Command Palette
Search for a command to run...
حقق فريق ألماني إنجازاً جديداً في مجال البحوث الطبية الحيوية ذات العينات الصغيرة باستخدام نماذج الذكاء الاصطناعي التوليدية لزيادة البيانات، مما قد يقلل من عدد حيوانات المختبر المطلوبة بمقدار 30-50 لكل TP3T.

غالباً ما تفشل "الآثار العلاجية الفعّالة" التي تم التحقق منها في التجارب على الحيوانات في التكرار في التجارب السريرية، ويُعدّ عدم كفاية حجم العينة أحد الأسباب الرئيسية لذلك. وتزيد قيود متعددة، بما في ذلك اللوائح الأخلاقية وتكاليف التجارب وظروف البحث، من تفاقم المشكلة.غالباً ما تواجه البحوث الطبية الحيوية قبل السريرية تحديات في إجراء تجارب على الحيوانات على نطاق واسع، مما يؤدي مباشرة إلى عدم كفاية القوة الإحصائية.يعجز الباحثون عن استخلاص الإشارات البيولوجية الحقيقية بشكل موثوق، وهم عرضة بشكل كبير للنتائج الإيجابية الكاذبة، مما يعيق بشكل خطير ترجمة البحوث الأساسية إلى تطبيقات سريرية.
ولمعالجة هذا التحدي، حاول الأكاديميون دمج بيانات البحث باستخدام أساليب مثل التحليل التلوي ودمج البيانات.ومع ذلك، فإن هذه الأساليب تعتمد بشكل كبير على قابلية مقارنة التصاميم التجريبية ومؤشرات الكشف والإجراءات التشغيلية بين الدراسات المختلفة.نطاق تطبيقها العملي محدود للغاية.
في السنوات الأخيرة، قدّم الذكاء الاصطناعي التوليدي نهجًا جديدًا لأبحاث العينات الصغيرة، إذ يقوم، من خلال تعلّم بنية التوزيع الكامنة في البيانات الأصلية، بتوليد بيانات اصطناعية لتوسيع حجم العينة. مع ذلك، تعاني النماذج التوليدية العامة من أوجه قصور كبيرة.إذا كانت البيانات الأصلية تحتوي على أخطاء عشوائية، فإن النموذج سيزيد من تضخيم الضوضاء ويولد عددًا كبيرًا من النتائج الإيجابية الخاطئة، مما سيقلل من مصداقية استنتاجات البحث.أصبحت كيفية قمع انتشار الأخطاء أثناء توليد البيانات بمثابة عقبة رئيسية أمام تطبيق الذكاء الاصطناعي التوليدي في المجال الطبي الحيوي.
لمعالجة هذه المشكلة الحرجة، قام فريق بحثي مشترك من جامعة فرانكفورت ومعهد فراونهوفر لتكنولوجيا المعلومات والإدارة بتطوير genESOM—تم تصميم نماذج الذكاء الاصطناعي التوليدية القائمة على الخرائط ذاتية التنظيم الناشئة خصيصًا لبيانات الطب الحيوي ذات العينات الصغيرة.يكمن الابتكار الأساسي لهذا النموذج في فصل عملية تعلم البنية عن عملية توليد البيانات. فهو يمنع انتشار الأخطاء من خلال تعديل الأبعاد، ويُدخل متغير تحكم سلبي لمراقبة جودة توليد البيانات في الوقت الفعلي. استخدم فريق البحث بيانات ما قبل السريرية للدهون في مرضى التصلب المتعدد كعينة للدراسة، حيث قاموا أولاً بتقليل حجم العينة بشكل مصطنع إلى عتبة الفشل الإحصائي، ثم استخدموا خوارزمية genESOM لزيادة حجم البيانات.
تؤكد النتائج أن هذه الطريقة قادرة على استعادة الإشارات البيولوجية الرئيسية المفقودة في بيانات العينات الصغيرة بكفاءة عالية، مع التحكم الدقيق في النتائج الإيجابية الخاطئة، مما يوفر نهجًا جديدًا موثوقًا به لأبحاث الطب الحيوي التي تعتمد على عينات صغيرة. علاوة على ذلك، في سيناريوهات البحث الاستكشافي، من المتوقع أن يقلل هذا النموذج عدد حيوانات التجارب المطلوبة بما يتراوح بين 30% و50% تقريبًا، مع الحفاظ على قابلية تكرار النتائج وصحتها العلمية.
