Command Palette
Search for a command to run...
20 بيانات تجريبية تخلق إنجازًا كبيرًا في مجال بروتين الذكاء الاصطناعي! أصدرت جامعة شنغهاي جياو تونغ ومختبر شنغهاي للذكاء الاصطناعي بشكل مشترك برنامج FSFP لتحسين نماذج التدريب المسبق للبروتين بشكل فعال

البروتينات، هذه الجزيئات البيولوجية الصغيرة ولكن القوية، تشكل أساس أنشطة الحياة وتلعب أدوارًا متعددة في الكائنات الحية. ومع ذلك، فإن ضبط وظائف البروتين وتحسينها بدقة لتناسب الاحتياجات الصناعية أو الطبية المحددة يعد مهمة صعبة. تقليديا، اعتمد العلماء على أساليب المختبرات الرطبة لاستكشاف أسرار البروتينات، ولكن هذا النهج يستغرق وقتا طويلا ومكلفا.
ولحسن الحظ، ومع التطور السريع للذكاء الاصطناعي، هناك أداة جديدة - نماذج لغة البروتين المدربة مسبقًا (PLMs)، تساعدنا في فهم وتوقع سلوك البروتينات بطريقة غير مسبوقة. تتعلم PLMs خصائص توزيع تسلسلات الأحماض الأمينية في ملايين البروتينات بطريقة غير خاضعة للإشراف وتظهر إمكانات كبيرة في الكشف عن العلاقة الضمنية بين تسلسلات البروتين ووظائفها، وبالتالي المساعدة في استكشاف مساحة تصميم كبيرة بكفاءة. الآن،لقد حققت برامج إدارة دورة حياة المنتج المدربة مسبقًا تقدمًا كبيرًا في غياب البيانات التجريبية، ولكن دقتها وإمكانية تفسيرها لا تزال بحاجة إلى التحسين.بالإضافة إلى ذلك، تتطلب نماذج التعلم الخاضع للإشراف التقليدية عددًا كبيرًا من عينات التدريب المصنفة، وهو ما يشكل أيضًا عقبة يصعب التغلب عليها في التطبيقات العملية.
من أجل حل المشاكل المذكورة أعلاه،مجموعة أبحاث البروفيسور هونغ ليانغ من كلية العلوم الطبيعية / كلية الفيزياء والفلك / معهد تشانغجيانغ للدراسات المتقدمة / كلية الصيدلة بجامعة شنغهاي جياو تونغ، بالتعاون مع تان بان، الباحث الشاب في مختبر الذكاء الاصطناعي في شنغهاي،الاستخدام الشامل للتعلم التحويلي الفوقي (MTL)، والتعلم من أجل الترتيب (LTR)، والضبط الدقيق الفعال للمعلمات (PEFT)،لقد قمنا بتطوير استراتيجية تدريب، FSFP، يمكنها تحسين نماذج لغة البروتين بشكل فعال عندما تكون البيانات نادرة للغاية.يمكن استخدامه لتعلم قدرة البروتين على التكيف من خلال عينات صغيرة. إنه يحسن بشكل كبير تأثير نماذج التدريب المسبق للبروتين التقليدية الكبيرة في التنبؤ بخصائص الطفرة عند استخدام القليل جدًا من البيانات التجريبية الرطبة، ويظهر أيضًا إمكانات كبيرة في التطبيقات العملية.
نُشر البحث ذو الصلة في مجلة Nature Communications، وهي شركة تابعة لـ Nature، تحت عنوان "تعزيز كفاءة نماذج لغة البروتين باستخدام الحد الأدنى من بيانات المختبر الرطب من خلال التعلم من خلال عدد قليل من اللقطات".

