HyperAI
Command Palette
Search for a command to run...
Papers
최신 AI 트렌드를 파악할 수 있도록 매일 업데이트되는 최첨단 AI 연구 논문

VStyle: 말하는 지시를 활용한 음성 스타일 적응을 위한 벤치마크

한래그: 히우리스틱 정확한 노이즈 저항성 리트리벌 보강형 생성을 통한 다단계 질문 응답























VStyle: 말하는 지시를 활용한 음성 스타일 적응을 위한 벤치마크
한래그: 히우리스틱 정확한 노이즈 저항성 리트리벌 보강형 생성을 통한 다단계 질문 응답
InfGen: 확장 가능한 이미지 합성을 위한 해상도 무관한 패러다임
X-Part: 높은 정밀도와 구조적 일관성을 갖춘 형태 분해
감소하는 수익의 환상: 대규모 언어 모델에서 장기적 실행 측정하기
IntrEx: 교육 대화의 참여를 모델링하기 위한 데이터셋
Youtu-GraphRAG: 그래프 검색 증강 복합 추론을 위한 수직 통합 에이전트
SceneSplat: 시각-언어 사전학습을 통한 가우시안 스플래터링 기반의 장면 이해
가상 에이전트 경제
시각 언어 모델에서 시각적 기반 이해를 위한 탐구
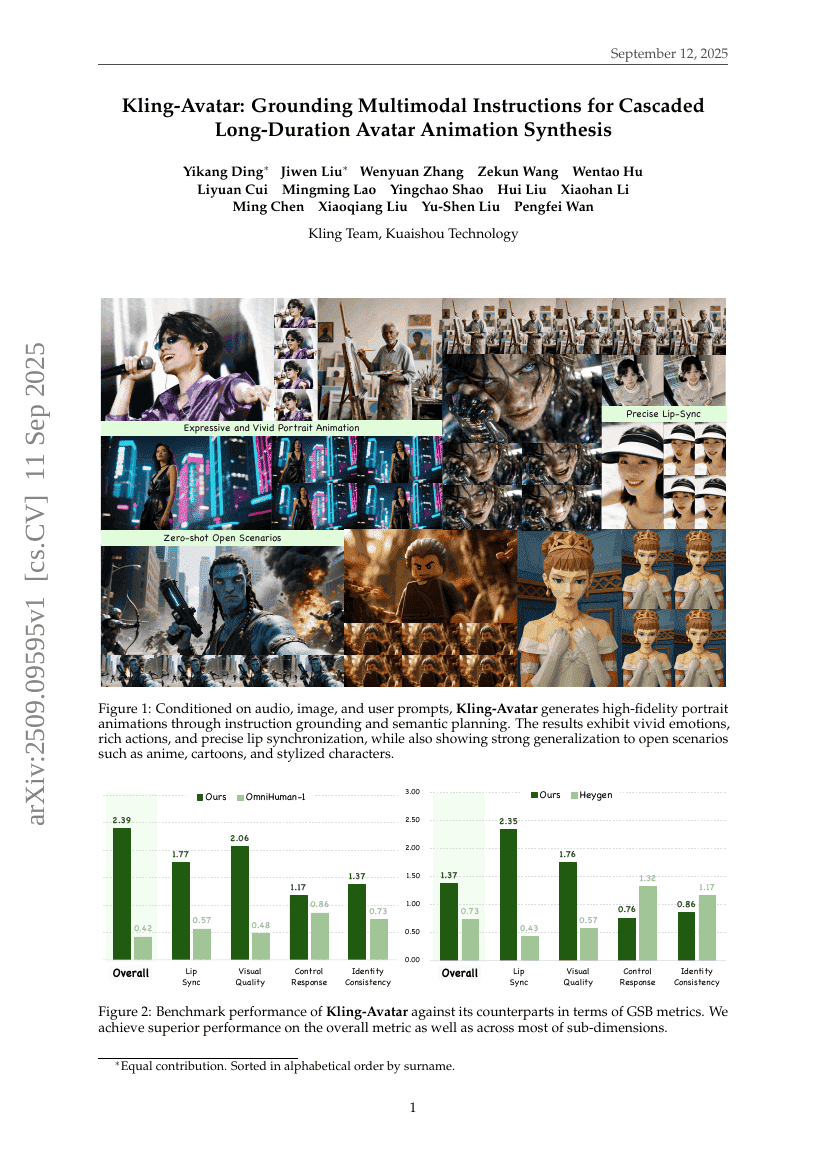
클링-아바타: 계단식 장시간 아바타 애니메이션 합성에 대한 다중모달 지시의 기반화
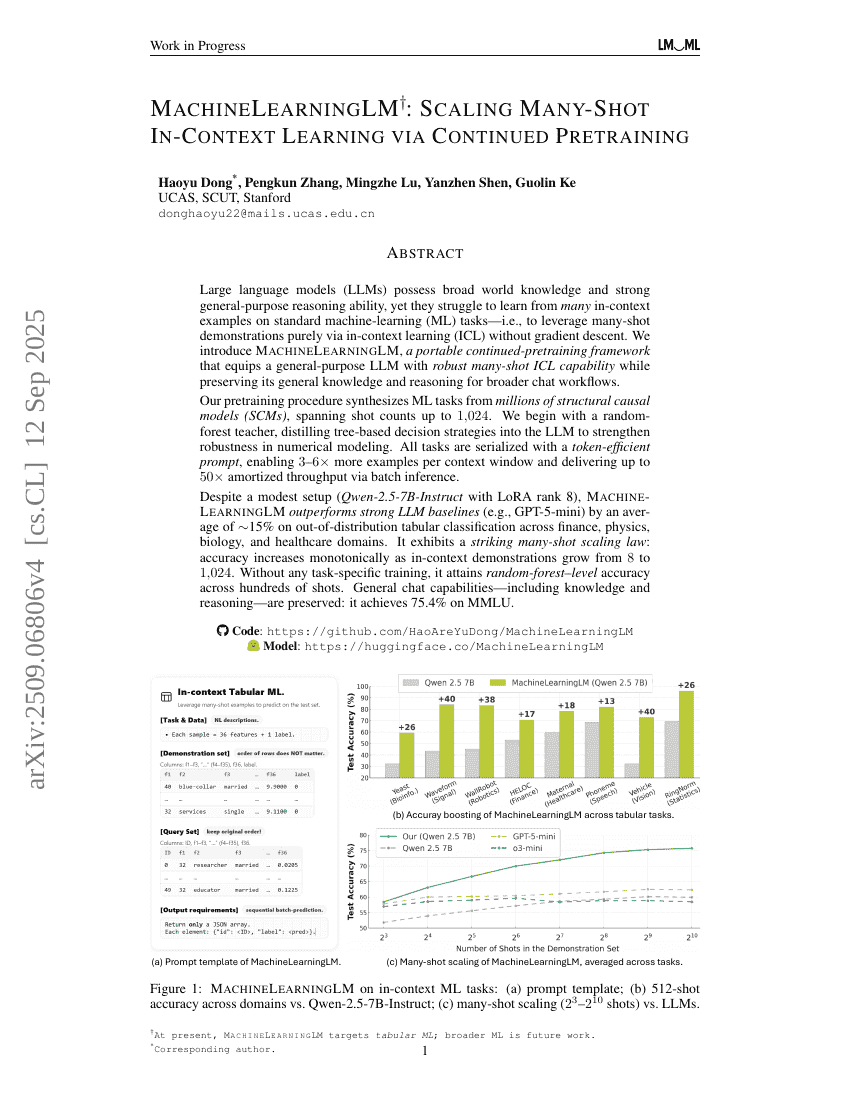
머신러닝LM: 수백만 개의 합성 표형 예측 과제를 통한 언어 모델의 지속적 사전 훈련으로 인-컨텍스트 머신러닝 확장
에코X: 음성-음성 LLM을 위한 에코 훈련을 통한 음향-의미 간 격차 완화 방향
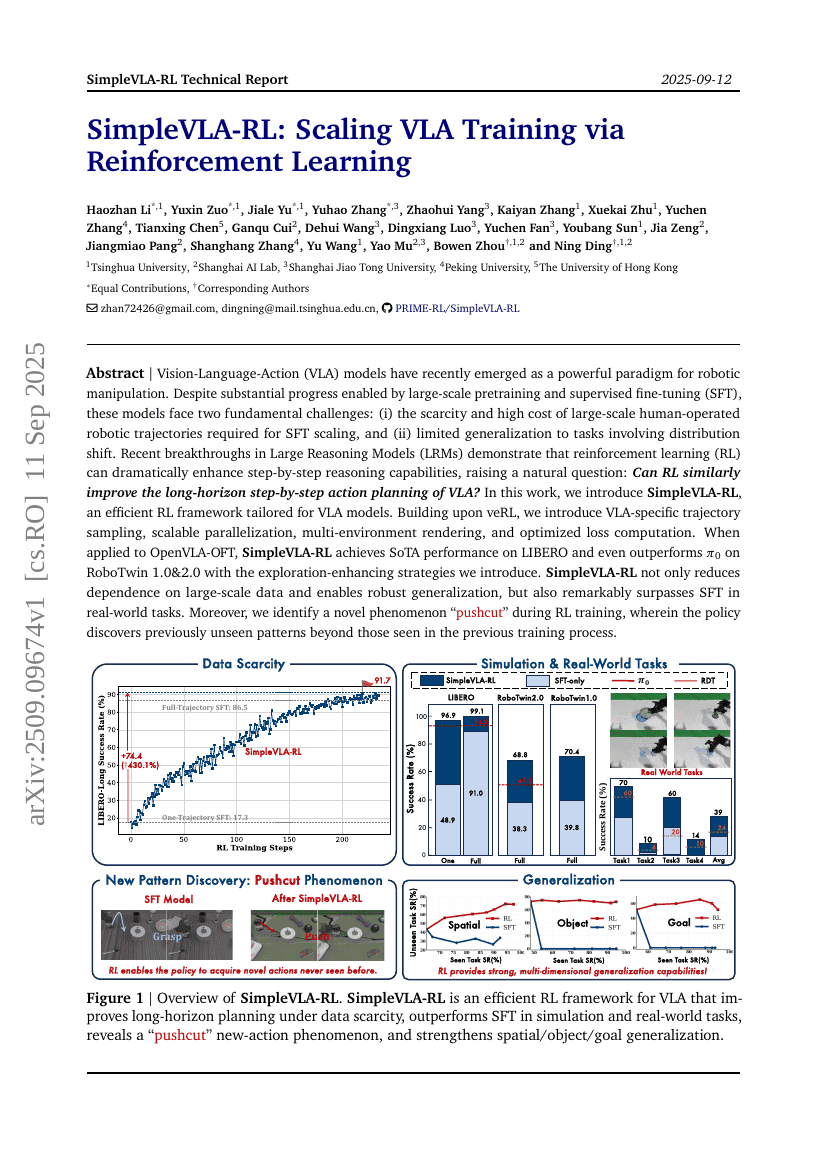
SimpleVLA-RL: 강화학습을 통한 VLA 훈련의 확장
VLA-Adapter: 미규모 시각-언어-행동 모델을 위한 효과적인 패러다임
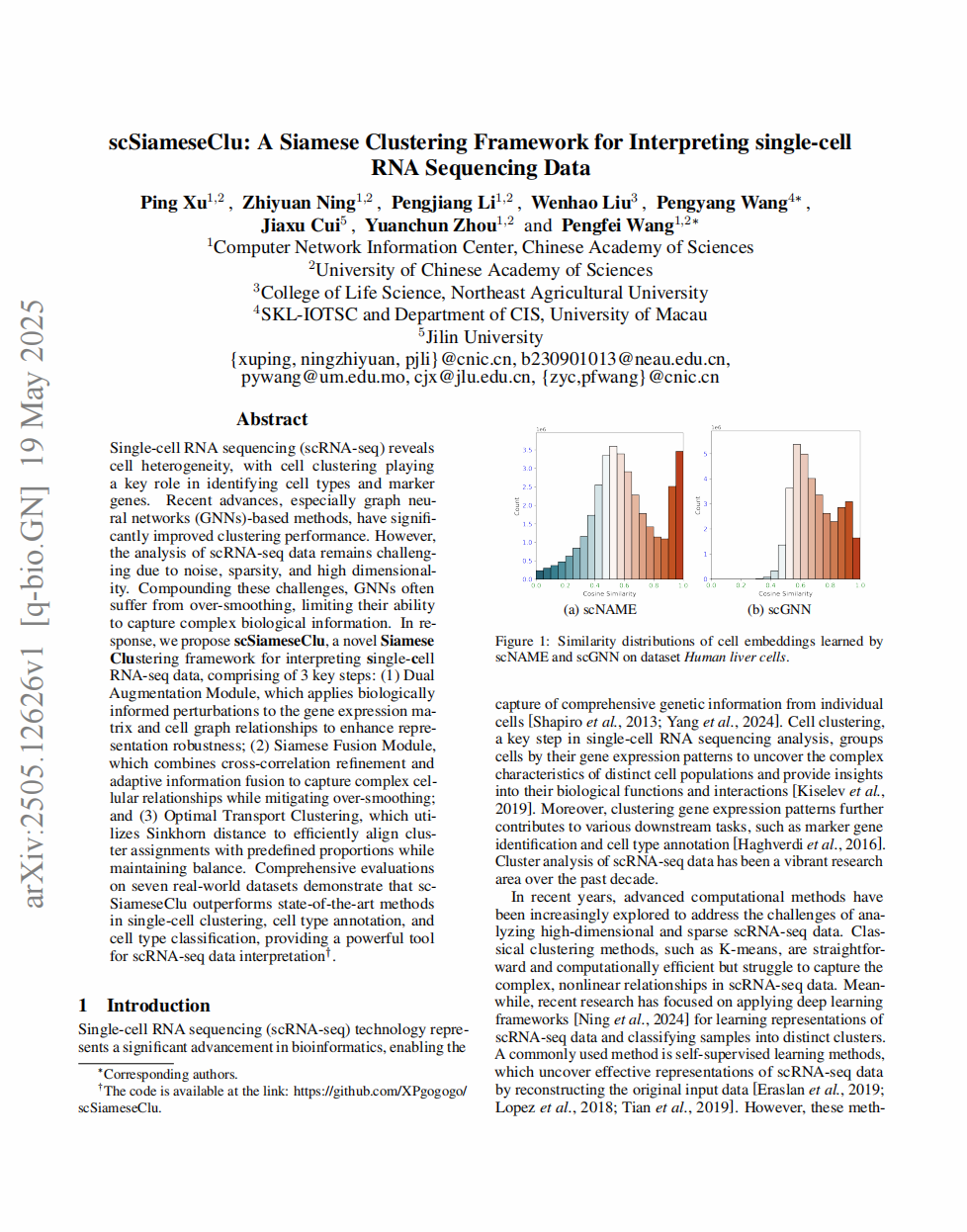
