HyperAI
Command Palette
Search for a command to run...
الأوراق البحثية
أوراق بحثية متطورة في مجال الذكاء الاصطناعي يتم تحديثها يوميًا لمساعدتك على مواكبة أحدث اتجاهات الذكاء الاصطناعي

MIRepNet: نموذج أساسي ومسار معالجة لتصنيف التخيل الحركي المستند إلى تخطيط الدماغ الكهربائي

ChemDFM-R: منهجية مُحكَمة للReasoning الكيميائي تعززت بمعارف كيميائية مُجزَّأة








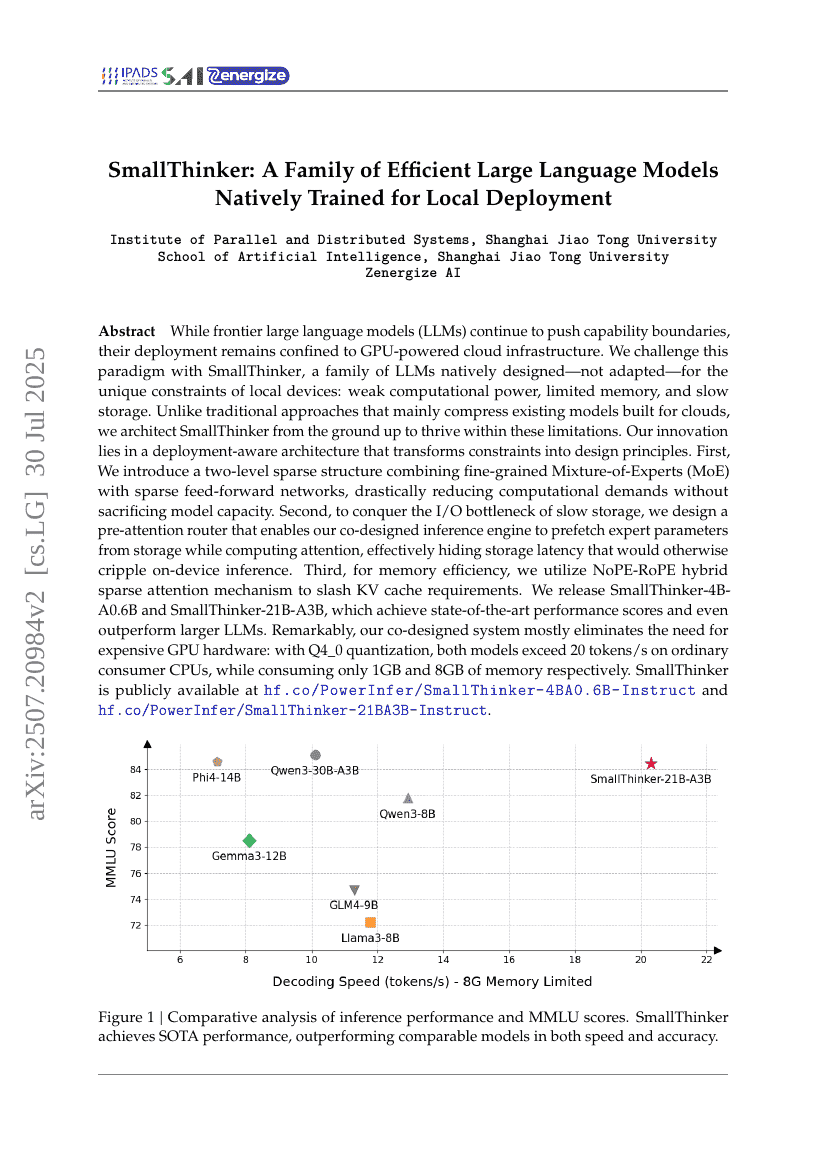



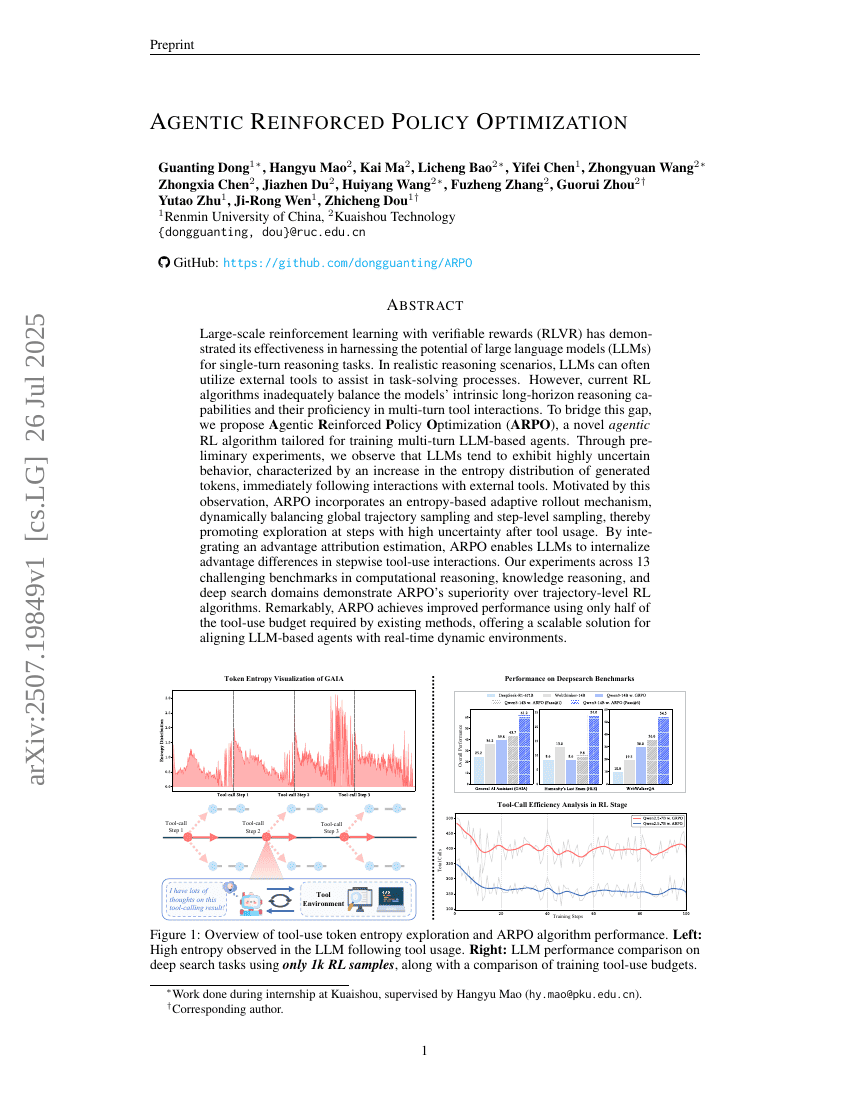

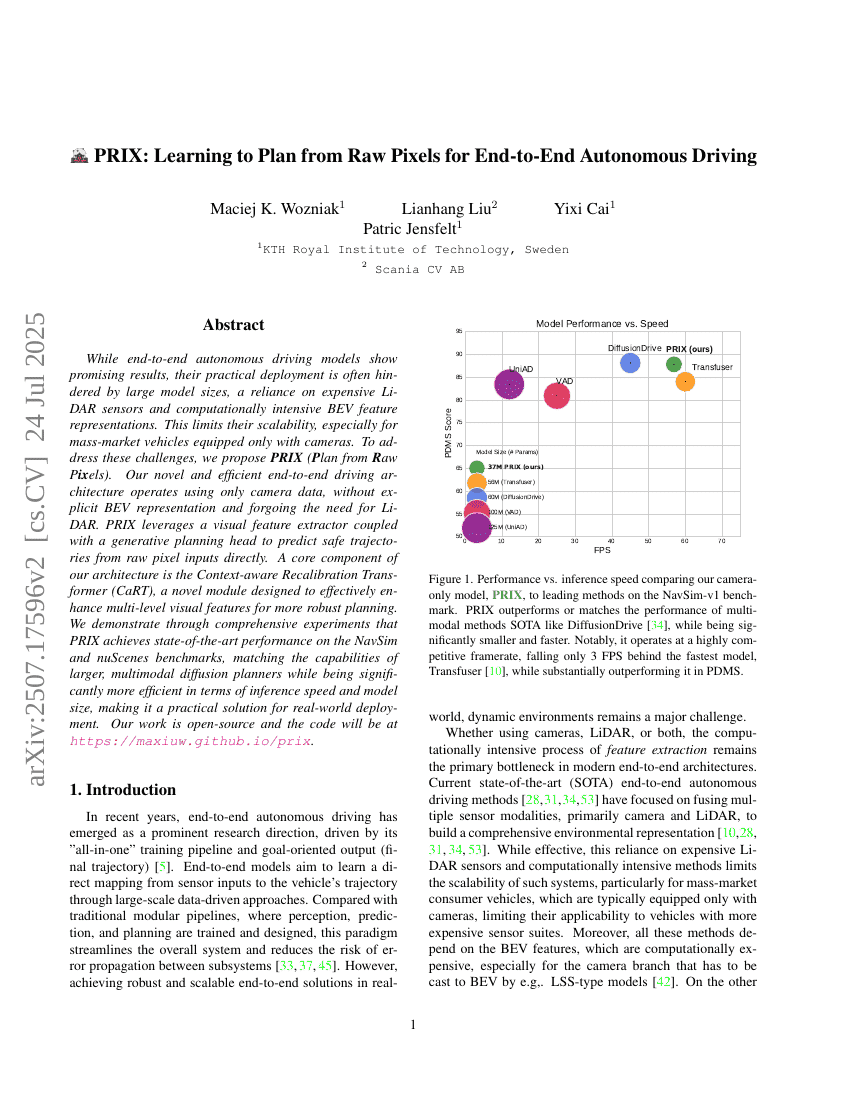















MIRepNet: نموذج أساسي ومسار معالجة لتصنيف التخيل الحركي المستند إلى تخطيط الدماغ الكهربائي
ChemDFM-R: منهجية مُحكَمة للReasoning الكيميائي تعززت بمعارف كيميائية مُجزَّأة
X-Omni: التعلم بالتعزيز يجعل نماذج توليد الصور ذات التوليد التلقائي المنفصلة رائعة مرة أخرى
هونيوان وورلد 1.0: إنشاء عوالم ثلاثية الأبعاد غامرة وقابلة للاستكشاف والتفاعل من كلمات أو بكسلات
أساسيات ألفاأرض: نموذج حقل التضمين لخرائط عالمية دقيقة وفعالة من بيانات التسمية النادرة
إلى تنبؤ طويل المدى بظاهرة النينو باستخدام نموذج تعلم عميق قابل للتفسير
OmniArch: بناء نموذج أساسي للحساب العلمي
UI-AGILE: تحسين الوكلاء الرسوميين باستخدام التعلم التعزيزي الفعّال والتوجيه الدقيق أثناء الاستنتاج
دويل سج: إطار تنبؤ بمتغيرات متعددة بالسلاسل الزمنية المعتمد على تدفق مزدوج ودليل معاني صريح
