Command Palette
Search for a command to run...
ازداد نشاط متغيرات البروتين المُصممة ٥٠ ضعفًا! اقترح فريق تشو هاو من جامعة تسينغهوا AIR نظام AMix-1 القائم على شبكات التدفق البايزية لتحقيق تصميم بروتيني شامل وقابل للتطوير.

حاليًا، لا تزال الأبحاث في مجال نماذج قاعدة البروتين عالقة في عصر "BERT"، الذي لا يتكيف تمامًا مع الخصائص البيولوجية لتسلسلات البروتين. في السابق، طوّرت نماذج الذكاء الاصطناعي، مثل AlphaFold وESM، تطوراتٍ ملحوظة في مجالات متعددة، بما في ذلك التنبؤ بالبنية، والطي العكسي، والتنبؤ بالخصائص الوظيفية، وتقييم تأثير الطفرات، وتصميم البروتينات.ومع ذلك، لا تزال هذه النماذج تفتقر إلى منهجيات قابلة للتطوير ومنهجية مماثلة لتلك الموجودة في نماذج اللغة الكبيرة المتطورة (LLMs)، ولا يمكن تحسين قدراتها بشكل مستمر مع زيادة حجم البيانات ومقياس النموذج وموارد الحوسبة.
وقد أدى الافتقار إلى عالمية مثل هذه النماذج إلى تحديات يصعب حلها في مجال تصميم البروتين: حيث لا تستطيع النماذج التقاط التباين التكويني للبروتينات، ولا يمكن للتنبؤات المتعلقة بتصميم البروتين أن تتجاوز نطاق بيانات التدريب؛ كما أدى الاعتماد المفرط على نقل منهجيات معالجة اللغة الطبيعية إلى عدم وجود تصميمات معمارية أصلية تستهدف خصائص البروتين.
في هذا السياق، اقترحت مجموعة أبحاث تشو هاو في معهد الصناعات الذكية (AIR) بجامعة تسينغهوا، بالتعاون مع مختبر الذكاء الاصطناعي في شنغهاي، نموذجًا أساسيًا للبروتين AMix-1 مدربًا بشكل منهجي يعتمد على شبكة تدفق بايزية، مما يوفر مسارًا عامًا وقابلًا للتطوير لتصميم البروتين.اعتمد هذا النموذج المنهجية المنظمة "قانون التوسع قبل التدريب" و"القدرة الناشئة" و"التعلم في السياق" و"التوسع في وقت الاختبار" لأول مرة، وصمم استراتيجية تعلم سياقية تعتمد على محاذاة التسلسلات المتعددة (MSA) على هذا الأساس، محققًا الاتساق في الإطار العام لتصميم البروتين مع ضمان قابلية التوسع للنموذج.
وقد تم نشر نتائج البحث ذات الصلة على منصة arXiv تحت عنوان "AMix-1: مسار إلى نموذج أساس البروتين القابل للتطوير في وقت الاختبار".
أبرز الأبحاث:
* تم إنشاء قانون قياس يمكن التنبؤ به لنموذج توليد البروتين استنادًا إلى شبكة التدفق البايزية؛
* يطور نموذج AMix-1 تلقائيًا "فهمًا إدراكيًا" لبنية البروتين من خلال أهداف التدريب على مستوى التسلسل وحدها، دون الحاجة إلى إشراف هيكلي صريح.
* يعمل إطار التعلم السياقي القائم على محاذاة التسلسلات المتعددة (MSA) على حل مشكلة المحاذاة في التحسين الوظيفي، ويرفع من قدرات التفكير والتصميم في النموذج في سياق تطوري، ويمكّن AMix-1 من توليد بروتينات جديدة ذات بنية ووظيفة محفوظة؛
* اقتراح خوارزمية لتمديد وقت الاختبار موجهة بتكلفة التحقق لتمكين نهج تصميم جديد قائم على التطور عندما تزيد ميزانيات التحقق.
