Command Palette
Search for a command to run...
New Interpretation of the Millennium Code: DeepMind Develops Ithaca to Decipher Greek Inscriptions

Inscriptions and steles are the embodiment of the thoughts, culture and language of past civilizations. To decipher the codes of thousands of years ago, epigraphers need to complete three major tasks: text restoration, time attribution and geographical attribution.
The mainstream research method is "string matching", which is to match inscriptions with similar fonts based on memory or query corpus, which leads to confusion and misjudgment of results.
To this end, DeepMind and the University of Venice Foscari jointly developed Ithaca, which uses AI to help human scholars decipher Greek inscriptions.
Author | Add Zero
Editor | Xuecai, Sanyang
Epigraphy is the study of epigraphic inscriptions, steles and ancient inscriptions, which connect the thoughts, culture and language of past civilizations. Currently, the academic community is facing an important question: how to study and understand this heritage in depth?
Generally speaking, interpreting inscriptions requires epigraphers to complete the following three basic tasks:
- Text restoration: supplement missing parts of the text;
- Chronological attribution: determining when an inscription was written;
- Geographical attribution: Determine the original location where the inscription was written.
To accomplish these tasks, epigraphers need to combine context and existing corpora and conduct a large number of comparative studies. Although the emergence of digital corpora can reduce the burden on researchers to a certain extent, the string matching method they adopt often leads to confusion and misjudgment of results. At the same time, due to their age, many inscriptions are damaged or lost, making the task more complicated.

Inscription repair icon
AI is good at discovering and applying complex statistical patterns to analyze large amounts of data that are difficult for humans to process.Therefore, researchers at DeepMind and Ca' Foscari University of Venice jointly developed Ithaca, which aims to assist epigraphers in the work of text restoration, chronological attribution, and geographical attribution.
Experiments have confirmed that the Ithaca text restoration work has an accuracy rate of 62%, the time attribution error is within 30 years, the regional attribution accuracy rate is 71%, and it has good synergy. The relevant paper has been published in "Nature".

Related results were published in Nature
Get the paper:
https://www.nature.com/articles/s41586-022-04448-z
Ithaca's relevant code has been open sourced on the GitHub platform, and epigraphers can also use the public interface to conduct research.
Source code: https://GitHub.com/deepmind/Ithaca
Public interface: https://Ithaca.deepmind.com
Experimental procedures
Dataset
Machine Operable Inscription Collection I.PHI
The researchers conducted their research based on the Packard Humanities Institute's searchable public dataset of Greek inscriptions (PHI).
Note: PHI stands for The Packard Humanities Institute's Searchable Greek Inscriptions public dataset
To facilitate machine operation, the researchers filtered the text in PHI, assigned digital IDs, corresponding annotated locations and time information to the selected texts, and finally obtained the I.PHI dataset.
I.PHI dataset is currently the largest machine-operable inscription dataset, containing 78,608 inscriptions.

I. PHI Dataset Example
Algorithm training:Training for 3 major tasks
1. Text inpainting: Use the cross entropy loss function to mask part of the input text and train the Ithaca model to predict the masked characters;
2. Time attribution: Ithaca discretized the period around 800 BC into time periods with equal probability at intervals of 10 years, called the target probability distribution. The Kullback-Leibler divergence was used to minimize the difference between the predicted probability distribution and the target probability distribution.
3. Regional attribution: Using the cross entropy loss function, the regional region metadata is used as the target label, and the label smoothing technique with a smoothing coefficient of 10% is applied to avoid overfitting.
Based on this, Ithaca was trained for a week on 128 TPU v4 pods on Google Cloud Platform with a batch size of 8,192 texts and a LAMB optimizer with a 3 × 10-4 The learning rate optimizes the Ithaca parameters.
