HyperAI
Command Palette
Search for a command to run...
CC-OCR 文字识别数据集
CC-OCR 数据集由阿里巴巴集团、华中科技大学和华南理工大学于 2024 年联合开发,旨在为评估大型多模态模型在文字识别(OCR)任务中的表现提供一个全面且具有挑战性的基准,相关论文成果为「CC-OCR: A Comprehensive and Challenging OCR Benchmark for Evaluating Large Multimodal Models in Literacy」。
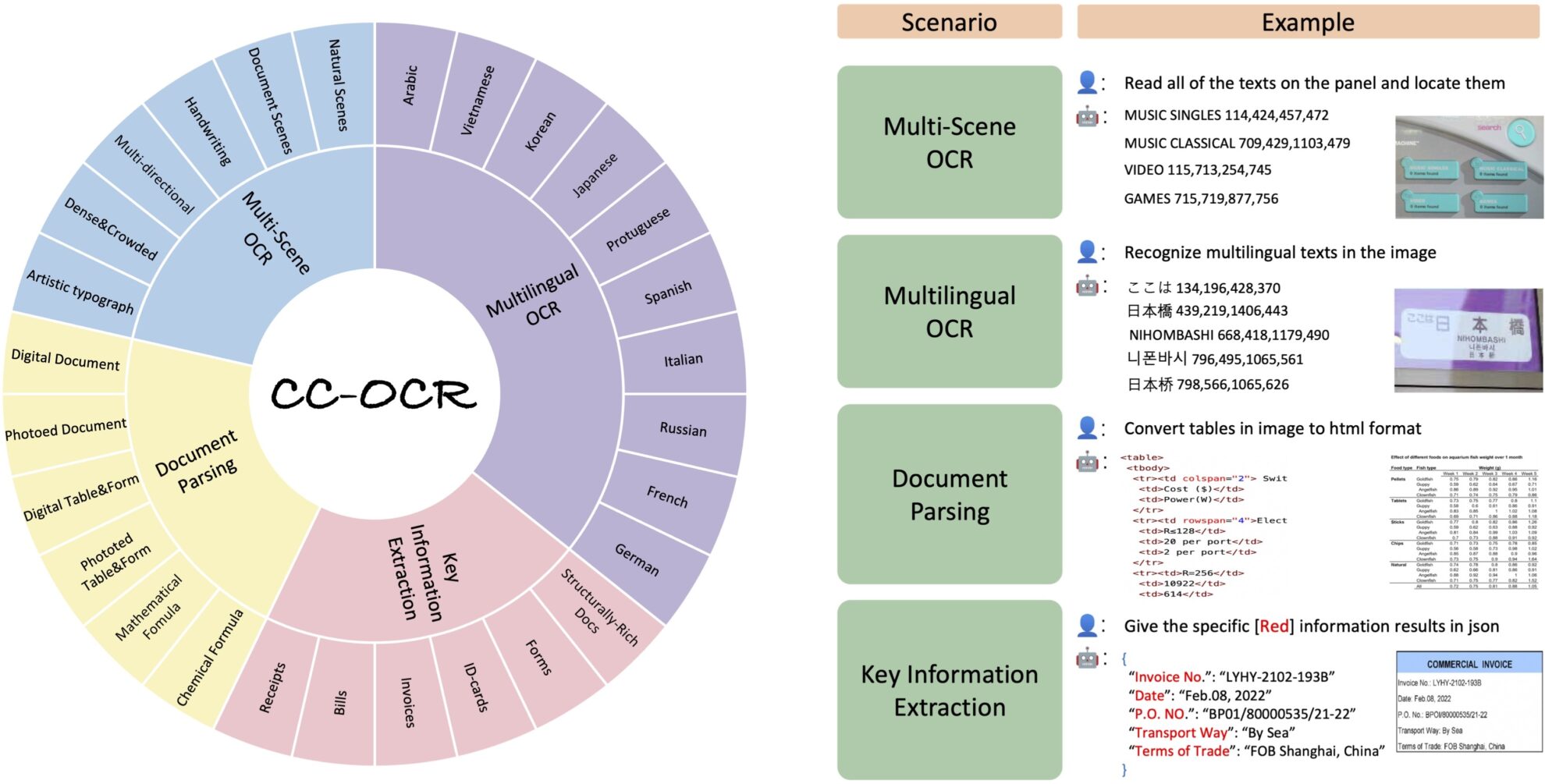
该数据集涵盖了多场景文本阅读、多语言文本阅读、文档解析和关键信息提取 4 大核心任务,包含 39 个子集和 7,058 张全标注图像。 CC-OCR 的推出填补了当前多模态模型在复杂结构和细粒度视觉挑战方面评估的空白,对推动多模态模型在实际应用中的进步具有重要意义。
CC-OCR.torrent
做种 2正在下载 0已完成 232总下载量 420
此数据集由社区用户贡献,仅用于教育和信息目的。如有任何内容涉及版权侵权,请通过 [email protected] 联系我们,我们将及时审核并删除。