Command Palette
Search for a command to run...
برنامج تعليمي عبر الإنترنت | تعديل ضخم باستخدام بطاقة SIM واحدة: MiniCPM-V-4.6، نموذج مفتوح المصدر بحجم 1.3 مليار يدعم فهم الصور/فهم الفيديو/التعرف الضوئي على الأحرف/الحوار متعدد الوسائط متعدد الأدوار (باستخدام Wallfacer ومكتبات مفتوحة المصدر أخرى).

في السنوات القليلة الماضية، غرق قطاع الذكاء الاصطناعي بأكمله تقريبًا في سردية قانون التوسع. فكلما زاد عدد المعاملات وبيانات التدريب، اقترب النموذج من "الذكاء العام". ومن مئات المليارات إلى تريليونات المعاملات، جددت النماذج الضخمة باستمرار تصورات الناس عن القدرة على الاستدلال والمعرفة العالمية، وجعلت أيضًا "تكديس قوة الحوسبة والتوسع" المسار الافتراضي لتطوير هذا القطاع.
لكن مع بدء تطبيق الذكاء الاصطناعي فعلياً في الصناعة، تظهر مشكلة حقيقية تدريجياً:لا تتطلب جميع السيناريوهات نشر النماذج الفائقة في مراكز بيانات الحوسبة السحابية.تُسبب تكاليف الاستدلال المرتفعة، وزمن استجابة الشبكة غير القابل للتحكم، ومخاطر خصوصية البيانات المتزايدة الحساسية، اختناقات في نهج النموذج "الكبير والشامل". وقد أصبح "المثلث المستحيل" بين الأداء والسرعة والتكلفة مشكلةً يجب على ديمقراطية الذكاء الاصطناعي معالجتها.
