HyperAI
Command Palette
Search for a command to run...
Papers
최신 AI 트렌드를 파악할 수 있도록 매일 업데이트되는 최첨단 AI 연구 논문

인간 피드백을 통한 강화 학습을 활용한 유용하고 해로우지 않은 어시스턴트 훈련

UQ: 미해결 질문에 대한 언어 모델 평가

























인간 피드백을 통한 강화 학습을 활용한 유용하고 해로우지 않은 어시스턴트 훈련
UQ: 미해결 질문에 대한 언어 모델 평가
CARJAN: AJAN을 활용한 에이전트 기반 교통 시나리오 생성 및 시뮬레이션
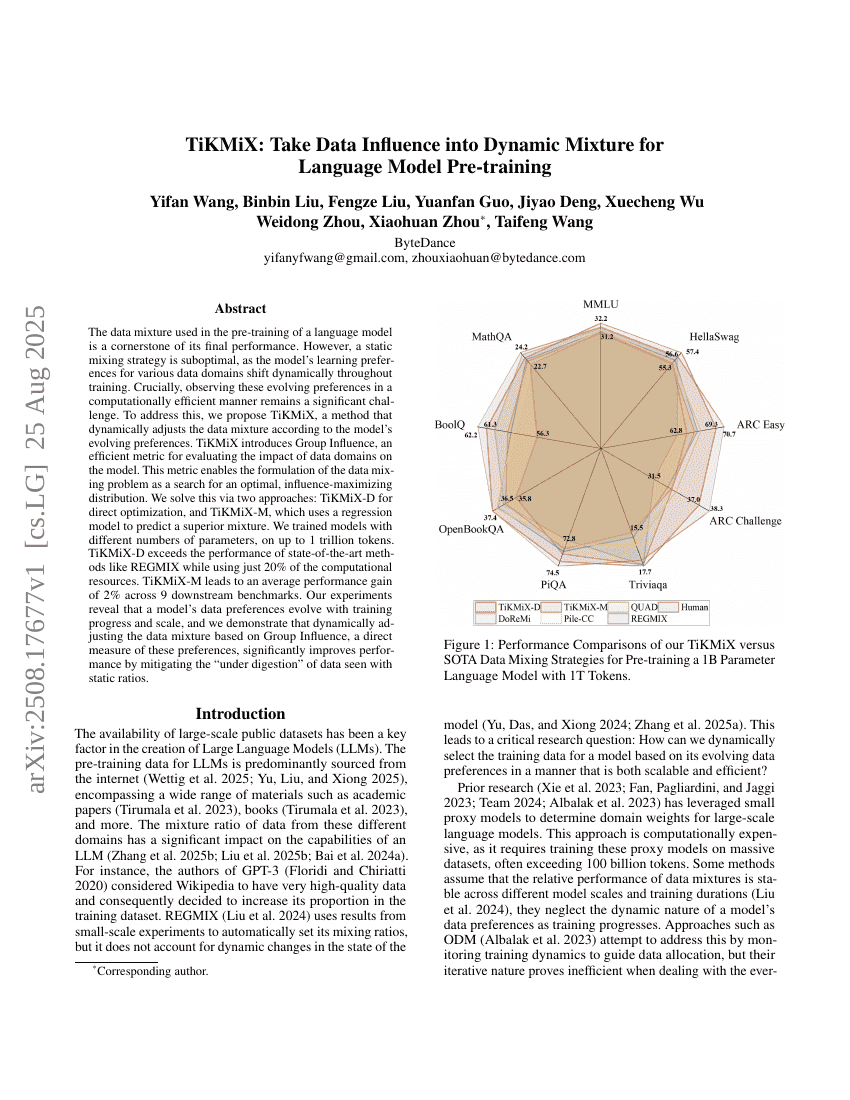
TiKMiX: 동적 믹스처에 데이터 영향력을 반영한 언어 모델 사전 훈련
