Command Palette
Search for a command to run...
تجميع مجموعات البيانات | مجموعات بيانات الاستدلال مفتوحة المصدر من NVIDIA و OpenAI والعديد من المؤسسات البحثية، والتي تغطي الرياضيات والفضاء البانورامي والإجابة على أسئلة الويكي ومهام البحث والفطرة البصرية وما إلى ذلك.

مع تطور النماذج الكبيرة من مجرد "القدرة على التحدث والكتابة" إلى "القدرة على التفكير والتحليل"، يتم إعادة تعريف أهمية البيانات.
في الماضي، دعمت مجموعات البيانات الضخمة متعددة الأغراض القدرة التعبيرية لنماذج اللغة؛ أما اليوم، فإن العقبة الحقيقية التي تحدد الحد الأقصى للنماذج تتجه تدريجيًا نحو بيانات الاستدلال ذات البنية الواضحة والمنطق الدقيق وعمليات الاستنتاج متعددة الخطوات. وسواء تعلق الأمر بمسائل رياضية معقدة، أو الإجابة على أسئلة معرفية متعددة المجالات، أو اتخاذ القرارات متعددة الخطوات واستخدام الأدوات، فإن كل ذلك يعتمد على دعم مجموعات بيانات استدلال عالية الجودة.
قد تركز مجموعات بيانات الاستدلال على الرياضيات والمنطق، أو تبني سلاسل استدلال معقدة من خلال التركيب. كما يمكن استخدامها لتقييم القدرات متعددة المهام، أو كمعايير علمية لتحسين أنظمة الإجابة على الأسئلة. مع ذلك، تتسم هذه الموارد البيانية بتشتت كبير، إذ غالبًا ما توجد بتنسيقات مختلفة، مما يصعب استخدامها بشكل موحد. وهذا ما يدفع العديد من المطورين والباحثين إلى قضاء وقت طويل في مجرد "البحث عن البيانات".
لذلك،قامت شركة HyperAI بتجميع مجموعة من مجموعات بيانات الاستدلال عالية الجودة، والتي تغطي الاستدلال متعدد المجالات ومتعدد المهام، وبيانات تدريب الاستدلال الاصطناعي، ومعايير البحث العلمي، وبيانات الإجابة على الأسئلة واسعة النطاق.كما يدعم تنزيل أو استخدام مجموعات البيانات عبر الإنترنت، مما يقلل من عائق الدخول لاستخدام مجموعات بيانات الاستدلال.
المزيد من مجموعات البيانات عالية الجودة:
مجموعة بيانات مشكلة الاستدلال Open-RL
* استخدم عبر الإنترنت:
Open-RL هي مجموعة بيانات لمشاكل الاستدلال متعددة المجالات أصدرتها شركة Turing في عام 2026، وتحتوي على مشاكل استدلال STEM مستقلة وقابلة للتحقق وصريحة في الفيزياء والرياضيات وعلم الأحياء والكيمياء.
تتطلب كل مسألة استدلالًا متعدد الخطوات، وتتضمن عمليات رمزية و/أو حسابات عددية، ولها إجابة نهائية قابلة للتحقق بموضوعية. تُعدّ هذه المجموعة من البيانات مناسبة لضبط نماذج التعلم المعزز، ونمذجة المكافآت، والتدريب الخاضع للإشراف على النتائج، وقياس أداء الاستدلال القابل للتحقق.
مجموعة بيانات اصطناعية للاستدلال العام من CHIMERA
* استخدم عبر الإنترنت:
CHIMERA هي مجموعة بيانات استدلالية اصطناعية مصممة خصيصًا لتدريب الاستدلال، وتغطي مجموعة واسعة من مواضيع العلوم والتكنولوجيا والهندسة والرياضيات، وتوفر مسارات طويلة لسلسلة التفكير (CoT).
تحتوي هذه المجموعة من البيانات على 9225 سؤالاً موزعة على 8 مواد دراسية (الرياضيات، وعلوم الحاسوب، والكيمياء، والفيزياء، والأدب، والتاريخ، والأحياء، وعلم الصوتيات). جميع الأمثلة مُولَّدة بواسطة نموذج لغوي ضخم (LLM) ويتم التحقق من صحتها تلقائياً دون الحاجة إلى أي تعليق يدوي.
توزيع الموضوع:
* الرياضيات: 4452
*علوم الحاسوب: 1303
*الكيمياء: 1102
*الفيزياء: 742
*الأدب: 504
*التاريخ: 422
*علم الأحياء: 383
*علم اللغة: 317
مجموعة بيانات الاستدلال الرياضي Nemotron-Math-v2
* استخدم عبر الإنترنت:
Nemotron-Math-v2 هي مجموعة بيانات للاستدلال الرياضي أصدرتها شركة NVIDIA. وهي تُستخدم بشكل أساسي لتدريب نماذج اللغة على أداء الاستدلال الرياضي المنظم، ودراسة الاختلافات بين الاستدلال المعزز بالأدوات والاستدلال اللغوي البحت، وبناء أنظمة استدلال طويلة السياق أو متعددة المسارات.
تحتوي هذه المجموعة من البيانات على ما يقارب 347,000 مسألة رياضية عالية الجودة و7 ملايين مسار استدلال مُولّد بواسطة النموذج. تُحل كل مسألة في ستة تكوينات: عمق استدلال عالٍ/متوسط/منخفض، مع أو بدون استخدام تقنية TIR في بايثون، ويتم التحقق من صحة الإجابات عبر مسار معالجة باستخدام نموذج خطي للتعلم (LLM) كمعيار للحكم.
مجموعة بيانات معيارية للاستدلال المكاني البانورامي الشامل
* استخدم عبر الإنترنت:
OmniSpatial هي مجموعة بيانات مرجعية شاملة للاستدلال المكاني، صدرت عام 2025 عن جامعة تسينغهوا بالتعاون مع معهد شنغهاي للدراسات المتقدمة في تكنولوجيا الفضاء، ومختبر شنغهاي للذكاء الاصطناعي، ومؤسسات أخرى. تحمل الورقة البحثية ذات الصلة عنوان "OmniSpatial: نحو معيار شامل للاستدلال المكاني لنماذج لغة الرؤية"، وتهدف إلى سد الفجوة في تقييم الفهم المكاني لنماذج لغة الرؤية.
تحتوي هذه المجموعة من البيانات على ما يقارب 1533 عينة من أسئلة الإجابة على الصور، تغطي أربع فئات رئيسية من مهام الاستدلال المكاني: الاستدلال الديناميكي، والمنطق المكاني المعقد، والتفاعل المكاني، وفهم وجهات النظر المختلفة، بإجمالي 50 مهمة فرعية. تتنوع مصادر البيانات، وتشمل صورًا من الإنترنت، واختبارات نفسية، وأسئلة اختبارات القيادة. خضعت التعليقات التوضيحية لعدة جولات من المراجعة لضمان الجودة والتنوع. بالمقارنة مع المعايير التقليدية، يتجنب OmniSpatial البناء القائم على القوالب، مما يجعله أقرب إلى محاكاة سيناريوهات العالم الحقيقي المعقدة. فهو لا يختبر العلاقات المكانية الأساسية فقط (مثل الأمام/الخلف، واليسار/اليمين، والمسافة)، بل يركز أيضًا على التفاعلات بين الكائنات المتعددة، وتغيرات المشهد، والاستدلال عبر وجهات النظر المختلفة.
هذه المجموعة من البيانات مناسبة لتدريب وتقييم قدرات الاستدلال المكاني للنماذج متعددة الوسائط الكبيرة، وخاصةً في تطبيقات مثل الملاحة الذكية، والواقع المعزز/الافتراضي، وفهم المشاهد المعقدة. وهي مجموعة بيانات مرجعية موحدة شاملة وصعبة.
مجموعة بيانات تقييم مهام البحث الاستدلالي من FrontierScience
* استخدم عبر الإنترنت:
FrontierScience هي مجموعة بيانات لتقييم مهام الاستدلال والبحث العلمي، تم إصدارها بواسطة OpenAI في عام 2025. وتهدف إلى تقييم قدرات النماذج الكبيرة بشكل منهجي في الاستدلال العلمي على مستوى الخبراء والمهام الفرعية للبحث العلمي.
تستخدم مجموعة البيانات هذه آلية تصميم "إنشاء الخبراء + هيكل مهمة من طبقتين + آلية تسجيل تلقائية"، وتنقسم إلى مجموعتين فرعيتين، تتوافقان مع نوعين من القدرات: التفكير الدقيق المغلق والتفكير البحثي العلمي المفتوح.
مجموعة بيانات الأولمبياد
صُممت هذه الأسئلة في الأصل من قبل الفائزين بالميداليات ومدربي المنتخبات الوطنية في الأولمبياد الدولية للفيزياء والكيمياء والأحياء، وهي ذات مستوى صعوبة مماثل للمسابقات الدولية الكبرى مثل IPhO وIChO وIBO؛ مع التركيز على مهام الاستدلال ذات الإجابات القصيرة، يُطلب من النموذج إخراج قيمة عددية واحدة أو تعبير جبري أو مصطلح بيولوجي يمكن مطابقته بشكل تقريبي، وذلك لضمان إمكانية التحقق من النتائج واستقرار التقييم التلقائي.
قاعدة بيانات البحث
صُممت هذه الأسئلة من قِبل طلاب الدكتوراه وزملاء ما بعد الدكتوراه والأساتذة، وهي تحاكي المشكلات الفرعية التي قد تُصادف في البحث العلمي الحقيقي، وتغطي المجالات الرئيسية الثلاثة: الفيزياء والكيمياء والأحياء. ويُرفق بكل سؤال نظام تقييم دقيق من 10 نقاط لتقييم أداء النموذج في عدة جوانب رئيسية، تتجاوز مجرد صحة الإجابة، بما في ذلك استكمال افتراضات النمذجة، ومسارات الاستدلال، والاستنتاجات الوسيطة.
مجموعة بيانات الإجابة على الأسئلة HotpotQA
* استخدم عبر الإنترنت:
مجموعة بيانات HotpotQA هي مجموعة بيانات ضخمة للأسئلة والأجوبة جُمعت من ويكيبيديا الإنجليزية، وتحتوي على 113,000 سؤال من مصادر متعددة. للإجابة على هذه الأسئلة، عليك الرجوع إلى الفقرات التمهيدية لمقالين من ويكيبيديا.
يحتوي كل سؤال على فقرتين ذهبيتين وقائمة بجمل من بعض الفقرات، والتي تقدم حقائق داعمة تُعتبر ضرورية للإجابة على السؤال. تتميز هذه المجموعة من البيانات بالخصائص التالية:
يتطلب السؤال البحث والتحليل المنطقي من خلال العديد من الوثائق الداعمة للإجابة عليه؛
* المشاكل متنوعة ولا تقتصر على أي قاعدة معرفية أو نموذج معرفي موجود مسبقًا؛
توفر مجموعة البيانات هذه حقائق داعمة على مستوى الجملة ضرورية للاستدلال، مما يُمكّن أنظمة ضمان الجودة من الاستدلال وتفسير التنبؤات تحت إشراف قوي؛
تقدم مجموعة البيانات هذه مشكلة جديدة لمقارنة الحقائق لاختبار قدرة نظام الإجابة على الأسئلة على استخراج الحقائق ذات الصلة وإجراء المقارنات اللازمة.
مجموعة بيانات الاستدلال الحسي البصري لأجهزة تسجيل الفيديو
* استخدم عبر الإنترنت:
VCR تعني Visual Commonsense Reasoning، وهي مجموعة بيانات واسعة النطاق للتفكير السليم البصري. تطرح مجموعة البيانات أسئلة صعبة حول الصور، وتحتاج الآلة إلى إكمال مهمتين فرعيتين: الإجابة على السؤال بشكل صحيح وتقديم أسباب لتبرير إجابتها.
تحتوي مجموعة بيانات VCR على عدد كبير من الأسئلة، منها 212 ألف سؤال تُستخدم للتدريب، و26 ألف سؤال للتحقق، و25 ألف سؤال للاختبار. الإجابات والأسباب تأتي من أكثر من 110 ألف مشهد سينمائي فريد.

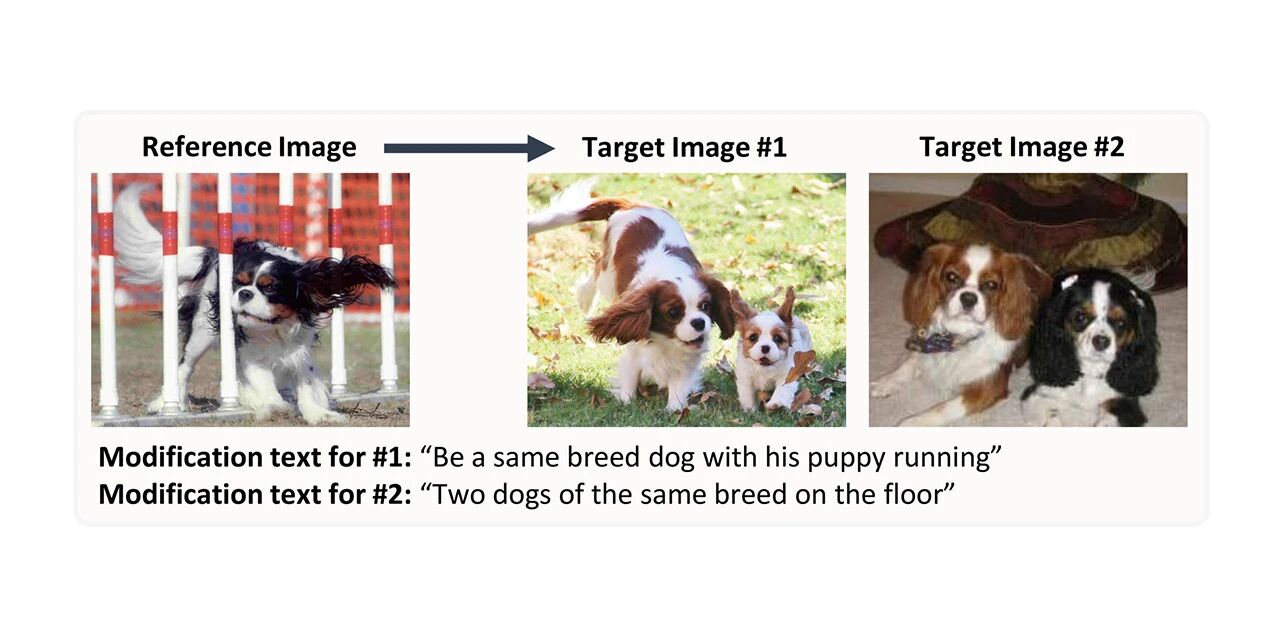
مجموعة بيانات استرجاع الصور المركبة من CIRR
* استخدم عبر الإنترنت:
CIRR يرمز إلى Compose Image Retrieval on Real-life images (استعادة الصور من الحياة الواقعية) ويحتوي على أكثر من 36000 زوج من الصور المفتوحة المصدر والنصوص المعدلة التي تم إنشاؤها يدويًا. تهدف مجموعة البيانات هذه إلى تسهيل الأبحاث المستقبلية حول التفكير الدقيق حول المفاهيم اللغوية البصرية والاسترجاع التكراري باستخدام الحوارات، ومعالجة أوجه القصور في مجموعات البيانات الحالية من خلال التركيز بشكل أكبر على التمييز بين الصور المتشابهة بصريًا في المجال المفتوح.