وهكذا، بدأ يظهر اتجاه يبدو غير بديهي: فقد أظهرت النماذج ذات المعلمات الأصغر كفاءة أعلى وفعالية من حيث التكلفة في عدد متزايد من سيناريوهات العالم الحقيقي، وخاصة في الأجهزة الطرفية والبيئات الصناعية ذات التزامن العالي.تتولى النماذج الخفيفة مهامًا أساسية مثل التعرف الضوئي على الأحرف، والإجابة على أسئلة الصور، والتعرف على النوايا.يمكنها العمل دون اتصال بالإنترنت على الأجهزة المحمولة بسرعات تصل إلى أجزاء من الثانية، كما يمكنها التعامل مع التوجيه وخفض التكاليف داخل نظام RAG، لتصبح بنية تحتية حاسمة للتنفيذ الحقيقي لتطبيقات الذكاء الاصطناعي.
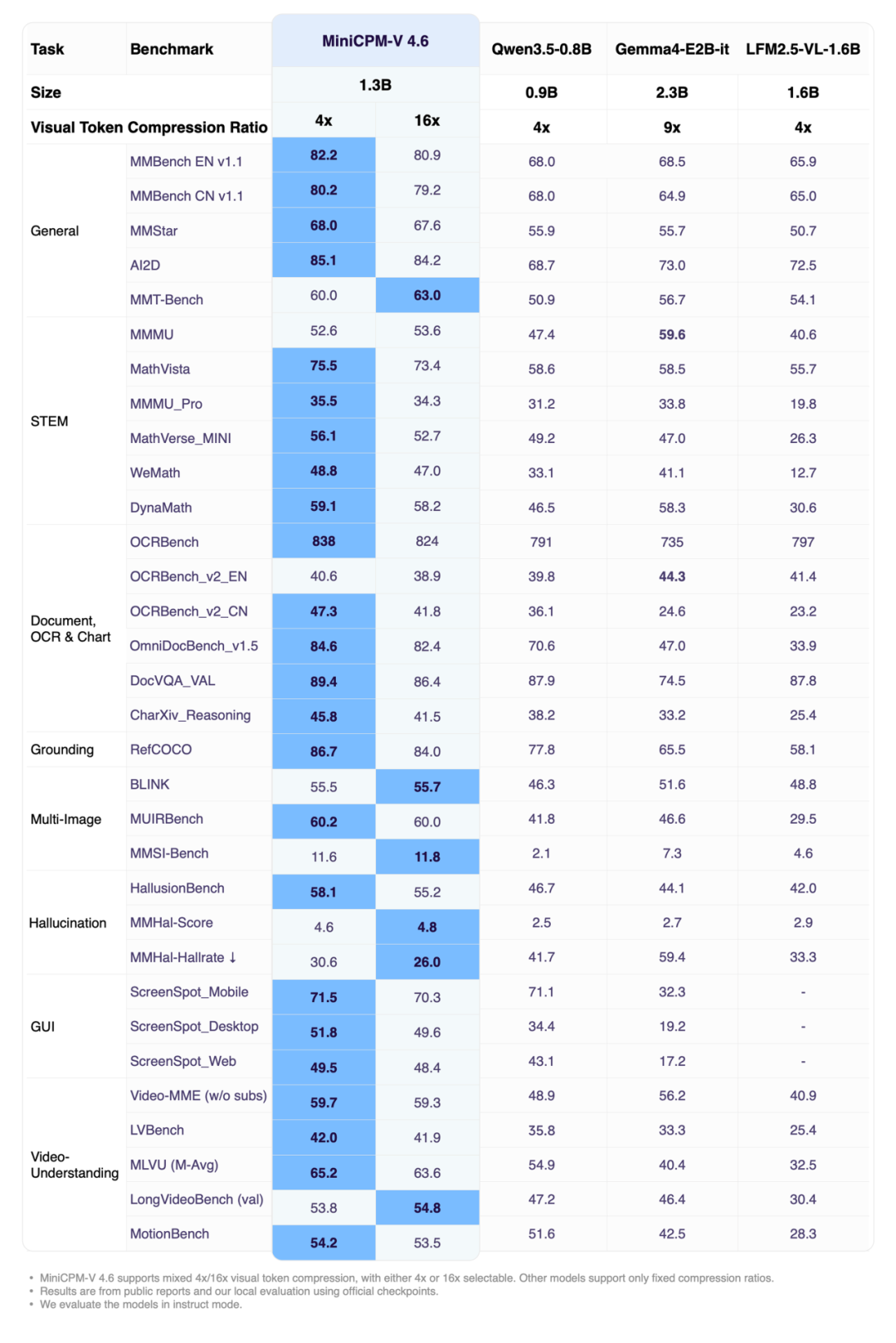
في الآونة الأخيرة، قامت شركة Facewall Intelligence وجامعة تسينغهوا وOpenBMB بشكل مشترك بنشر نموذج MiniCPM-V 4.6 متعدد الوسائط من الجيل التالي كمصدر مفتوح. يحتوي هذا النموذج على حوالي 1.3 مليار معلمة فقط، ولكنه يدعم فهم الصور والفيديوهات والتعرف الضوئي على الأحرف (OCR) وقدرات الحوار متعدد الوسائط متعدد الأدوار، وقد تفوق على النماذج الأخرى من نفس المستوى في العديد من التقييمات.
تجدر الإشارة إلى أن بطاقة النموذج الرسمية توفر حل استدلال AutoProcessor و AutoModelForImageTextToText يعتمد على Transformers، وهو مناسب للتحقق السريع ونمذجة التطبيقات في بيئة GPU واحدة.
لتسهيل تجربة هذا النموذج الخفيف للمطورين العالميين، أطلقت HyperAI "MiniCPM-V-4.6: نموذج لغة مرئي متعدد الوسائط فعال لتطبيقات الحافة". اكتملت تهيئة البيئة، ويمكن نشر النموذج عبر الإنترنت بسهولة.