عنوان الورقة:
قم بمتابعة الحساب الرسمي ورد "AMix" للحصول على ملف PDF كامل
مزيد من أوراق البحث الرائدة في مجال الذكاء الاصطناعي:
مجموعة بيانات UniRef50: المعالجة المسبقة والتجميع التكراري
استخدم الباحثون مجموعة بيانات UniRef50 المُعالجة مسبقًا أثناء التدريب المسبق للنموذج. هذه المجموعة، المُقدمة من EvoDiff، مُشتقة من UniProtKB ومُرشحة من تسلسلات UniParc عبر التجميع التكراري (UniProtKB+UniParc → UniRef100 → UniRef90 → UniRef50).يحتوي على 41,546,293 تسلسل تدريب و82,929 تسلسل تحقق. تم تقليص التسلسلات التي يزيد طولها عن 1,024 بقايا إلى 1,024 بقايا باستخدام استراتيجية التقليم العشوائي لتقليل التكلفة الحسابية وتوليد تسلسلات فرعية متنوعة. تضمن هذه العملية التكرارية تمثيلًا عالي الجودة، غير مكرر، ومتنوعًا لتسلسلات UniRef50، مما يوفر تغطية شاملة لمساحة تسلسل البروتين لنماذج لغة البروتين.
تنزيل مجموعة بيانات UniRef50:
الحلول التقنية المنهجية
يوفر AMix-1 مجموعة كاملة من الحلول التقنية المنهجية لتنفيذ قياس وقت الاختبار لنماذج قاعدة البروتين:
* قانون التوسع قبل التدريب:ومن الواضح كيفية تحقيق التوازن بين المعلمات وعدد العينات والجهد الحسابي لتحقيق أقصى قدر من قدرات النموذج؛
* القدرة الناشئة:ويُظهِر هذا أنه مع تقدم التدريب، سيظهر النموذج "بفهم إدراكي" لبنية البروتين؛
* التعلم في السياق:إنه يحل مشكلة المحاذاة في التحسين الوظيفي، مما يسمح للنموذج بتعلم التفكير والتصميم في سياق تطوري؛
* قياس وقت الاختبار:يفتح AMix-1 نهجًا جديدًا للتصميم المبني على التطور مع زيادة ميزانيات التحقق.
من التدريب والاستدلال إلى التصميم، أثبت AMix-1 تنوعه وقابليته للتوسع كنموذج أساسي للبروتين، مما يمهد الطريق للتنفيذ العملي.
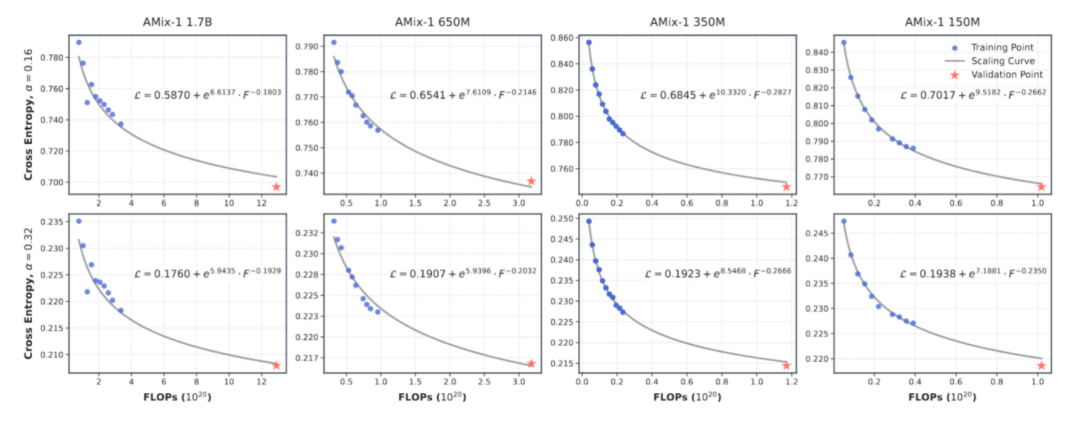
قانون التوسع قبل التدريب: قدرات نموذج البروتين القابلة للتنبؤ
لتحقيق قانون مقياس يمكن التنبؤ به لـ AMix-1، صممت هذه الدراسة مزيجًا من النماذج متعددة المقاييس مع معلمات تتراوح من 8 ملايين إلى 1.7 مليار في التجربة، واستخدمت عمليات التدريب ذات الفاصلة العائمة (FLOPs) كمؤشر قياس موحد لتناسب بدقة والتنبؤ بعلاقة قانون الطاقة بين فقدان الإنتروبيا المتقاطعة للنموذج وكمية الحساب.