TalkVid: 음성 주도 대화 헤드 합성용 대규모 다변화 데이터셋
Droplet3D: 비디오에서 도출한 일상 지식 사전이 3D 생성을 촉진한다
A.S.E: 인공지능 생성 코드의 보안 평가를 위한 레포지터리 수준 벤치마크
에임바디드원비전: 일반 로봇 제어를 위한 병렬화된 시각-텍스트-행동 사전학습
R-4B: 다목적 자동 사고 능력의 유도를 통한 MLLMs의 이중 모드 안내 및 강화 학습
작은 언어 모델에서 창의적 글쓰기 자극하기: LLM-as-a-Judge와 다중 에이전트 개선 보상 비교
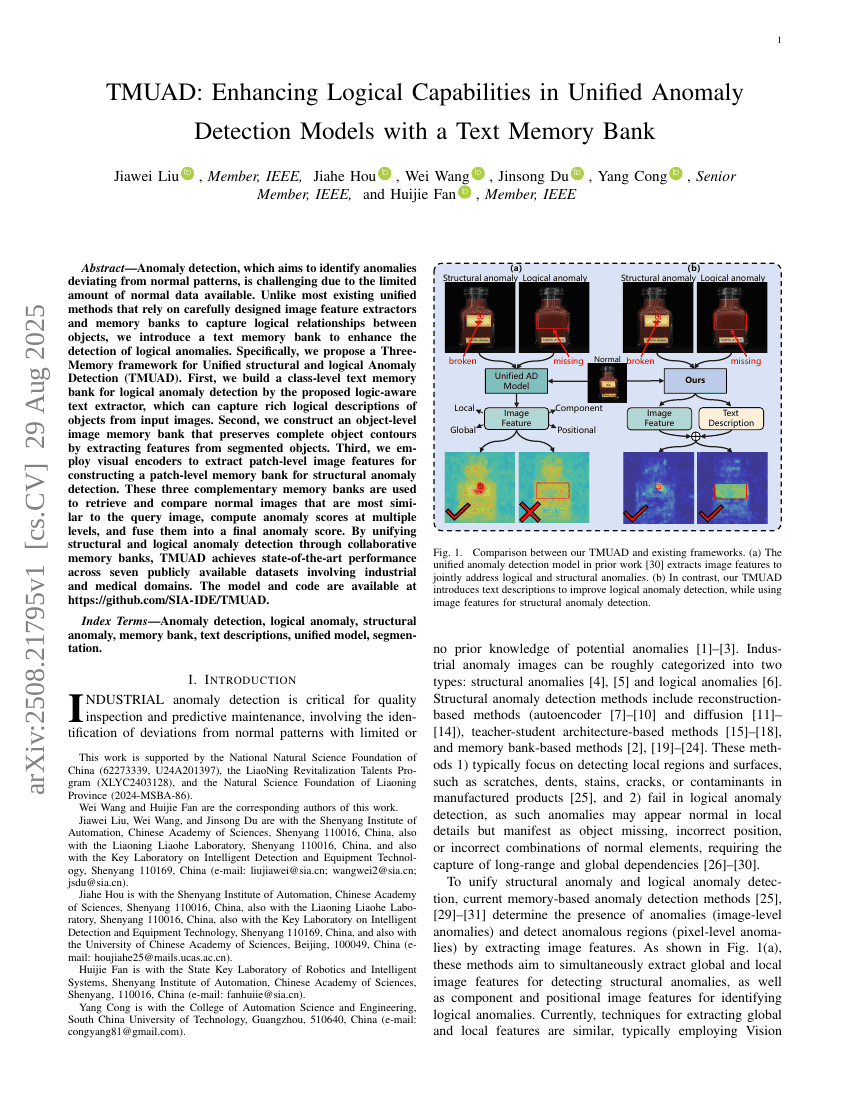
TMUAD: 텍스트 메모리 벙크를 활용한 통합 이상 탐지 모델의 논리적 능력 향상
사고 과정 역학 분석: 능동적 안내인가, 부정확한 사후 정당화인가?