تشغيل عبر الإنترنت:https://go.hyper.ai/GVDmw
اطلع على الأبحاث ذات الصلة:
https://hyper.ai/papers/2605.08985
المزيد من الدروس التعليمية عبر الإنترنت:
نرحب بكم لزيارة موقعنا الإلكتروني الرسمي لمزيد من المعلومات:
تشغيل تجريبي
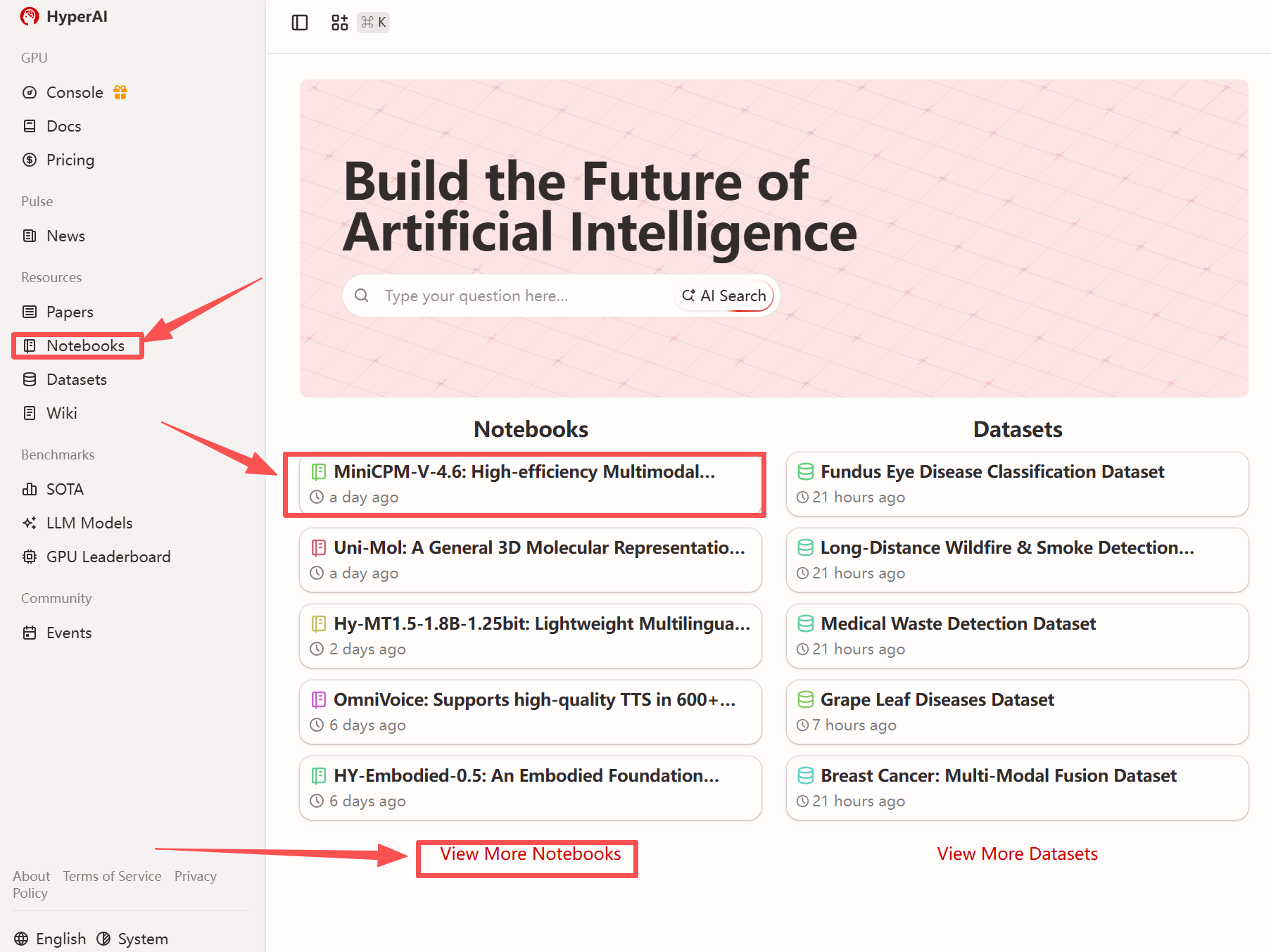
1. بعد الدخول إلى الصفحة الرئيسية لموقع hyper.ai، حدد صفحة "الدروس التعليمية"، أو انقر فوق "عرض المزيد من الدروس التعليمية"، وحدد "MiniCPM-V-4.6: نموذج لغة مرئية متعدد الوسائط فعال للأجهزة"، وانقر فوق "تشغيل هذا البرنامج التعليمي".