وبناءً على النتائج، فإن منحنى قانون القوة بين خسارة النموذج والجهد الحسابي متسق للغاية، مما يؤكد أن عملية تدريب النموذج القائمة على شبكة التدفق البايزية يمكن التنبؤ بها بدرجة كبيرة.
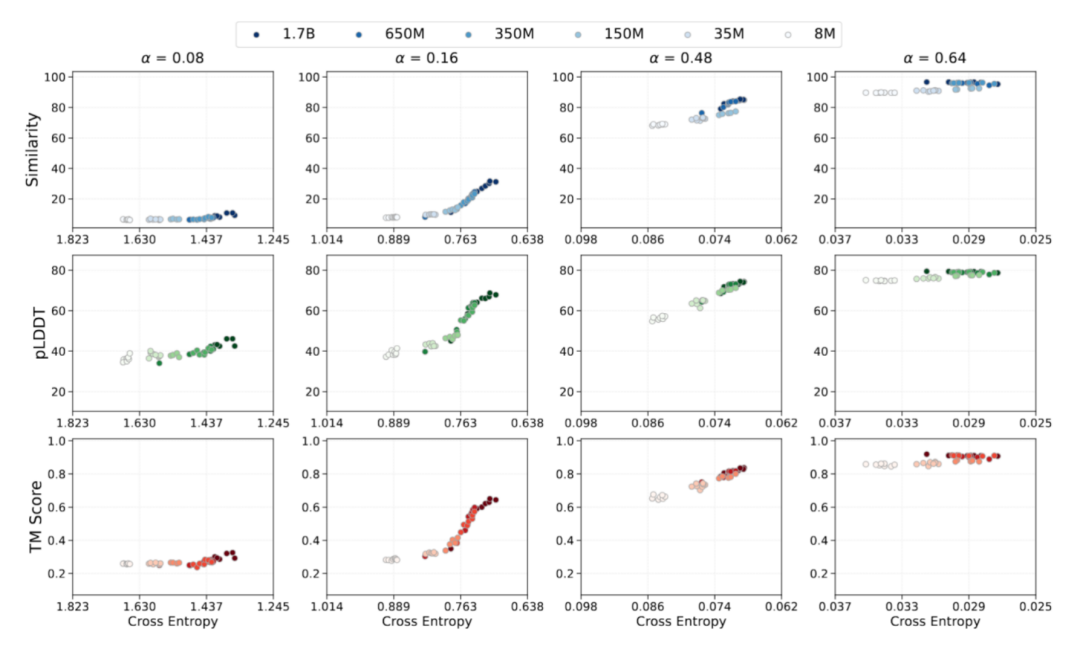
القدرة الناشئة: تحقيق قدرات النموذج المتقدمة
في تعلم تسلسلات البروتينات، تعتمد دراسة النشوء الهيكلي عادةً على نموذج "التسلسل - البنية - الوظيفة". للتحقق من صحة العلاقة بين ديناميكيات التحسين والنتائج الوظيفية في نمذجة البروتينات، حلل فريق البحث السلوك الناشئ من منظور يركز على الخسارة استنادًا إلى قانون قياس قابل للتنبؤ. باستخدام فقدان الإنتروبيا المتقاطعة التنبؤي كمرساة، قاموا تجريبيًا بربط خسارة التدريب بأداء توليد البروتين. ركز تقييم هذه الدراسة لقدرة النموذج على النشوء على ثلاثة جوانب:
* قدرة النموذج على استعادة مستويات التسلسل من توزيعات التسلسل الفاسدة بناءً على ملاحظات اتساق التسلسل؛
* انتقال النماذج من فهم التسلسل إلى الجدوى البنيوية من منظور قابلية الطي؛
* يتم استخدام الاتساق البنيوي لتحديد قدرة النموذج على الحفاظ على الخصائص البنيوية.