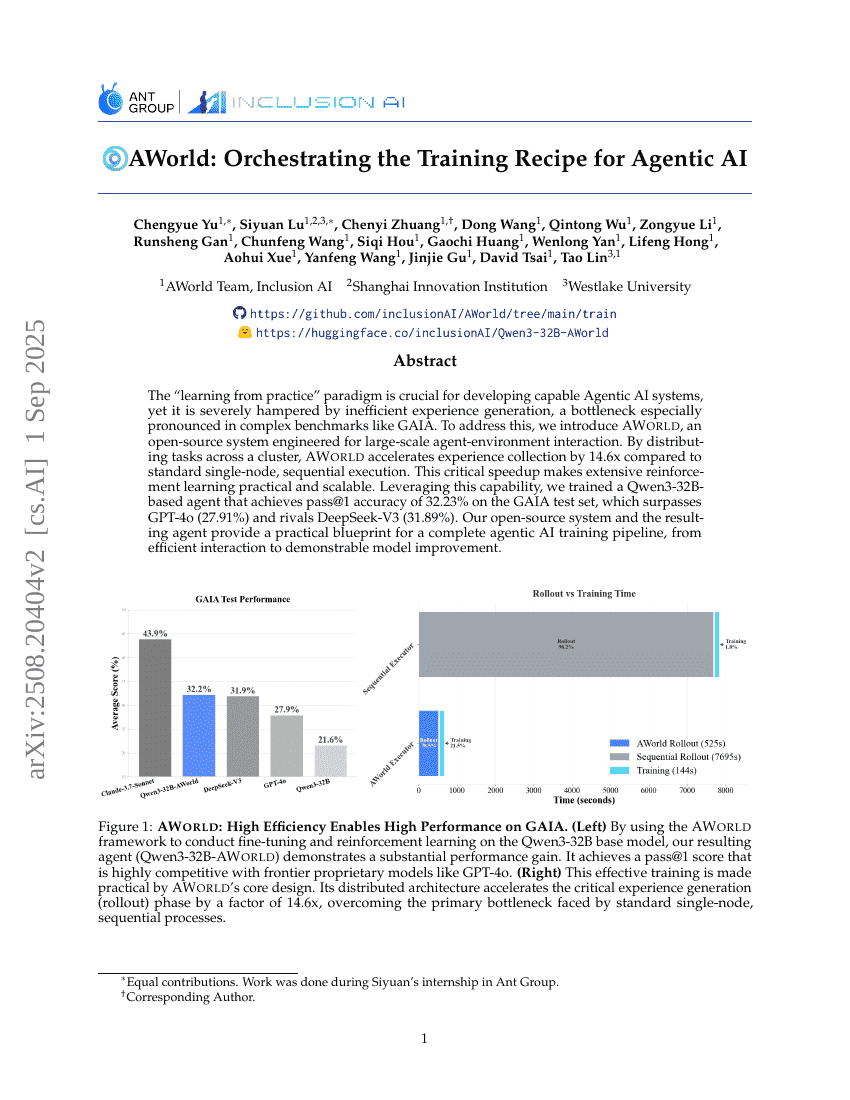
AWorld: 에이전트형 AI를 위한 훈련 조리법의 조율
MCP-Bench: MCP 서버를 통한 복잡한 실세계 작업을 수행하는 도구 사용 LLM 에이전트 평가를 위한 벤치마크 도구
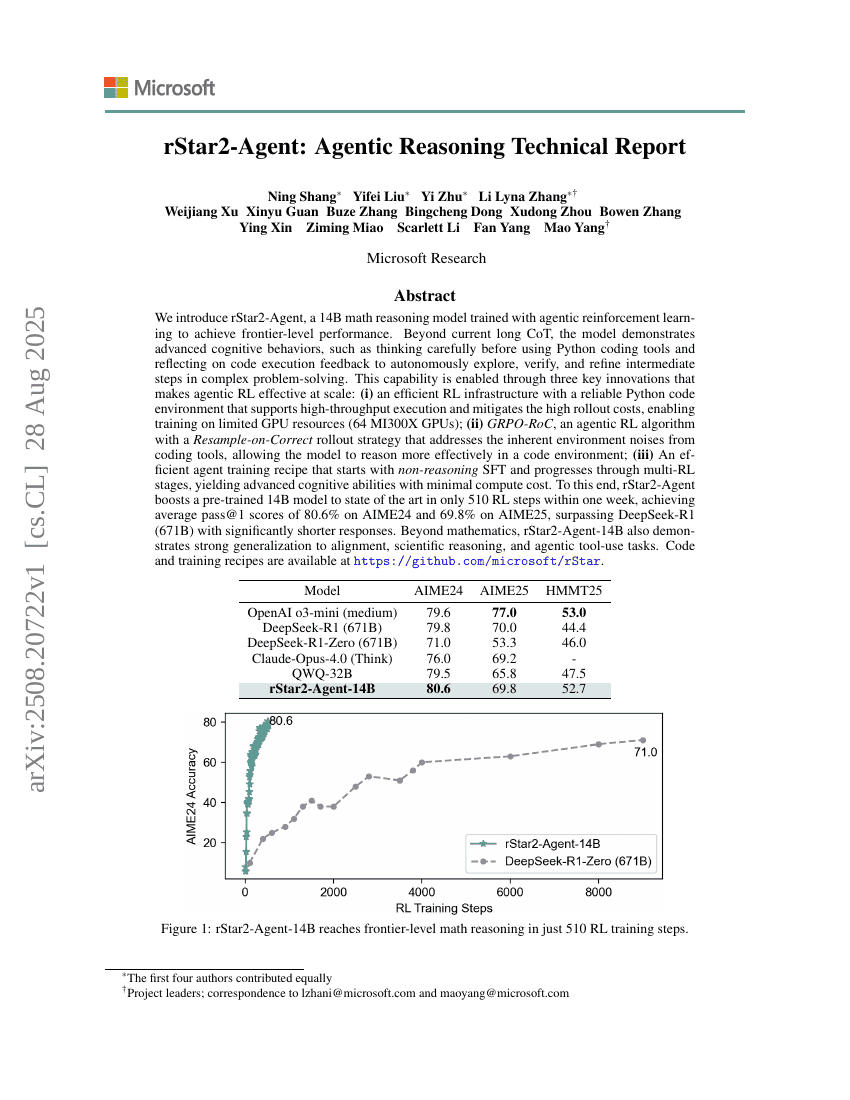
rStar2-Agent: 에이전트형 추론 기술 보고서
Pref-GRPO: 쌍별 선호 보상 기반 GRPO를 활용한 안정적인 텍스트-이미지 강화 학습
모바일클립2: 다중 모달 강화 학습 개선
AI-AI 미학적 협업: 명시적 상징의식과 부상하는 문법 발달을 통한 협업
시선을 심장으로: rPPG 및 건강 생체지표 추정을 위한 다중 시점 영상 데이터셋
앞으로 올 토큰의 순서를 예측하는 것은 언어 모델링을 향상시킨다
MIDAS: 실시간 자기회귀 영상 생성을 통한 다중모달 상호작용 디지털 인간 합성
이산 확산 VLA: 시각-언어-행동 정책에서 행동 해석에 이산 확산 도입하기
이론 분해를 통한 자기 보상 시각-언어 모델
전사 이상: 음성인식에서의 기계적 해석 가능성
CODA: 두뇌를 조율하는 인공지능: 분리된 강화학습을 통한 대뇌와 소뇌 기반의 이중 뇌 컴퓨터 사용 에이전트
WebSight: 강건한 웹 에이전트를 위한 비전 우선 아키텍처
UltraMemV2: 1200억 파라미터까지 확장되는 메모리 네트워크 및 우수한 장문맥 학습 성능
헤르메스 4 기술 보고서