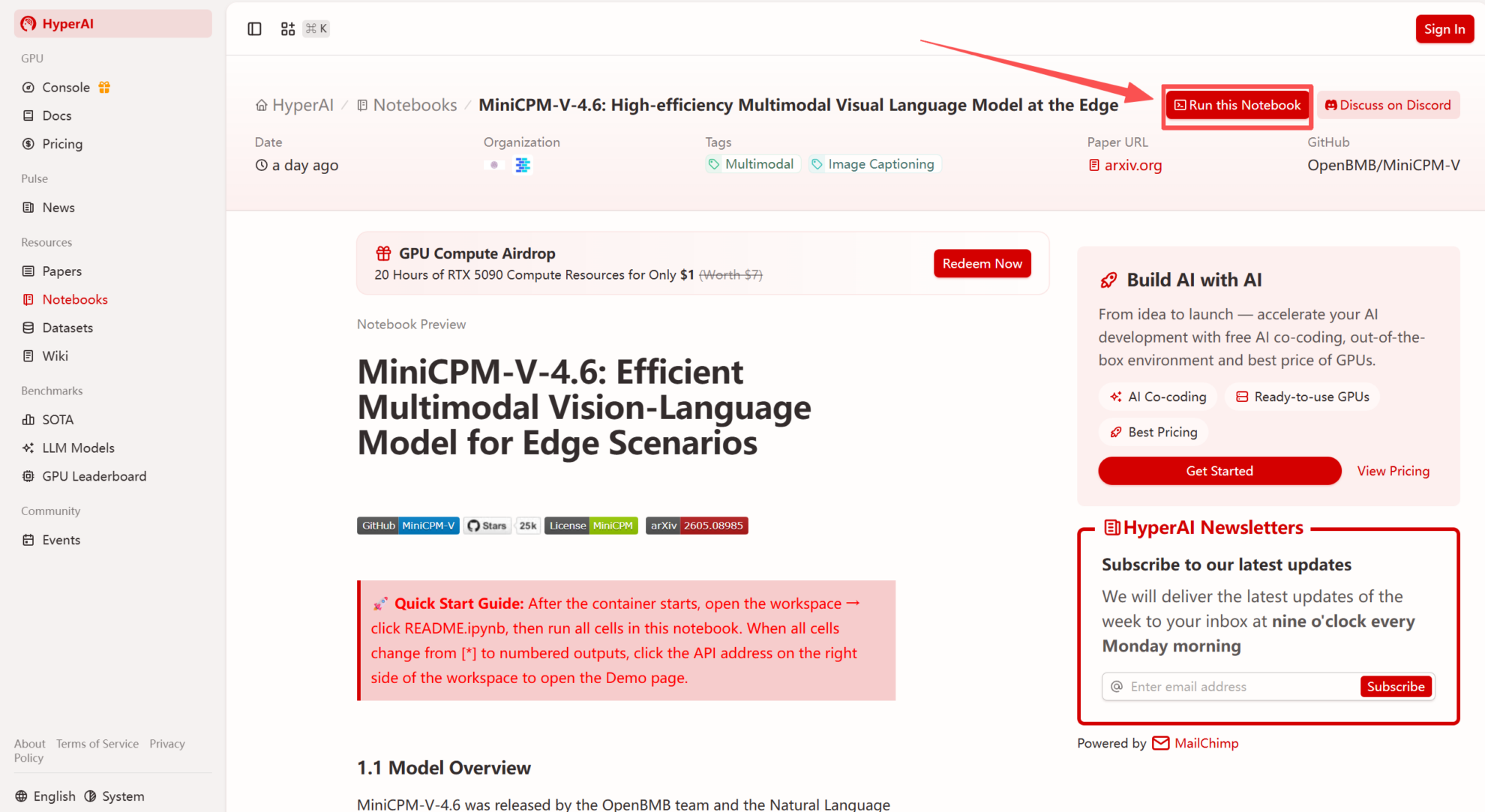
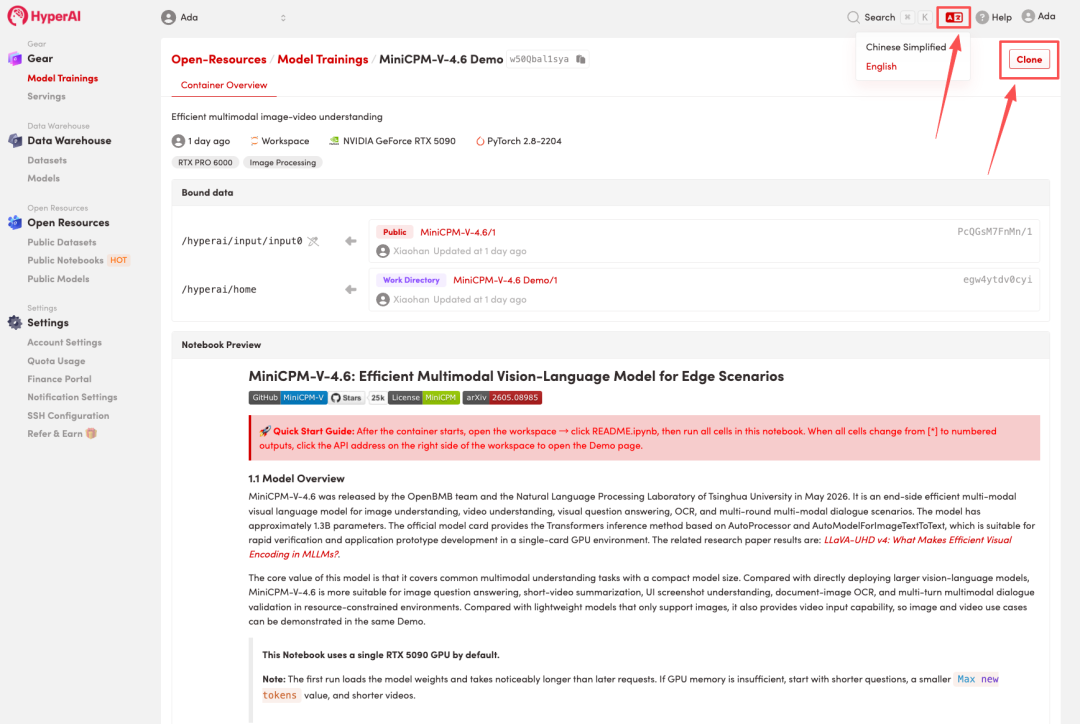
2. بعد إعادة توجيه الصفحة، انقر فوق "استنساخ" في الزاوية اليمنى العليا لاستنساخ البرنامج التعليمي في الحاوية الخاصة بك.