عندما تتحدث الرموز كثيرًا: مراجعة لضغط الرموز الطويلة عبر الصور والفيديوهات والصوتيات
SmallThinker: مجموعة من نماذج اللغة الكبيرة الفعّالة المدربة أصلاً للاستخدام المحلي
إعادة بناء الذكاء الفراغي 4D: مراجعة
ريب-إم تي إل: تحرير قوة أهمية المهمة على مستوى التمثيل لتعلم المهام المتعددة
ARC-Hunyuan-Video-7B: فهم الفيديو المُنظم للفيديوهات القصيرة في العالم الحقيقي
تحسين سياسة التعلم المُعزَّز بالذكاء
التصحيح الذاتي للمواصفات: تخفيف تلاعب المكافأة في السياق من خلال تحسين في وقت الاختبار
السعر: تعلم التخطيط من الصور الخام لقيادة السيارات ذاتية القيادة بالكامل
الدردشة مع الذكاء الاصطناعي: التطور المفاجئ للاتصال الفيديو الزمني الحقيقي من الإنسان إلى الذكاء الاصطناعي
MMBench-GUI: إطار تقييم متعدد المنصات متسلسل للوكلاء الرسوميين
هندسة كميّة نموذج لغة كبير: GPTQ كخوارزمية النقطة الأقرب لبوباي
مدي كيو إيه: نموذج أساسي قابل للتوسع لتقدير جودة الصور الطبية بناءً على الأوامر
OS-MAP: إلى أي مدى يمكن لل-Agent التي تستخدم الحواسيب أن تذهب من حيث الاتساع والعمق؟
التحسين الهرمي لسياسة الميزانية للاستدلال التكيفي
قائد السينما: نحو إنتاج أفلام قصيرة
LAPO: تكامل كفاءة الاستدلال من خلال تحسين السياسة المتكيفة مع الطول
موف: التفكير المُوجه بتحريض عدم اليقين في الزخم لنموذجات اللغة الكبيرة
∇NABLA: الانتباه المستوي الكتلي المتكيف مع الجوار
تحسين سياسة التسلسل الجماعي