عنوان الورقة:
https://doi.org/10.1038/s41467-024-49798-6
عنوان تنزيل مجموعة بيانات طفرة البروتين ProteinGym:
يجمع المشروع المفتوح المصدر "awesome-ai4s" أكثر من مائة تفسير ورقي لـ AI4S ويوفر مجموعات وأدوات ضخمة من البيانات:
https://github.com/hyperai/awesome-ai4s
FSFP يحسن نموذج لغة البروتين لمعالجة مشكلة نقص البيانات
يتكون نهج FSFP من ثلاث مراحل:إنشاء مهام مساعدة للتدريب الفوقي، وتدريب PLMs على المهام المساعدة، ونقل PLMs إلى المهمة المستهدفة عبر LTR.
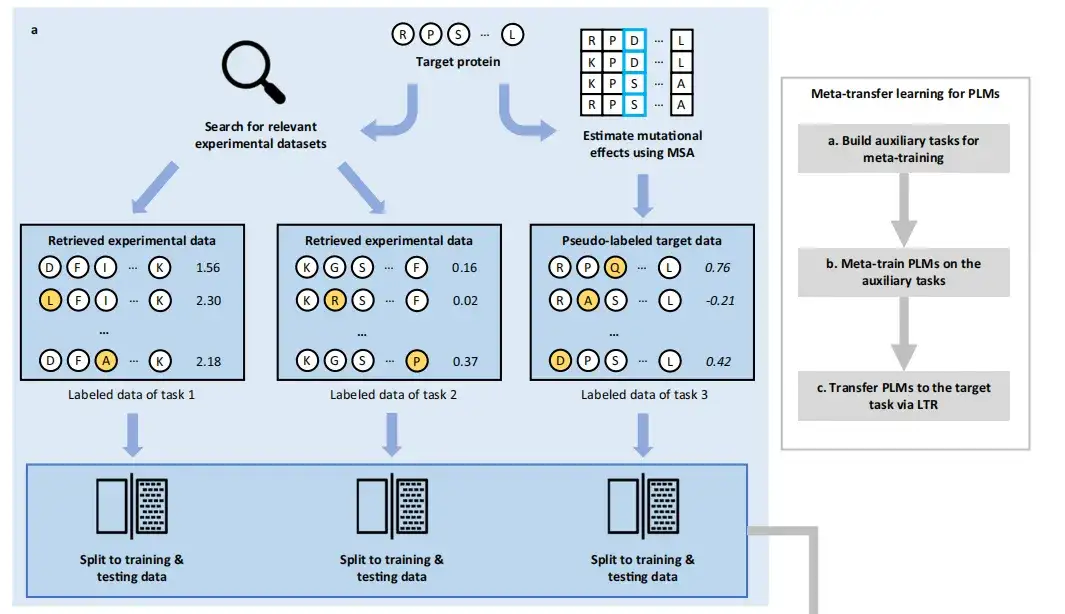
في،يهدف التعلم الفوقي إلى تجميع الخبرة من مهام التعلم المتعددة لتدريب نموذج يمكنه التكيف بسرعة مع المهام الجديدة باستخدام عدد صغير فقط من أمثلة التدريب والتكرارات.. لذلك، استخدمت هذه الدراسة أولاً PLMs لتشفير التسلسل أو البنية البرية للبروتين المستهدف والتسلسل أو البنية في قاعدة البيانات في متجه مضمن.
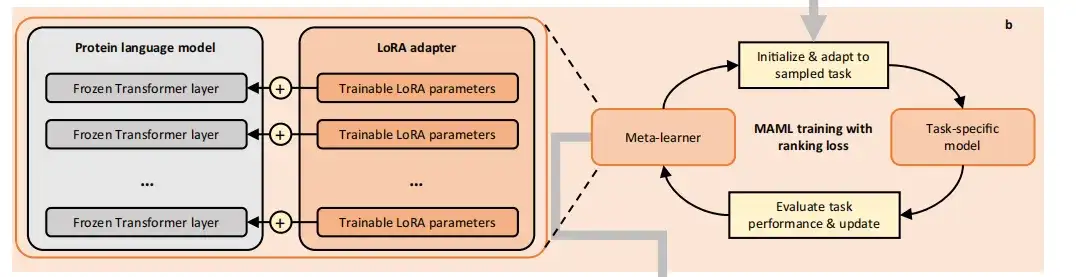
أيضًا،استخدمت الدراسة أسلوب التعلم الميتا القائم على التدرج والذي يسمى التعلم الميتا المستقل عن النموذج (MAML).تدريب PLMs على المهام المبنية. تتمكن MAML من العثور على معلمات النموذج الأولي المثالية بحيث يمكن حتى للتغييرات الصغيرة فيها أن تؤدي إلى تحسينات كبيرة في المهمة المستهدفة. في كل تكرار، تتكون عملية التدريب الفوقي من مستويين من التحسين وتحول في النهاية PLMs إلى متعلمين فوقيين مبدئيين.