ملاحظة: يمكنك تبديل اللغات في الزاوية العلوية اليمنى من الصفحة. حاليًا، اللغتان الصينية والإنجليزية متاحتان. سيوضح هذا البرنامج التعليمي الخطوات باللغة الإنجليزية.
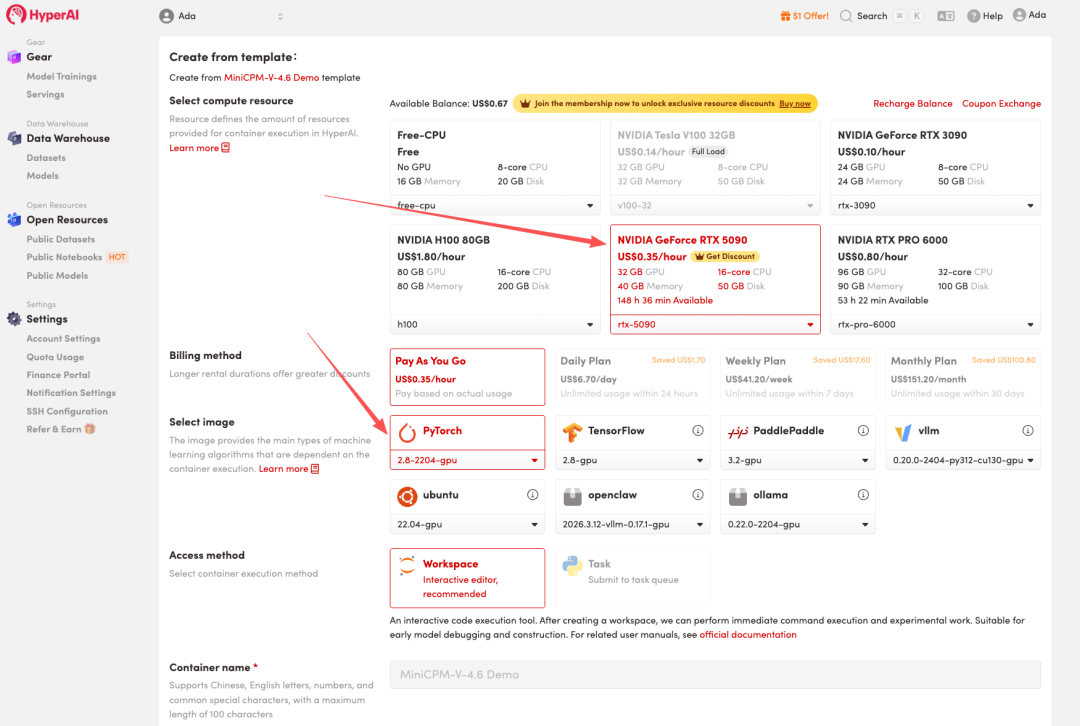
3. حدد صور "NVIDIA RTX 5090" و "PyTorch"، وانقر فوق "متابعة تنفيذ المهمة".
تقدم HyperAI مكافأة تسجيل للمستخدمين الجدد: مقابل $1 فقط، يمكنك الحصول على 20 ساعة من قوة الحوسبة RTX 5090 (بسعر أصلي $7)، والموارد صالحة إلى أجل غير مسمى.