SafeWork-R1: التطور المشترك للأمان والذكاء وفقًا لقانون الذكاء الاصطناعي 45
فصل المعرفة والاستدلال في نماذج اللغة الكبيرة: استكشاف باستخدام نظرية النظامين العقليين
العنوان: تقليل المعرفة البشرية في التحقق الرسمي للبرامج ذات الحجم الكبير باستخدام التعلم بالتعزيز في نماذج اللغة الكبيرة: دراسة أولية على Dafny
RAVine: تقييم متناسب مع الواقع لبحث الوكالة
X-Omni: التعلم بالتعزيز يجعل نماذج توليد الصور ذات التوليد التلقائي المنفصلة رائعة مرة أخرى
هونيوان وورلد 1.0: إنشاء عوالم ثلاثية الأبعاد غامرة وقابلة للاستكشاف والتفاعل من كلمات أو بكسلات
أساسيات ألفاأرض: نموذج حقل التضمين لخرائط عالمية دقيقة وفعالة من بيانات التسمية النادرة
إلى تنبؤ طويل المدى بظاهرة النينو باستخدام نموذج تعلم عميق قابل للتفسير
OmniArch: بناء نموذج أساسي للحساب العلمي
UI-AGILE: تحسين الوكلاء الرسوميين باستخدام التعلم التعزيزي الفعّال والتوجيه الدقيق أثناء الاستنتاج
دويل سج: إطار تنبؤ بمتغيرات متعددة بالسلاسل الزمنية المعتمد على تدفق مزدوج ودليل معاني صريح
عندما تتحدث الرموز كثيرًا: مراجعة لضغط الرموز الطويلة عبر الصور والفيديوهات والصوتيات
SmallThinker: مجموعة من نماذج اللغة الكبيرة الفعّالة المدربة أصلاً للاستخدام المحلي
إعادة بناء الذكاء الفراغي 4D: مراجعة
ريب-إم تي إل: تحرير قوة أهمية المهمة على مستوى التمثيل لتعلم المهام المتعددة
ARC-Hunyuan-Video-7B: فهم الفيديو المُنظم للفيديوهات القصيرة في العالم الحقيقي