Model structure:The Ithaca model consists of 4 parts:
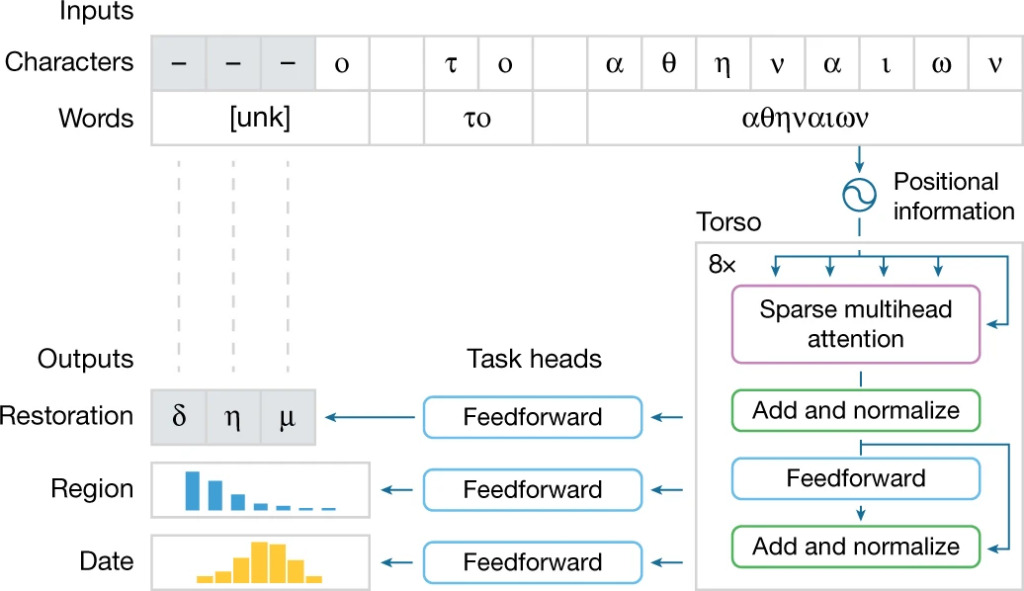
Ithaca model task processing flow
The structure of the Ithaca model can be summarized into the following four parts:
1. Input: The input text is processed as both characters and words, ensuring that Ithaca can understand individual characters and integrate them into words for contextual understanding. Unknown and damaged words are replaced with the special symbol "unk";
2. Torso: Ithaca's torso adopts a stacked Transformer neural network architecture, which uses an attention mechanism to measure the impact of input characters and words on the model's decision process.
In the body part, Ithaca combines the input text with the position information and normalizes it into a sequence of length equal to the number of input characters. Each item in this sequence is a 2,048-dimensional embedding vector. This sequence is transmitted to three different task heads;
3. Task heads: Ithaca has 3 different task heads, each head consists of a shallow feedforward neural network, specializing in text restoration, temporal attribution, and regional attribution tasks.
4. Outputs: The three task heads output corresponding results respectively.
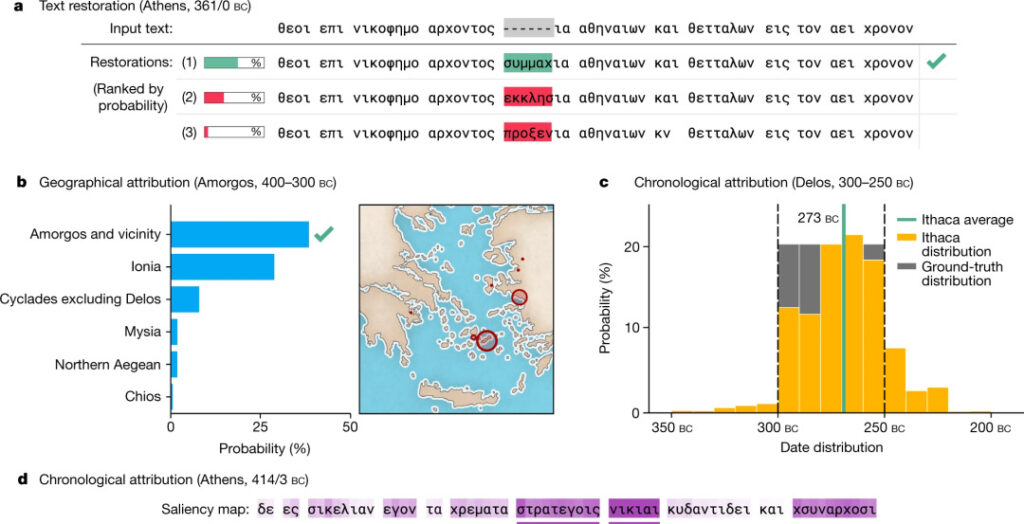
Ithaca output
- Text repair: Ithaca predicts 3 missing characters and provides a set of top 20 decoding predictions ranked by probability (a above);
- Regional attribution: Ithaca divides the input text into 84 regions and uses maps and bar charts to intuitively implement a possible regional prediction ranking table (Figure b above);
- Time Attribution: To expand the interpretability of time attribution tasks, Ithaca dates back to 800 BC to 800 AD and predicts a categorical distribution of dates instead of outputting a single date value (Figure 2c above).
