HyperAI
Command Palette
Search for a command to run...
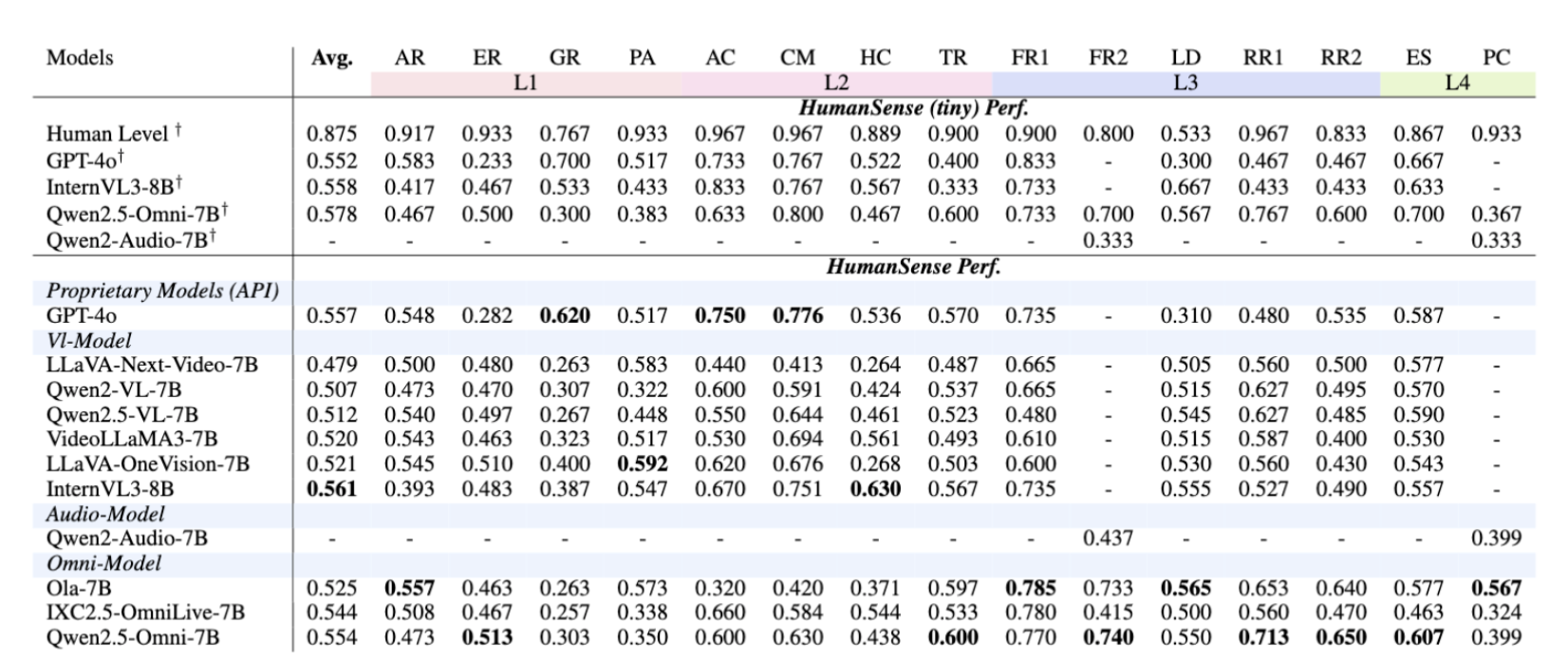
HumanSense Benchmark 是由西安交通大学联合蚂蚁集团于 2025 年发布的一个人体感知评测基准数据集,相关论文成果为「HumanSense: From Multimodal Perception to Empathetic Context-Aware Responses through Reasoning MLLMs」,旨在全面衡量模型在视觉、音频与文本等多模态信息融合下的真实交互能力。 该数据集包含 3,291 条基于视频的问题和 591 条基于音频的问题,涵盖 15 项由浅入深的任务,任务结构呈四层金字塔式,包括:
- L1–L2 感知层:视觉、音频与跨模态的基础与复杂感知能力;
- L3 理解层:基于互动情境的隐含关系、情绪与状态理解能力;
- L4 响应层:交互场景中的策略性与情境化应答能力。
该数据集从真实视频、音频与多模态对话中构建问题,通过多种开源数据集与真实场景录制生成,覆盖从外观识别、情绪识别到关系理解、心理对话等多类人本交互任务,是当前更贴近真实人类沟通场景的多模态评测基准之一。
数据集分布
Citation
@article{qin2025humansense,
title={HumanSense: From Multimodal Perception to Empathetic Context-Aware Responses through Reasoning MLLMs},
author={Qin, Zheng and Zheng, Ruobing and Wang, Yabing and Li, Tianqi and Yuan, Yi and Chen, Jingdong and Wang, Le},
journal={arXiv preprint arXiv:2508.10576},
year={2025}
}
此数据集由社区用户贡献,仅用于教育和信息目的。如有任何内容涉及版权侵权,请通过 [email protected] 联系我们,我们将及时审核并删除。