Command Palette
Search for a command to run...
تم اختياره لـ ICML، وأصدرت Tsinghua AIR وآخرون نموذج لغة البروتين ESM-AA بشكل مشترك، متجاوزين نموذج SOTA التقليدي

باعتبارها القوة الدافعة لعدد لا يحصى من التفاعلات الكيميائية الحيوية داخل الخلايا، تلعب البروتينات دور المهندسين المعماريين في العالم المجهري للخلايا. إنها لا تعمل على تحفيز أنشطة الحياة فحسب، بل تعمل أيضًا كمكونات أساسية لبناء وصيانة مورفولوجيا ووظيفة الكائنات الحية. إن التفاعل والتآزر بين البروتينات هو الذي يدعم المخطط الكبير للحياة.
ومع ذلك، فإن بنية البروتين معقدة وقابلة للتغيير، والطرق التجريبية التقليدية تستغرق وقتا طويلا وتتطلب جهدا كبيرا لتحليل بنية البروتين. ظهرت نماذج لغة البروتين (PLMs). من خلال استخدام تقنية التعلم العميق، من خلال تحليل كمية كبيرة من بيانات تسلسل البروتين، وتعلم القوانين الكيميائية الحيوية وأنماط التطور المشترك للبروتينات، فقد حقق إنجازات ملحوظة في مجالات التنبؤ ببنية البروتين، والتنبؤ بالتكيف وتصميم البروتين، وعزز بشكل كبير تطوير هندسة البروتين.
على الرغم من أن PLMs حققت نجاحًا كبيرًا على نطاق البقايا، إلا أن قدرتها على توفير المعلومات على المستوى الذري محدودة. ردًا على ذلك، تعاون تشو هاو، الباحث المشارك في معهد الصناعات الذكية بجامعة تسينغهوا، مع جامعة بكين وجامعة نانجينغ وفريق شويمو الجزيئي لـتم اقتراح نموذج لغة البروتين متعدد المقاييس ESM-AA (ESM All Atom).ومن خلال تصميم آليات التدريب مثل توسيع البقايا وترميز المواضع متعددة المقاييس، تم توسيع القدرة على معالجة المعلومات على المستوى الذري.
تم تحسين أداء ESM-AA في المهام مثل ربط الربيطة المستهدفة بشكل كبير، متجاوزًا نماذج لغة بروتين SOTA الحالية مثل ESM-2، ومتجاوزًا أيضًا نماذج تعلم التمثيل الجزيئي SOTA الحالية مثل Uni-Mol. وقد تم نشر بحث ذي صلة تحت عنوان "ESM All-Atom: نموذج لغة البروتين متعدد المقاييس للنمذجة الجزيئية الموحدة".نُشرت في ICML، مؤتمر التعلم الآلي الأهم.

عنوان الورقة:
https://icml.cc/virtual/2024/poster/35119
يجمع المشروع المفتوح المصدر "awesome-ai4s" أكثر من مائة تفسير ورقي لـ AI4S ويوفر مجموعات وأدوات ضخمة من البيانات:
https://github.com/hyperai/awesome-ai4s
مجموعة البيانات: تم إنشاء مجموعة بيانات مختلطة من البيانات البروتينية والجزيئية
في مهمة ما قبل التدريب،استخدمت الدراسة مجموعة بيانات مشتركة من البيانات البروتينية والجزيئية تحتوي على معلومات بنيوية مثل الإحداثيات الذرية.
بالنسبة لمجموعة بيانات البروتين، استخدمت الدراسة AlphaFold DB، التي تحتوي على 8 ملايين من تسلسلات وهياكل البروتين عالية الثقة المتوقعة من AlphaFold2.
بالنسبة لمجموعة البيانات الجزيئية، استخدمت الدراسة البيانات التي تم إنشاؤها بواسطة حقول القوة الجزيئية ETKDG وMMFF، والتي تحتوي على 19 مليون جزيء و209 مليون تكوين.
عند تدريب ESM-AA، قام الباحثون أولاً بخلط مجموعة بيانات البروتين Dp ومجموعة بيانات الجزيئات Dm معًا كمجموعة بيانات نهائية، أي D=Dp∪Dm. بالنسبة للجزيئات من Dm، نظرًا لأنها تتكون فقط من ذرات، فإن تسلسل تحويل الكود الخاص بها X̄ هو المجموعة المرتبة لجميع الذرات Ā بدون أي بقايا، أي R̄=∅. ومن الجدير بالذكر أنه نظرًا لاستخدام البيانات الجزيئية في التدريب المسبق، يمكن لـ ESM-AA قبول كل من البروتينات والجزيئات كمدخلات.
بناء نموذج ESM-AA: التدريب المسبق والترميز متعدد المقاييس لتحقيق النمذجة الجزيئية الموحدة
مستوحى من طريقة تبديل الكود متعدد اللغات، يقوم ESM-AA أولاً بفك ضغط بعض البقايا بشكل عشوائي لتوليد تسلسلات بروتينية لتبديل الكود متعدد المقاييس عند تنفيذ مهام التنبؤ وتصميم البروتين. يتم بعد ذلك تدريب هذه التسلسلات من خلال ترميزات موضعية متعددة المقاييس مصممة بعناية، وقد تم إثبات فعاليتها على مستوى البقايا والمستويات الذرية.
عند التعامل مع المهام الجزيئية البروتينية، أي المهام التي تنطوي على البروتينات والجزيئات الصغيرة، لا يتطلب ESM-AA أي مساعدة نموذجية إضافية ويمكنه الاستفادة الكاملة من قدرات النموذج المدرب مسبقًا.
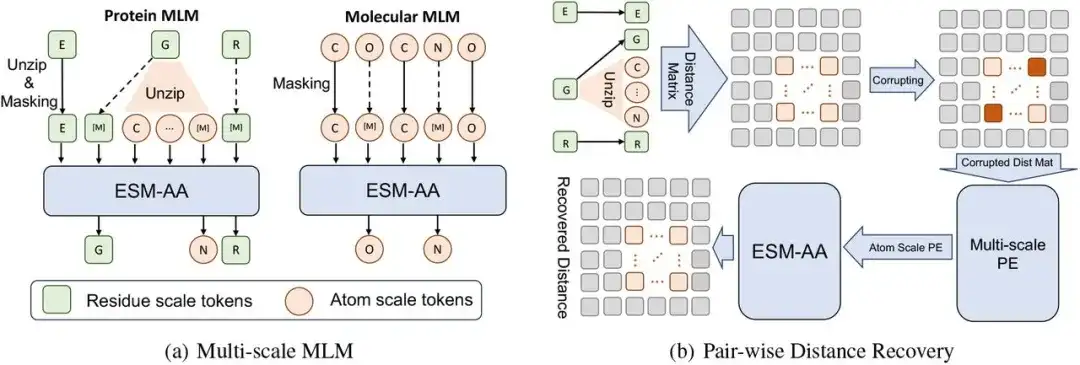
يتكون إطار التدريب المسبق متعدد المقاييس لهذه الدراسة من نموذج اللغة المقنع متعدد المقاييس (MLM) واستعادة المسافة الزوجية.
على وجه التحديد، على مقياس البقايا، يمكن النظر إلى البروتين X باعتباره تسلسلًا من بقايا L، أي، X = (r1،…،ri،…،rL). كل بقايا ri تتكون من ذرات N A Ai={a1i,…,aNi}. ولإنشاء تسلسل بروتين تبديل الكود X̅، قمنا بتنفيذ عملية إزالة الضغط عن طريق اختيار مجموعة من البقايا بشكل عشوائي وإدخال ذراتها المقابلة في X. وفي هذه العملية، رتب الباحثون الذرات التي تم فك ضغطها بالترتيب، وأخيرًا، بعد إدخال مجموعة الذرات Ai في X (أي فك ضغط البقايا ri)، حصلوا على تسلسل تبديل الكود X̄.
ثم،أجرى الباحثون نمذجة لغوية مقنعة على تسلسل تبديل الكود X̄.
أولاً، نقوم بإخفاء بعض الذرات أو البقايا بشكل عشوائي في X̄ ونترك النموذج يتنبأ بالذرات أو البقايا الأصلية باستخدام السياق المحيط. ثم استخدم الباحثون الاسترداد عن طريق المسافة الزوجية (PDR) كمهمة أخرى للتدريب المسبق. وهذا يعني أن المعلومات البنيوية على مستوى الذرة يتم تدميرها عن طريق إضافة الضوضاء إلى الإحداثيات، ويتم استخدام معلومات المسافة بين الذرات المدمرة كمدخلات للنموذج، مما يتطلب من النموذج استعادة المسافة الإقليدية الدقيقة بين هذه الذرات.
بالنظر إلى الاختلاف الدلالي بين المعلومات البنيوية طويلة المدى عبر بقايا مختلفة والمعلومات البنيوية على المستوى الذري داخل بقايا واحدة، فإن هذه الدراسة تحسب فقط PDR داخل البقايا، مما يمكن أيضًا ESM-AA من تعلم المعرفة البنيوية المختلفة داخل بقايا مختلفة.
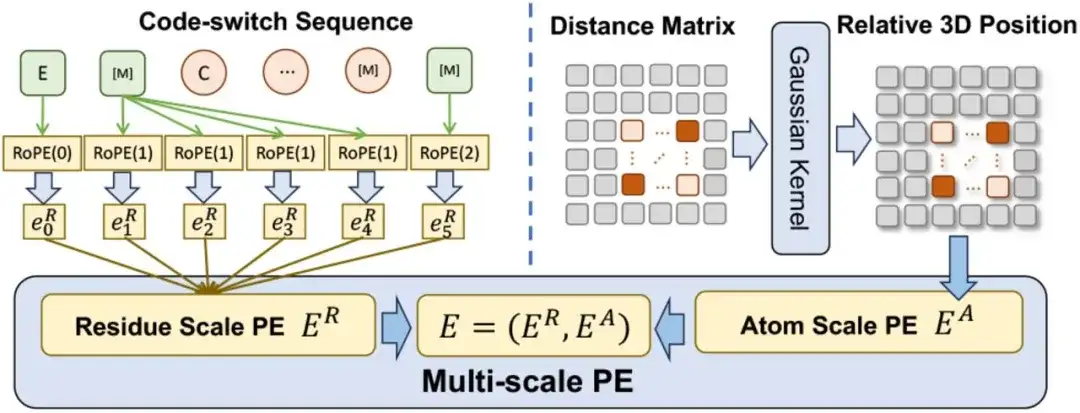
من حيث ترميز الموضع متعدد المقاييس، قام الباحثون بتصميم ترميز موضع متعدد المقاييس E لتشفير العلاقة الموضعية في تسلسل تبديل الرموز. يحتوي E على رمز موضع على مقياس البقايا ER ورمز موضع على مقياس الذرات EA.
بالنسبة لـ ER،قام الباحثون بتوسيع طريقة الترميز الموجودة لتمكينها من ترميز العلاقات بين البقايا والذرات مع الحفاظ على الاتساق مع الترميز الأصلي عند التعامل مع تسلسلات البقايا النقية.بالنسبة لـ EA،ولرصد العلاقات بين الذرات، تستخدم الدراسة بشكل مباشر مصفوفة المسافة المكانية لتشفير مواقعها ثلاثية الأبعاد.
ومن الجدير بالذكر أن طريقة الترميز متعدد المقاييس تضمن عدم تأثر التدريب المسبق بعلاقة الموضع الغامضة، بحيث يمكن لـ ESM-AA العمل بشكل فعال في كلا المقياسين.
عند دمج PE متعدد المقاييس في Transformer، استبدلت الدراسة أولاً الترميز الجيبي في Transformer بترميز موضع المقياس المتبقي ER، واعتبرت ترميز موضع المقياس الذري EA بمثابة مصطلح التحيز لطبقة الاهتمام الذاتي.
نتائج البحث: دمج المعرفة الجزيئية لتحسين فهم البروتين
للتحقق من فعالية النموذج الموحد متعدد المقاييس المدرب مسبقًا، قامت هذه الدراسة بتقييم أداء ESM-AA في مهام مختلفة تتضمن البروتينات والجزيئات الصغيرة.
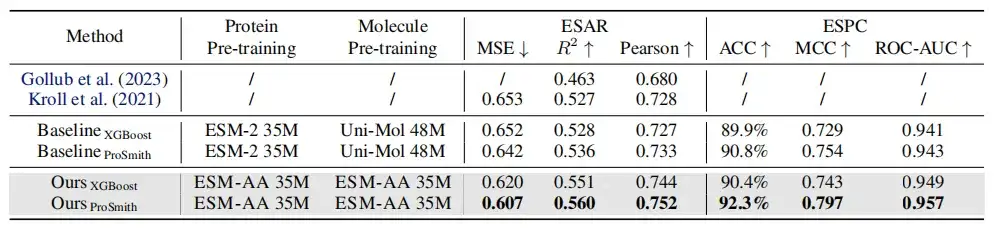
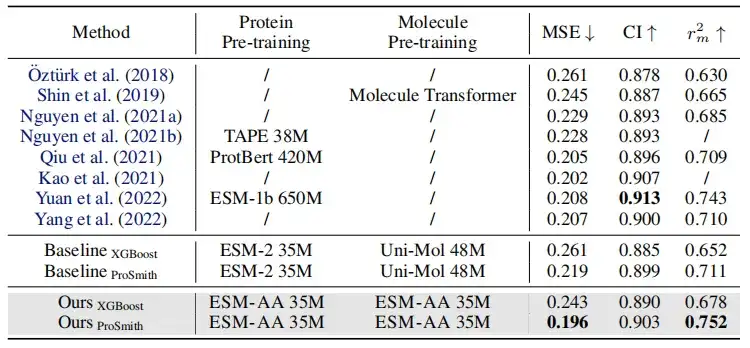
كما هو موضح في الجدول أعلاه، في مقارنة أداء مهمة الانحدار بين الإنزيم والركيزة، ومهمة تصنيف أزواج الإنزيم والركيزة، ومهمة الانحدار بين الدواء والهدف،وفي معظم المقاييس، يتفوق نموذج ESM-AA على النماذج الأخرى ويحقق نتائج متطورة.علاوة على ذلك، فإن استراتيجيات الضبط الدقيق (مثل ProSmith وXGBoost) المبنية على ESM-AA تفوقت باستمرار على الإصدارات التي تجمع بين نموذجين جزيئيين مستقلين مدربين مسبقًا مع نموذج البروتين المدرب مسبقًا (كما هو موضح في الصفوف الأربعة الأخيرة من الجدولين 1 و2).
ومن الجدير بالذكر أنيمكن لـ ESM-AA أن يتفوق حتى على الطرق التي تستخدم نماذج مدربة مسبقًا ذات أحجام معلمات أكبر.(على سبيل المثال، المقارنة بين الصف الخامس والسابع والأخير في الجدول 2).
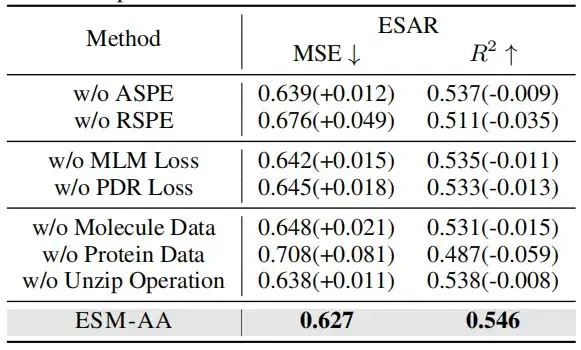
للتحقق من فعالية ترميز الموضع متعدد المقاييس، أجرت هذه الدراسة تجارب استئصال في حالتين: الأولى بدون استخدام ترميز الموضع على المقياس الذري (ASPE)؛ والأخرى بدون استخدام ترميز موضع المقياس الجيني (RSPE).
عند إزالة الجزيئات أو بيانات البروتين، انخفض أداء النموذج بشكل كبير. ومن المثير للاهتمام أن تدهور الأداء الناجم عن إزالة بيانات البروتين أكثر وضوحًا من التدهور الناجم عن إزالة البيانات الجزيئية. ويشير هذا إلى أنه عندما لا يتم تدريب النموذج على بيانات البروتين، فإنه يفقد بسرعة المعرفة المرتبطة بالبروتين، مما يؤدي إلى انخفاض كبير في الأداء العام. لكن،حتى بدون البيانات الجزيئية، لا يزال النموذج قادرًا على الحصول على معلومات على المستوى الذري من خلال عمليات إزالة الضغط.
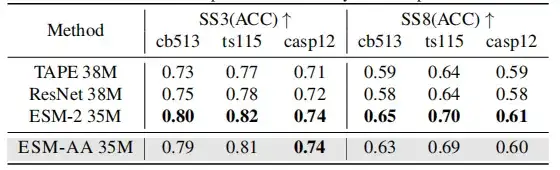
نظرًا لأن ESM-AA تم تطويره على أساس PLMs الموجودة، فإن هذه الدراسة تأمل في تحديد ما إذا كان لا يزال يحتفظ بفهم شامل للبروتينات، وبالتالي اختبار قدرة نماذج البروتين المدربة مسبقًا على فهم بنية البروتين باستخدام التنبؤ بالبنية الثانوية ومهام التنبؤ بالاتصال غير الخاضع للإشراف.
تظهر النتائج أنه على الرغم من أن ESM-AA قد لا يحقق الأداء الأمثل في هذا النوع من الدراسات،ومع ذلك، فإن أداءه في التنبؤ بالهيكل الثانوي والتنبؤ بالاتصال مماثل لأداء ESM-2.
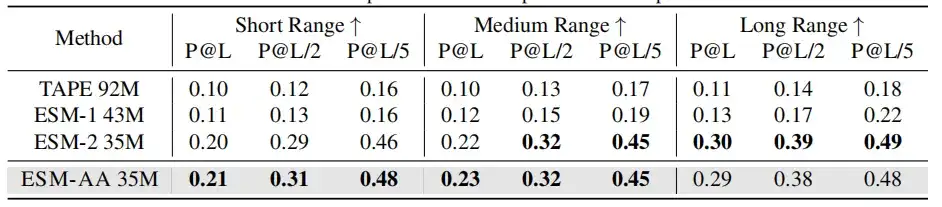
في المعايرة الجزيئية،يؤدي ESM-AA أداءً مماثلاً لـ Uni-Mol في معظم المهام.إنه يتفوق على العديد من النماذج الجزيئية المحددة في كثير من الحالات، مما يدل على إمكاناته كنهج قوي للمهام الجزيئية.
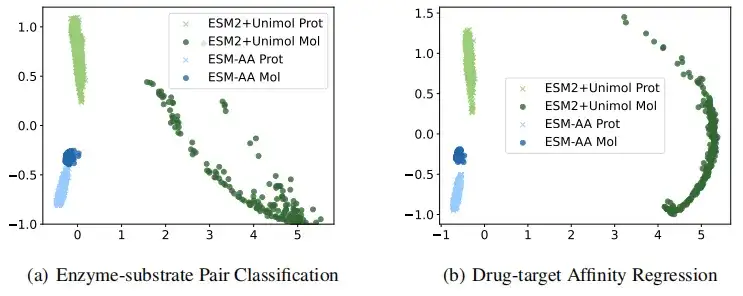
لتوضيح أن ESM-AA يحصل على بروتينات ذات جودة أعلى وتمثيلات جزيئية صغيرة بشكل أكثر بديهية، قامت هذه الدراسة بمقارنة التمثيلات المستخرجة بواسطة ESM-AA وESM-2+Uni-Mol بصريًا في مهام تصنيف زوج الإنزيم والركيزة وانحدار تقارب هدف الدواء. وتظهر النتائج أننموذج ESM-AA قادر على إنشاء تمثيل دلالي أكثر تماسكًا لكل من البيانات البروتينية والجزيئية، مما يجعل ESM-AA يتفوق على النموذجين المدربين مسبقًا المنفصلين.
نموذج لغة البروتين، الخطوة التالية في نموذج اللغة الكبير
منذ سبعينيات القرن العشرين، أصبح عدد متزايد من العلماء يعتقدون أن "القرن الحادي والعشرين هو قرن علم الأحياء". في يوليو/تموز الماضي، كتب فوربس مقالاً طويلاً، تخيل فيه أن برنامج الماجستير في القانون يضع الناس في طليعة جولة جديدة من التغييرات في مجال علم الأحياء. لقد أصبح علم الأحياء بمثابة نظام يمكن فك شفرته وبرمجته، وحتى رقمنته في بعض النواحي.إن برنامج الماجستير في القانون، مع قدرته المذهلة على التحكم في اللغات الطبيعية، يوفر إمكانية فك رموز اللغات البيولوجية.وهذا يجعل أيضًا نموذج لغة البروتين أحد المجالات الأكثر شعبية في هذا العصر.
تمثل نماذج لغة البروتين تطبيقات متطورة لتكنولوجيا الذكاء الاصطناعي في علم الأحياء. ومن خلال تعلم أنماط وهياكل تسلسلات البروتين، فإنه يمكن التنبؤ بوظيفة وشكل البروتينات، وهو أمر ذو أهمية كبيرة لتطوير الأدوية الجديدة وعلاج الأمراض والبحوث البيولوجية الأساسية.
في السابق، أظهرت نماذج لغة البروتين مثل ESM-2 وESMFold دقة مماثلة لتلك الخاصة بـ AlphaFold، مع سرعات معالجة أسرع وقدرات تنبؤ أكثر دقة لـ "البروتينات اليتيمة". ولا يؤدي هذا إلى تسريع التنبؤ ببنية البروتين فحسب، بل يوفر أيضًا أدوات جديدة للهندسة البروتينية، مما يسمح للباحثين بتصميم تسلسلات بروتينية جديدة تمامًا ذات وظائف محددة.
علاوة على ذلك، يستفيد تطوير نماذج لغة البروتين من ما يسمى بـ "قوانين القياس".وهذا يعني أن أداء النموذج يتحسن بشكل كبير مع زيادة مقياس النموذج وحجم مجموعة البيانات والجهد الحسابي.وهذا يعني أنه مع زيادة معلمات النموذج وتراكم بيانات التدريب، فإن قدرات نموذج لغة البروتين ستحقق قفزة نوعية.
وفي العامين الماضيين، دخلت نماذج لغة البروتين أيضًا فترة من التطور السريع في مجتمع الأعمال. في يوليو 2023، اقترحت شركة Baidu Biosciences وجامعة Tsinghua بشكل مشترك نموذجًا يسمى نموذج اللغة العامة للبروتين xTrimo (xTrimoPGLM) بحجم معلمات يصل إلى 100 مليار (100B)، والذي تفوق بشكل كبير على نماذج الأساس المتقدمة الأخرى في مهام فهم البروتين المتعددة (13 من أصل 15 مهمة).في مهمة التوليد، يتمكن xTrimoPGLM من توليد تسلسلات بروتينية جديدة تشبه الهياكل البروتينية الطبيعية.
في يونيو 2024، أعلنت شركة بروتين الذكاء الاصطناعي Tushen Zhihe أنتم توفير أول نموذج بروتيني للغة الطبيعية في الصين، TourSynbio™، مفتوح المصدر لجميع الباحثين والمطورين.يحقق هذا النموذج فهمًا لأدبيات البروتين بطريقة محادثة، بما في ذلك وظائف مثل خصائص البروتين والتنبؤ بالوظيفة وتصميم البروتين. من حيث مؤشرات التقييم التي تقارن مجموعات بيانات تقييم البروتين، فإنه يتفوق على GPT4 ويصبح الأول في الصناعة.
علاوة على ذلك، فإن الاختراق في البحث التكنولوجي الذي تمثله ESM-AA قد يعني أيضًا أن تطوير التكنولوجيا على وشك تجاوز "لحظة الأخوين رايت" والدخول في قفزة إلى الأمام. وفي الوقت نفسه، لن يقتصر تطبيق نماذج لغة البروتين على المجالات الطبية والبيولوجية الصيدلانية فحسب، بل قد يمتد أيضًا إلى مجالات متعددة مثل الزراعة والصناعة وعلوم المواد وإصلاح البيئة، مما يعزز الابتكار التكنولوجي في هذه المجالات ويجلب تغييرات غير مسبوقة للبشرية.