تحسين سياسة التعلم المُعزَّز بالذكاء
التصحيح الذاتي للمواصفات: تخفيف تلاعب المكافأة في السياق من خلال تحسين في وقت الاختبار
السعر: تعلم التخطيط من الصور الخام لقيادة السيارات ذاتية القيادة بالكامل
الدردشة مع الذكاء الاصطناعي: التطور المفاجئ للاتصال الفيديو الزمني الحقيقي من الإنسان إلى الذكاء الاصطناعي
MMBench-GUI: إطار تقييم متعدد المنصات متسلسل للوكلاء الرسوميين
هندسة كميّة نموذج لغة كبير: GPTQ كخوارزمية النقطة الأقرب لبوباي
مدي كيو إيه: نموذج أساسي قابل للتوسع لتقدير جودة الصور الطبية بناءً على الأوامر
OS-MAP: إلى أي مدى يمكن لل-Agent التي تستخدم الحواسيب أن تذهب من حيث الاتساع والعمق؟
التحسين الهرمي لسياسة الميزانية للاستدلال التكيفي
قائد السينما: نحو إنتاج أفلام قصيرة
LAPO: تكامل كفاءة الاستدلال من خلال تحسين السياسة المتكيفة مع الطول
موف: التفكير المُوجه بتحريض عدم اليقين في الزخم لنموذجات اللغة الكبيرة
∇NABLA: الانتباه المستوي الكتلي المتكيف مع الجوار
تحسين سياسة التسلسل الجماعي
SafeWork-R1: التطور المشترك للأمان والذكاء وفقًا لقانون الذكاء الاصطناعي 45
فصل المعرفة والاستدلال في نماذج اللغة الكبيرة: استكشاف باستخدام نظرية النظامين العقليين
العنوان: تقليل المعرفة البشرية في التحقق الرسمي للبرامج ذات الحجم الكبير باستخدام التعلم بالتعزيز في نماذج اللغة الكبيرة: دراسة أولية على Dafny
RAVine: تقييم متناسب مع الواقع لبحث الوكالة