Command Palette
Search for a command to run...
فقط! مؤتمر ACL 2024 يعلن عن أفضل 7 أوراق بحثية، والمؤلف الأول من طلاب البكالوريوس في جامعة هيوستن يفوز بالجائزة

في الحادي عشر من أغسطس، افتتح رسميا الاجتماع السنوي الشهير عالميا لجمعية اللغويات الحاسوبية (ACL) في بانكوك، تايلاند. من المقرر أن يستمر مؤتمر ACL 2024 لمدة 6 أيام وسيتضمن 34 ورشة عمل بالإضافة إلى المؤتمر الرئيسي.
منذ عام 2022، اعتمدت ACL آلية المراجعة المتجددة (ACL Rolling Review، ARR)، حيث حددت موعدًا نهائيًا كل شهر. وفي يناير/كانون الثاني من هذا العام، أعلنت السلطات أيضًا عن خبر جيد - تم إلغاء فترة عدم الكشف عن هوية مقدمي الأوراق البحثية، وتم السماح للمؤلفين بنشر أعمالهم خلال فترة التقديم. وسيدخل هذا التنظيم حيز التنفيذ أيضًا بشكل مباشر في دورة المراجعة التالية بعد النشر.
وفقا للبيانات الرسمية،معدل قبول المؤتمر الرئيسي لهذا العام هو 21.3%، ومعدل قبول النتائج هو 22.1%.

ومن الجدير بالذكر أن مؤتمر ACL 2024 قد أضاف أيضًا موضوعًا خاصًا "العلم المفتوح والبيانات المفتوحة والنماذج المفتوحة لأبحاث معالجة اللغة الطبيعية القابلة للتكرار"، والذي يقبل مجموعات البيانات مفتوحة المصدر عالية الجودة ونماذج مفتوحة المصدر وبرامج مفتوحة المصدر وغيرها من نتائج الأبحاث ذات الصلة، بهدف تحفيز المناقشات في الصناعة حول العلم المفتوح وأبحاث معالجة اللغة الطبيعية القابلة للتكرار، ودعم تطوير برامج مفتوحة المصدر.

في 14 أغسطس، تم الإعلان عن سلسلة من الجوائز لـ ACL 2024. حصل هذا الموضوع على 22 ورقة بحثية رئيسية، والفائز بجائزة الورقة البحثية كان "OLMo: تسريع علم نماذج اللغة".
عنوان الورقة:https://arxiv.org/pdf/2402.00838

تم منح جائزة اختبار الزمن لكتاب "GloVe: Global Vectors for Word RepresentationGloVe" الذي نُشر في عام 2014.
عنوان الورقة:https://aclanthology.org/D14-1162.pdf

بالإضافة إلى ذلك، اختارت ACL 2024 أيضًا أفضل 7 أوراق بحثية. فازت ورقة بحثية بعنوان "فك شفرة لغة عظام أوراكل باستخدام نماذج الانتشار" والتي نشرت بشكل مشترك من قبل جامعة هواتشونغ للعلوم والتكنولوجيا، وجامعة أديلايد، وجامعة أنيانغ العادية، وجامعة جنوب الصين للتكنولوجيا، بجائزة أفضل ورقة بحثية. المؤلف الأول هو جوان هايسو، وهو طالب جامعي في عام 2021 من فريق البروفيسور باي شيانغ، عميد كلية البرمجيات في جامعة هواتشونغ للعلوم والتكنولوجيا. سوف يقدم لك HyperAI شرحًا مفصلاً في هذه المقالة.
قم بمتابعة الحساب الرسمي ورد "ACL 2024" لتحميل جميع الأوراق الفائزة.
أما الأوراق الستة الفائزة المتبقية فهي:
التقدير السببي لملفات الحفظ

* عنوان الورقة:https://arxiv.org/abs/2406.04327* مؤسسات البحث: جامعة كامبريدج، المعهد الفيدرالي السويسري للتكنولوجيا في زيورخ* محتوى البحث: اقترح الباحثون طريقة جديدة ومبدئية وفعالة لتقدير الذاكرة والتي تحتاج فقط إلى ملاحظة عدد صغير من سلوكيات المثيلات للنموذج أثناء عملية التدريب بأكملها لتوصيف خصائص ذاكرة النموذج - أي اتجاهات ذاكرته أثناء عملية التدريب.
نموذج آية: وضع لغة متعدد اللغات مفتوح المصدر مع ضبط دقيق للتعليمات

* عنوان الورقة:
https://arxiv.org/abs/2402.07827
* مؤسسات البحث: Cohere For AI، جامعة براون، Cohere، مجتمع Cohere For AI، معهد ماساتشوستس للتكنولوجيا، جامعة كارنيجي ميلون
* محتوى البحث: قدم الباحثون نموذج Aya، وهو نموذج لغوي توليدي متعدد اللغات على نطاق واسع، ويتبع التعليمات في 101 لغة، مما أدى إلى مضاعفة عدد اللغات المغطاة. بالإضافة إلى ذلك، قدم الباحثون مجموعة تقييم جديدة شاملة تعمل على توسيع تكنولوجيا التقييم متعدد اللغات إلى 99 لغة.
قابلية إرضاء اللغة الطبيعية: استكشاف توزيع المشكلات وتقييم نماذج اللغة القائمة على المحولات
*لا توجد نسخة مطبوعة من الورقة حتى الآن*

* عنوان الورقة:https://arxiv.org/abs/2406.05930* مؤسسة البحث: جامعة كارنيجي ميلون، جامعة جنوب كاليفورنيا* محتوى البحث: اقترح الباحثون مهمة إعادة بناء تاريخية شبه خاضعة للإشراف، حيث يتم تدريب النموذج فقط على كمية صغيرة من البيانات المصنفة وكمية كبيرة من البيانات غير المصنفة. لقد قمنا أيضًا بتطوير بنية عصبية لإعادة بناء المقارنة، DPDBiReconstructor، والتي تجمع بين الأفكار الأساسية من أساليب المقارنة الخاصة باللغويين وتتمكن من الاستفادة من مجموعات غير مصنفة من الكلمات المتشابهة، متفوقة على خطوط الأساس القوية شبه الخاضعة للإشراف في المهام الجديدة.
المهمة: نماذج اللغة المستحيلة
* عنوان الورقة:https://arxiv.org/abs/2401.06416* مؤسسات البحث: جامعة ستانفورد، جامعة كاليفورنيا، جامعة تكساس
* محتوى البحث: قام الباحثون بتجميع سلسلة من اللغات المعقدة وغير الموجودة وتقييم قدرة نموذج GPT-2 على تعلم هذه اللغات. وأظهرت النتائج أن GPT-2 واجه صعوبة في تعلم اللغات المستحيلة مقارنة بتعلم اللغة الإنجليزية.
لماذا تعد الوظائف الحساسة صعبة على المحولات؟

* عنوان الورقة:
https://arxiv.org/abs/2402.09963
* المؤسسة البحثية: جامعة سارلاند، ألمانيا
* محتوى البحث: في بنية المحول، يتم تقييد مشهد الخسارة من خلال الحساسية لمساحة الإدخال. من خلال العمل النظري والتجريبي، يمكن لهذه النظرية توحيد مجموعة واسعة من الملاحظات التجريبية حول قدرة التعلم والتحيز لدى المحولات.
تحليل متعمق للأوراق البحثية الحائزة على جوائز
التالي،سيقدم HyperAI أربعة جوانب: بنية النموذج، ومجموعة البيانات، ونتائج البحث، والفريق.تفسير متعمق لـ "فك شفرة لغة عظام أوراكل باستخدام نماذج الانتشار" للجميع.
في هذه الدراسة، استخدم فريق البحث المكون من باي شيانغ وليو يوليانغ من جامعة هواتشونغ للعلوم والتكنولوجيا، بالتعاون مع جامعة أديلايد وجامعة أنيانغ العادية وجامعة جنوب الصين للتكنولوجيا، نموذجًا توليديًا قائمًا على الصور لـتم تدريب نموذج الانتشار الشرطي Oracle Bone Script Decipher (OBSD) المحسن لفك تشفير Oracle Bone Script.يستخدم النموذج فئات غير مرئية من نقوش عظام العرافة كمدخلات مشروطة لتوليد صور أحرف صينية حديثة مقابلة، مما يوفر نهجًا جديدًا لمهمة التعرف على الأحرف القديمة التي يصعب حلها في معالجة اللغة الطبيعية.
أبرز الأبحاث:
* توفير نهج جديد لمهام التعرف على الأحرف الصينية القديمة باستخدام تقنية توليد الصور
* يستخدم OBSD تقنية أخذ العينات التحليلية المحلية لتعزيز قدرة النموذج على التمييز بين أنماط الأحرف المعقدة وتفسيرها
* إثبات فعالية OSBD في فك التشفير من خلال دراسات الاستئصال الشاملة واختبارات المعايير
رابط تحميل مجموعة البيانات المستخدمة في هذه الدراسة:
* مجموعة بيانات تطور نص Oracle-Bone EVOBC:
* مجموعة بيانات التعرف على العظام HUST-OBS Oracle:
مجموعة البيانات: استخدام أكبر مستودع لشركة Oracle، واستخدام تقنية التعرف الضوئي على الحروف كمعيار
لتدريب وتقييم نموذج OSBD المقترح،اختارت هذه الدراسة مجموعة بيانات HUST-OBS ومجموعة بيانات EVOBC.وهي واحدة من أكبر مستودعات نقوش العظام، حيث تحتوي على 1590 حرفًا مختلفًا مصورة في 71698 صورة.
وبما أن فك رموز عظام الوحي المجهولة يتطلب عادة التحقق المهني الأكثر شمولاً، فقد استخدمت هذه الدراسة النصوص المفكوكة فقط كمجموعة اختبار، وبالتالي تبسيط عملية التقييم بأكملها. والأمر الأكثر أهمية هو أن الدراسة استبعدت أيضًا على وجه التحديد فئات الأحرف المحددة في مجموعة الاختبار من مجموعة التدريب للتأكد من استخدام النموذج لكسر الأحرف التي لم تتم معالجتها مطلقًا. يتم تقسيم مجموعة البيانات إلى مجموعات تدريب واختبار بنسبة 9:1، مما يوفر إطارًا موثوقًا به للتقييم.
بالإضافة إلى ذلك، على الرغم من أن نموذج OSBD يقوم بفك تشفير أوراكل من منظور إنشاء الصورة، فإن مقاييس إنشاء الصورة التقليدية مثل SSIM ليست مناسبة لهذه المهمة. لذلك، اعتمدت هذه الدراسة تقنية التعرف الضوئي على الحروف كمقياس أكثر موضوعية لتحديد نتائج فك التشفير الناجحة. على وجه التحديد، قام الباحثون بتخصيص أداة OBS-OCR باستخدام مصنف بسيط مع شبكة أساسية ResNet-101، تم تدريبها خصيصًا على مجموعة بيانات كبيرة تحتوي على 88899 فئة من الأحرف الصينية الحديثة لتقييم مخرجات النموذج.
وتظهر النتائج أن حققت أداة التعرف الضوئي على الحروف المخصصة دقة التعرف البالغة 99.87%.لقد تم إثبات موثوقية نتائج فك التشفير. وفي الوقت نفسه، قدمت هذه الدراسة أيضًا على نطاق واسع أداة التعرف الضوئي على الحروف الصينية مفتوحة المصدر PaddleOCR 1 لمزيد من التقييم. توفر طريقة التعرف الضوئي على الحروف المزدوجة هذه ضمانة قوية لفعالية النموذج في فك رموز عظام الوحي.
إعادة بناء نموذج OBSD استنادًا إلى نموذج الانتشار الشرطي
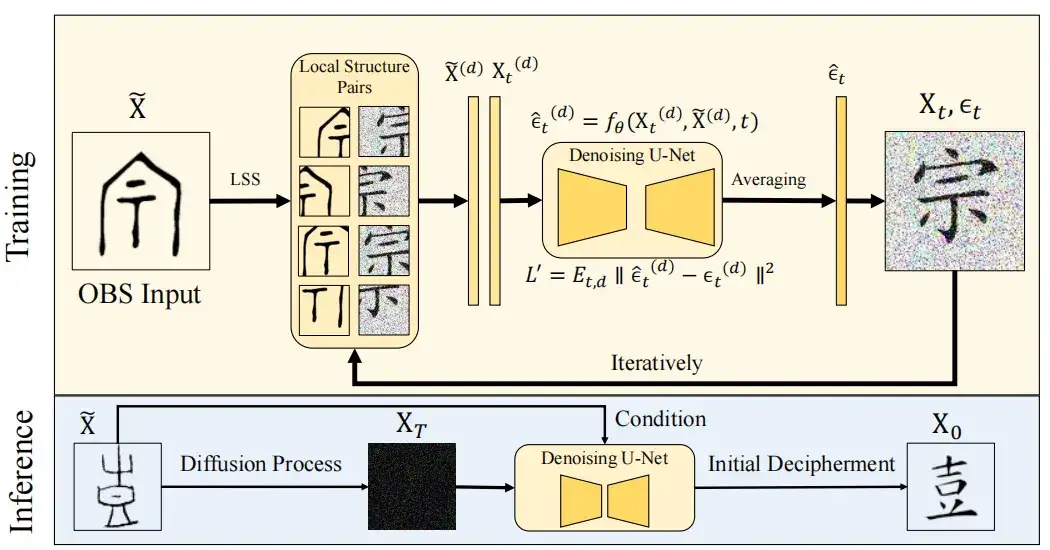
تمثل هذه الدراسة مجموعة التدريب على النحو التالي: S = {(si, ci) | si هي حالة أوراكل، ci∈C}، أي مطابقة حالات أوراكل مع مجموعة من الأحرف الصينية الحديثة في فئة معروفة C واقتراح أشكال أحرف جديدة حيث تكون المطابقات الموجودة مفقودة. ولتحقيق ذلك،تقوم هذه الدراسة بتحويل صورة حرف عظمة العرافة X إلى نظيرتها الصينية الحديثة بناءً على نموذج الانتشار.
كما هو موضح في الشكل أدناه، يتم تقسيم النموذج إلى مرحلتين:
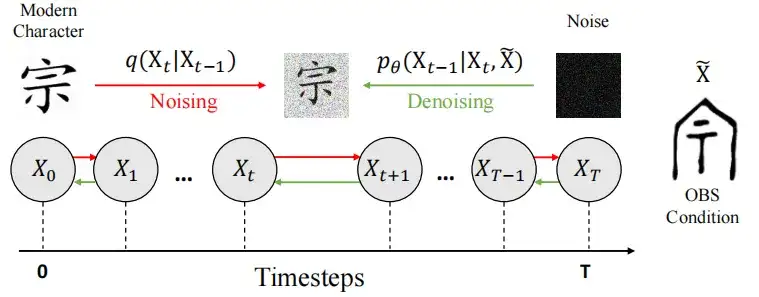
في المرحلة المبكرة (الضوضاء)،قام الباحثون بإدخال الضوضاء في صورة الحرف الصيني الحديث X0 واستخدموا عملية سلسلة ماركوف القابلة للتحكم لتحويلها إلى حالة مماثلة للضوضاء النقية، مما أدى في النهاية إلى تشكيل توزيع غاوسي N (0، I).
في مرحلة إزالة الضوضاء،استخدم الباحثون بنية U-Net لتدريب النموذج fθ للتنبؤ بالضوضاء e واستعادة الصورة، واستخدموا et ∼ N(0, I) لإدخال العشوائية لتعزيز تنوع نتائج توليد النموذج. النتيجة النهائية لفك التشفير هي الصورة المولدة الخالية من الضوضاء X0.
وعلى هذا الأساس، يدمج نموذج OBSD مرحلة فك التشفير الأولية ومرحلة تحسين اللقطة الصفرية لتحسين دقة فك التشفير، كما هو موضح في الشكل أدناه.
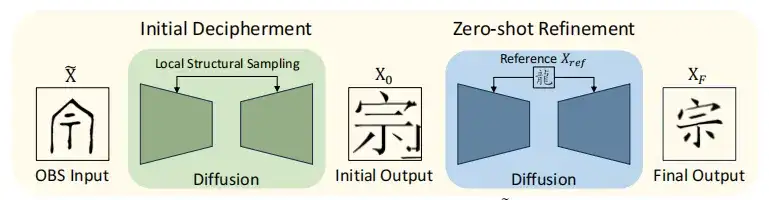
أولاً، يتم نشر صورة أوراكل X بشكل مشروط لتقريب الصورة الأولية X0، والتي يتم تحسينها بعد ذلك من خلال طريقة التعلم بدون لقطة، ويتم استخدام Xref كمرجع لتصحيح وتحسين البنية. بالاستفادة من الرؤية الثاقبة لبنية النص أثناء عملية التحسين، تم في النهاية إنشاء نتيجة النص XF التي تتوافق مع الأحرف الصينية الحديثة.
تقديم مفهوم LSS لتعزيز قدرة النموذج على ربط الأحرف القديمة بالأحرف الصينية الحديثة
ومع ذلك، في حالات التطبيق الفعلية، لا يستطيع النموذج المدرب بهذه الطريقة توليد الأحرف الصينية الحديثة المقابلة بدقة، بل يشكل بدلاً من ذلك بعض الهراء بناءً على عدد كبير من الأجزاء العشوائية، كما هو موضح في الشكل أدناه.

يعتقد الباحثون أن سبب هذه النتيجة هو أن نموذج الانتشار مصمم بشكل أساسي لتوليد صور طبيعية، ولكن في عملية فك رموز نقوش عظام الوحي، هناك اختلافات كبيرة في البنية بين نقوش عظام الوحي والحروف الصينية الحديثة.وهذا يجعل من المستحيل على نموذج الانتشار الشرطي القياسي إعادة بناء الأحرف الصينية الحديثة المستهدفة بدقة.
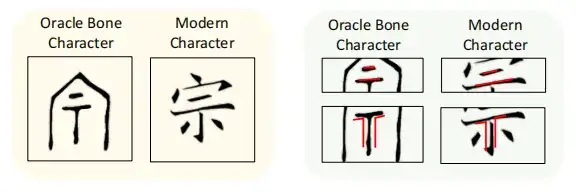
ولمعالجة هذا التحدي،قدمت هذه الدراسة مفهوم أخذ العينات من البنية المحلية (LSS).ساعد نموذج الانتشار على تعلم كيفية رسم خريطة للهيكل الجذري المحلي لنقوش عظام الوحي للأحرف الصينية الحديثة المقابلة، وبالتالي تعزيز قدرة النموذج على ربط الأحرف القديمة بالأحرف الصينية الحديثة. ووجدت الدراسة أيضًا أنه على الرغم من التطور الهيكلي الكبير من الحروف الصينية القديمة إلى الحروف الصينية الحديثة، فقد تم الحفاظ على بعض الهياكل المحلية.
من أجل تمكين نموذج الانتشار من تعلم خصائص البنية المحلية، تستخدم وحدة LSS طريقة النافذة المنزلقة لتقسيم صورة الأحرف الصينية الحديثة المستهدفة X0∈RHxWx3 وصورة عظمة الوحي المقابلة X∈RHxWx3 إلى D كتلة صغيرة بحجم p×p، يشار إليها بـ X(d) وXt(D)∈Rp×p×3، D=1,2…D، p=64. هنا، يمثل Xt صورة نصية حديثة مع ضوضاء غاوسية ϵt مضافة في خطوة الوقت t.
وبناء على هذه الطريقة،يمكن للنموذج تكرار وتحسين التصحيحات من خلال تعلم البنية المحلية لنقوش عظام الوحي والاختلافات الدقيقة في بنية الأحرف الصينية.إن ما يميز طريقتنا هو أنها تحسب متوسط التداخلات بين المناطق المتجاورة في كل خطوة زمنية t دون إكمال إزالة الضوضاء لضمان تأثير موحد على المناطق المشتركة. وفي الوقت نفسه، تجنبت هذه الدراسة الاختلافات بين الحواف وحافظت على الاتساق البصري للصورة المعاد بناؤها من خلال تنعيم التحولات الإقليمية في عملية أخذ العينات.
تقديم أساليب التعلم بدون طلقة لتعزيز قدرة النموذج على فهم بنية الشخصية
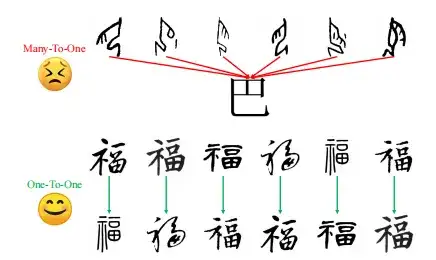
وعلى الرغم من تحقيق بعض التقدم في توليد الأحرف الصينية الحديثة باستخدام العينات الهيكلية المحلية، فإن جهود فك التشفير الأولية لا تزال تواجه عقبات واضحة مثل التشوهات الهيكلية والتحف.

ويرجع ذلك إلى أسلوب التدريب المتعدد إلى واحد المستخدم، والذي يربط بين نقوش عظام أوراكل المتعددة وصورة حرف صيني حديث واحد.وهذا يؤدي إلى الارتباك وعدم الدقة في التقاط تطور الشخصيات.ونتيجة للعينات المحدودة من الحروف الصينية الحديثة، يظهر هيكل غير مكتمل.
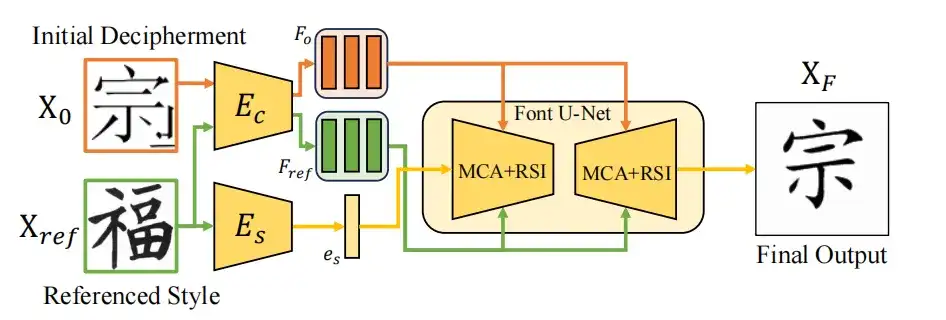
وللتغلب على هذه التحديات،اقترحت هذه الدراسة استراتيجية تعلم من الصفر لتحسين فهم النموذج للبنية باستخدام أنماط مختلفة من الكتابة بالحروف الصينية الحديثة.وفي التشغيل الفعلي، قامت الدراسة بتدريب الوحدة بطريقة فردية على 20 خطًا صينيًا حديثًا مختلفًا، وبالتالي تعلم التحولات البنيوية بين أنماط الكتابة الصينية الحديثة المختلفة وتعزيز قدرة النموذج على فهم بنية الأحرف.
كما هو موضح في الشكل أدناه، تعتمد طريقة التعلم هذه على إطار عمل عالمي لنقل نمط الخط. من خلال نظام ترميز مزدوج، يتم تكييف نمط صورة الخط المصدر X0 مع نمط الهدف Xref مع الحفاظ على سلامة المحتوى. يقوم مشفر النمط Es باستخراج ميزة النمط es من Xref، بينما يقوم مشفر المحتوى Ec بمعالجة Xo وXref للحصول على ميزة المحتوى متعدد المقاييس Fo، والتي يتم تحسينها بواسطة Font U-Net باستخدام تجميع المحتوى متعدد المقاييس (MCA) وبنية المرجع. بعد اكتمال التدريب، يمكن استخدام وحدة التعلم بدون لقطة مباشرة لتحسين النتائج الناتجة عن نموذج الانتشار.
تقييم أداء OSBD: معدل دقة التعرف هو الأعلى في ظل معايير التقييم المتعددة
من أجل تقييم أداء OSBD كميًا، استخدمت هذه الدراسة معيارين مختلفين للتقييم: فك التشفير بجولة واحدة وفك التشفير بجولات متعددة. نظرًا لعدم وجود أدوات مخصصة لفك رموز عظام الوحي، فإن هذه الدراسة تتبنى إطارًا مقارنًا لتكييف طرق ترجمة الصور إلى الصور الرائدة مع هذه المهمة.
على وجه التحديد، تتضمن هذه الأساليب أساليب تعتمد على GAN مثل Pix2Pix، وCycleGAN، وDRIT++، ونماذج الانتشار مثل CDE، وPalette، وBBDM. يضمن هذا الإعداد إمكانية تقييم طريقة OBSD في سياق ترجمة الصور الحديثة ويضمن الاتساق العادل في ظروف التدريب والاختبار.
في جولة واحدة من تقييم فك التشفير،تتمتع تقنية OBSD بمزايا كبيرة مقارنة بطرق تحويل الصور المعدلة إلى صور في كسر عظام أوراكل.كما هو موضح في الشكل أدناه.
إن الدقة الأولى التي تم تحقيقها بواسطة OSBD من خلال OBS-OCR و PaddleOCR هي 41.0% و 30.0% على التوالي، وهو ما يؤدي إلى أداء أفضل من الطرق الأخرى. ومع ارتفاع التصنيف، تظهر الدقة اتجاهًا واضحًا نحو التحسن. في ظل دقة أعلى 500، يحقق OSBD دقة التعرف على OBS-OCR بمقدار 64.5%.
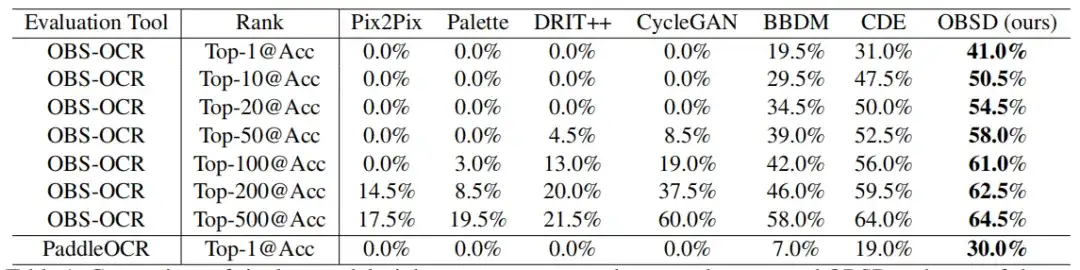
ومن الجدير بالذكر أن جميع الطرق المعتمدة على GAN (مثل Pix2Pix وPalette وDRIT++ وCycleGAN) تظهر أسوأ فعالية في هذه الحالة، مع دقة قصوى تبلغ 0.%. قد يكون هذا بسبب صعوبة GAN نفسها في التقاط علاقات التخطيط المعقدة والدقيقة المطلوبة لفك رموز عظام العرافة.
في جولات متعددة من تقييم فك التشفير،تحسن معدل نجاح OBS-OCR تدريجيًا على مدى محاولات متعددة.لقد تحسن المؤشر بشكل مستمر من معدل نجاح 41.0% إلى 80.0%، كما هو موضح في الشكل أدناه.
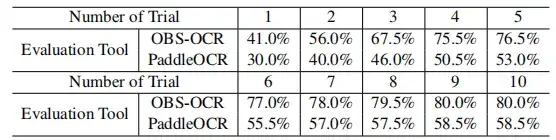
وأظهر اتجاه نمو مؤشر PaddleOCR أيضًا اتجاهًا تصاعديًا، بدءًا من 30.0% وأخيرًا وصل إلى 58.5%. وتؤكد كل هذه النتائج أنه من الممكن تحقيق تحسينات تدريجية من خلال محاولات متتالية.
وللتحقق بشكل أعمق من تأثير كل مكون، أجرت هذه الدراسة أيضًا دراسة استئصال، مع التركيز على وحدة LSS والتعلم بدون طلقة. تظهر النتائج أن فك رموز نقوش عظام الوحي باستخدام نموذج الانتشار الشرطي الأساسي فقط له حدود ودقة أقل بشكل كبير. على وجه التحديد، يؤدي تدريب نموذج الانتشار دون أي زيادة إلى مخرجات لا معنى لها في الأساس.
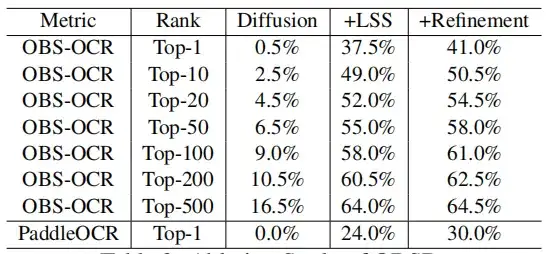
من خلال تقديم وحدة LSS،تم تحسين دقة التعرف على OBS-OCR إلى 37.5%.تم تحسين PaddleOCR إلى 24%. من خلال استخدام وحدة التعلم بدون لقطة مع LSS، يمكن تحسين دقة Top-1 لـ OBS-OCR وPaddleOCR بشكل أكبر من خلال 3.5% و6% إضافية على التوالي.
وأخيرًا، تقوم هذه الدراسة أيضًا بإجراء دراسة نوعية على نماذج مختلفة لترجمة الصور إلى الصور.
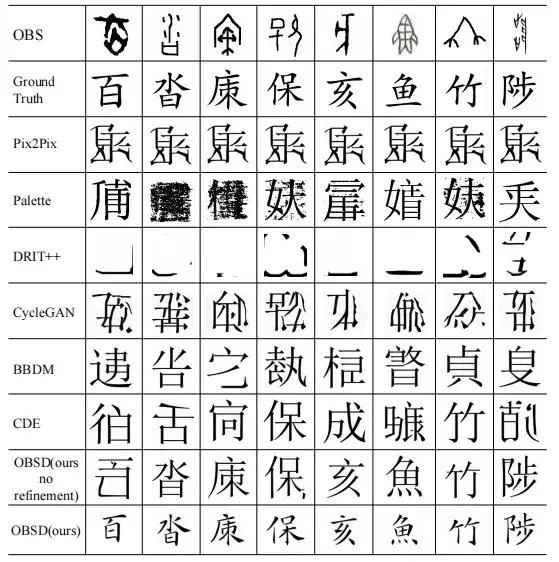
تظهر النتائج أن نقوش عظام الوحي المدخلة من خلال طريقة OBSD يمكن أن تنتج فك تشفير أحرف صينية حديثة بدقة عالية ويمكنها تمييز التفاصيل المعقدة لنقوش عظام الوحي. لا تسلط هذه النتائج الضوء على فعالية OSBD فحسب، بل تسلط الضوء أيضًا على إمكاناتها كأداة متخصصة لفك تشفير لغة أوراكل.
يتألق فريق البحث بشكل كبير، ويقود الذكاء الاصطناعي + Oracle
في مجال أبحاث الأحرف الصينية القديمة، وخاصة أبحاث نصوص عظام الوحي، كانت جامعة هواتشونغ للعلوم والتكنولوجيا دائمًا في طليعة العصر. وهي واحدة من أوائل الجامعات في الصين التي قامت بإنشاء قاعدة بيانات مستقلة لنصوص عظام أوراكل. مع التطور السريع لتكنولوجيا الذكاء الاصطناعي، أصبحت المعالجة الذكية للنصوص والصور واحدة من النقاط الساخنة في مجال أبحاث الذكاء الاصطناعي. أصبحت جامعة هواتشونغ للعلوم والتكنولوجيا، ممثلة بفريق البحث باي شيانغ وليو يوليانغ، رائدة وقائدة في مجال ذكاء النص والصورة مرة أخرى.
البروفيسور باي شيانغ هو عالم شاب متميز على المستوى الوطني وزميل في IAPR. وهو يشغل حاليًا منصب عميد كلية البرمجيات في جامعة هواتشونغ للعلوم والتكنولوجيا ومدير مركز أبحاث هندسة هوبي للرؤية الآلية والأنظمة الذكية. سابقًا،فاز نموذج Monkey المتعدد الوسائط الكبير الذي تم تطويره تحت قيادة البروفيسور باي شيانغ بالمركز الأول في إصدار OpenCompass مفتوح المصدر لقائمة النماذج الكبيرة الموثوقة.وتم تطبيق النتائج على المنتجات المبتكرة لشركات البرمجيات الرائدة في ووهان.
باعتباره عضوًا أساسيًا في فريق باي شيانغ، تم اختيار ليو يوليانغ للمشروع التاسع لدعم المواهب الشابة التابع للجمعية الصينية للعلوم والتكنولوجيا. ركز على ذكاء النص والصورة وحقق سلسلة من نتائج العمل في التحليل الذكي للوثائق، والرؤية وفهم اللغة الطبيعية، والنماذج الكبيرة متعددة الوسائط.
مع تطور التكنولوجيا ونضجها، ومن أجل تحقيق اختراقات أكبر في أبحاث عظام العرافة، اختار باي شيانغ والأستاذ ليو يوليانغ بحزم القيام بالتعاون المتعمق مع جامعة أنيانغ العادية، إحدى المؤسسات الرائدة في أبحاث عظام العرافة في الصين. في عام 2018، تمت الموافقة على إنشاء مختبر رئيسي لمعالجة معلومات أوراكل التابع لوزارة التعليم في جامعة أنيانغ العادية؛ في عام 2019، تم افتتاح "Yinqiwenyuan"، وهي منصة بيانات كبيرة لنصوص أوراكل العظام تم بناؤها بعناية بواسطة المختبر والتي تدمج مكتبة مستندات نصوص أوراكل العظام ومكتبة الكتالوج ومكتبة الأحرف، للعالم.هذه هي منصة بيانات أوراكل الأكثر اكتمالا وتوحيدا وموثوقية في العالم.ويمثل افتتاحه دخول أبحاث عظام العرافة إلى العصر الذكي.
ومن الجدير بالذكر أن ليو يونغجي، أحد المؤلفين المراسلين لهذه المقالة، هو مدير المختبر الرئيسي لمعالجة معلومات أوراكل التابع لوزارة التعليم في جامعة أنيانغ العادية.
من أجل تسجيل ونشر أبحاث عظام أوراكل بشكل أفضل، ركز المختبر على أمرين رئيسيين في عام 2023: من ناحية أخرى، أطلق بشكل مشترك "خطة العودة الرقمية العالمية لعظام أوراكل" مع Tencent SSV ومحطة عمل Anyang التابعة لمعهد الآثار والأكاديمية الصينية للعلوم الاجتماعية ومكتب الآثار الثقافية لبلدية Anyang، باستخدام كاميرات تحتوي على مئات الملايين من وحدات البكسل لتحقيق ترميم عالي الدقة وحماية عظام أوراكل المادية في الفضاء الرقمي. ومن ناحية أخرى، نجح البرنامج الصغير "Amazing Oracle" الذي أطلقته المختبرات بالتعاون مع شركة Tencent في تقريب شركة Oracle من الجمهور.
وبالمصادفة، من أجل تسهيل على الباحثين العثور على معلومات حول ربط عظام الأوراكل بشكل أكثر ملاءمة وتقصير الوقت اللازم لجمع البيانات في المرحلة المبكرة من البحث،في أوائل عام 2023، قام يانغ يي وهوانغ بو وتشنغ مينغ هوي، طلاب الدكتوراه من مركز أبحاث الوثائق المحفورة والشخصيات القديمة في جامعة فودان، بإنشاء قاعدة بيانات معلومات ربط عظام أوراكل "اليشم واللؤلؤ".يضم هذا الكتاب أكثر من 6700 مجموعة من نتائج ربط عظام أوراكل من العديد من العلماء منذ نشر "مجموعة عظام أوراكل". لم يصبح هذا الموقع أداة عبر الإنترنت للمجتمع الأكاديمي للبحث عن نتائج رئيسية لربط عظام الوحي فحسب، بل يسمح أيضًا للعديد من المتحمسين لعظام الوحي خارج "البرج العاجي" بالحصول على فرصة المشاركة في عمل حل شظايا عظام الوحي وتقديم التصحيحات ومعلومات جديدة حول ربط عظام الوحي.
ومن الواضح أنه بمساعدة التقنيات الرقمية مثل البيانات الضخمة والحوسبة السحابية والذكاء الاصطناعي، دخل بحث عظام أوراكل عصرًا جديدًا. ومع استمرار تعميق البحث، أعتقد أن هذه "المهارة السرية غير الشعبية" سوف تكشف في نهاية المطاف عن المزيد من الرموز في المستقبل القريب، وسوف تكون بمثابة مرجع مهم للغاية لفك رموز الشخصيات القديمة الأخرى.