في التحسين الداخلي، نستخدم المتعلم الفوقي الحالي لتهيئة متعلم أساسي مؤقت، والذي يتم تحديثه بعد ذلك إلى نموذج محدد للمهمة عن طريق أخذ عينات من بيانات تدريب المهمة. في التحسين الخارجي، نستخدم فقدان الاختبار لنموذج محدد للمهمة على المهمة لتحسين المتعلم الفوقي.
من أجل تجنب الإفراط في التجهيز الكارثي بسبب قلة بيانات التدريب،يستخدم FSFP التكيف مع الرتبة المنخفضة (LoRA) لحقن مصفوفات تحليل العوامل القابلة للتدريب في PLMs.تم تجميد المعلمات المدربة مسبقًا الأصلية وتم تقييد جميع تحديثات النموذج على عدد صغير من المعلمات القابلة للتدريب.
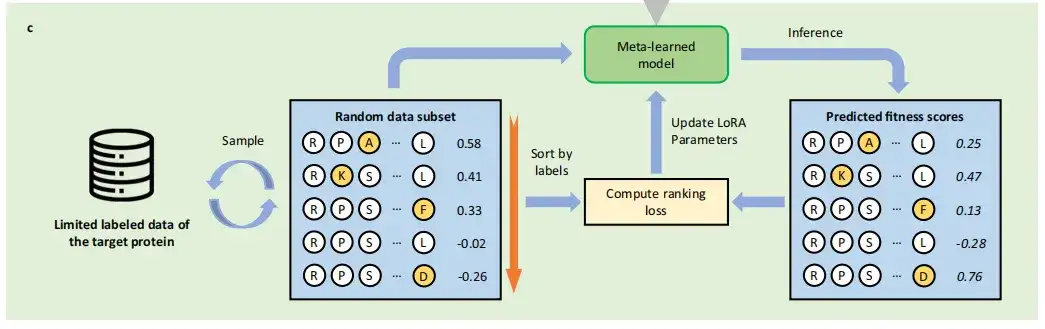
بعد التدريب التلوي، يمكن للدراسة الحصول على التهيئة بناءً على معلمات LoRA ونقل PLMs المدربة تليًا أخيرًا إلى مهمة التعلم الخاصة بالعينة الصغيرة المستهدفة، أي تعلم كيفية التنبؤ بتأثير الطفرة للبروتين المستهدف باستخدام بيانات محدودة مُسمّاة. تختلف عن طرق التعلم الخاضع للإشراف التقليدية للتنبؤ بطفرات البروتين،تتعامل FSFP مع هذه المشكلة باعتبارها مشكلة فرز وتستخدم تقنية LTR.
على وجه التحديد، يتعلم FSFP كيفية تصنيف لياقة الطفرة عن طريق حساب خسارة ListMLE. في كل تكرار، تقوم الدراسة بتدريب النموذج بحيث تتقارب تنبؤاته بشأن مجموعة فرعية واحدة أو أكثر من البيانات المأخوذة من العينات نحو ترتيب الحقيقة الأساسية. يتم تطبيق مخططات التدريب هذه في وقت واحد لتحقيق التحسين الداخلي في مرحلة التعلم الانتقالي باستخدام بيانات التدريب المستهدفة وفي مرحلة التدريب الفوقي باستخدام بيانات تدريب المهام المساعدة.