وقد نُشرت نتائج البحث ذات الصلة، بعنوان "الذكاء الاصطناعي التوليدي القائم على الشبكة العصبية ذاتية التنظيم مع التحكم المضمن في تضخم الخطأ يعزز استخراج المعرفة الفعالة من الدراسات قبل السريرية مع تقليل حجم العينة"، في مجلة البحوث الدوائية.
أبرز الأبحاث:
* تعمل آلية التحكم في الأخطاء المدمجة والقائمة على البيانات على قمع التضخم الإيجابي الخاطئ بشكل فعال، على عكس الطرق غير المقيدة مثل GAN.
* تم استعادة إشارات الدهون الرئيسية بنجاح (مثل حمض الليزوفوسفاتيديك) بعد تقليل حجم العينة، دون زيادة معدل النتائج الإيجابية الكاذبة.
* يمكن أن يقلل من كمية TP3T المستخدمة في الحيوانات بنسبة 30-50٪، حيث يعمل كأداة تحليلية تكميلية مع مراعاة كل من متانة البحث والمبادئ الأخلاقية 3R.

عرض الورقة:
https://www.sciencedirect.com/science/article/pii/S1043661826000745
مجموعات البيانات: من التجارب الكاملة إلى الفشل الإحصائي للعينات الصغيرة
تأتي البيانات الخاصة بهذه الدراسة من دراسة حيوانية قبل السريرية منشورة علنًا حول التصلب المتعدد.استخدمت الدراسة فئران SJL/J لإنشاء نموذج تجريبي لالتهاب الدماغ والنخاع المناعي الذاتي المتكرر (EAE).تهدف الدراسة إلى توضيح آليات الأمراض العصبية الالتهابية والتحقق من صحة الفعالية العلاجية للدواء المعتمد فينجوليمود.
ملاحظة: يُعدّ فينغوليمود مُعدِّلاً لمستقبلات سفينغوزين-1-فوسفات، حيث يُمكنه التأثير على مسارات الإشارات المناعية من خلال تنظيم استقلاب السفينغوليبيدات. وهو دواء شائع الاستخدام في العلاج السريري للتصلب المتعدد.
شملت التجربة 26 فأرة أنثى عمرها ثمانية أسابيع، قُسّمت عشوائيًا إلى ثلاث مجموعات: مجموعة ضابطة، ومجموعة نموذج التهاب الدماغ والنخاع المناعي الذاتي التجريبي (EAE)، ومجموعة علاج التهاب الدماغ والنخاع المناعي الذاتي التجريبي (EAE) مع فينغوليمود. أُعطيت المجموعة العلاجية الدواء عن طريق ماء الشرب بجرعة 0.5 ملغم/كغم/يوم بدءًا من اليوم الثامن عشر من بدء التحصين.
قام فريق البحث بجمع البيانات السلوكية والجزيئية في آن واحد:تشمل المؤشرات السلوكية القدرة الحركية والتنسيق البدني والسلوك الاجتماعي؛ على المستوى الجزيئي، تم استخدام تقنية التحديد الكمي المستهدف LC-MS/MS للكشف عن تركيز 62 وسيطًا دهنيًا في أربعة أنسجة: البلازما والمخيخ والحصين وقشرة الفص الجبهي، والتي تغطي أربع فئات رئيسية: حمض الليزوفوسفاتيديك والسيراميدات والدهون السفينغولية والإندوكانابينويدات.وأخيراً، تم إنشاء مصفوفة بيانات قياسية لـ "خصائص الفأر الفردية × الدهون".
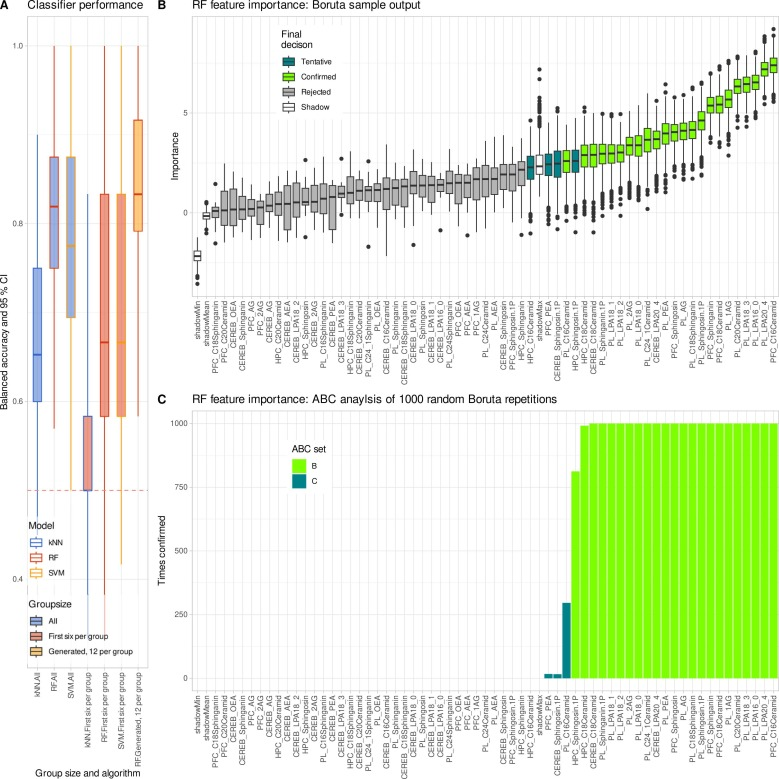
قبل تحليل البيانات،قام فريق البحث بإجراء تحويل لوغاريتمي على بيانات تركيز الدهون لجعلها تتوافق مع افتراضات التوزيع الخاصة بالتحليل الإحصائي.بالنسبة للقيم المفقودة في البيانات الأصلية 5.3%، وبعد إجراء عملية محاذاة متعددة الطرق، تم ملء هذه القيم باستخدام خوارزمية الغابة العشوائية (missForest). بعد ذلك، أُجري تحليل التباين أحادي الاتجاه (ANOVA) على 62 مؤشرًا دهنيًا، واستُخدم تصحيح سيداك للتحكم في أخطاء الاختبارات المتعددة. في الوقت نفسه، تم إدخال ثلاثة نماذج للتعلم الآلي - الغابة العشوائية، وآلة المتجهات الداعمة، وخوارزمية أقرب الجيران - للتحقق المتبادل من استقرار الإشارات البيولوجية في البيانات من بُعدين: دلالة الاختلافات بين المجموعات وقدرة التنبؤ بالتصنيف.
بعد إتمام التحليل الأساسي، أجرت الدراسة تجربة تحقق جوهرية: تمثلت في تقليص حجم العينة بشكل منهجي لتحديد القيمة الحرجة للفشل الإحصائي مع العينات الصغيرة. قام الباحثون بتقليل عدد الفئران في كل مجموعة تدريجيًا، مع تكرار إجراء التحليل بالكامل بعد كل تقليص. أظهرت النتائج أنه عند تقليص حجم العينة إلى 6 فئران لكل مجموعة،يُعد الاختفاء الكامل لجميع النتائج الإحصائية الهامة من البيانات الأصلية بمثابة معيار لتقييم قدرات genESOM على زيادة البيانات.—في سيناريوهات العينات الصغيرة حيث تكون الإحصاءات غير فعالة تمامًا، تحقق مما إذا كان بإمكان الذكاء الاصطناعي استعادة الإشارات البيولوجية التي دفنتها الضوضاء.
الذكاء الاصطناعي التوليدي مصمم خصيصًا لبيانات الطب الحيوي ذات العينات الصغيرة
تواجه النماذج التوليدية التقليدية معضلة مستمرة عند معالجة بيانات العينات الصغيرة: إما أن تكون البيانات المُولَّدة تفتقر إلى المعلومات ولا تستطيع استعادة الإشارات البيولوجية الأصلية، أو أنها مُحمَّلة بالتشويش، مما يُنتج عددًا كبيرًا من النتائج الإيجابية الخاطئة. يتمثل التصميم الأساسي لـ genESOM في إنشاء آلية توازن دقيقة بين هذين العاملين، لتحقيق زيادة آمنة وقابلة للتفسير لبيانات العينات الصغيرة.