تُظهر البيانات ذات الصلة أثناء تدريب AMix-1 بشكل كامل عملية ظهور قدرات "اتساق التسلسل، وقابلية الطي، والاتساق البنيوي" في نموذج القاعدة البروتينية.تظهر البيانات أن جميع مؤشرات قدرة النموذج أثناء التدريب مرتبطة ارتباطًا وثيقًا بفقدان الإنتروبيا المتقاطعة، مما يؤكد إمكانية التنبؤ بقدرة النموذج من خلال قانون التوسع وفقدان الإنتروبيا المتقاطعة.في الوقت نفسه، عندما يتم تدريبه فقط باستخدام أهداف ذاتية الإشراف على مستوى التسلسل وبدون إدخال أي معلومات هيكلية، لا يزال النموذج يُظهر قدرة الطوارئ بعد انخفاض خسارة الإنتروبيا المتقاطعة إلى حد معين، مما يُظهر انتقالًا غير خطي بين pLDDT ونتيجة TM.
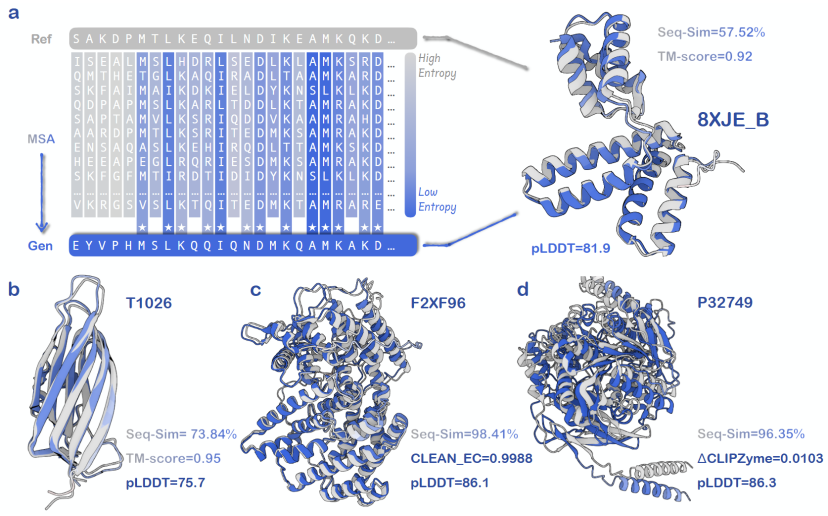
التعلم في السياق: نموذج عام لتصميم البروتين
من خلال حالات المحاكاة الحاسوبية، تحقق الباحثون من آلية التعلم السياقي لـ AMix-1. أظهرت تجارب حالات المحاكاة أنيتمكن AMix-1 من استخراج وتعميم القيود الهيكلية أو الوظيفية بدقة من عينات الإدخال دون الاعتماد على تسميات صريحة أو إشراف هيكلي.
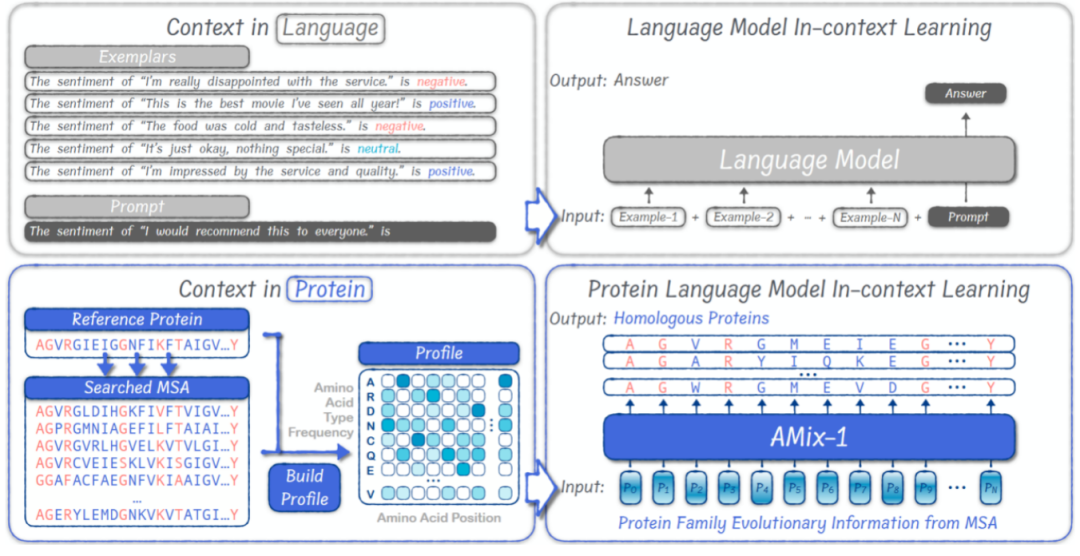
مقارنةً بتصميم البروتينات التقليدي، الذي يتطلب عمليات مُخصصة بناءً على أنواع المهام ويفتقر إلى إطار عمل موحد لتصميم البروتينات، يُقدم AMix-1 آلية تعلم سياقي (ICL) ضمن نموذج لغوي كبير لإنجاز تصميم بروتين مُوجه بالبنية والوظيفة. وقد أظهرت التجارب أنه في المهام الهيكلية، يُمكن لـ AMix-1 توليد بروتينات جديدة ذات هياكل مُتوقعة متسقة للغاية باستخدام بروتينات متماثلة تقليدية، أو حتى بروتينات خالية تقريبًا من التماثل، كمؤشرات. أما في المهام الوظيفية، فيُمكن لـ AMix-1 توليد بروتيازات متسقة للغاية بناءً على الوظيفة الأنزيمية وتصميم الإنزيم المُوجه بالتفاعل الكيميائي للبروتين المُدخل.
وبموجب هذه الآلية العامة،يمكن للنموذج استنتاج المعلومات والقواعد المشتركة تلقائيًا في مجموعة معينة من البروتينات، واستخدام هذه القواعد لتوجيه توليد بروتينات جديدة تتوافق مع القواعد المشتركة.تضغط هذه الآلية مجموعة من بروتينات MSAs في مُدخل توزيع احتمالي على مستوى الموضع (Profile) في النموذج. بعد تحليل سريع لبنية البروتينات المُدخلة وقواعدها الوظيفية، يُمكن للنموذج توليد بروتينات جديدة تُلبي الغرض.
التوسع في وقت الاختبار: الذكاء العام القابل للتطوير
استنادًا إلى نهج التوسع الزمني للاختبار، استخدم الباحثون إطار عمل المُقترِح-المُتحقق لبناء EvoAMix-1. ومن خلال زيادة ميزانية التحقق باستمرار، حسّنوا أداء نموذج AMix-1. وفي الوقت نفسه، عزز الفريق كفاءة تصميم النموذج، وحقق قابلية التوسع. علاوة على ذلك، لضمان التوافق، ألغى الفريق المتطلبات المحددة مسبقًا لخصائص المُتحقق.
يُعزز EvoAMix-1 الاستكشاف القائم على العشوائية المتأصلة في النماذج الاحتمالية. من خلال دمج وظائف مكافأة المحاكاة الحاسوبية الخاصة بكل مهمة أو التغذية الراجعة للكشف التجريبي، يُولّد ويفحص بشكل متكرر تسلسلات بروتينية مرشحة في ظل قيود تطورية. ويمكنه تحقيق تطور بروتيني موجه بكفاءة دون الحاجة إلى ضبط دقيق للنموذج، مما يُحقق أداءً قويًا وقابلًا للتطوير في تصميم البروتينات مع مرور الوقت.في جميع مهام التصميم الست، يتفوق EvoAMix-1 باستمرار على AMix-1 في التعلم في السياق ومختلف أساليب الأساس القوية.
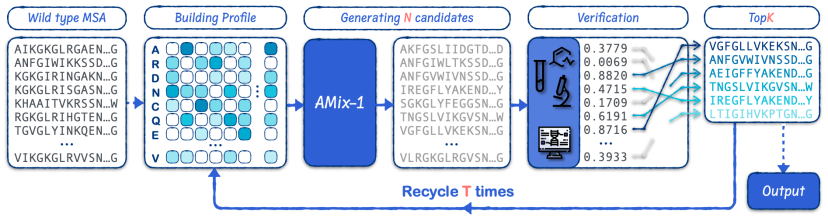
بالمقارنة مع الطريقة التقليدية لتوليد متغيرات بروتينية جديدة من خلال أخذ العينات ذات الأهمية،لا يقوم EvoAMix-1 بتحديث معلمات النموذج، بل يقوم بدلاً من ذلك ببناء توزيع الاقتراح من خلال الأمثلة السياقية.في كل جولة، يأخذ AMix-1 كإشارات مجموعة من محاذاة التسلسل المتعددة (MSAs) أو أطيافها، والتي تعتبر بمثابة شروط إدخال لنموذج قاعدة البروتين، والذي يقوم بعد ذلك بأخذ عينات من التسلسلات المجاورة، مما يؤدي إلى تحديد توزيع اقتراح مشروط جديد بشكل فعال.
أثبت فريق البحث بشكل منهجي تعدد استخدامات EvoAMix-1 وقابليته للتوسع عبر عدة مهام تمثيلية للتطور الموجه للبروتين، بما في ذلك التطور الأمثل لدرجة الحموضة ودرجة الحرارة للإنزيمات، والحفاظ على الوظيفة وتحسينها، وتصميم البروتينات اليتيمة، والتحسين العام الموجه بالبنية. تُظهر النتائج التجريبية قابلية التوسع القوية لتوسع EvoAMix-1 في وقت الاختبار، مما يُظهر تنوعًا كبيرًا في مختلف المهام والأهداف.
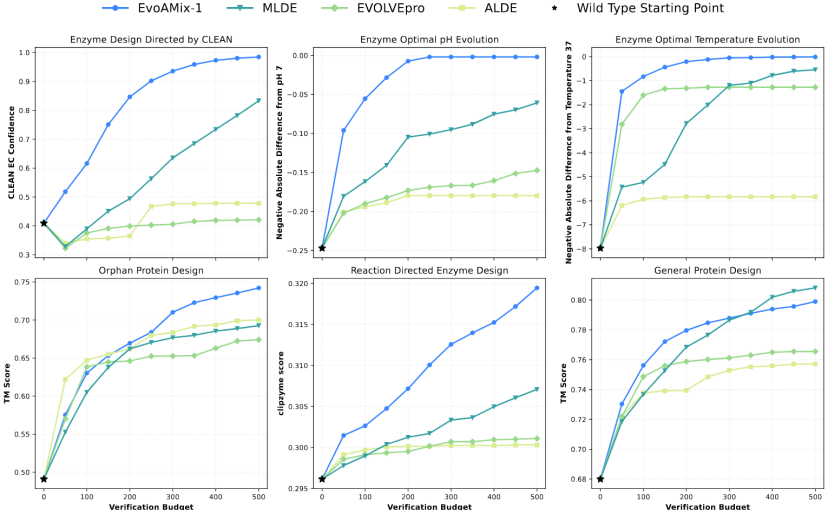
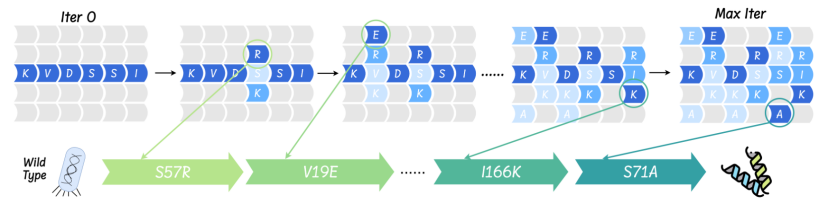
التحقق من التجربة الرطبة: يساعد AMix-1 في تطوير متغيرات البروتين AmeR مع زيادة في النشاط بمقدار 50 ضعفًا
اختبرت الدراسة استراتيجية "التصميم المُستلهم من السياق" في تجارب رطبة فعلية، مما زاد من صحة مزايا AMix-1 في تصميم متغيرات AmeR عالية النشاط بكفاءة. اختار الباحثون البروتين المستهدف AmeR واستخدموا نموذج AMix لتوليد 40 متغيرًا بناءً على توزيع احتمالات عائلة AmeR. قُيِّمت القدرة التثبيطية لكل متغير من خلال تجارب جينات المراسل الفلورية. احتوى كل متغير على ≤10 طفرات في الأحماض الأمينية فقط، وكلما ارتفعت قيمة تثبيط الطيات، زادت قوة الوظيفة. بالإضافة إلى ذلك، اقترحت الدراسة أيضًا خوارزمية توسع للاختبار التطوري لتعزيز قابلية تطبيق AMix-1 في التطور الموجه للبروتين، وتحققت من أدائه من خلال مجموعة متنوعة من مؤشرات منطقة الهدف بالمحاكاة الحاسوبية.