معيار بروتين جيم يعتمد على 87 مجموعة بيانات طفرات عالية الإنتاجية
من أجل بناء مهام التدريب المطلوبة للتعلم الفوقي،تسترجع هذه الطريقة أولاً مجموعات بيانات الطفرات الموسومة الموجودة، ثم تسترجع مجموعات بيانات الطفرة للبروتينين الأولين الأقرب إلى البروتين المستهدف من أكبر مجموعة عامة لمجموعات بيانات DMS، ProteinGym، وتستخدم طريقة وضع العلامات الزائفة GEMME المستندة إلى MSA لتسجيل معلومات الطفرة للبروتين المستهدف لإنشاء مجموعة البيانات للمهمة الثالثة. قد تكون مجموعات البيانات هذه مفيدة للتنبؤ بتأثيرات المتغيرات على البروتينات المستهدفة. يتم تقسيم البيانات المصنفة لهذه المهام بشكل عشوائي إلى بيانات تدريب وبيانات اختبار.
لتقييم أداء النموذج،تم اختيار مجموعة بيانات طفرة البروتين (ProteinGym) كمجموعة بيانات مرجعية لهذه الدراسة. تحتوي مجموعة البيانات على ما مجموعه حوالي 1.5 مليون متغير غير متماثل من 87 تجربة تسلسل DMS. نظرًا لأن الحد الأقصى لطول الإدخال لـ ESM-1v هو 1024، فقد قامت هذه الدراسة بتقليص البروتينات التي تحتوي على أكثر من 1024 حمضًا أمينيًا وتأكدت من أن معظم طفراتها في مجموعات البيانات المقابلة حدثت ضمن الفاصل الزمني الناتج.
بعد ذلك، اختارت الدراسة عشوائيًا 20 طفرة ذات نقطة واحدة كمجموعة تدريب أولية، ثم أضافت 20 طفرة أخرى ذات نقطة واحدة لتوسيع حجم مجموعة التدريب إلى 40، وبالمثل تم إنشاء مجموعات تدريب مكونة من 60 و80 و100. بعد 5 عمليات تقسيم عشوائي للبيانات،يمكن لهذه الدراسة تحقيق متوسط أداء النموذج على أقسام مختلفة من مقياس تدريب معين.
يتم تطبيق FSFP بنجاح على ثلاثة نماذج أساسية وله مزايا كبيرة في مهام التعلم ذات العينات الصغيرة
من الناحية النظرية، يمكن تطبيق FSFP على أي نموذج لغة بروتينية يعتمد على تحسين الانحدار التدرجي.من أجل التحقق من عالميتها،وقد اختارت هذه الدراسة ثلاثة نماذج PLM تمثيلية - ESM-1v وESM-2 وSaPro-t كنماذج أساسية للتدريب، كما اختارت نسخة 650M للتقييم.
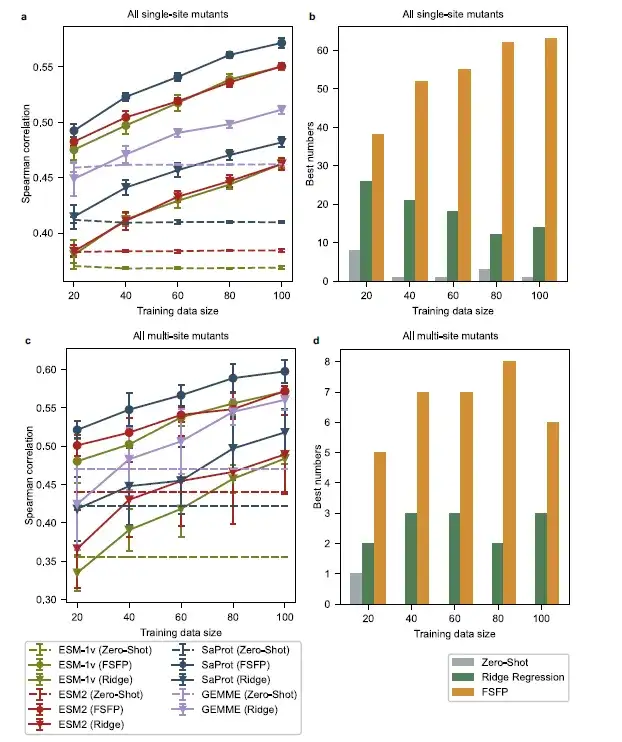
من حيث الأداء المتوسط،تتفوق PLMs التي تم تدريبها بواسطة FSFP باستمرار على خطوط الأساس الأخرى في جميع أحجام بيانات التدريب. ومن بينها، كان أداء SaProt (FSFP) هو الأفضل، في حين كان أداء ESM-1v (FSFP) وESM-2 (FSFP) جيدًا بنفس القدر. علاوة على ذلك، في معظم مجموعات البيانات الخاصة بـ ProteinGym، حققت PLMs المدربة بواسطة FSFP أفضل ارتباط سبيرمان. بالمقارنة مع التنبؤ بالرصاصة الصفرية، تعمل FSFP على تحسين أداء PLMs على الطفرات الفردية بنحو 0.1 من خلال تحسين ارتباط سبيرمان للطفرات الفردية باستخدام 20 مثالاً تدريبيًا فقط، وتصبح هذه الفجوة أكبر عندما يتعلق الأمر بالعديد من الطفرات. تزداد هذه التحسينات مع نمو مجموعة بيانات التدريب، وهو ما يتوافق مع نتائج الاستئصال لهذه الدراسة.
يحقق النموذج الذي يستخدم FSFP تحسينات كبيرة على GEMME ونسخته المحسنة من الانحدار التلالي في جميع عينات التدريب. يشير هذا إلى أن FSFP لا ينقل فقط معرفة محاذاة التسلسل المتعددة في GEMME إلى PLM، بل يجمعها أيضًا بنجاح مع معلومات الإشراف من بيانات التدريب المستهدفة من خلال التعلم متعدد المهام.وهذا يؤكد مرة أخرى ميزة FSFP في مهام التعلم ذات اللقطات القليلة.
تقييم أداء الاستقراء، وتقييم ارتباط سبيرمان لـ FSFP المدربين على PLMs أفضل
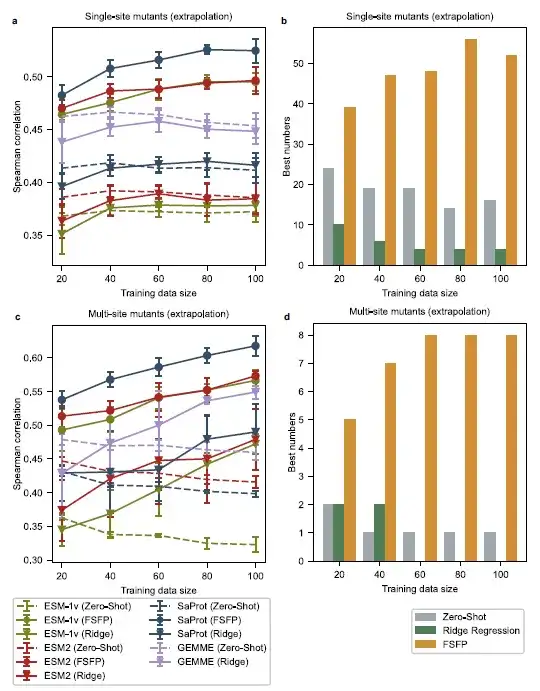
قام الباحثون باختيار جميع الطفرات ذات النقطة الواحدة من كل مجموعة اختبار أصلية كانت مواقع طفراتها مختلفة عن أمثلة التدريب، وبالتالي الحصول على مجموعة اختبار من الطفرات ذات النقطة الواحدة التي كانت مختلفة عن أمثلة التدريب. ثم قام الباحثون باختيار الطفرات متعددة النقاط التي لا تتداخل طفراتها الفردية مع تلك الموجودة في بيانات التدريب، مما أدى إلى مجموعة اختبار أخرى صعبة. في هذا الإعداد، نجد أن أداء اللقطة الصفرية للنموذج الأساسي يتناسب بشكل كبير مع حجم مجموعة التدريب.
بالنسبة للطفرات ذات النقطة الواحدة في مواضع مختلفة، فإن النموذج المعزز بالانحدار التلالي لا يؤدي بشكل أفضل من النموذج الأساسي حتى مع 100 مثال تدريبي. بالنسبة للطفرات متعددة النقاط، عندما يكون حجم التدريب أقل من 60، لا يمكن لطريقة الانحدار التلالي تحسين أداء GEMME وESM-2 بشكل فعال. على النقيض من ذلك، كان لدى نماذج PLM المدربة باستخدام FSFP درجات ارتباط سبيرمان أعلى مقارنة بجميع النماذج الأساسية في جميع أحجام التدريب. أيضًا،أفضل النماذج أداءً في معظم مجموعات البيانات هي النماذج المدربة باستخدام FSFP.
مقارنة شاملة لأربعة بروتينات، يتمتع FSFP بفوائد أكبر في التدريب باستخدام مجموعات بيانات صغيرة
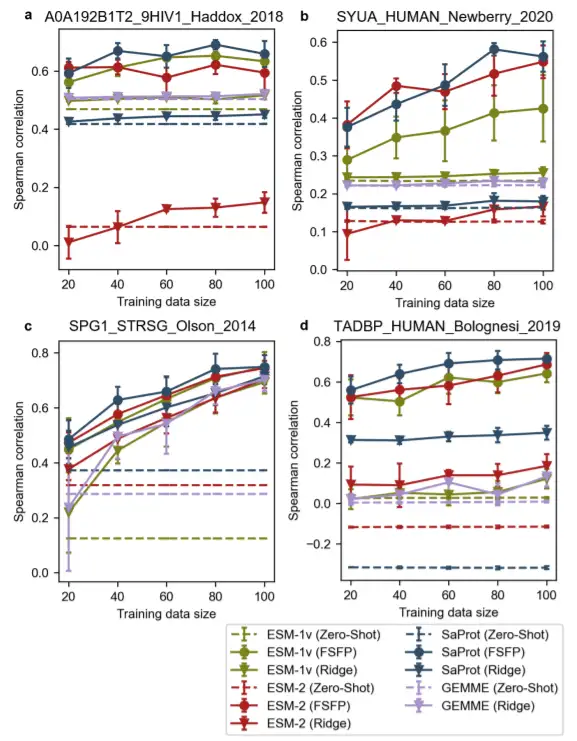
ولتوضيح مدى إمكانية تطبيق وتعميم FSFP بشكل أكبر،وأظهرت الدراسة أيضًا نتائج المقارنة بين طرق مختلفة لأربعة بروتينات: بروتين الغلاف Env من فيروس نقص المناعة البشرية، وα-synuclein البشري، والبروتين G (GB1)، وبروتين ربط الحمض النووي البشري TAR 43 (TDP-43). وفي العديد من هذه الحالات، كان أداء نموذج واحد أو أكثر غير خاضع للإشراف ضعيفا.
ومن الجدير بالملاحظة أنه بالنسبة لـ TDP-43، فإن جميع ارتباطات سبيرمان للتنبؤات بالعينة الصفرية قريبة من الصفر. باستثناء GB1، فإن معظم النماذج المعززة بالانحدار التلالي لا تحقق أيضًا تحسينات كبيرة في الأداء على مجموعات بيانات التدريب الأكبر حجمًا. في المقابل، يمكن للنماذج المدربة مسبقًا تحقيق مكاسب كبيرة عند تدريبها على مجموعات بيانات صغيرة باستخدام FSFP.