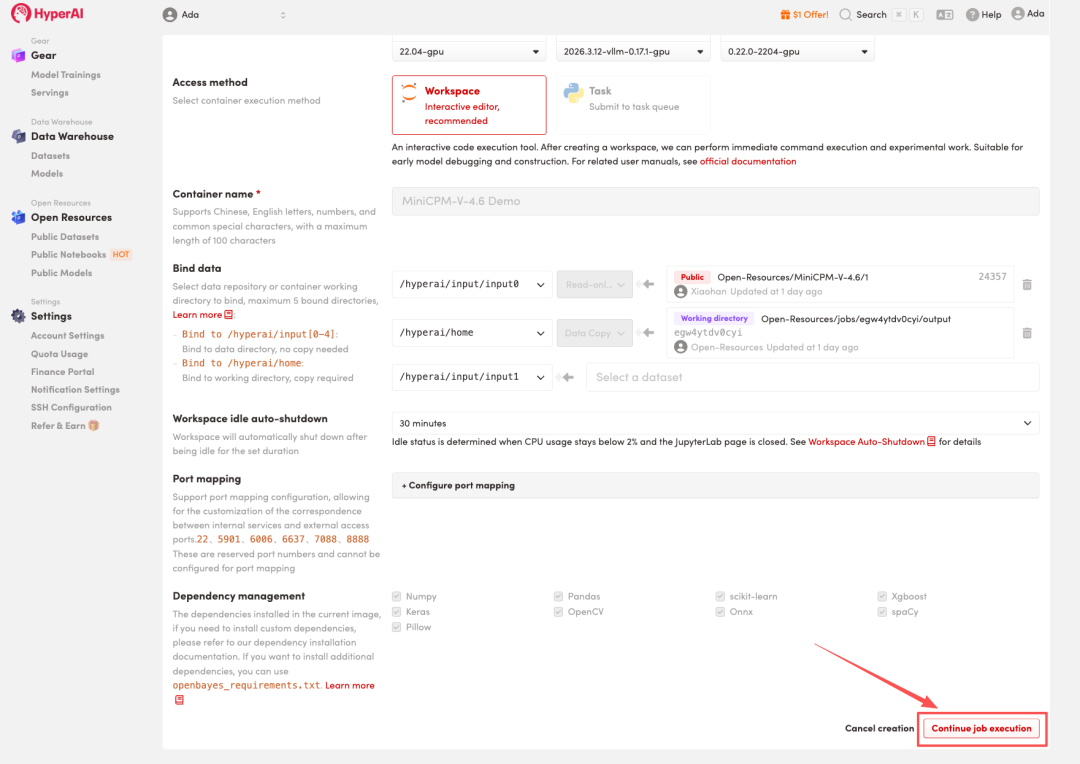
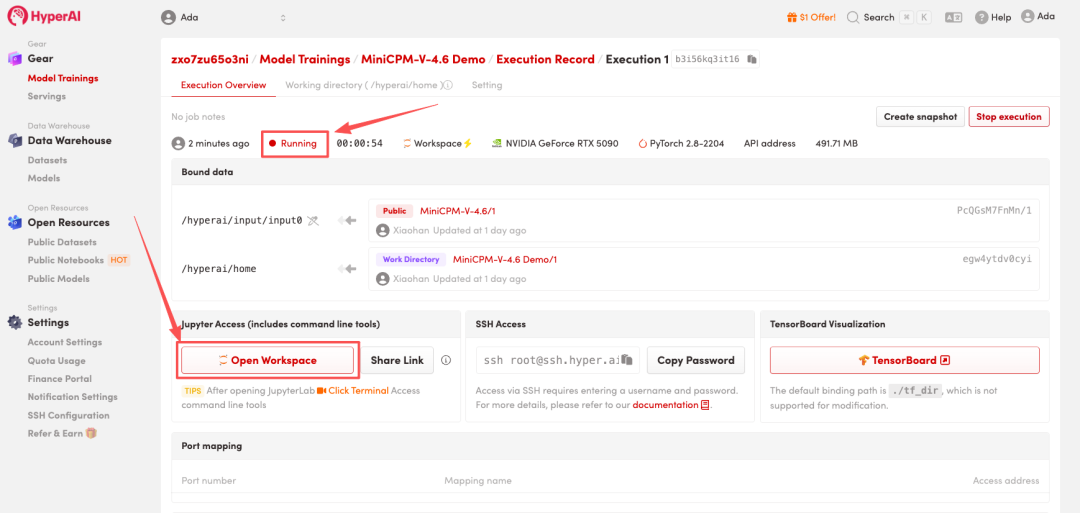
4. انتظر حتى يتم تخصيص الموارد. بمجرد أن تتغير الحالة إلى "قيد التشغيل"، انقر فوق "فتح مساحة العمل" للدخول إلى مساحة عمل Jupyter.
عرض التأثير
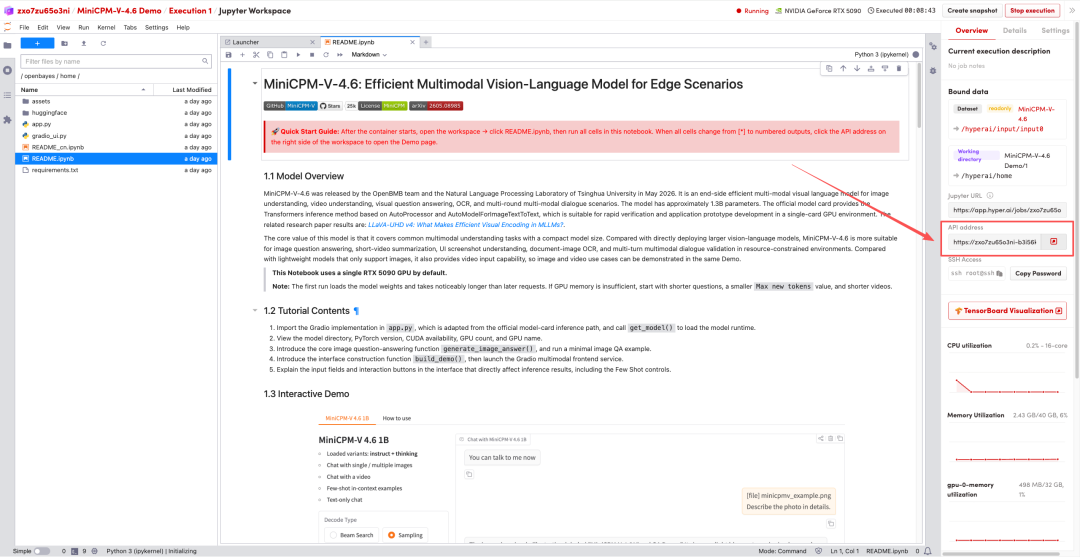
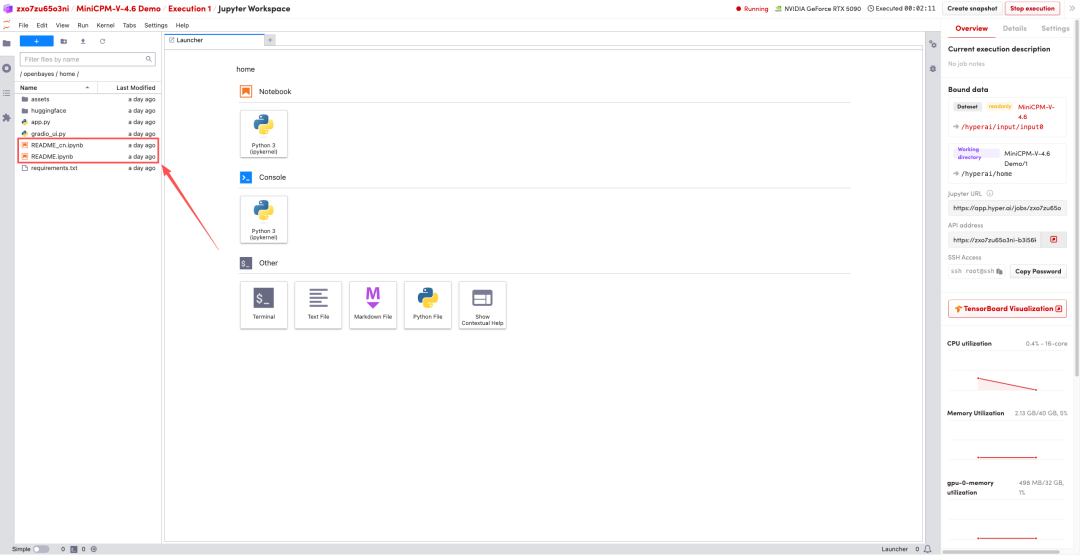
1. بعد إعادة توجيه الصفحة، انقر على ملف README الموجود على اليسار، ثم انقر على تشغيل في الأعلى.
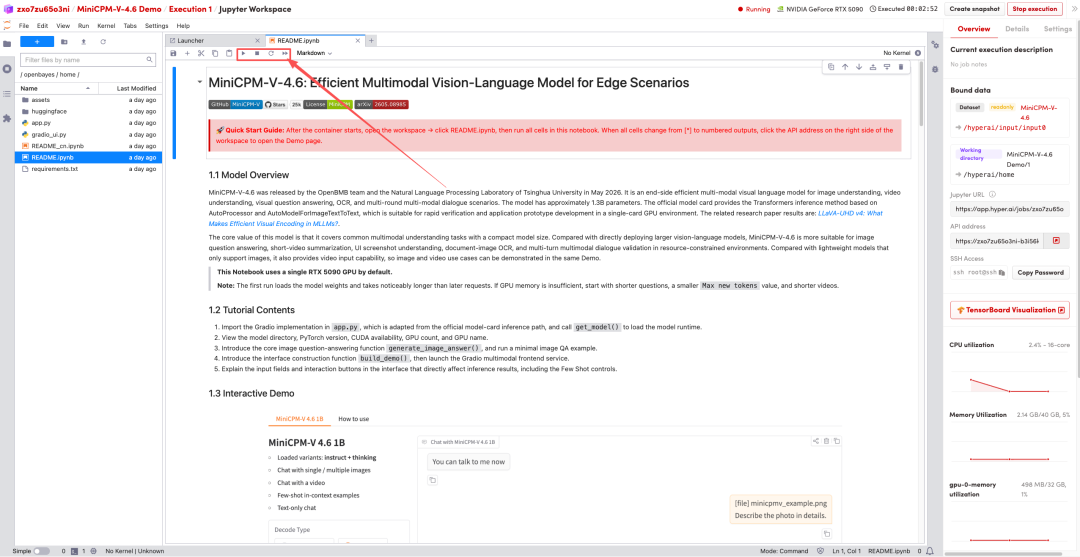
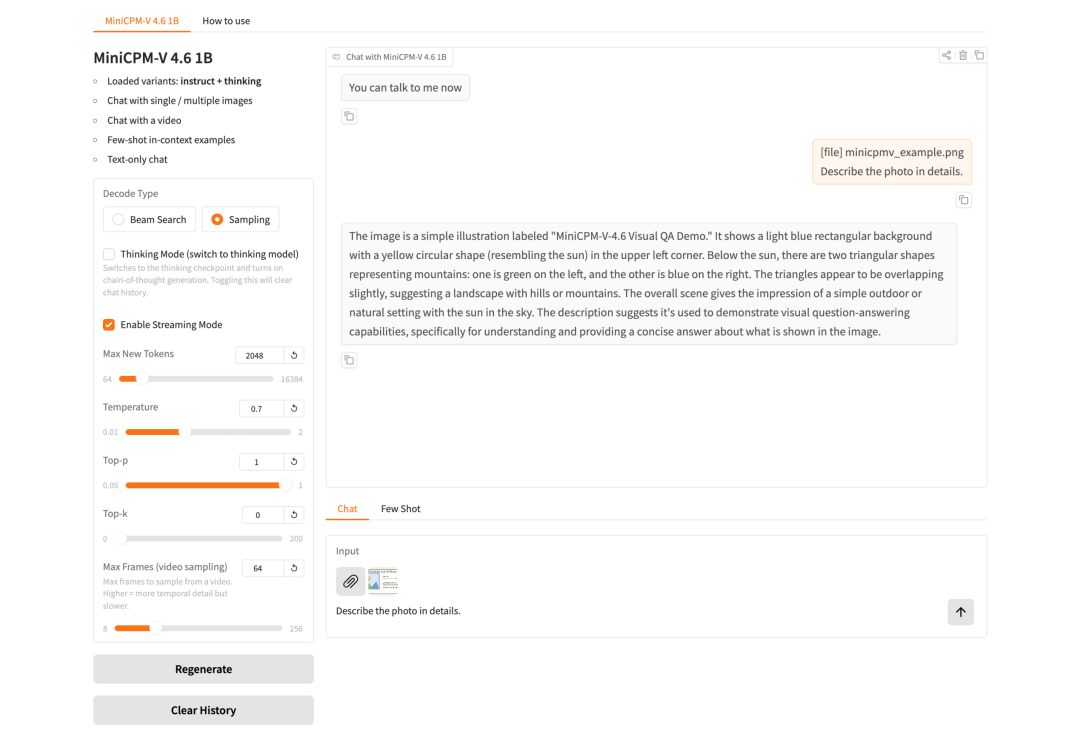
2. بمجرد اكتمال العملية، انقر فوق عنوان API الموجود على اليمين للانتقال إلى صفحة العرض التوضيحي.