오미니휴먼-1.5: 인지 시뮬레이션을 통한 아바타에 능동적 사고 심화
VoxHammer: 본질적인 3차원 공간에서의 훈련 없이 정밀하고 일관성 있는 3차원 편집
CMPhysBench: 응집물리에서 대규모 언어 모델 평가를 위한 벤치마크
TreePO: 히우리스틱 트리 기반 모델링을 통한 정책 최적화와 효과성, 추론 효율성 간 격차 해소
CARJAN: AJAN을 활용한 에이전트 기반 교통 시나리오 생성 및 시뮬레이션
TiKMiX: 동적 믹스처에 데이터 영향력을 반영한 언어 모델 사전 훈련
TalkVid: 음성 주도 대화 헤드 합성용 대규모 다변화 데이터셋
Droplet3D: 비디오에서 도출한 일상 지식 사전이 3D 생성을 촉진한다
A.S.E: 인공지능 생성 코드의 보안 평가를 위한 레포지터리 수준 벤치마크
에임바디드원비전: 일반 로봇 제어를 위한 병렬화된 시각-텍스트-행동 사전학습
R-4B: 다목적 자동 사고 능력의 유도를 통한 MLLMs의 이중 모드 안내 및 강화 학습
작은 언어 모델에서 창의적 글쓰기 자극하기: LLM-as-a-Judge와 다중 에이전트 개선 보상 비교
TMUAD: 텍스트 메모리 벙크를 활용한 통합 이상 탐지 모델의 논리적 능력 향상
사고 과정 역학 분석: 능동적 안내인가, 부정확한 사후 정당화인가?
AWorld: 에이전트형 AI를 위한 훈련 조리법의 조율
MCP-Bench: MCP 서버를 통한 복잡한 실세계 작업을 수행하는 도구 사용 LLM 에이전트 평가를 위한 벤치마크 도구
rStar2-Agent: 에이전트형 추론 기술 보고서
Pref-GRPO: 쌍별 선호 보상 기반 GRPO를 활용한 안정적인 텍스트-이미지 강화 학습
모바일클립2: 다중 모달 강화 학습 개선
AI-AI 미학적 협업: 명시적 상징의식과 부상하는 문법 발달을 통한 협업
시선을 심장으로: rPPG 및 건강 생체지표 추정을 위한 다중 시점 영상 데이터셋
앞으로 올 토큰의 순서를 예측하는 것은 언어 모델링을 향상시킨다
MIDAS: 실시간 자기회귀 영상 생성을 통한 다중모달 상호작용 디지털 인간 합성
이산 확산 VLA: 시각-언어-행동 정책에서 행동 해석에 이산 확산 도입하기
이론 분해를 통한 자기 보상 시각-언어 모델
전사 이상: 음성인식에서의 기계적 해석 가능성
CODA: 두뇌를 조율하는 인공지능: 분리된 강화학습을 통한 대뇌와 소뇌 기반의 이중 뇌 컴퓨터 사용 에이전트
WebSight: 강건한 웹 에이전트를 위한 비전 우선 아키텍처
UltraMemV2: 1200억 파라미터까지 확장되는 메모리 네트워크 및 우수한 장문맥 학습 성능
헤르메스 4 기술 보고서
오미니휴먼-1.5: 인지 시뮬레이션을 통한 아바타에 능동적 사고 심화
VoxHammer: 본질적인 3차원 공간에서의 훈련 없이 정밀하고 일관성 있는 3차원 편집
CMPhysBench: 응집물리에서 대규모 언어 모델 평가를 위한 벤치마크
TreePO: 히우리스틱 트리 기반 모델링을 통한 정책 최적화와 효과성, 추론 효율성 간 격차 해소