Model training results
Comprehensive comparison:Ithaca has superior performance
* 4 contrast mechanisms
1. Ancient historian: Anthropologists use the training set to find similarities in the texts and compare the results with Ithaca;
2. Ancient historian and Ithaca: Ithaca provides 20 possible restorations for epigraphers and assesses the synergy between Ithaca and anthropologists;
3. Pythia: a sequence-to-sequence recurrent neural network for text inpainting tasks, evaluating the text inpainting performance of Ithaca;
4. Onomastics: The researchers used the known distribution of Greek personal names in time and space to complete the temporal and regional attribution of a set of texts and evaluate the temporal and regional attribution performance of Ithaca.
* 3 major evaluation indicators
1. Character error rate (CER): evaluates text repair tasks and calculates the normalized difference between the highest predicted repair sequence and the target sequence;
2. Top-k accuracy: evaluates text restoration or regional attribution tasks, and calculates the proportion of the top k results with the highest probability in the prediction results that contain correct labels. The top 1 accuracy is often used;
3. distance metric (Methods): evaluates the temporal attribution task and calculates the distance in years between the mean of the predicted distribution and the ground-truth interval.
* Experimental results
1. Text repair

Text repair tasks
a: original inscription;
b: Rhodes-Osborne restored inscription;
c: Pythia restoration, which has 74 mismatches with the Rhodes-Osborne version;
d: Ithaca restoration, which has 45 mismatches with the Rhodes-Osborne version;
The correct repaired parts are shown in green in the figure, and the errors are highlighted in red.
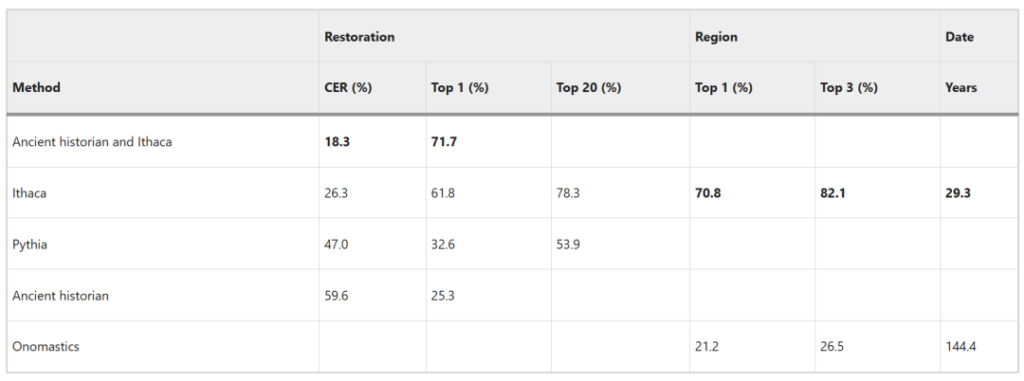
The original inscription (IG II² 116) is missing 378 characters. Based on the restoration completed by Rhodes-Osborne in 2003 (Figure b), Ithaca's CER is 26.3% and the top 1 accuracy reaches 61.8%.
Compared to Epigraphy, Ithaca has a CER 2.2 times lower. Ithaca’s top 20 prediction accuracy is 78.3%, which is 1.5 times higher than Pythia.
2. Geographical attribution
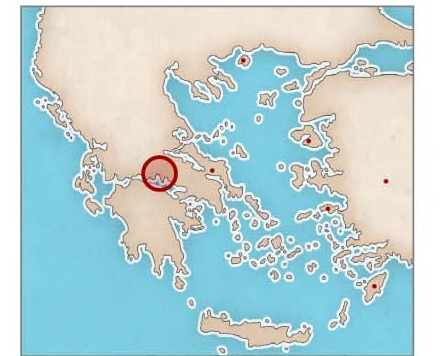
Geographical attribution tasks
In the region attribution task, Ithaca achieved a top 1 accuracy of 70.8% and a top 3 accuracy of 82.1%.The above image shows that Ithaca correctly attributed the manumission inscription to the Delphi region.
3. Time Attribution
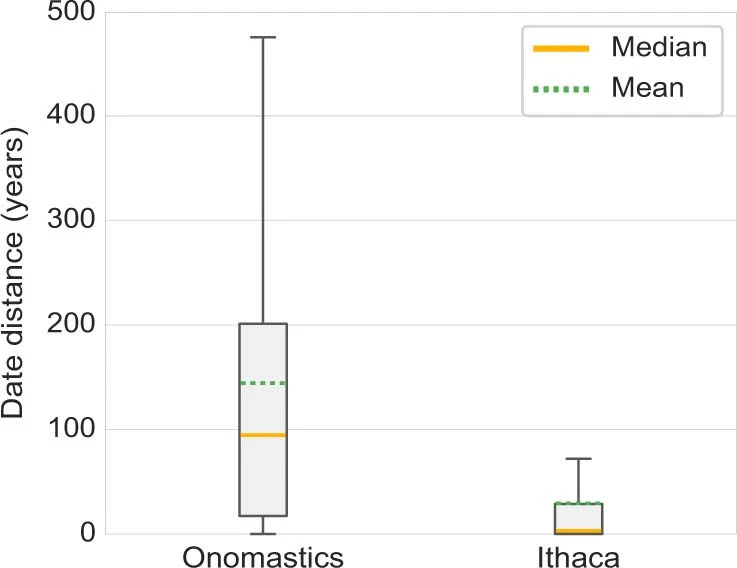
Time attribution task
For the time attribution task, the average prediction of human experts was 144.4 years, and the median was 94.5 years, while Ithaca's prediction had an average difference of 29.3 years from the ground-truth interval, and a median difference of only 3 years.
Combining Ithaca's performance in the three tasks, the results are summarized as follows:
Compared with human experts and Pythia, Ithaca demonstrates superior performance in all three tasks.
When human experts collaborated with Ithaca, they achieved a CER of 18.3% and a top 1 accuracy of 71.7%., showing a 3.2-fold and 2.8-fold improvement over the epigraphers working alone, and a significant improvement over Ithaca completing the task alone.Demonstrating Ithaca's superior synergy.
Comparison of Ithaca’s experimental results
Time Attribution:Ithaca resolve disputes
The dating of some of the inscriptions has been controversial. The traditional sigma dating criterion used for dating cannot guarantee accuracy, and epigraphers cannot determine whether these inscriptions were made before or after 446/5 BC.
The inscription shown below was traditionally dated to 446/5 BC, but has recently been re-dated to 424/3 BC.

A controversial inscription (partial)
This controversial set of inscriptions exists in the I.PHI dataset, and the time attribution results of Ithaca overturn the traditional historical interpretation based on the sigma dating standard, and the difference with the newly discovered basic facts is an average of 5 years.
This proves thatIthaca can help historians narrow date ranges and increase the precision of their attribution of historical events.
AI and humans: 1 + 1 > 2?
The result output part of Ithaca is very interesting. It does not output a single answer, but gives multiple possible results for researchers to choose from.
This is worth learning from for other AI developers and users. Instead of relying on AI output, it is better to use AI to "explore the way", eliminate some wrong answers, and expand the depth and breadth of independent thinking.
By combining the computational power of AI with the creativity and deep thinking of humans, Ithaca helps us pioneer a new paradigm for working hand in hand with AI.
In the future, we expect AI and human scholars to work together to achieve the goal of "1+1 > 2".
References:
https://www.nature.com/articles/s41586-022-04448-z
https://www.nature.com/articles/d41586-023-03212-1
-- over--








