Command Palette
Search for a command to run...
من خلال تحقيق تسريع الاستدلال بمقدار 1.4-3.7 مرة، يقترح معهد ماساتشوستس للتكنولوجيا تقنية DRiffusion للتغلب على عنق الزجاجة في زمن أخذ العينات في نماذج الانتشار.

في مجال الذكاء الاصطناعي التوليدي، تتغلب نماذج الانتشار، بفضل آلية إزالة التشويش التكرارية الفريدة، بفعالية على قيود النماذج التقليدية من حيث جودة التوليد وتنوعه، وقد تم تطبيقها على نطاق واسع في مجالات متطورة مختلفة مثل معالجة الصور والفيديو والصوت والتصميم الجزيئي. مع ذلك، تتطلب عملية التحسين هذه، التي تعتمد على الوقت مقابل الجودة، عادةً عشرات أو حتى مئات التكرارات للحصول على نتائج عالية الدقة.وينتج عن ذلك سرعات أخذ عينات بطيئة للغاية وتكاليف استدلال عالية.لقد أصبح هذا الأمر بمثابة عقبة رئيسية أمام نماذج الانتشار للانتقال نحو التطبيقات في الوقت الفعلي والنشر على نطاق واسع.
لمعالجة مشكلة بطء عملية أخذ العينات، اقترح الباحثون أساليب تسريع مثل التدفق المُقوَّم والتقطير: يقلل الأول من التكرارات غير الصالحة عن طريق تحسين مسار إزالة التشويش، بينما يستخدم الثاني تقطير المعرفة لتخفيف وزن النموذج. ومع ذلك، عندما يتم ضغط عدد خطوات أخذ العينات بشكل كبير سعيًا وراء نسبة تسريع عالية،كلا الطريقتين تضحي بشكل كبير بجودة الناتج (مثل فقدان التفاصيل وتشويه الأنسجة)، وقد يؤدي التقطير إلى تقليل تنوع النتائج بشكل كبير.
رغم أن تقنيات التوازي تُقدم نهجًا تكميليًا دون المساس بالجودة، إلا أن الأساليب الحالية على مستوى النظام محدودة ببنى النماذج (مثل U-Net وTransformer)، مما يُؤدي إلى ضعف مرونتها. أما الأساليب الرياضية، التي تُنمذج عملية الانتشار كمعادلات تفاضلية وتُصمم حلولًا فعالة، فغالبًا ما تُعاني من ضعف التوافق مع الأطر السائدة، وتكون عُرضة للانحراف عن توزيع العينات الأصلي. لا يُعالج أي من هذه الحلول بشكل جذري التبعية التسلسلية المتأصلة في نماذج الانتشار، حيث تعتمد كل خطوة من خطوات إزالة التشويش على مُخرجات الخطوة السابقة.
ولمعالجة هذا التحدي، قام باحثون في معهد ماساتشوستس للتكنولوجيا مؤخرًا بمعالجة المشكلة الأساسية، ومن خلال اكتشاف رياضي موجز ونموذج جدولة مبتكر، أثبتوا لأول مرة التوازي الجوهري غير المستغل ضمن إطار الانتشار. وبناءً على ذلك،اقترح الباحثون نموذج الانتشار DRiffusion الذي يعتمد على عملية المسودة والتنقيح.من خلال الجمع بين مزايا أساليب مستوى النظام والأساليب الرياضية، يتم تحقيق تسريع كبير دون التضحية بجودة التوليد، مما يوفر حلاً جديداً لتحقيق التوازن بين الدقة العالية وكفاءة أخذ العينات في نماذج الانتشار.
تم نشر نتائج البحث ذات الصلة، بعنوان "DRiffusion: عملية الصياغة والتحسين توازي نماذج الانتشار بسهولة"، كنسخة أولية على arXiv.
أبرز الأبحاث:
* ريادة إطار عمل DRiffusion المتوازي "المسودة والتحسين"، مما يكشف عن التوازي المتأصل في نماذج الانتشار.
