Command Palette
Search for a command to run...
مؤتمر ICLR 2026 | انخفاض بمقدار 125 ضعفًا في المعلمات القابلة للتدريب لكل مهمة! تساعد طريقة Task Tokens الجديدة الذكاء المجسد على تحسين قدرته على التعامل مع المهام المعقدة.

في السنوات الأخيرة، حفّزت التطورات في مجال التعلم بالتقليد في التحكم بالروبوتات تطوير نماذج أساسية للسلوك قائمة على المحولات (BFMs)، والتي تُمكّن من التحكم متعدد الوسائط في الأنظمة الذكية الشبيهة بالبشر. تُولّد هذه النماذج حلولًا بناءً على أهداف أو إشارات عالية المستوى، مثل توجيه الروبوت إلى إحداثية محددة بناءً على وضعية حوضه. ورغم تفوق نماذج BFMs في توليد سلوكيات قوية باستخدام أمثلة غير مُدرّبة مسبقًا، إلا أنها غالبًا ما تتطلب هندسة مُعقّدة عند أداء مهام مُحدّدة، مما قد يؤدي إلى نتائج دون المستوى الأمثل.
وفي هذا السياق،اقترح فريق بحثي من معهد التخنيون - معهد إسرائيل للتكنولوجيا طريقة تسمى رموز المهام، والتي يمكنها تكييف BFM بشكل فعال مع مهام محددة مع الحفاظ على مرونتها.بالمقارنة مع الطرق الأساسية القياسية، يمكن للطريقة الجديدة أن تقلل عدد المعلمات القابلة للتدريب لكل مهمة بما يصل إلى 125 مرة وتحسن سرعة التقارب بما يصل إلى 6 مرات.
في الوقت نفسه، تحقق الباحثون من فعالية رموز المهام في مهام متنوعة (بما في ذلك سيناريوهات خارج نطاق التوزيع) وأثبتوا توافقها مع أساليب التوجيه الأخرى. تُظهر النتائج التجريبية أن رموز المهام تُقدم حلاً واعداً لتكييف نموذج إدارة السلوك (BFM) مع مهام تحكم محددة مع الحفاظ على قدرات التعميم.
تم قبول نتائج البحث ذات الصلة، بعنوان "رموز المهام: نهج مرن لتكييف نماذج أساس السلوك"، في مؤتمر ICLR 2026.
أبرز الأبحاث:
* التكيف الخاص بالمهمة: تعمل رموز المهام على تكييف MaskedMimic (GC-BFM) مع مهام محددة من خلال التحكم بالرموز، دون الحاجة إلى ضبط دقيق للنموذج الأساسي، مع الاحتفاظ بقدرته على التعلم بدون تدريب.
* نموذج التحكم الهجين: يُمكّن من التكامل السلس لمعلومات المستخدم عالية المستوى (مثل النصوص أو الأهداف المشتركة) مع تحسين التعلم القائم على المكافأة.
* الأداء والقدرة على التعميم: إنه قابل للمقارنة مع طريقة الضبط الدقيق الكاملة من حيث أداء المهمة، بينما يتفوق على الطرق الأخرى من حيث المتانة في مواجهة التغيرات في الديناميكيات البيئية (مثل الجاذبية والاحتكاك).

عنوان الورقة:
https://hyper.ai/papers/2503.22886
اطلع على المزيد من الأبحاث الرائدة في مجال الذكاء الاصطناعي:
مجموعة المهام: اختبار مدى عمومية النموذج في سلسلة من السيناريوهات شبه الواقعية.
صممت الدراسة مجموعة من المهام المعيارية لاختبار عمومية النموذج وقابليته للتكيف في مجموعة من سيناريوهات العالم الحقيقي تقريبًا، حيث أدخلت كل مهمة مستويات مختلفة من التعقيد في مشكلة التحكم.
الاتجاه (المشي في اتجاه محدد)
تتطلب هذه المهمة من الشخصية التحرك في اتجاه محدد لاختبار قدرات النموذج في التحكم الأساسي بالمشي ومحاذاة اتجاه الهدف. ويتمثل معيار النجاح في ألا يتجاوز انحراف سرعة النموذج البشري على طول اتجاه الهدف، خلال فترة القياس، 20% من سرعة الهدف.
توجيه
تتطلب هذه المهمة من نموذج بشري تحريكه في اتجاه محدد مع الحفاظ على حوضه مواجهًا لاتجاه معين. يختبر هذا قدرات تحكم أكثر دقة في الحركة ويُدخل سيناريوهات أكثر تعقيدًا. معيار النجاح هو أن يحافظ النموذج على انحراف سرعة في اتجاه الهدف لا يتجاوز 20%، بينما لا يتجاوز انحراف اتجاهه الكلي 45 درجة.
يصل
في هذه المهمة، يحتاج النموذج البشري إلى الوصول إلى نقطة إحداثيات محددة بيده اليمنى. يتطلب ذلك دقة عالية في الحركة. معيار النجاح هو أن تكون المسافة بين موضع اليد اليمنى وموضع الهدف أقل من 20 سنتيمترًا.
يضرب
تتطلب المهمة من الشخصية أولاً السير إلى جوار الهدف، ثم القيام بحركة لإسقاطه. لا يختبر هذا فقط القدرة الأساسية على المشي، بل يفحص أيضاً سلوكيات معقدة موجهة نحو المهمة، بما في ذلك التحكم في الوقت والإدراك المكاني. معيار النجاح هو إسقاط الهدف وإمالته في وضعية معينة، بحيث لا تتجاوز زاوية انحرافه 78 درجة تقريباً.
الوثب الطويل
يجب على الشخصية الركض داخل نفق عرضه متر واحد، ثم عبور خط بعد 20 متراً والقفز، ويجب ألا تلمس الأرض مرة أخرى بعد عبور خط الانطلاق. ويُعتبر معيار النجاح هو مسافة قفز تزيد عن 1.5 متر.
حل فعال لتكييف المهام يعتمد على بنية MaskedMimic
تعتمد الطريقة المقترحة في هذه الدراسة على "نماذج أساسية للسلوك المشروط بالهدف (GC-BFMs)" تُسمى MaskedMimic. على عكس طرق التعلم المعزز المشروط بالهدف التقليدية التي تعتمد على إشارات المكافأة للتعلم،يجمع MaskedMimic بين بنية Transformer ويقوم بعملية إخفاء عشوائية على الأهداف المستقبلية المستخدمة كرموز إدخال.وهذا يُمكّن من تعلم وإعادة إنتاج السلوك الشبيه بالسلوك البشري من خلال طرائق متعددة، مثل أوضاع المفاصل المستقبلية، والتعليمات النصية، والأشياء التفاعلية.
إن هذا المزيج من البنية وآليات التحكم يجعل MaskedMimic أساسًا مثاليًا لنهج Task Tokens؛ علاوة على ذلك، يعزز الباحثون قدراته بشكل أكبر من خلال تعلم الرموز الخاصة بالمهام لتحسين أداء المهام اللاحقة.
رموز المهام
كما هو موضح في الرسم البياني أدناه، يدمج Task Tokens ثلاثة أنواع من مصادر الإدخال:
* رمز الأولوية: مدخل اختياري يستخدم لإدخال افتراضات سلوكية محددة من قبل المستخدم عبر مطالبات نصية أو شروط مشتركة؛
* رمز المهمة: يتم إنشاؤه بواسطة مشفر مهمة مدرب يقوم بمعالجة الملاحظة المستهدفة الحالية؛
* رمز الحالة: يمثل الحالة الحالية للبيئة.
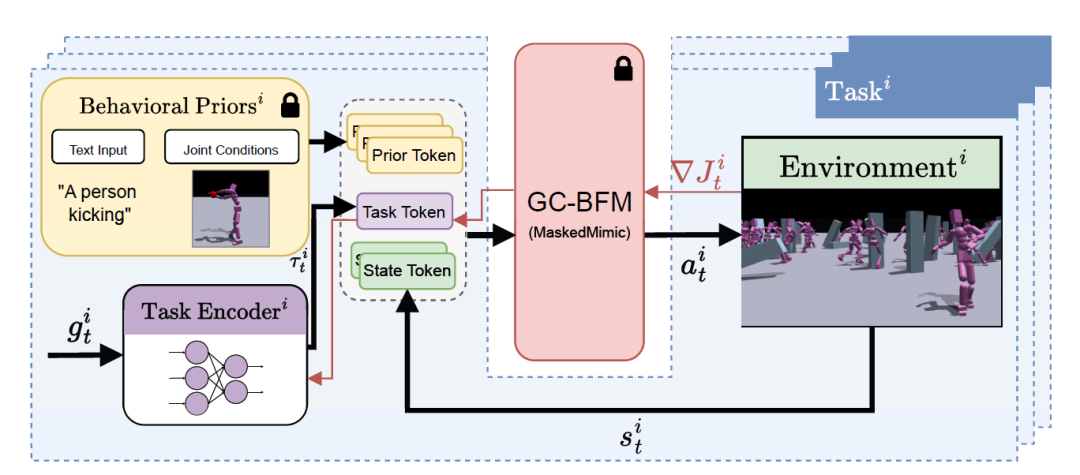
قام الباحثون بتدريب مُشفِّر مهام مُخصَّص لكل مهمة جديدة لتوليد رموز فريدة مُقابلة. تُجسِّد هذه الرموز المتطلبات والقيود الفريدة للسلوك المستهدف، مُقدِّمةً إشارات توجيهية مُوجزة ولكنها غنية بالمعلومات للنموذج الأساسي، مما يُمكِّنه من توليد مُخرجات تُلبِّي مُتطلبات المهمة المُحدَّدة مع الحفاظ على المُسبقات السلوكية العامة.
مُشفّر المهام
يستقبل مُشفّر المهمة بيانات تُحدد هدف المهمة الحالية. تُمثَّل هذه البيانات باستخدام العامل نفسه كإطار مرجعي، وتُخرج رمز مهمة. يختلف شكل البيانات باختلاف المهمة؛ فعلى سبيل المثال، في مهمة الانعطاف، تشمل البيانات اتجاه حركة الهدف، وتوجيهه، وسرعته المطلوبة.
بما أن MaskedMimic يتم تدريبه بناءً على أهداف الوضعية المستقبلية، فإن مشفر المهمة يتلقى أيضًا معلومات حسية للتوافق مع التمثيل المدرب مسبقًا، وبالتالي توليد إشارات هدف ذات معنى.
قام الباحثون بتطبيق مُشفِّر المهام كشبكة عصبية أمامية. يتم دمج مُخرَجها (أي رمز المهمة) مع رموز مُشفِّر أخرى في فضاء إدخال BFM لتشكيل "جملة" رمزية. في هذا الهيكل، تُعادل الرموز التي يُخرِجها مُشفِّر المهام "كلمات" مُتخصصة تُستخدم لتوجيه النموذج لإكمال مهمة مُحددة مع الحفاظ على طبيعية الأفعال.
تمرين
لتكييف مُشفِّر المهام مع المهام اللاحقة الجديدة، استخدم الباحثون خوارزمية تحسين السياسة التقريبية (PPO). أثناء التدريب، يتنبأ نموذج BFM بتوزيع احتمالية الفعل بناءً على مجموعة من رموز الإدخال، بما في ذلك رمز المهمة. ثم تُحسب دالة هدف PPO بناءً على المكافأة الخاصة بالمهمة واحتمالات الفعل التي يُخرجها نموذج BFM، وبالتالي الحصول على التدرجات المستخدمة لتحديث معلمات مُشفِّر المهام مع الحفاظ على ثبات نموذج BFM نفسه.
تكييف إدارة الأعمال بكفاءة وفعالية مع المهام المحددة
قام الباحثون بتقييم فعالية طريقة رموز المهام من خلال سلسلة من التجارب الشاملة، والتحقق من أدائها وقابليتها للتطبيق في أربعة جوانب رئيسية، ومقارنتها بالعديد من الطرق الأساسية المنافسة، بما في ذلك:
التعلم المعزز الخالص: يستخدم فقط استراتيجية تدريب PPO ولا يعتمد على أي نموذج أساسي؛
* ضبط دقيق لنموذج MaskedMimic: يعمل على تحسين نموذج MaskedMimic بالكامل باستخدام إشارة المكافأة (بدون تجميد المعلمات)؛
* MaskedMimic (حالة المفصل فقط): MaskedMimic الأصلي، الذي يستخدم فقط حالات المفصل كآلية إشارة؛
* نبض: نهج هرمي يعيد استخدام مساحة المهارات الكامنة في بيانات التقاط الحركة؛
* AMP: يستخدم أداة تمييز لتحسين أداء المهمة مع ضمان جودة العمل.
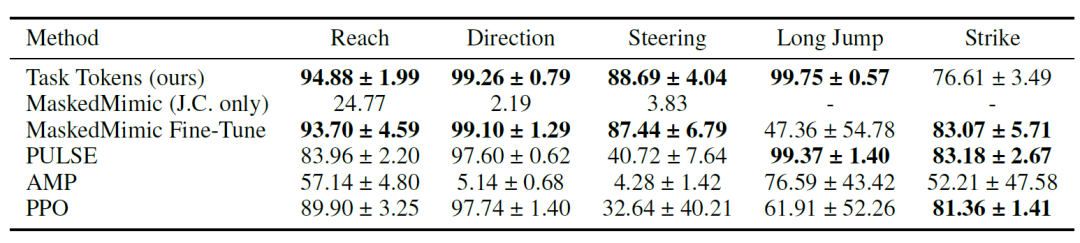
قدرة التكيف مع المهام
أظهر الباحثون أولاً أن رموز المهام قادرة على تكييف MaskedMimic بفعالية مع المهام اللاحقة؛ وتُعرض النتائج الرقمية في الجدول أدناه. وتشير النتائج إلى أن...حققت رموز المهام درجات عالية في معظم البيئات، حيث سجلت PULSE و MaskedMimic Fine-Tune و PureRL درجات أعلى في مهمة Strike.
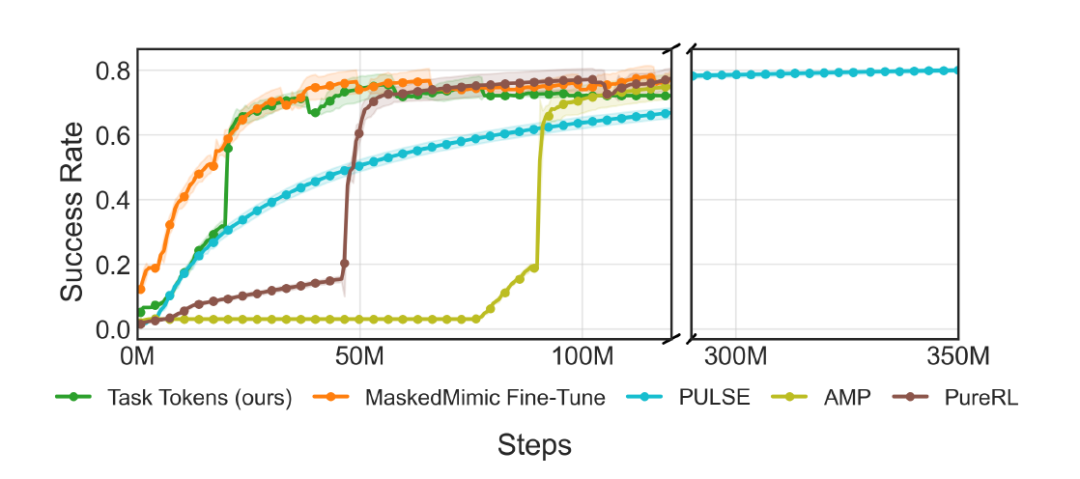
علاوة على ذلك، يوضح الشكل أدناه منحنى معدل النجاح أثناء التدريب. يُلاحظ أن نموذج Task Tokens يتقارب في حوالي 50 مليون خطوة، بينما يتطلب نموذج PULSE حوالي 300 مليون خطوة لتحقيق الأداء نفسه.
ولتحقيق النتائج المذكورة أعلاه،لا تتطلب رموز المهام سوى تدريب مشفر واحد مع ما يقرب من 200000 (~200 ألف) معلمة.يتطلب كل من PULSE و MaskedMimic Fine-Tune 9.3 مليون (9.3 مليون) و 25 مليون (25 مليون) مُعامل على التوالي، أي ما يعادل 46.5 ضعفًا و 125 ضعفًا تقريبًا. وتُعد هذه الكفاءة بالغة الأهمية في التطبيقات العملية، نظرًا للتكلفة الباهظة لتدريب النماذج واسعة النطاق.
تُظهر هذه النتائج أن رموز المهام يمكنها تكييف النماذج السلوكية الأساسية مثل MaskedMimic بكفاءة وفعالية مع المهام الجديدة وغير المرئية.
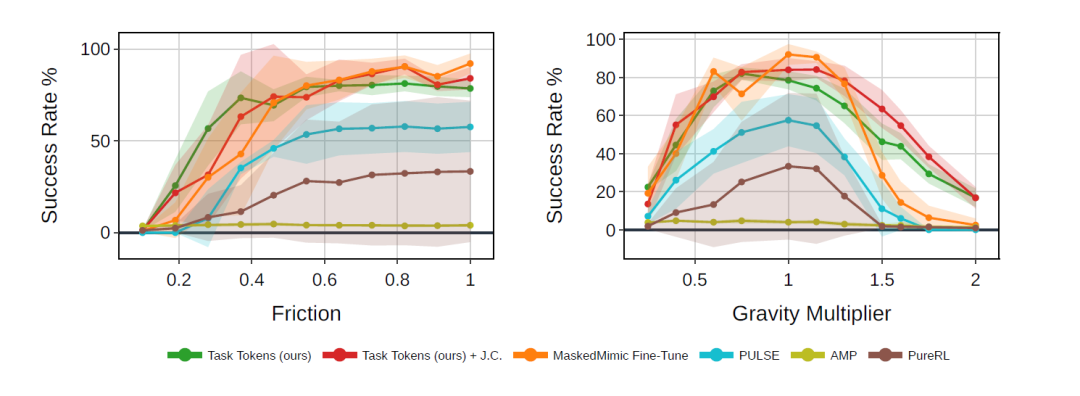
القدرة على التعميم خارج نطاق التوزيع (OOD)
أجرى الباحثون تجارب مقارنة في ظل ظروف اضطراب خارج التوزيع (OOD)، والتي لم تحدث أثناء تدريب BFM الأصلي و Task Tokens، ونظروا بشكل أساسي في نوعين من التغييرات: الجاذبية والاحتكاك الأرضي.
تُظهر النتائج في الشكل أدناه أنه بمساعدة BFM،تُظهر رموز المهام متانة محسّنة بشكل كبير في سيناريوهات جديدة وغير مسبوقة.أولًا، في ظل الظروف الأساسية (بدون أي تشويش)، يُؤدي برنامج Task Tokens أداءً مطابقًا تقريبًا لبرنامج MaskedMimic المُحسَّن بالكامل، ويتفوق على جميع الطرق الأساسية الأخرى. لاحقًا، يتجاوز أداؤه الطرق الأساسية بشكل ملحوظ مع ازدياد قوة التشويش. والجدير بالذكر أن برنامج Task Tokens يحافظ على معدل نجاح أعلى بكثير حتى في ظل ظروف احتكاك منخفضة للغاية (مثل 0.4×) وجاذبية عالية (مثل 1.5×).
دراسة بشرية
يوضح الجدول أدناه النسبة المئوية لرموز المهام المختارة باعتبارها الإجراء "الأكثر إنسانية" مقارنةً بكل طريقة مقارنة. وتشير النتائج إلى أن...تتفوق رموز المهام بشكل كبير على MaskedMimic (JC فقط) و MaskedMimic Fine-Tune.يشير هذا إلى أن الشروط التي صممها المستخدم لها خصائص معينة خارج التوزيع لنموذج MaskedMimic الأساسي، وأن رموز المهام هي طريقة أكثر فعالية للتكيف مع جودة العمل مقارنة بالضبط الدقيق.
علاوة على ذلك، يمكن ملاحظة أنه على الرغم من أن Task Tokens متفوقة من حيث سرعة التقارب وحجم المعلمات وأداء المهمة، إلا أن PULSE يحقق نتائج أعلى من حيث "تشابه الحركة مع الإنسان".
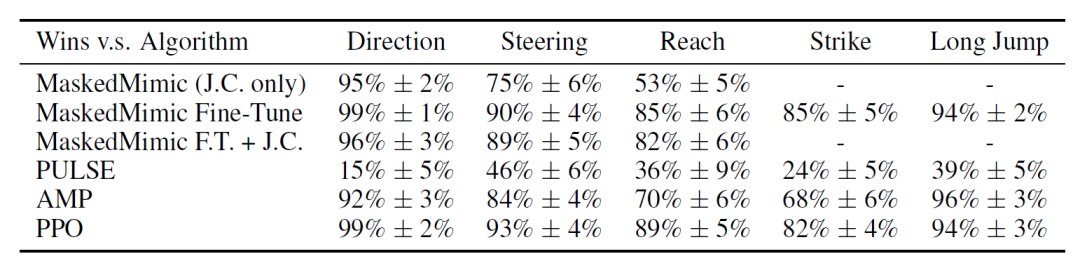
بناءً على النتائج المذكورة أعلاه، يمكن استنتاج أن رموز المهام تحقق توازناً جيداً بين الكفاءة وجودة العمل والمتانة.
تأثير التنبيه متعدد الوسائط
وأخيراً، استكشف الباحثون التأثيرات التآزرية لرموز المهام مع أساليب التحفيز الأخرى، مما يدل على توافقها ومرونتها الجيدة.
في مهمة تحديد الاتجاه، تشجع وظيفة المكافأة العامل على التحرك في الاتجاه الصحيح فقط، دون مراعاة وضعية الجسم الشبيهة بالإنسان. لذلك، قد تتقارب السياسة إلى "المشي للخلف". ورغم أن هذا السلوك يحقق مكافآت أعلى ونسبة نجاح أكبر، إلا أنه ليس ما هو متوقع.
توضح الصورة أدناه إدخال معلومات مسبقة مصممة بشكل مصطنع (مثل القيود المفروضة على ارتفاع واتجاه هدف الرأس).يمكن أن تتقارب عملية التدريب إلى نمط حركة "المشي في وضع مستقيم".

في مهمة الضربة، يحتاج العامل إلى إصابة الهدف، ومن السلوكيات الشائعة التي تظهر أن يتراجع العامل نحو الهدف ثم يقوم بحركة دائرية سريعة، ليصيب الهدف بالدوران حول نفسه. يوضح الشكل أدناه دمج الطريقتين السابقتين.
أولاً، باستخدام شروط توجيه مشابهة لتلك المستخدمة في مهمة تحديد الاتجاه، يُجبر العامل على مواجهة الهدف دائمًا أثناء الحركة. ثم، عندما يقترب من الهدف، يُعرض النص "شخص يقوم بركلة" لتوجيه العامل لاستخدام قدمه لإتمام حركة الركل.

لاحظ الباحثون، على وجه الخصوص، أن ضبط النموذج بأكمله بدقة يؤدي إلى مشكلة النسيان الكارثي المعروفة، مما يُضعف قدرة النموذج على الاحتفاظ بالإشارات متعددة الوسائط ودمجها. في المقابل، تحافظ رموز المهام، من خلال تجميد النموذج الأساسي، على قدراتها في التوجيه المُدرَّبة مسبقًا، مما يسمح للسلوكيات المُتعلَّمة بالاندماج بشكل أكثر اتساقًا مع السلوكيات التي يُحدِّدها الإنسان.
خاتمة
تعتمد التجارب الحالية بشكل أساسي على بنية MaskedMimic؛ ويتطلب العمل المستقبلي التحقق من إمكانية تعميم هذه الطريقة ضمن بنية GC-BFM أوسع. وبينما لا يزال تصميم المكافآت والملاحظات المتعلقة بالمهام يعتمد على خبرة الخبراء، يمكن للبحوث المستقبلية استكشاف التصميم (شبه) الآلي لتسهيل عملية التعلم. ويتمثل أحد التوجهات الرئيسية في نقل الاستراتيجيات المُكيَّفة مع Task Tokens إلى أنظمة الروبوتات في العالم الحقيقي، ومعالجة مشكلة الانتقال من المحاكاة إلى الواقع، والتوسع ليشمل مهامًا معقدة في العالم الحقيقي تتطلب اتخاذ قرارات رفيعة المستوى، تتجاوز مجرد محاكاة الرسوم المتحركة.
أخيرًا، قد يؤدي استكشاف بنى ترميز مهام أكثر تعقيدًا (تتجاوز بنية الشبكة الأمامية الحالية) إلى مزيد من التحسينات في الأداء. وسيساهم حل هذه المشكلات في تحسين إطار عمل رموز المهام، ودفع عجلة تطوير وكلاء ذكاء اصطناعي بشريين أكثر تنوعًا وقابلية للتكيف وكفاءة.
مراجع:
https://openreview.net/forum?id=6T3wJQhvc3
https://arxiv.org/pdf/2503.22886