وتظهر النتائج النهائية أنيتمتع المتغير الأمثل الذي تم إنشاؤه بواسطة AMix-1 بتحسن في النشاط يصل إلى 50 مرة، وتم تحسين أدائه بنحو 77% مقارنة بنموذج SOTA الحالي.بالإضافة إلى ذلك، لا يعتمد AMix-1 على الفحص المتكرر أو التصميم اليدوي، بل يتم إنشاؤه تلقائيًا بالكامل بواسطة النموذج.وقد نجح في تحقيق حلقة مغلقة كاملة من "النموذج إلى التجربة" وحقق أول اختراق على الإطلاق في استخدام الذكاء الاصطناعي لتصميم البروتين الوظيفي.
الطوبولوجيا العالمية والإدراك يفتحان بعدًا جديدًا في تصميم البروتين
يشهد حاليًا بحث دمج الذكاء الاصطناعي وتصميم البروتينات ازدهارًا كبيرًا. فبالإضافة إلى AMix-1، حقق نموذج الانتشار المراعي للهندسة TopoDiff، الذي اقترحه فريق غونغ هايبينغ في كلية علوم الحياة بجامعة تسينغهوا وفريق شو تشونفو في معهد بكين لعلوم الحياة، إنجازاتٍ بارزة في تصميم البروتينات.
لا تعاني نماذج الانتشار التقليدية، مثل نموذج RFDiffusion، من تحيز التغطية عند توليد أنواع طيات محددة مثل الغلوبولينات المناعية فحسب، بل تفتقر أيضًا إلى مقاييس تقييم كمية لطوبولوجيا البروتين الشاملة. اقترحت هذه الدراسة، المستندة إلى قواعد بيانات هيكلية مثل CATH وSCOPe، نظامًا غير خاضع للإشراف، وهو إطار عمل TopoDiff. من خلال تعلم والاستفادة من التمثيلات الكامنة الواعية هندسيًا الشاملة، يحقق النظام توليد بروتين غير مشروط وقابل للتحكم بناءً على نماذج الانتشار. تقترح هذه الدراسة مقياس تقييم جديدًا، وهو "التغطية"، والذي يفصل، من خلال إطار عمل نموذجي ثنائي المرحلة يعتمد على التشفير والانتشار، بنية البروتين إلى مخطط هندسي شامل وتوليد إحداثيات ذرية محلية، متغلبًا بذلك على تحديات البحث في تغطية طيات البروتين.
علاوة على ذلك، تغلبت شركة NVIDIA، بالتعاون مع معهد ميلا للذكاء الاصطناعي في كيبيك بكندا، على تحدي التنبؤ بالسلاسل الطويلة باستخدام نموذج مُحسّن لتوليد الذرات بالكامل، قائم على بنية AlphaFold. لا تقتصر صعوبة الطرق التقليدية على توليد هياكل ذرية كاملة لسلاسل طويلة جدًا (أكثر من 500 بقايا)، بل تفشل أيضًا في استكشاف أشكال الطي غير التقليدية، مثل الجيوب الخاصة ببروتينات الغشاء. وقد قدّم فريق البحث آلية اتخاذ قرار احتمالية، مستبدلًا مسارات الطي الحتمية بأخذ عينات تكاملية المسار من نظرية المجال الكمومي، مما زاد من معدل نجاح تصميم بروتين الغشاء إلى 68%.
من الاستشعار الهندسي لطي البروتينات، إلى تصميم سلاسل طويلة تضم أكثر من 500 بقايا، إلى تصميم البروتينات المعتمدة على اللغة الطبيعية، وصولًا إلى استهداف البروتينات المُهجّنة داخليًا "غير القابلة للعلاج"، يُوسّع الذكاء الاصطناعي آفاق قدرات تصميم البروتينات، ويُقدّم نموذجًا جديدًا للبحث في هذا المجال. في المستقبل، من المتوقع أن يفتح تصميم البروتينات المعتمد على الذكاء الاصطناعي آفاقًا أوسع لتطوير علاجات وإنزيمات ومواد حيوية مُبتكرة.
روابط مرجعية:








