Command Palette
Search for a command to run...
مجموعة بيانات arXiv بحجم 1.1 تريليون: 1.7 مليون ورقة بحثية، يمكنك أن ترى حياتك القادمة
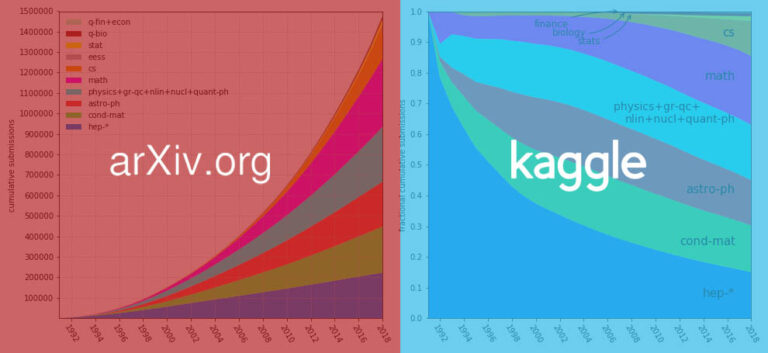
في الآونة الأخيرة، قام arXiv بتجميع أكثر من 1.7 مليون ورقة بحثية في مجموعة بيانات ووضعها على منصة Kaggle، مما يجعل الوصول إلى الأوراق البحثية وتنزيلها في المستقبل أكثر ملاءمة. يبلغ حجم مجموعة البيانات حاليًا حوالي 1.1 تيرابايت، ومن المتوقع أن تستمر في النمو مع التحديثات الأسبوعية.
أكثر من 1.7 مليون ورقة أكاديمية، بحجم 1.1 تيرابايت، هذه مجموعة من مجموعات البيانات التي تم فتحها مؤخرًا بواسطة arXix على Kaggle. وعندما سأل رواد الإنترنت عن ذلك، قالوا: رائع للغاية!
وقال فريق تجميع مجموعة البيانات إنهم يأملون في إلهام الباحثين ذوي الصلة لاستكشاف تقنيات التعلم الآلي الأكثر ثراءً والتوصل إلى المزيد من الاكتشافات والابتكارات.
تجعل مجموعات البيانات المفتوحة عمليات البحث الورقية أسهل
منذ ما يقرب من 30 عامًا، يوفر موقع arXiv للجمهور ومجتمعات البحث إمكانية الوصول المفتوح إلى المقالات العلمية التي تغطي مجموعة واسعة من المجالات.من فروع الفيزياء الواسعة، إلى فروع علوم الكمبيوتر العديدة، إلى جميع التخصصات مثل الرياضيات والإحصاء والهندسة الكهربائية وعلم الأحياء الكمي والاقتصاد.
هناك الكثير من أوراق البحث على arXiv، وعلى الرغم من أن العديد من الأشخاص يستفيدون منها،ومع ذلك، غالبًا ما يتم الإبلاغ عن وجود عيوب فيه مثل صعوبة التصفح والبحث والفرز.حتى أن بعض الأشخاص وجدوا بعض النصائح حول البحث عن الأوراق البحثية على arXiv وقاموا بمشاركتها معك.
لذا، لجعل arXiv أكثر سهولة في الوصول إليه، تقدم جامعة كورنيل الآن مجموعة بيانات arXiv مجانية ومفتوحة على Kaggle.
تحتوي مجموعة البيانات على 1.7 مليون ورقة أكاديمية، بالإضافة إلى عناصر مرتبطة بالورقة (ميزات)، مثل عنوان المقال، والمؤلف، والفئة، والملخص، والنص الكامل بصيغة PDF.
قالت إليونورا بريساني، المديرة التنفيذية لـ arXiv: "إن توفير مجموعة arXiv كاملةً على Kaggle يزيد بشكل كبير من إمكانات أوراق arXiv البحثية. بتوفير مجموعة البيانات على Kaggle، لم نعد نسمح للناس بتعلم المعرفة من خلال قراءة هذه المقالات فحسب،والأمر الأكثر أهمية هو أن البيانات والمعلومات التي يوفرها موقع arXiv ينبغي أن تكون متاحة للعامة بتنسيق قابل للقراءة بواسطة الآلة. "

وأضاف بريساني: "إن arXiv أكثر من مجرد مستودع للأوراق البحثية؛ إنه منصة لمشاركة المعرفة. وهذا يتطلب منا الابتكار في طريقة عرضنا وتفسيرنا للمعارف المتاحة. ويمكن لمستخدمي Kaggle المساهمة في توسيع آفاق هذا الابتكار، ليصبح قناة جديدة لنا للتعاون مع المجتمع".
شاهد: ماذا تتضمن مجموعة بيانات arXiv؟
المعلومات الأساسية لمجموعة بيانات arXiv هي كما يلي:
مجموعة بيانات arXiv
نُشر بواسطة: بول جينسبارج، مصنع مونشوت، جاك هيداري
الكمية المتضمنة:أكثر من 1.7 مليون ورقة أكاديمية
تنسيق البيانات:جسون
حجم البيانات:1.1 تيرابايت
وقت الإصدار:أغسطس 2020
عنوان التنزيل:https://www.kaggle.com/Cornell-University/arxiv
حاليًا، توفر مجموعة بيانات arXiv ملف بيانات وصفية بتنسيق json، والذي يحتوي على الإدخالات ذات الصلة بكل ورقة بحثية، على النحو التالي:
- معرف: عنوان الوصول إلى الورقة، والذي يمكن استخدامه للوصول إلى الورقة؛
- المُرسِل: مُرسِل الورقة؛
- المؤلفون: مؤلفو الورقة؛
- العنوان: عنوان الورقة؛
- التعليقات: معلومات أخرى مثل عدد الصفحات والأشكال في الورقة؛
- journal-ref: معلومات عن المجلة التي نشرت فيها الورقة؛
- doi: معرف الكائن الرقمي؛
- الملخص: ملخص الورقة؛
- الفئات: الفئات أو العلامات التي تنتمي إليها الورقة في arXiv؛
- الإصدارات: الإصدارات الورقية.
يمكنك تصفح هذه الأوراق الضخمة وتصفيتها والتحقق منها بسهولة.
بالإضافة إلى ذلك، يمكن للمستخدمين الوصول إلى كل ورقة بحثية مباشرة على arXiv عبر الرابطين التاليين:
- https://arxiv.org/abs/{id}: صفحة الورقة، بما في ذلك الملخص والروابط الأخرى؛
- https://arxiv.org/pdf/{id}: صفحة تحميل الورقة بصيغة PDF.
يتوفر أيضًا الوصول بالجملة: يتوفر ملف PDF الكامل مجانًا على مجموعة gs://arxiv-dataset على Google Cloud Storage، أو من خلال واجهة برمجة تطبيقات Google (وثائق json ووثائق xml).
يتم تجميع ملفات PDF الورقية في عدة ملفات .tar.gz في مجلد tarpdfs، ويبلغ حجم مجموعة البيانات بالكامل حوالي 1.1 تيرابايت. التفاصيل هي كما يلي (فيما يلي الأجزاء الأول والثاني والثالث من الحقول في يناير 2010 (1001)):
tarpdfs/arXiv_pdf_1001_001.tar.gz (gs://arxiv-dataset/tarpdfs/arXiv_pdf_1001_001.tar.gz)tarpdfs/arXiv_pdf_1001_002.tar.gz (gs://arxiv-dataset/tarpdfs/arXiv_pdf_1001_002.tar.gz)tarpdfs/arXiv_pdf_1001_003.tar.gz (gs://arxiv-dataset/tarpdfs/arXiv_pdf_1001_003.tar.gz)
يمكن للمستخدمين أيضًا تنزيل البيانات إلى أجهزتهم المحلية باستخدام أدوات مثل gsutil.

ومع ذلك، ما هي سيناريوهات الاستخدام المحددة لهذه المجموعة من البيانات؟ لدى العديد من مستخدمي الإنترنت بالفعل أفكار، مثل نمذجة الموضوع واستخدام البيانات لتدريب GPT-3.
arXiv: مستودع ضخم للأوراق الأكاديمية
يجب على الطلاب في الأوساط البحثية العلمية والأكاديمية أن يكونوا على دراية بـ arXiv.
إنه موقع ويب يجمع المطبوعات المسبقة للأبحاث في الفيزياء والرياضيات وعلوم الكمبيوتر والأحياء. فهو لا يوفر منصة للباحثين العلميين "لحجز الأفكار" فحسب، بل يعمل أيضًا كمكتبة موارد ضخمة للجميع للبحث وقراءة الأوراق البحثية.
اعتبارًا من أكتوبر 2008، جمع موقع arXiv.org أكثر من 500 ألف نسخة مطبوعة مسبقًا؛ وبحلول نهاية عام 2014، وصلت مجموعتها إلى مليون؛اعتبارًا من أكتوبر 2016، تجاوزت إرساليات arXiv 10000 شهريًا.
تم تأسيس موقع arXiv لأول مرة على يد الفيزيائي بول جينسباغ في عام 1991. وكان الهدف الأصلي منه جمع مسودات أولية لأوراق الفيزياء، ثم توسع لاحقًا ليشمل مجالات أخرى مثل علم الفلك والرياضيات.
كان arXiv مستضافًا في الأصل في مختبر لوس ألاموس الوطني (LANL)، لذلك كان يُطلق عليه اسم "قاعدة بيانات LANL Preprint" في الأيام الأولى. في الوقت الحالي، يقع موقع arXiv في جامعة كورنيل ولديه مواقع مرآة في جميع أنحاء العالم. تمت إعادة تسمية الموقع إلى arXiv.org في عام 1999.
الآن، وبعبارات بسيطة، arXiv هو موقع يستخدم "لحجز مكان". ولمنع سرقة أفكارهم من قبل الآخرين قبل إدراج البحث، يقوم الباحثون بنشر مسوداتهم على arXiv لإثبات أصالتها.
مراجع:
https://www.kaggle.com/Cornell-University/arxiv?select=arxiv-metadata-oai-snapshot.json
https://zh.wikipedia.org/wiki/ArXiv
-- زيادة--








