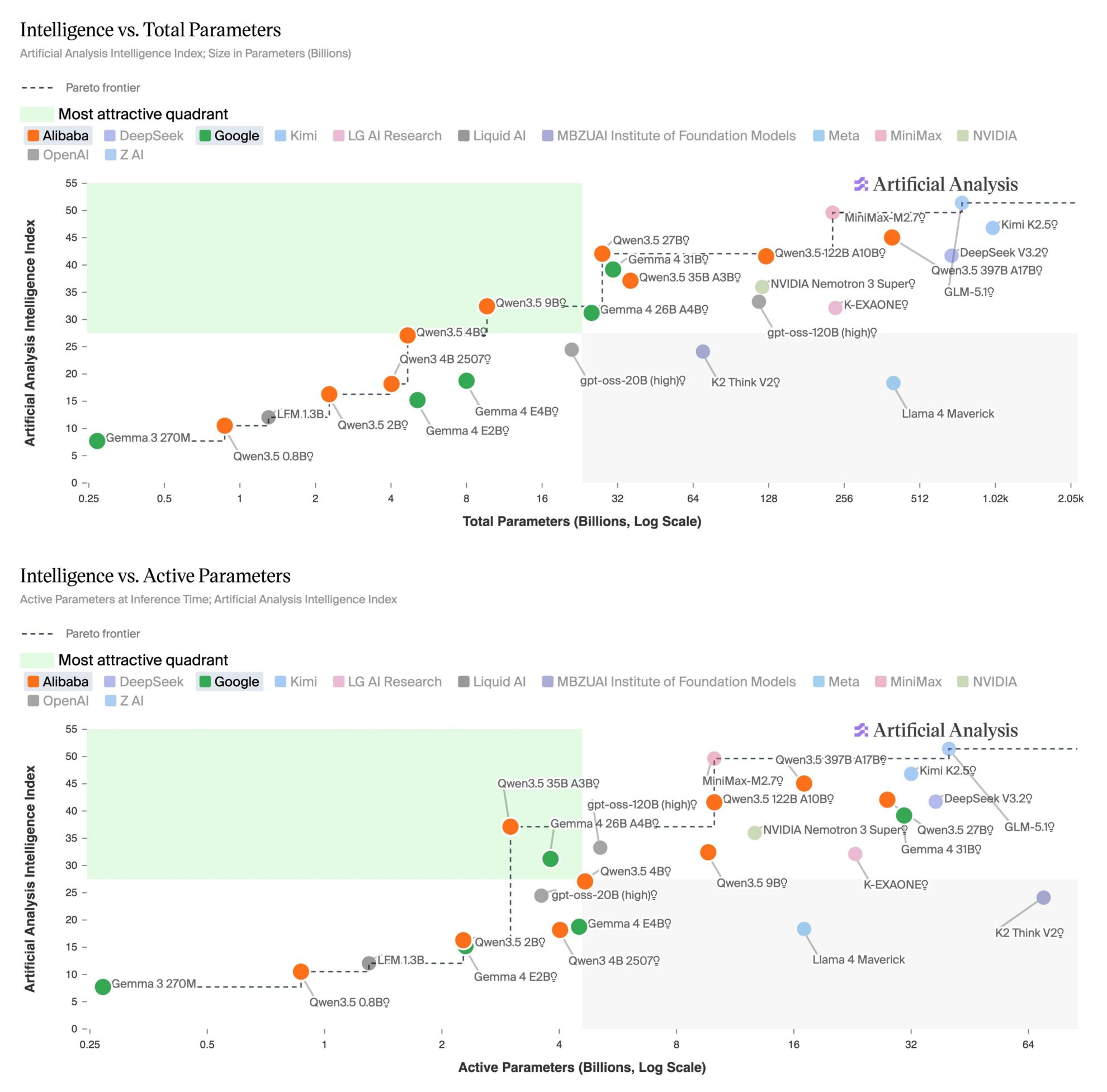
报告指出,这一代子 32B 模型在推理能力与 agent 表现上进步显著。 Qwen3.5 27B 在 Agentic Index 上达到 55 分,超过 GPT-5(medium)的 46 分;Gemma 4 31B 在 TerminalBench Hard 和 HLE 等复杂任务上也领先 GPT-5(low)。与此同时,两者均原生支持多模态输入,在 MMMU-Pro 等视觉理解任务中表现居于同级开源模型前列。
不过,小模型在知识准确性与幻觉控制方面仍明显落后。两者在 AA-Omniscience 指标上分别为 -42 和 -45,而 GPT-5 相关版本为 -10,显示出参数规模对知识记忆能力的持续影响。
在部署层面,这类模型的实用性显著提升。上述两款模型均可在单张 NVIDIA H100 上运行,并可通过量化在个人设备上本地部署,降低了使用门槛。同时,开源权重阵营整体也在快速逼近前沿,大模型如 GLM-5.1 等已将差距缩小至个位数分值。
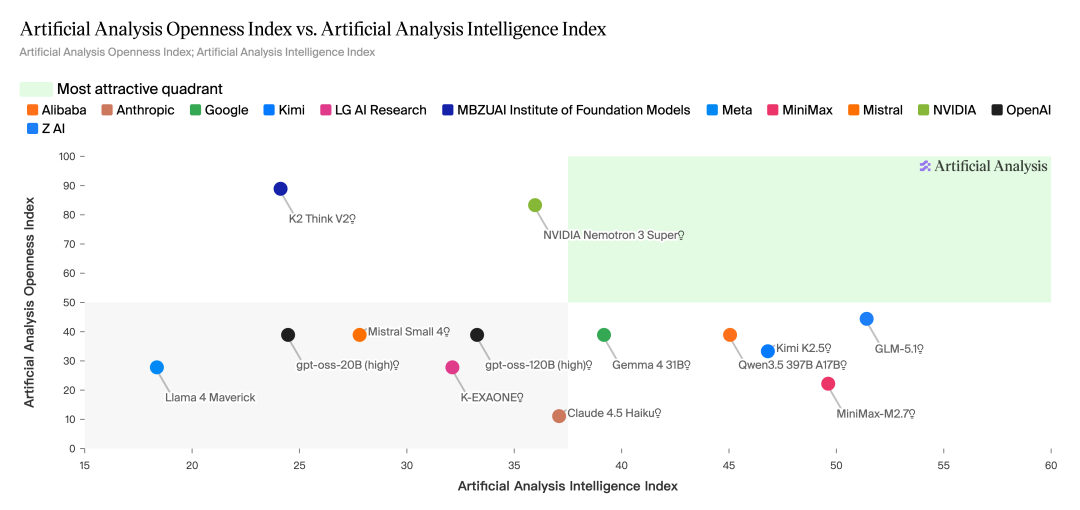
一直以来,HyperAI 为帮助开发者快速上手、验证最新开源模型,持续在官网的「教程」版块更新热门模型的在线部署 notebook 。本文为大家汇总了 Artificial Analysis 报告中提及的高质量开源模型及其一键部署教程,快来亲自体验逼近闭源模型的高性能吧!
更多在线教程:
免费领取算力福利
为了便于大家体验 HyperAI 的稳定算力服务,我们准备了丰富的「算力礼包」,内含 NVIDIA RTX 5090 、 PRO 6000 等 GPU 资源。
扫码添加微信(微信号:Hyperai01),备注注册平台所用的邮箱,即可收到空投礼包!数量有限,手慢无~
欢迎登录官网查看更多内容:

NVIDIA-Nemotron-3-Super-120B
NVIDIA Nemotron 3 Super NVFP4 由 NVIDIA Corporation 在 2026 年 3 月发布。该模型是一个 120B 总参数、 12B 激活参数的大语言模型,采用 LatentMoE 混合架构,并支持最长 1M tokens 上下文。
该模型面向长上下文推理、 Agent 工作流、工具调用、 RAG 与高吞吐问答等场景。在交互方式上,模型同时支持是否启用 reasoning 模式,并可以通过标准化聊天模板参数在普通问答与推理增强模式之间切换。
在线运行:

Qwen3.5-27B-Claude-4.6-Opus–Reasoning-Distilled
2026 年 3 月,Jackrong 开源了一款高性能推理模型 Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled,其基于 Qwen3.5-27B 基础架构构建,并融合了从 Claude-4.6 与 Opus 中蒸馏得到的先进推理能力,在保持原有强大语言理解与表达能力的基础上,显著增强了复杂问题求解与多轮对话交互表现。
在核心能力层面,该模型通过引入高质量思维链蒸馏技术,实现了推理能力的全面升级,使其在数学推导、逻辑分析、规划决策以及多步骤任务拆解等场景中表现尤为突出。相比传统模型,该系统不仅能够生成答案,更能够以结构化方式逐步分析问题,将复杂任务拆解为清晰可执行的逻辑步骤,从而提升整体推理稳定性与结果可靠性。
在线运行:
Gemma-4-31B-it
Google DeepMind 开源的 Gemma 4 系列模型,依托与 Gemini 3 同源的技术体系,不仅在 Arena AI 排行榜中跻身全球前三,更以远小于同级竞品的参数规模,实现了接近甚至超越更大尺寸模型的能力表现。
从产品形态来看,Gemma 4 并非单一模型,而是覆盖 E2B 、 E4B 、 26B A4B 到 31B 的多尺寸体系,分别对应移动端、本地部署到高性能算力环境等不同场景。其中,31B 版本作为当前系列中的性能上限,其能力水平甚至可以媲美 Qwen 3.5 397B 。
应用场景上,31B 版支持图文输入与文本输出,具备最高达 256K tokens 的上下文窗口,并原生支持推理、函数调用以及系统提示(system prompts),同时还支持超过 140 种语言,因此在高质量问答、代码辅助以及智能体(agent)服务等场景中表现出色。
在线运行:
CPU 部署 Qwen3.5-9B-GGUF
Qwen3.5 是由 阿里巴巴通义千问团队 发布的新一代多模态大语言模型系列,支持文本与图像输入,并生成文本输出,面向对话、推理、编程以及视觉理解等任务。其中,Qwen3.5-9B 是该系列中的 9B 参数版本,在能力与部署成本之间取得平衡,适用于资源受限环境下的端侧或本地部署推理。
在本教程中,我们将使用社区提供的 GGUF 权重(Q4_K_M 量化版本),并结合视觉编码器(mmproj GGUF 文件)。通过 llama.cpp 启动一个兼容 OpenAI 接口的后端服务,并连接 OpenWebUI,从而提供基于浏览器的对话交互界面。
在线运行:
查找更多热门教程:








