Command Palette
Search for a command to run...
مؤتمر GTC 2026 | من فيرا روبين إلى نيمو كلاو: هل يمتد مستقبل إنفيديا إلى ما هو أبعد من وحدات معالجة الرسومات؟

لطالما اعتُبرت الكلمة الرئيسية التي يلقيها الرئيس التنفيذي لشركة NVIDIA، جنسن هوانغ، في مؤتمرها السنوي العالمي للتقنية (GTC) مؤشراً هاماً على صناعة الذكاء الاصطناعي العالمية. فمن بنية الجيل القادم لوحدات معالجة الرسومات (GPU) إلى تطوير منظومة البرمجيات، غالباً ما تُنبئ هذه الكلمة الرئيسية بالتقنيات الرائجة واتجاهات تطوير البنية التحتية للحوسبة في مجال الذكاء الاصطناعي خلال السنوات القادمة.
في السادس عشر من مارس بالتوقيت المحلي، أُلقيت الكلمة الرئيسية في مؤتمر GTC 2026 كما هو مقرر. وظهر جينسن هوانغ، البالغ من العمر 63 عامًا، مرتديًا سترته الجلدية المميزة، وقدم بحماس سلسلة من المنتجات الجديدة الهامة في ملعب سان خوسيه في كاليفورنيا.
ليس فقط وحدات معالجة الرسومات
باعتباره "المنتج النجم" في خارطة طريق رقائق الذكاء الاصطناعي لشركة NVIDIA،كما أثارت منصة فيرا روبين شهية الجمهور في مؤتمر GTC لهذا العام - فهي تتكون من 7 رقائق رائدة، و5 رفوف، وجهاز كمبيوتر عملاق واحد.وصفها جنسن هوانغ بأنها قفزة نوعية في مجال التكنولوجيا. ومن أبرز مكوناتها وحدة معالجة الرسومات Rubin، ووحدة معالجة الرسومات NVIDIA Groq 3 LPX، ووحدة المعالجة المركزية NVIDIA Vera.
أولًا، وحدة معالجة الرسومات Rubin، وهي بنية جديدة كليًا مصممة خصيصًا للذكاء الاصطناعي الآلي، وقد تم الكشف عنها رسميًا في يناير من هذا العام. تتميز بمحرك Transformer من الجيل الثالث مع ضغط تكيفي مُسرّع بالأجهزة، مما يوفر أداءً حاسوبيًا يصل إلى 50 بيتافلوب من نوع NVFP4 لاستنتاج الذكاء الاصطناعي، ويدعم الربط البيني الكامل NVLink 72.
ثانيًا، هناك تطبيق تقنية Groq في شركة NVIDIA. منذ أن أنفق جنسن هوانغ 20 مليار دولار للحصول على ترخيص تقنية Groq في نهاية عام 2025، انتشرت تكهنات بأن هذه الخطوة تهدف إلى "التخلي عن وحدات معالجة الرسومات لصالح وحدات المعالجة المنطقية". الآن، وبعد أن هدأت الأمور، أصبح هناك تكامل وتناغم جيد بين التقنيتين.
في عمليات النشر واسعة النطاق، تعمل مجموعات وحدات المعالجة المنطقية (LPU) كمعالج واحد ضخم لتسريع الاستدلال السريع والحتمي. عند نشرها بالتزامن مع Vera Rubin NVL72، تعمل وحدات معالجة الرسومات Rubin ووحدات المعالجة المنطقية معًا على تحسين أداء فك التشفير من خلال حساب كل طبقة من نموذج الذكاء الاصطناعي لكل رمز إخراج. بناءً على ذلك، قدمت NVIDIA وحدة LPX المزودة بـ 256 معالجًا من وحدات المعالجة المنطقية، والمصممة خصيصًا لتلبية متطلبات زمن الاستجابة المنخفض والسياق الواسع لأنظمة الوكلاء.عند دمجها مع فيرا روبين، يمكنها أن توفر ما يصل إلى 35 ضعف إنتاجية الاستدلال لكل ميغاواط لنماذج ذات تريليون معلمة.
وأخيرًا، هناك معالج NVIDIA Vera، وهو أول معالج في العالم مصمم لعصر الذكاء الاصطناعي الوكيل والتعلم المعزز.تبلغ كفاءة تشغيلها ضعف كفاءة وحدات المعالجة المركزية التقليدية المثبتة على الرف، وسرعة تشغيلها أسرع من 50%.بإمكانها توفير إنتاجية واستجابة وكفاءة أعلى للذكاء الاصطناعي في خدمات الذكاء الاصطناعي واسعة النطاق، مثل مساعدي البرمجة والوكلاء الأذكياء للمستهلكين والمؤسسات. صرّح جنسن هوانغ قائلاً: "لم يعد دور وحدة المعالجة المركزية يقتصر على دعم النماذج، بل أصبح تشغيلها. بفضل الأداء الرائد وكفاءة الطاقة العالية، تُمكّن فيرا أنظمة الذكاء الاصطناعي من التفكير بشكل أسرع والتوسع بفعالية أكبر."
وبناءً على ذلك، أصدرت NVIDIA أيضًا رفًا جديدًا تمامًا لوحدة المعالجة المركزية Vera يدمج 256 وحدة معالجة مركزية Vera مبردة بالسوائل، ويدعم أكثر من 22500 بيئة وحدة معالجة مركزية متزامنة، يمكن لكل منها أن تعمل بشكل مستقل وبكامل سرعتها.

يمثل إطلاق معالج Vera Rubin نقلة نوعية أخرى في قدرة NVIDIA التنافسية في عصر الذكاء الاصطناعي الوكيل. فمن قاعدة قوة الحوسبة لوحدة المعالجة المركزية Vera إلى ذروة الاستدلال لوحدة معالجة الرسومات Rubin، وثورة التخزين لوحدة معالجة البيانات BlueField-4، تدفع NVIDIA كل حلقة من حلقات مصنع الذكاء الاصطناعي إلى آفاق جديدة من خلال تصميم تعاوني فائق.
بالنسبة للمطورين والشركات، وبينما يستمتعون بمزايا هذه المصفوفة الضخمة والمتطورة باستمرار من الرقائق، يبرز تحدٍ عملي أكثر أهمية: مع تزايد تعقيد نماذج وحدات معالجة الرسومات (GPU) وكثرة مقاييس قوة الحوسبة، كيف يمكنهم تجاوز مواصفات الشركات المصنعة ومقارنة الأداء الحقيقي للأجهزة المختلفة بموضوعية؟ بعبارة أخرى، كيف يمكنهم تحديد الخيار الأنسب لأعمالهم بدقة من بين مجموعة واسعة من الخيارات؟
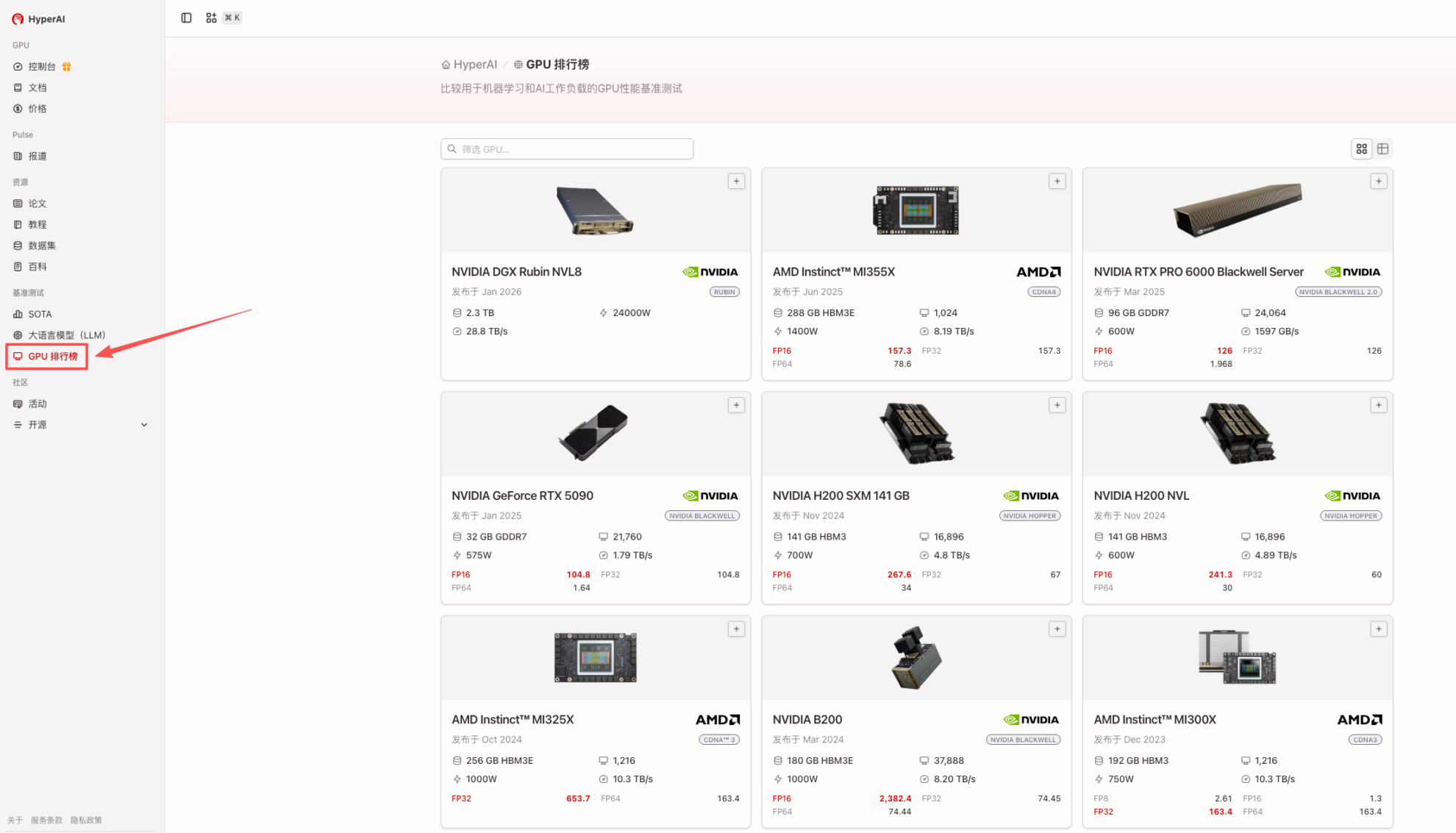
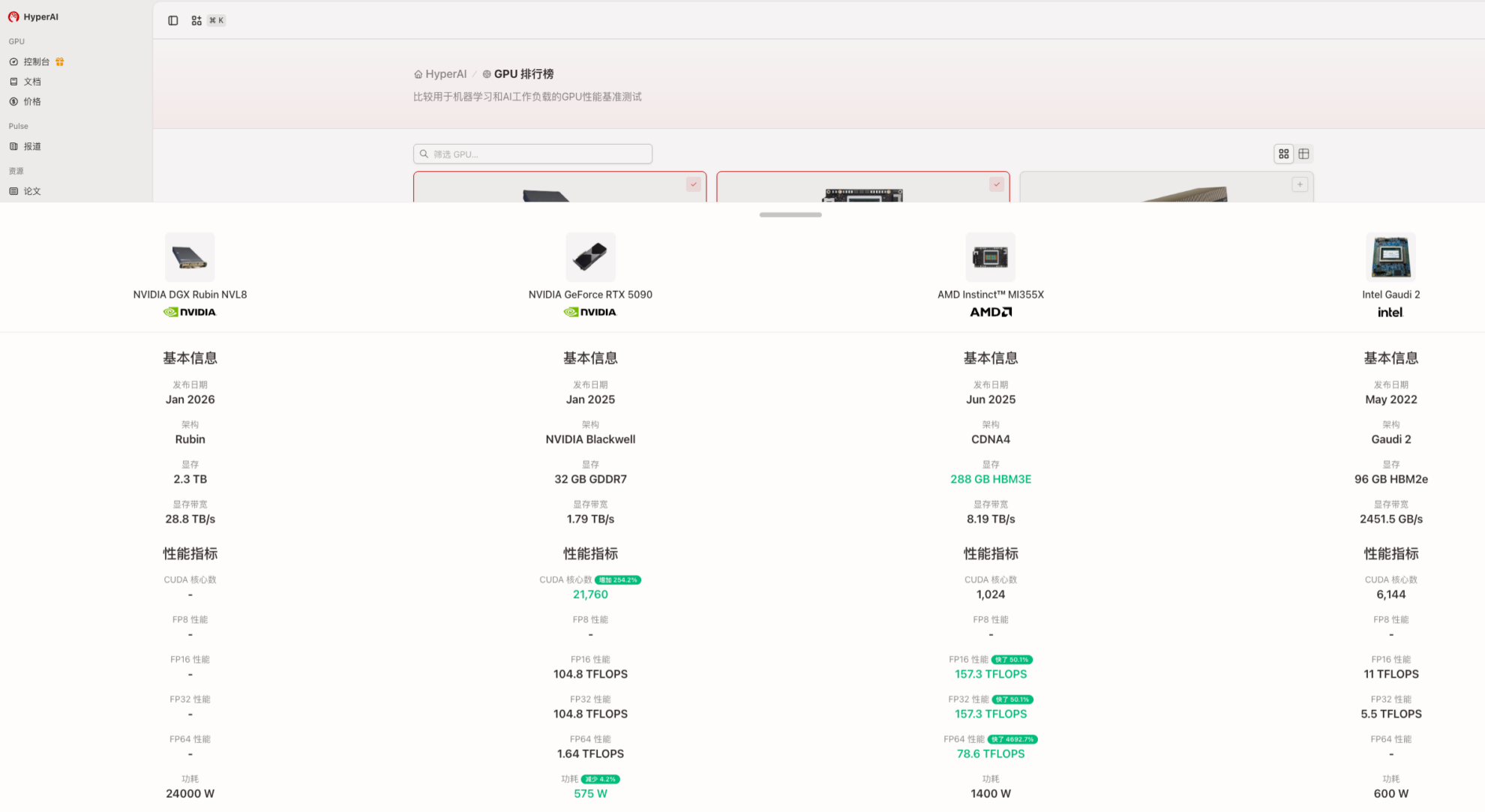
وفي ضوء ذلك،أطلقت شركة HyperAI "قائمة تصنيف وحدات معالجة الرسومات" لبناء منصة مرجعية لاختيار وحدات معالجة الرسومات واتخاذ القرارات لسيناريوهات الذكاء الاصطناعي/النماذج الكبيرة/الحوسبة عالية الأداء.يدعم النظام المقارنات بين مختلف الموردين والبنى، مستخدمًا قواعد مقارنة موحدة لمساعدة المستخدمين على اتخاذ قرارات تقنية سليمة وعقلانية في سوق معالجات الرسوميات/مسرعات الذكاء الاصطناعي المعقدة. وسيتابع HyperAI آخر تحديثات المنتجات لتزويد المطورين بأدوات عملية تركز على تطبيقات الذكاء الاصطناعي الواقعية.
تتوفر الآن مقارنة أداء معالجات الرسوميات (GPU) الجديدة من Rubin. اطلع على تصنيفات معالجات الرسوميات الآن:
https://hyper.ai/gpu-leaderboard
NemoClaw: تحسين OpenClaw بأمر واحد.
بعد إصدار خارطة طريق الجيل التالي من الرقائق، قدمت NVIDIA في الوقت نفسه إجابتها على "المرحلة التالية من الذكاء الاصطناعي" على مستوى البرمجيات: NemoClaw.
أشاد هوانغ رينكسون بالمشروع قائلاً: "لقد جلب OpenClaw آفاقاً جديدة في مجال الذكاء الاصطناعي للجميع، وأصبح أسرع مشاريع المصادر المفتوحة نمواً في التاريخ. نظاما التشغيل ماك وويندوز هما نظاما تشغيل الحواسيب الشخصية..."أما OpenClaw، من ناحية أخرى، فهو نظام تشغيل للذكاء الاصطناعي الشخصي.هذه هي اللحظة التي انتظرتها الصناعة بأكملها - بداية نهضة جديدة في مجال البرمجيات.
يستخدم برنامج NemoClaw برنامج NVIDIA Agent Toolkit لتحسين أداء OpenClaw بأمر واحد.يُدمج هذا النظام مباشرةً في بيئة NVIDIA. يقوم NemoClaw بتثبيت OpenShell، موفرًا نموذجًا مفتوح المصدر وبيئة معزولة لتعزيز خصوصية البيانات وأمانها للوكلاء المستقلين. يوفر هذا الحل للمخالب طبقة بنية تحتية أساسية كانت مفقودة سابقًا، مما يُمكّنها من الوصول اللازم لأداء المهام مع الالتزام في الوقت نفسه بضوابط أمنية قائمة على السياسات، وشبكة، وحماية للخصوصية. (انظر الرسم البياني أدناه).
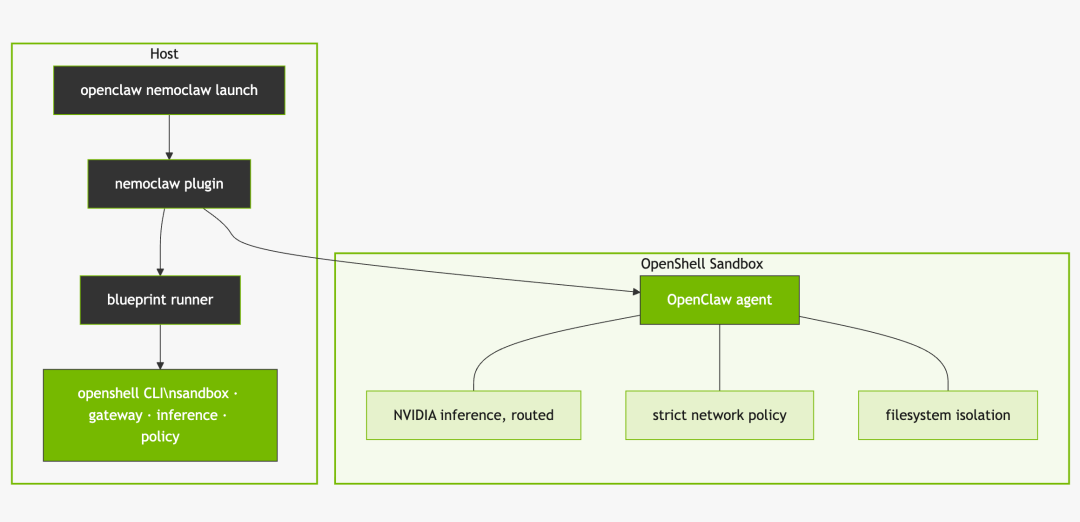
يدعم NemoClaw استخدام أي وكيل قابل للبرمجة. وبفضل بنيته المفتوحة، يمكنه استدعاء نماذج مفتوحة المصدر (بما في ذلك NVIDIA Nemotron) تعمل على النظام المحلي للمستخدم. وفي الوقت نفسه، ومن خلال موجه خصوصية، يمكن للوكيل أيضًا الوصول إلى أحدث النماذج التي تعمل على السحابة.يوفر الجمع بين النماذج المحلية والسحابية أساسًا للوكلاء لتعلم مهارات جديدة وإكمال المهام المعقدة ضمن قيود الخصوصية والأمان المعمول بها.
في هذا الإطار، بدأت رؤية جنسن هوانغ حول "نظام تشغيل الذكاء الاصطناعي الشخصي" تتضح معالمها: لم تعد الوكلاء مجرد واجهات لاستدعاء النماذج، بل أصبحت أدوات تنفيذ رقمية قادرة على العمل طويل الأمد والتعلم المستمر. إذا كانت وحدات معالجة الرسومات (GPUs) وبنية النظام المُطوَّرة حديثًا تُوفران أساسًا حاسوبيًا لهذه الرؤية، فإن NemoClaw يُحدد طريقة تشغيل الوكيل وحدود أمانه على مستوى البرمجيات، ليشكلا معًا رؤية NVIDIA الكاملة لـ"مصانع الذكاء الاصطناعي" و"قوى عاملة الذكاء الاصطناعي".
إلى حد ما، يُسهّل NemoClaw عملية تطوير OpenClaw. ومع ذلك، بالنسبة للمطورين، يُعدّ التحقق السريع من حالات الاستخدام بنفس القدر من الأهمية؛ لذلك،توفر HyperAI للمطورين في جميع أنحاء العالم بيئة تشغيل جاهزة للاستخدام ودفاتر ملاحظات عبر الإنترنت.يمكنك البدء في بناء وكيل الذكاء الاصطناعي الخاص بك دون الحاجة إلى إعدادات معقدة.
رابط الجري عبر الإنترنت:
أوبن كلاو: تشغيل استدعاءات واجهة برمجة التطبيقات باستخدام وحدة المعالجة المركزية المجانية
https://hyper.ai/notebooks/49888
برنامج تعليمي لتشغيل OpenClaw باستخدام وحدة معالجة الرسومات
https://hyper.ai/notebooks/49890
لا شك أن مؤتمر GTC السنوي يُعتبر منذ زمن طويل بمثابة "مهرجان ربيع الذكاء الاصطناعي"، فهو ليس مجرد منصة لعرض قدرات NVIDIA فحسب، بل يُعدّ أيضًا مرجعًا أساسيًا في مجال التكنولوجيا. وقد غطّت العديد من وسائل الإعلام هذا الحدث التكنولوجي الضخم، حيث غمرت المنتجات والتحديثات المتنوعة للنماذج اهتمام الجمهور. خلال الفترة القادمة، ستواصل HyperAI مشاركة معلومات معمقة حول نماذج ومجموعات بيانات المصادر المفتوحة عالية الجودة التي تم إطلاقها في هذا المؤتمر، بالإضافة إلى توفير تجارب تفاعلية عبر الإنترنت. تابعونا.