* يوفر أوضاع تسارع قوية وأخرى متحفظة، مما يسمح بموازنة مرنة بين الجودة والسرعة.
* يحقق تسريعًا في العالم الحقيقي يتراوح من 1.4 إلى 3.7 مرة في الاختبارات الميدانية متعددة النماذج، مع جودة توليد شبه معدومة وتفوق شامل على الطرق الحالية.

عنوان الورقة:
https://arxiv.org/abs/2603.25872
تابع حسابنا الرسمي على WeChat وأجب بكلمة "DRiffusion" في الخلفية للحصول على ملف PDF كامل.
مجموعة بيانات MS-COCO: تحتوي على 5000 صورة و 25000 وصف.
استخدمت التجربة مجموعة التحقق MS-COCO 2017 كمجموعة بيانات مرجعية، والتي تحتوي على 5000 صورة.تُرفق كل صورة بخمسة أسطر نصية وصفية. ووفقًا للممارسات المعتادة، يُستخدم سطر الوصف الأول فقط لكل صورة لتقييم محاذاة الصورة مع النص، وذلك لضمان تطابق تام بين الصورة المُنشأة والنص المرجعي، مما يضمن دقة التقييم.
نظراً لعدم كفاية حساسية المقاييس التقليدية للتفضيلات البصرية الدقيقة، تُقدّم هذه الدراسة مقياسَي PickScore وHuman Preference Score v2.1 (HPSv2.1) كتقييمات تكميلية. ولتقييم الكفاءة، استُخدم ما يصل إلى أربع وحدات معالجة رسومية NVIDIA V100، وقُيس متوسط زمن استجابة أخذ العينات من خلال عدة عمليات تشغيل في حالة الاستقرار. ويُبيّن التقرير التسارع النسبي مقارنةً بنموذج الانتشار الأساسي أحادي وحدة المعالجة الرسومية، بالإضافة إلى الحمل الزائد للذاكرة الناتج عن هذه الطريقة.
للمقارنة مع خط الأساس، تم اختيار طريقتين تمثيليتين لتسريع نموذج الانتشار: التخطي المباشر (أي تقليل عدد خطوات أخذ العينات) وAsyncDiff (موازاة إزالة التشويش عن طريق توزيع الشبكات الفرعية على أجهزة مختلفة وإجراء أخذ عينات غير متزامن). ولضمان اتساق التقييم، أعاد الباحثون إنتاج النتائج التجريبية استنادًا إلى التطبيق الرسمي لـ AsyncDiff في ظل نفس إعدادات القياس.
DRiffusion: سهولة موازاة نماذج الانتشار من خلال عملية تحسين المسودة
يعتمد تصميم DRiffusion على سؤال أساسي: هل يمكن لنموذج الانتشار أن يحسب تنبؤات الضوضاء لعدة خطوات زمنية في آن واحد؟ في نموذج الانتشار الأصلي، يصعب تحقيق هذا الهدف بشكل مباشر لأن كل خطوة لإزالة الضوضاء تعتمد على حالة الإخراج للخطوة السابقة.توفر الانتقالات المتقطعة منظورًا جديدًا للتغلب على هذا القيد:إذا أمكن اعتبار عملية التخطي بمثابة عامل محلي قابل للاستدعاء بشكل مستقل، فإنه يمكن إنشاء الحالات الوسيطة مباشرة دون الحاجة إلى التحرك على طول المسار الكامل، وبالتالي تحقيق الحساب المتوازي عبر الخطوات الزمنية.
مفهوم الانتقالات القفزية ليس جديدًا. كما هو موضح في الشكل أدناه، من منظور الزمن المستمر، يمكن دمج ديناميكيات النظام على مدى فترة زمنية أطول، وتجاوز الخطوات الوسيطة عملية طبيعية. ومع ذلك، حاليًا...تستخدم أطر نماذج الانتشار عادةً درجة الحرية هذه فقط على المستوى العالمي (على سبيل المثال، عن طريق إعادة تحديد تسلسل الخطوة الزمنية).هناك نقص في آلية خطوة بخطوة يمكن استدعاؤها محلياً واستخدامها عند الطلب.

تحقيقا لهذه الغاية،تقوم خوارزمية DRiffusion أولاً بتحويل انتقال القفز إلى عامل.على وجه التحديد، بالنسبة لنماذج الانتشار السائدة مثل DDPM وDDIM والحلول القائمة على المعادلات التفاضلية العادية (ODE)، يتم اشتقاق صيغة انتقال القفزة الموحدة، والتي تتيح الاتصال المباشر بين أي حالتين من حالات الانتشار دون الحاجة إلى إعادة تعريف الجدول الزمني العالمي للخطوة الزمنية.
بأخذ نموذج DDPM كمثال، فإن الانتقال المفاجئ من الحالة الحالية x_t إلى الحالة المستقبلية x_t-k له حل مغلق؛ ويمكن تعميم نموذج DDIM بناءً على اتساق التوزيع الهامشي؛ وفي نمذجة المعادلات التفاضلية العادية، فإن تخطي الخطوات الوسيطة يعادل استخدام حجم خطوة تكامل عددي أكبر مباشرةً. يُحسّن إدخال هذا المؤثر بشكل كبير مرونة تصميم نمط أخذ العينات، ويضع الأساس للتوازي اللاحق.
استنادًا إلى عامل الانتقال القفزييمكن تلخيص سير العمل الأساسي لـ DRiffusion في مرحلتين: إنشاء المسودة وتحسينها.انطلاقًا من الحالة x_t عند الخطوة الزمنية t، تُولَّد الحالات للخطوات الزمنية k اللاحقة بالتوازي باستخدام انتقالات القفز للحصول على تقديرات للمسودة. ونظرًا لزيادة حجم الخطوة، فإن دقة هذه المسودات أقل قليلًا من دقة التكرارات المتتالية، لكن النتائج الإجمالية لا تزال متوافقة مع المسار الأصلي بعد إزالة التشويش.
بعد ذلك، تُدخل هذه المسودات بالتوازي إلى مُتنبئ الضوضاء للحصول على تقديرات الضوضاء المقابلة. ثم تُجرى تحديثات قياسية لإزالة الضوضاء لتحسين كل مسودة، وأخيرًا، يتم الحصول على الحالة المُحسّنة والضوضاء المقابلة لها، والتي تُشكّل نقطة ارتكاز للتكرار التالي.
يواجه هذا التصميم مشكلة محتملة: قد يؤدي حجم خطوة القفزة الكبير إلى انخفاض جودة التوليد بسبب عيوب في توقع الضوضاء. وقد أشارت الأبحاث السابقة إلى هذا الخطر، لكن ملاحظاتنا التجريبية تكشف عن عاملين مخففين.أولاً،إن الانخفاض الطفيف في الجودة المتصورة لا يعادل انخفاضًا كبيرًا في القدرة التمثيلية؛ فالصور المولدة أو المتجهات الكامنة عادة ما تحتفظ بمعظم المعلومات الدلالية والهيكلية الأساسية.ثانية،على الرغم من أن مُتنبئ الضوضاء ليس دقيقًا تمامًا، إلا أن قدرته على التعميم كافية لرسم خرائط معقولة لمجموعات العينات المجاورة والحصول على نتائج معقولة. وبناءً على هاتين النقطتين، لا يزال بإمكان DRiffusion إخراج صور عالية الجودة حتى عند استخدام خطوة كبيرة.
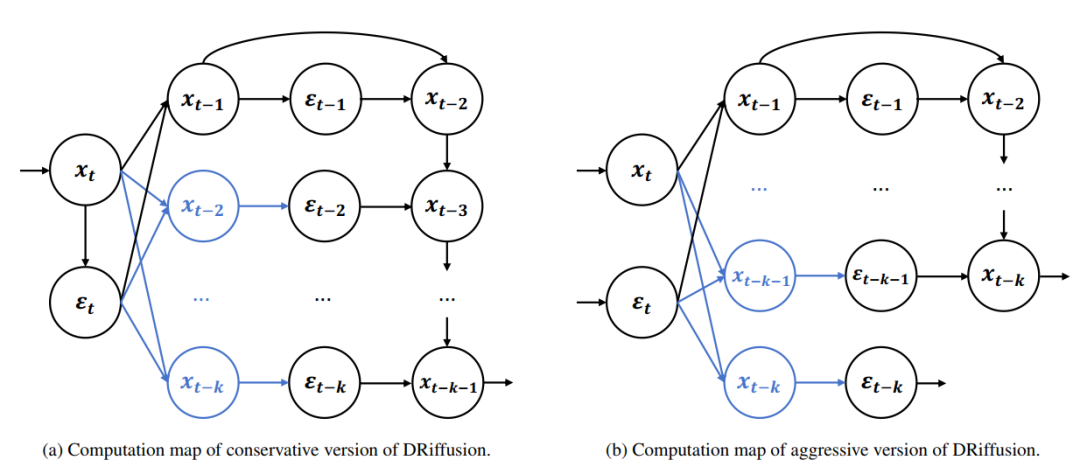
من حيث التنفيذ، يتضمن DRiffusion نسختين: جذرية ومحافظة.
كما هو موضح في الشكل أدناه، تُجري النسخة الجذرية عملية متوازية كاملة لتوقعات الضوضاء المتعددة في دورة واحدة. وبافتراض تجاهل التكاليف الإضافية البسيطة مثل تكاليف الاتصال، يمكن أن يصل التسريع الأمثل إلى k ضعف، أي أن زمن التشغيل ينخفض إلى 1/k من الزمن الأصلي.
تقوم النسخة المحافظة أولاً بحساب ضوضاء التيار بدقة عالية (ناتجة عن الحالة المُحسَّنة)، ثم تستخدمها كأساس لإعادة إنتاج عملية النسخة المُحسَّنة، مع إضافة خطوة زمنية إضافية، لتحقيق تسريع مثالي قدره 2k+1 مرة. الفكرة الأساسية لكلا النسختين واحدة: استبدال المسودة بقوة الحوسبة المتوازية، والتحسين لضمان جودة المخرجات.
تم تحقيق زيادة في السرعة الفعلية تقارب 3 أضعاف على 3 وحدات معالجة رسومية.
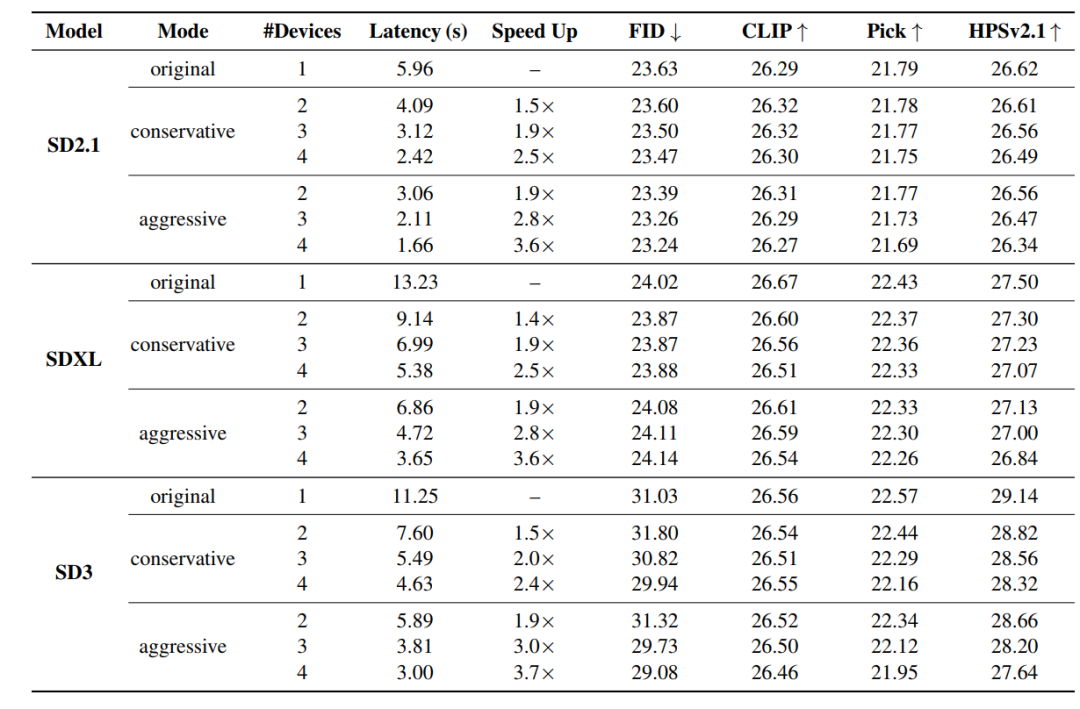
للتحقق من أداء خوارزمية DRiffusion، شملت التجارب نماذج انتشار ذات بنى ومقاييس متنوعة، بما في ذلك Stable Diffusion 2.1 (SD2.1) القائم على U-Net، وStable Diffusion XL (SDXL) القائم على U-Net، وStable Diffusion 3 (SD3) القائم على Transformer لمطابقة التدفق. لا يُسهّل هذا التغطية متعددة النماذج إجراء مقارنات عادلة مع الطرق الحالية فحسب، بل يختبر أيضًا بشكل كامل مدى عمومية الطريقة.
تظهر النتائج النوعية في الشكل أدناه. في ظل نسب تسارع عالية،بينما يكافح برنامج DRiffusion لإعادة إنتاج مخرجات البكسل تلو البكسل للخط الأساسي بشكل كامل، فإنه يحافظ باستمرار على الاتساق الدلالي ويحافظ بشكل فعال على التفاصيل الدقيقة (مثل نسيج الخشب واللمعان على صدر القطة).من خلال تخطي بعض خطوات أخذ عينات الضوضاء بشكل معتدل، يمكن للنسخة المُسرّعة أحيانًا توليد صور ذات تباين أقوى وتفاصيل أدق (مثل انعكاسات عين القطة). قد يؤدي التسريع المفرط (حوالي 4 أضعاف) إلى فقدان طفيف في الجودة، مثل تشبع الألوان الزائد أو ظهور بعض التشوهات البسيطة، ولكنه بشكل عام يحافظ على اتساق عالٍ مع النسخة الأساسية.

تظهر النتائج الكمية في الجدول أدناه.في جميع التكوينات، تكون قيمة FID قريبة جدًا من خط الأساس، ولا يتجاوز الحد الأقصى للانخفاض في درجة CLIP 0.16.في بعض الحالات، تحسّن مؤشر FID بشكل طفيف، ويعود ذلك أساسًا إلى التباين الإحصائي وليس إلى التحسينات المنهجية. تُظهر تقييمات PickScore وHPSv2.1 التكميلية انخفاضًا متوسطًا قدره 0.17 و0.43 على التوالي. الاستثناء الوحيد هو SD3 في وضع الأجهزة الأربعة المكثف، حيث انخفض HPSv2.1 بمقدار 1.50. ويعود ذلك إلى أن عدد خطوات أخذ العينات الافتراضي في SD3 هو 28 خطوة فقط، وحجم الخطوة الكبير جدًا يُضخّم خطأ التقريب. وبالنظر إلى استقرار المقاييس الأربعة والتحسينات الكبيرة في السرعة، يُعدّ هذا التراجع في الجودة مقبولًا.
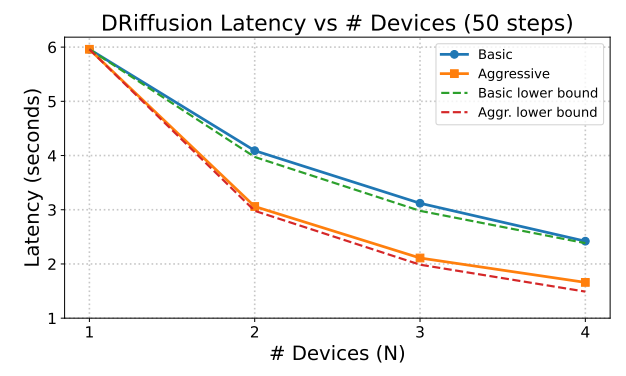
من حيث أداء التسارع،يتراوح التسريع الفعلي بين 1.4 و 3.7 مرة، والتكلفة الحسابية الإجمالية لكل عينة هي نفسها تقريبًا مثل النموذج الأصلي.تُظهر البيانات التجريبية أن مقياس التأخير للوضع العدواني قريب من الحد الأدنى النظري O(1/N)، بينما يتوافق الوضع المحافظ بشكل كبير مع O(2/(N+1))، مما يثبت أن DRiffusion يحقق توازيًا فعالًا وقابلًا للتوسع.
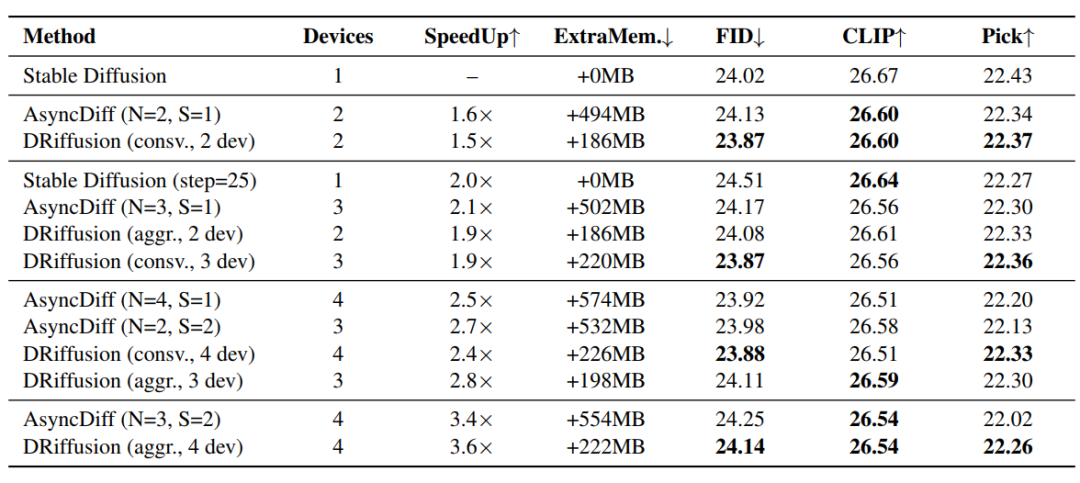
تظهر نتائج مقارنة الطرق في الجدول أدناه.في جميع مجموعات تسريع الأداء، تفوقت تقنية DRiffusion على تقنية AsyncDiff وتقنية تخطي الأساس البسيطة من حيث جودة التوليد.باستخدام PickScore، الأكثر حساسيةً للتسارع، كمقياس أساسي، قلّل DRiffusion فجوة تدهور الأداء بمعدل 48.61 TP3T، مع انخفاض أقصى قدره 58.51 TP3T لأربعة أجهزة. يرتبط تأثير التسارع خطيًا تقريبًا بعدد الأجهزة، ونسبة التسارع مماثلة أو أفضل قليلًا من AsyncDiff لعدد مماثل من الأجهزة.
تتجلى ميزة كفاءة الذاكرة بشكل أوضح: يتطلب AsyncDiff ما يصل إلى 574 ميجابايت من الذاكرة الإضافية، وتزداد هذه الزيادة مع عدد الأجهزة، بينما لا يُضيف DRiffusion سوى عبء ثابت يتراوح بين 186 و226 ميجابايت. وبالمقارنة مع متطلبات الذاكرة الأساسية لـ SDXL التي تبلغ حوالي 13 جيجابايت، يُعد هذا العبء ضئيلاً. عند حجم دفعة يبلغ 5، واجه AsyncDiff خللاً في نقص الذاكرة على عقدة بسعة 32 جيجابايت، بينما عمل DRiffusion بشكل طبيعي.والسبب هو أن DRiffusion يقوم فقط بتعديل عملية تكرار أخذ العينات، وفصلها عن بنية النموذج والحساب الأساسي.
في ملخص،يحقق DRiffusion سرعة تقارب 3 أضعاف على 3 وحدات معالجة رسومية مع الحفاظ على جودة التوليد والتفاصيل الدقيقة، مما يحسن سرعة الاستدلال بشكل كبير.من خلال الجمع بين السمات النظرية الموجزة والتنفيذ العملي المتوازي، تم تحقيق نتائج تجريبية عالية الجودة ومستقرة.
يؤدي التوازي في نماذج الانتشار إلى تسريع العملية
أصبح التوازي في نماذج الانتشار محورًا رئيسيًا للبحث العلمي، يحظى باهتمام الأوساط الأكاديمية والصناعية على مستوى العالم. وفي الأوساط الأكاديمية، حققت العديد من المؤسسات الرائدة إنجازاتٍ بارزة في هذا المجال. فعلى سبيل المثال، حقق نموذج Fast-dLLM، الذي اقترحه معهد ماساتشوستس للتكنولوجيا وجامعة هونغ كونغ بالاشتراك، تسريعًا شاملاً بمقدار 27.6 ضعفًا لنماذج لغة الانتشار واسعة النطاق (مهام توليد النصوص الطويلة) دون الحاجة إلى إعادة تدريب النموذج، مع الحفاظ على نسبة فقدان الدقة ضمن 2%.
عنوان الورقة: FAST-DLLM V2: نموذج LLM فعال بتقنية الانتشار الكتلي
رابط الورقة:https://arxiv.org/pdf/2509.26328
يدمج نظام البث StreamDiffusionV2 الذي طورته جامعة كاليفورنيا في بيركلي جدولة دفعية واعية بمستوى الخدمة ووحدة تحكم في الضوضاء واعية بالحركة لنماذج انتشار الفيديو، مما يزيد من معدل إطارات توليد الفيديو إلى 58 إطارًا في الثانية في بيئة متعددة وحدات معالجة الرسومات، ويتغلب على عنق الزجاجة في قوة الحوسبة لتوليد الفيديو في الوقت الحقيقي.
عنوان الورقة: StreamDiffusionV2: نظام بث لإنشاء فيديو ديناميكي وتفاعلي
رابط الورقة:https://arxiv.org/abs/2511.07399
في قطاع المؤسسات، دمجت NVIDIA تقنية المعالجة المتوازية بشكلٍ عميق في منظومتها البرمجية والمادية. ومن خلال تحسين مسارات الحوسبة والتعاون بين الأجهزة المتعددة، تُحسّن NVIDIA بشكلٍ ملحوظ سرعة استدلال نماذج الانتشار وتُقلّل التكاليف الحسابية في سيناريوهات توليد الصور والفيديوهات. من جهة أخرى، تستكشف تقنية Stability AI استراتيجيات أخذ العينات المتوازية في سلسلة نماذج Stable Diffusion. ومن خلال تحسين معلمات المعالجة الدفعية وتمكين أدوات أخذ العينات التي تدعم المعالجة المتوازية، مثل DDIM وPLMS، تُحسّن هذه التقنية كفاءة توليد الصور بمقدار 3 إلى 5 أضعاف مع الحفاظ على جودة التوليد.
باختصار، ساهمت الجهود المشتركة بين الأوساط الأكاديمية والصناعية في جعل موازاة نماذج الانتشار موضوعًا بالغ الأهمية لتحقيق اختراقات تكنولوجية. وقد أثبت نموذج DRiffusion، كحل نموذجي، جدوى وكفاءة استغلال التوازي المتأصل. في المستقبل، ومع التعاون الوثيق بين الأجهزة والخوارزميات، يُتوقع أن تُحقق نماذج الانتشار تجربة توليد فورية حقيقية مع الحفاظ على دقة عالية، مما يُزيل عوائق الكفاءة أمام التطبيق الأوسع للذكاء الاصطناعي.
روابط مرجعية:
1.https://mp.weixin.qq.com/s/70OiIuuNP2PWgIV_hiRZBQ