يعتمد genESOM على الشبكة العصبية للخريطة ذاتية التنظيم الناشئة (ESOM) ويحقق ترقيتين رئيسيتين مقارنة بالخريطة ذاتية التنظيم الكلاسيكية (SOM):أولاً،يتم ترتيب الخلايا العصبية في شبكة دائرية ثنائية الأبعاد للحفاظ على علاقة بنية الجوار للبيانات عالية الأبعاد إلى أقصى حد.ثانيًا،إن إضافة بُعد ثالث، يقوم بتشفير تباعد المجموعات الفرعية وخطأ الإسقاط، يحسن بشكل كبير من دقة تحديد هياكل التجميع المحتملة.
بعد توحيد البيانات وإزالة القيم المفقودة، تُسقط على شبكة ESOM للتدريب. يُطابق النموذج باستمرار العصبون الأمثل لكل عينة، ويُعدّل أوزان العصبونات ديناميكيًا، ويُقلل معدل التعلم تدريجيًا لضمان استقرار التدريب. بعد التدريب، يُخرج النموذج مصفوفتين أساسيتين: المصفوفة U التي تُحدد المسافة بين العصبونات وتُحدد حدود المجموعات؛ والمصفوفة P التي تُستخدم لتحليل كثافة البيانات المحلية إحصائيًا، مما يُوفر أساسًا لتوليد بيانات اصطناعية. يتم تحديد مُعامل نصف القطر، الذي يتحكم في نطاق توليد البيانات الاصطناعية، تلقائيًا عن طريق مُلاءمة توزيع المسافة باستخدام نموذج خليط غاوسي، دون الحاجة إلى أي تدخل يدوي.
إن التصميم الأكثر ابتكارًا في genESOM هو الفصل الكامل بين عمليات تعلم البنية وتوليد البيانات.يتعلم النموذج أولاً تمثيل البنية الكامنة للبيانات بشكل مستقل، ثم يُنشئ بيانات اصطناعية بناءً على هذه البنية المستقرة، متجنباً بذلك تراكم الأخطاء من الخطوتين السابقتين. والأهم من ذلك، يُمكن للنموذج إدخال متغيرات التبديل كضوابط سلبية لمراقبة ما إذا كانت أهمية الميزات مُضخمة بشكل غير طبيعي في الوقت الفعلي؛ فبمجرد اكتشاف تراكم الأخطاء، يتم إيقاف عملية زيادة البيانات فوراً وبشكل تلقائي، مما يُقلل من مخاطر التخصيص الزائد والنتائج الإيجابية الخاطئة.
في هذه الدراسة، استخدم فريق البحث نسبة تعزيز آمنة 1:1 (عينة اصطناعية واحدة مُولَّدة من كل عينة أصلية) لتوسيع حجم العينة في كل مجموعة من 6 إلى 12. بعد التعزيز،يتم إجراء مجموعة كاملة من التحليلات الإحصائية وتحليلات التعلم الآلي على البيانات الأصلية لتقييم تأثير استعادة الإشارة كمياً.في الوقت نفسه، قارنت الدراسة genESOM وجهاً لوجه مع طريقتين توليديتين رئيسيتين: نموذج الخليط الغاوسي (GMM) وشبكة الخصومة التوليدية للجدول الشرطي (CT-GAN)، باستخدام معدل الإيجابية الكاذبة ومعدل السلبية الكاذبة ومعدل استعادة الإشارة الأصلية كمؤشرات أساسية للتحقق من مزايا النموذج.
يتفوق بشكل ملحوظ على أساليب التوليد التقليدية في سيناريوهات العينات الصغيرة.
كما هو موضح في الشكل أدناه، يكشف تحليل مجموعة البيانات الأصلية الكاملة عن اختلافات جوهرية بين المجموعات في 27 من أصل 62 متغيرًا دهنيًا، مع كون التغيرات في دهون الليزوفوسفاتيديل كولين هي الأكثر دلالة. تتوافق هذه النتيجة بشكل كبير مع نتائج الأبحاث السابقة حول التصلب المتعدد. في الوقت نفسه، يصنف نموذج الغابة العشوائية العينات بدقة تفوق بكثير دقة الاحتمالية العشوائية، مما يؤكد هاتين النتيجتين.وهذا يؤكد وجود إشارات بيولوجية مستقرة وموثوقة في البيانات الأصلية.
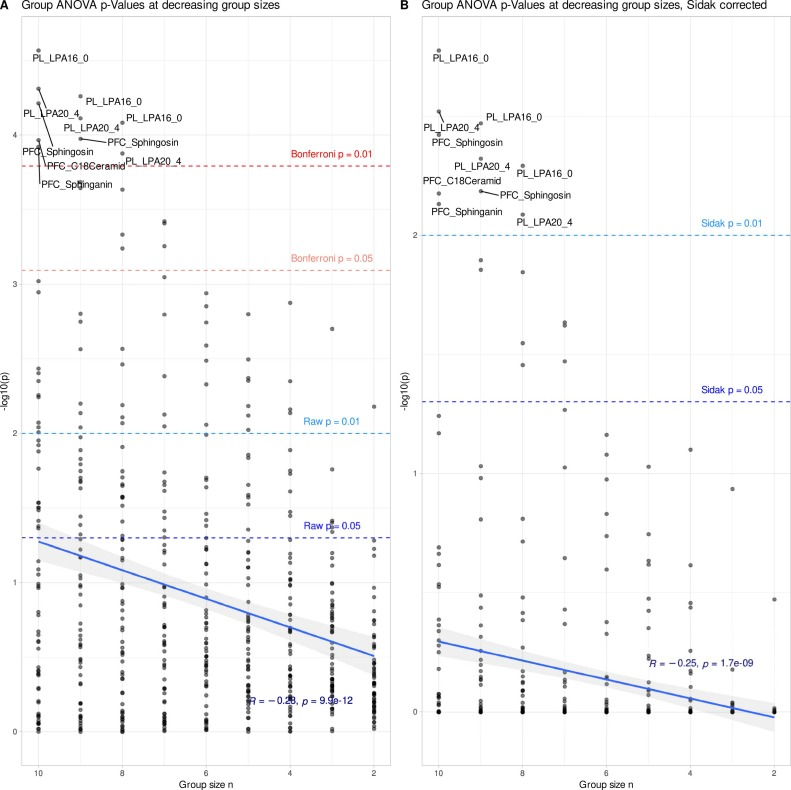
مع ذلك، عندما انخفض حجم العينة في كل مجموعة إلى 6 حيوانات، كما هو موضح في الشكل أدناه، تغيرت خصائص البيانات بشكل جذري: فبعد إجراء تصحيحات التحقق المتعددة، اختفت الدلالة الإحصائية لجميع مؤشرات الدهون تمامًا، وانخفضت كفاءة تصنيف الغابة العشوائية بشكل ملحوظ. ومن المهم التأكيد على أن هذا لا يعني اختفاء التأثيرات البيولوجية تمامًا.بدلاً من ذلك، يؤدي صغر حجم العينة إلى عدم كفاية قوة الكشف الإحصائي، وتطغى الضوضاء على الإشارة الحقيقية.