باستخدام FSFP لتصميم بوليميراز الحمض النووي Phi29، زاد معدل الإيجابية بمقدار 25%
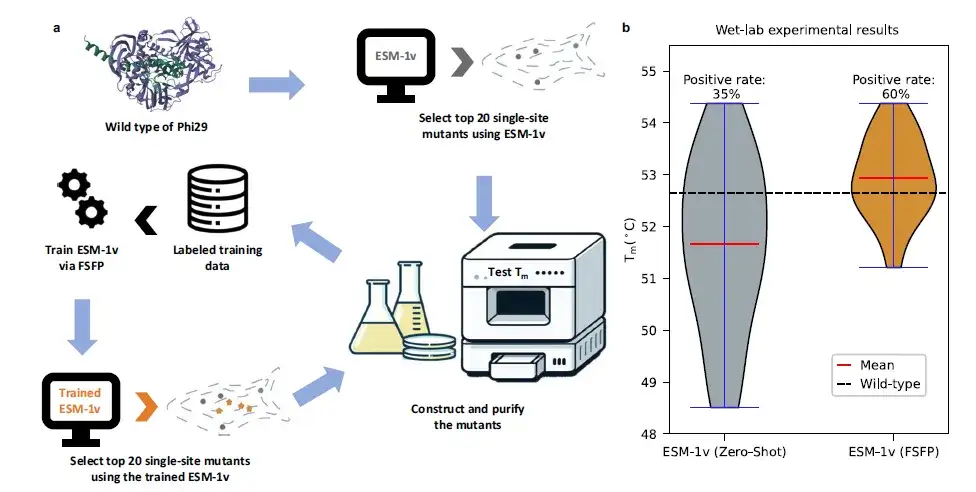
وتناولت الدراسة أيضًا حالة محددة لتعديل بروتين Phi29.تم إجراء التحقق من الاختبار الرطب.استنادًا إلى مجموعة محدودة من البيانات التجريبية الرطبة، استخدمت هذه الدراسة FSFP لتدريب ESM-1v، واستخدمتها للعثور على طفرات جديدة في موقع واحد، وأجرت التحقق التجريبي. عند مقارنة أفضل 20 نتيجة تنبؤ لـ ESM-1v قبل وبعد تدريب FSFP، زاد متوسط قيمة Tm بأكثر من 1 درجة مئوية وزاد المعدل الإيجابي بمقدار 25%.
على وجه التحديد، تم التوصية أيضًا بأفضل الطفرات (أي الطفرات ذات أعلى قيم Tm) التي وجدها ESM-1v (FSFP) بواسطة ESM-1v (اللقطة الصفرية). ومع ذلك، من بين الطفرات الإيجابية التي تنبأ بها ESM-1v (FSFP)، لم يظهر 9 منها في بيانات التدريب، مما يشير إلى أن FSFP يمكن أن يمكّن PLMs من تحديد المزيد من المتغيرات البروتينية.وتؤكد هذه النتائج قدرة FSFP على تسريع الدورات التكرارية لتصميم واختبار هندسة البروتين.وقد يساعد هذا في تطوير البروتينات ذات الخصائص الوظيفية المحسنة.
ممثل نموذجي للذكاء الاصطناعي في مجال الهندسة الحيوية، تحالف قوي يقف في طليعة العصر
واليوم، عندما أصبح الذكاء الاصطناعي والبحث العلمي متكاملين بشكل وثيق، فإننا نقف أمام فرصة تاريخية. يعتقد البروفيسور هونغ ليانغ أنه على الرغم من أن صناعة الأدوية الحيوية في الصين تتمتع بقوة كبيرة، إلا أنه لا يزال هناك مجال للتحسين في حصتها من الأرباح في السلسلة الصناعية الدولية. ومن خلال الذكاء الاصطناعي، لدينا الفرصة "لتغيير المسارات والتجاوز" واستخدام قوة الذكاء الاصطناعي بشكل مباشر لتعزيز تطوير الصناعة. وبناءً على هذا المفهوم، أطلق البروفيسور هونغ ليانغ والباحث تان بان استكشافات لا نهاية لها في مجال الذكاء الاصطناعي للهندسة الحيوية.
يركز الدكتور تان بان على الفيزياء الحيوية الجزيئية، وتصميم البروتين الوظيفي للذكاء الاصطناعي، وتصميم جزيئات الدواء.نشر 15 ورقة بحثية في مجال SCI في مجلات مثل Nature Communications، وPRL، وJournal of Cheminformatics، وPCCP، وغيرها. قام بتطوير مجموعة متنوعة من خوارزميات تصميم وتعديل البروتين بمساعدة الذكاء الاصطناعي. ومن خلال الجمع بين خبرة البروفيسور هونغ ليانغ وخوارزميات الذكاء الاصطناعي للدكتور تان بان، حقق البحث التعاوني بين الطرفين نجاحات متكررة.
على مر السنين، ركز الطرفان على الأبحاث المبتكرة في مجال الذكاء الاصطناعي العام في مجال هندسة البروتين ونجحا في تطوير سلسلة احترافية من الذكاء الاصطناعي العام لهندسة البروتين. على غرار الطريقة التي يفهم بها ChatGPT اللغة البشرية، تستخدم سلسلة Pro نماذج كبيرة لفهم ترتيب الأحماض الأمينية للبروتينات في الطبيعة وتصميم منتجات بروتينية ذات أداء متفوق. ومن بين هذه المنتجات، هناك أيضًا منتجان رائدان في التطبيقات الصناعية:
* جسم مضاد أحادي المجال مقاوم للغاية للقلويات:حقق أول منتج بروتيني مصمم على نطاق واسع في العالم، والذي تم تطويره بالتعاون مع شركة Jinsai Pharmaceuticals، 5000 لتر من الإنتاج الصناعي، مما يوفر حلاً جديدًا لتنقية الجزيئات البيولوجية الكبيرة.
* جليكوسيل ترانسفيراز:بالتعاون مع شركة Hanhai New Enzyme، قمنا بتطوير الإنزيم لإنتاج EPS-G7، المادة الأساسية لفحص التهاب البنكرياس، وكسر الاحتكار الأجنبي طويل الأمد وخفض التكاليف بشكل كبير.
تمثل هاتان الحالتان أول وثاني تصميم نموذجي واسع النطاق في العالم ونجاحًا في توسيع نطاق الإنتاج إلى مرحلة التصنيع لمنتجات البروتين. استنادًا إلى تراكمه العميق في مجال تصميم بروتين الذكاء الاصطناعي، أسس البروفيسور هونغ ليانغ شركة شنغهاي تيان وو للتكنولوجيا المحدودة في عام 2021. وفي غضون ثلاث سنوات فقط، لم تكمل الشركة مشاريع متعددة لتصميم البروتين فحسب، بل حصلت أيضًا على عشرات الملايين من اليوان في جولة ما قبل A من التمويل. ومن بين المستثمرين مؤسسات معروفة مثل Glory Ventures وGSR Ventures.
في الوقت الحاضر، تغطي خدمات الشركة مجالات متعددة مثل الأدوية المبتكرة، والتشخيصات المختبرية، وعلم الأحياء الاصطناعي، وما إلى ذلك، وهي تسعى بنشاط إلى التعاون مع المزيد من معاهد البحث العلمي والمؤسسات، وهي ملتزمة بوضع معيار وطني وحتى عالمي في مجال هندسة البروتين.
في مجال هندسة البروتين الذي يشهد منافسة شديدة، فإن رؤية البروفيسور هونغ ليانغ واضحة:لا ينبغي لنا أن نصبح قائدًا محليًا فحسب، بل قائدًا عالميًا أيضًا.وفي رحلة البحث العلمي المستقبلية، يلتزم البروفيسور هونغ ليانغ وفريقه بتوسيع التعاون المتعمق مع مؤسسات ومؤسسات البحث العلمي العالمية، واستكشاف الاحتمالات اللانهائية لتصميم البروتين باستمرار، والسعي إلى تحقيق اختراقات تكنولوجية وابتكار تطبيقات في هذا المجال، ووضع معيار محليًا وإظهار التميز دوليًا.
وأخيرًا، أوصي بنشاط تبادل أكاديمي عبر الإنترنت. يمكن للأصدقاء المهتمين مسح رمز الاستجابة السريعة للمشاركة!