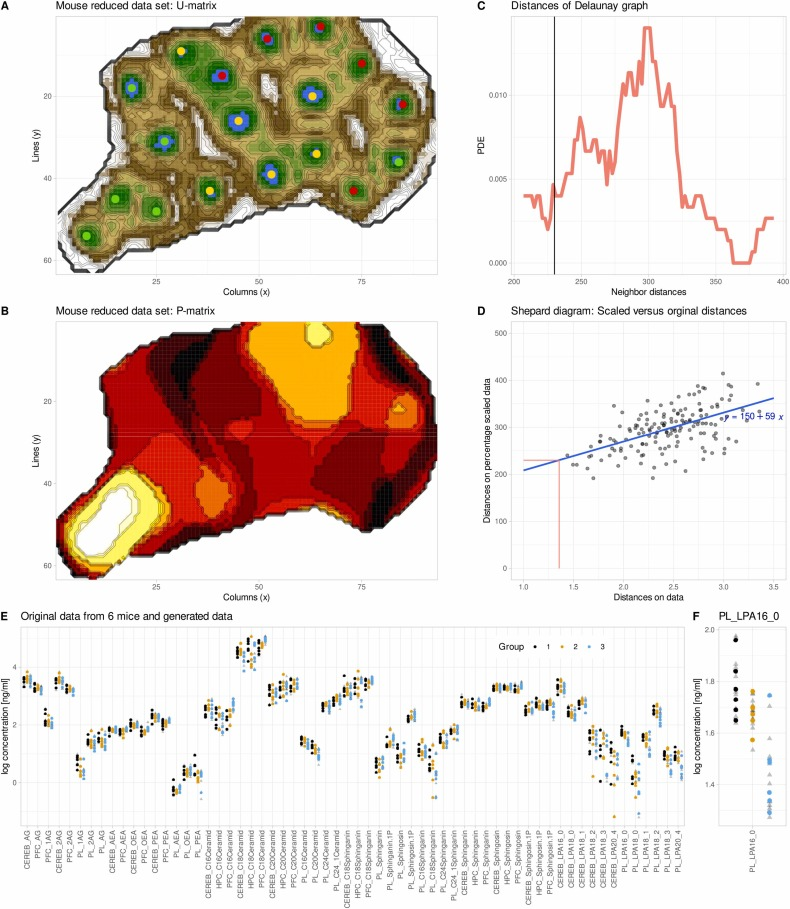
بعد ذلك، استخدم فريق البحث برنامج genESOM لزيادة البيانات المخفضة.بعد 20 جولة من التدريب، كان النموذج لا يزال قادراً على تحديد بعض اتجاهات الفصل بين المجموعات الثلاث من العينات في فضاء ESOM.وهذا يؤكد أنه حتى عندما تختفي الدلالة الإحصائية، فإن البيانات لا تزال تحتفظ بمعلومات هيكلية بيولوجية محتملة.
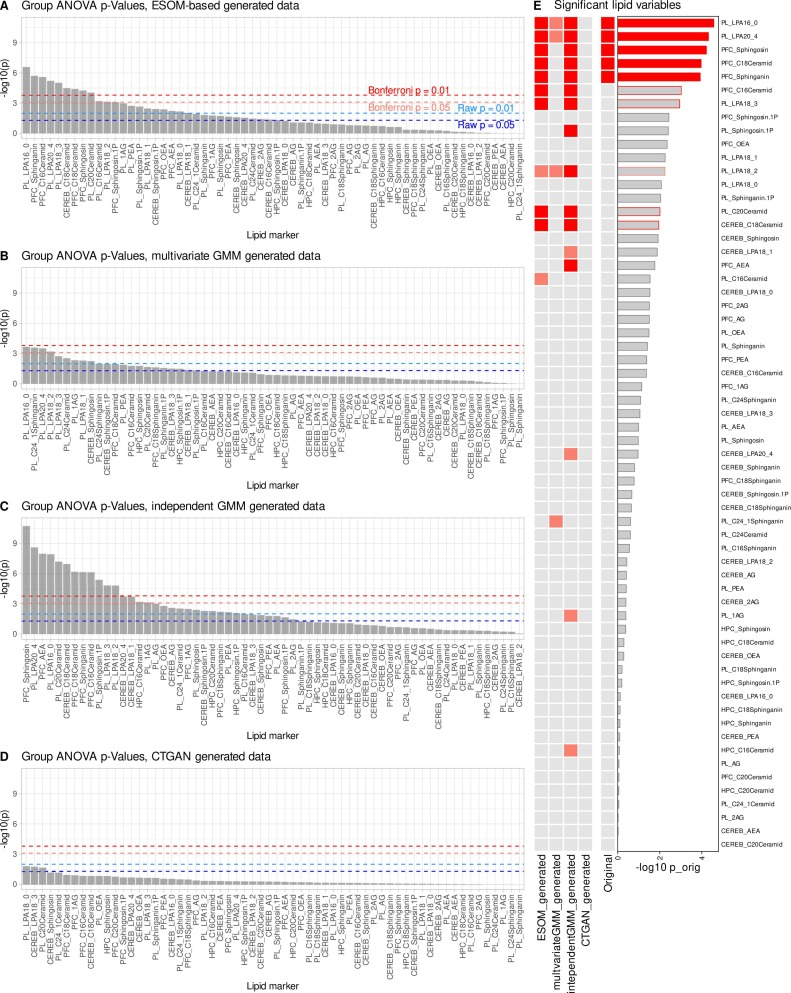
بعد زيادة البيانات، أظهرت مؤشرات الدهون الرئيسية، مثل حمض الليزوفوسفاتيديك والدهون السفينغولية في قشرة الفص الجبهي في البلازما، اختلافاتٍ كبيرة بين المجموعات مرة أخرى. كانت هذه المؤشرات قد فشلت تمامًا في بيانات العينات الصغيرة، ولكن تم استعادتها بنجاح من خلال تعزيز الذكاء الاصطناعي. في الوقت نفسه، لم يُدخل النموذج عددًا كبيرًا من السمات الجديدة غير المنطقية، ولم يظهر سوى عدد قليل من المؤشرات الإضافية ذات مستويات دلالة متقاربة.يشير هذا إلى أن genESOM لا يقوم بإنشاء إشارات جديدة من العدم، بل يقوم بتضخيم الإشارات البيولوجية الحقيقية الموجودة بالفعل ولكن لا يمكن اكتشافها بسبب عدم كفاية حجم العينة.
في ظل نفس ظروف العينة الصغيرة، كما هو موضح في الشكل أدناه، كان أداء طريقتي توليد التحكم ضعيفًا: لم يتمكن نموذج خليط غاوسي متعدد المتغيرات إلا من استعادة جزء من الإشارة الأصلية؛ بينما استعاد نموذج خليط غاوسي المستقل بعض المؤشرات المهمة، إلا أنه كان مصحوبًا بنتائج إيجابية خاطئة واضحة؛ ولم يتمكن نموذج GAN للجدول الشرطي من استعادة النتائج الأساسية بشكل فعال، مع ارتفاع معدل النتائج السلبية الخاطئة. بشكل عام،يُظهر برنامج genESOM استقرارًا وموثوقية أفضل بكثير من طرق التوليد التقليدية في سيناريوهات العينات الصغيرة.يمكنه استعادة الإشارات البيولوجية الرئيسية بدقة مع التحكم الصارم في انتشار الخطأ والاكتشافات الخاطئة.
كما هو موضح في الشكل أدناه، أكد تحليل التعلم الآلي هذا الاستنتاج بشكل أكبر: فقد أعادت البيانات المحسنة القدرة التصنيفية للغابة العشوائية، وكانت الميزات الرئيسية المختارة متسقة للغاية مع الدراسة الأصلية.
الكلمات الأخيرة
لطالما شكلت أحجام العينات الصغيرة تحديًا في البحوث الطبية الحيوية: فالتكاليف الباهظة، والعقبات الأخلاقية، وصعوبة الحصول على العينات تؤدي إلى ضعف القوة الإحصائية. كما أن أساليب زيادة البيانات التقليدية محدودة من حيث قابلية المقارنة، والذكاء الاصطناعي التوليدي العام عرضة للنتائج الإيجابية الخاطئة مع العينات الصغيرة. يكمن سر نجاح genESOM في عدم "تصنيع" البيانات، بل في استعادة الإشارات البيولوجية الموجودة بثبات من بيانات محدودة.
يفصل تصميمها الأساسي بين تعلم البنية وتوليد البيانات، ويقلل الأخطاء من خلال تعديل الأبعاد، ويُدخل آلية تحكم سلبية للمراقبة الآنية، مُشكلاً إطارًا مُقيدًا يقوم على "تحسين الموجود فقط، لا إنشاء ما هو غير موجود". من المهم إدراك أن التحسين لا يُغني عن التجارب العملية؛ فهذه الطريقة لا تزال في مرحلة الاستكشاف، وتتطلب قابليتها للتطبيق مزيدًا من التحقق. مع ذلك، يُرسل هذا البحث إشارةً هامة: ففي ظل تحكم دقيق في الأخطاء والنتائج الإيجابية الخاطئة، يمتلك الذكاء الاصطناعي التوليدي القدرة على أن يصبح أداة مساعدة فعالة للدراسات ذات العينات الصغيرة، مما يُساعد على استخلاص استنتاجات حقيقية من بيانات محدودة بموثوقية أكبر.