scSiameseClu: 단일세포 RNA 시퀀싱 데이터 해석을 위한 시아메스 클러스터링 프레임워크
ST-Raptor: LLM 기반의 반구조화된 테이블 질문 응답
오미니스페이셜: 비전 언어 모델을 위한 종합적인 공간 인지 추론 벤치마크로의 도전
협상 게임에서 인간 및 인공지능 에이전트 간의 경제적 트레이드오프 이해
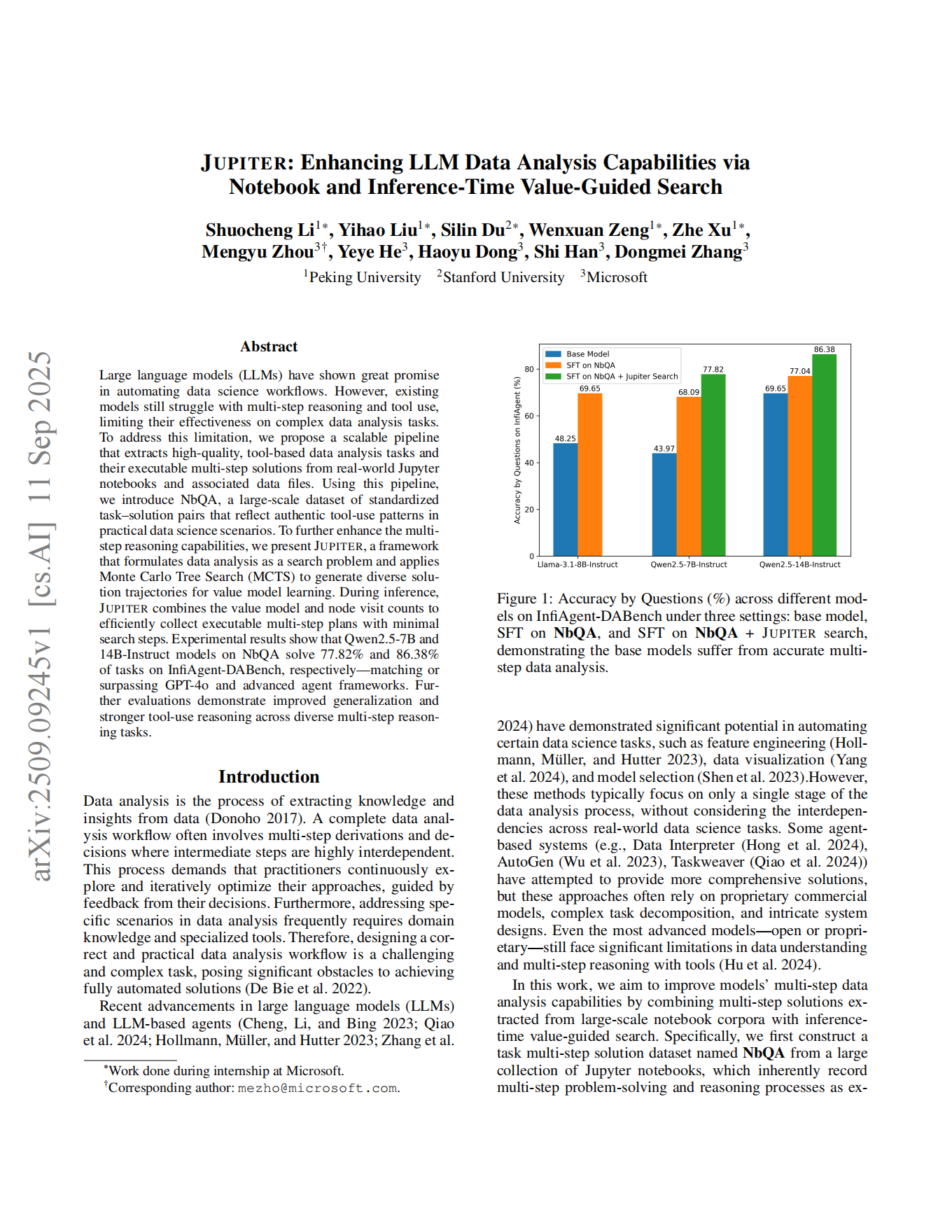
자니트스: 노트북 및 추론 시점 가치 기반 검색을 통한 LLM 데이터 분석 능력 향상
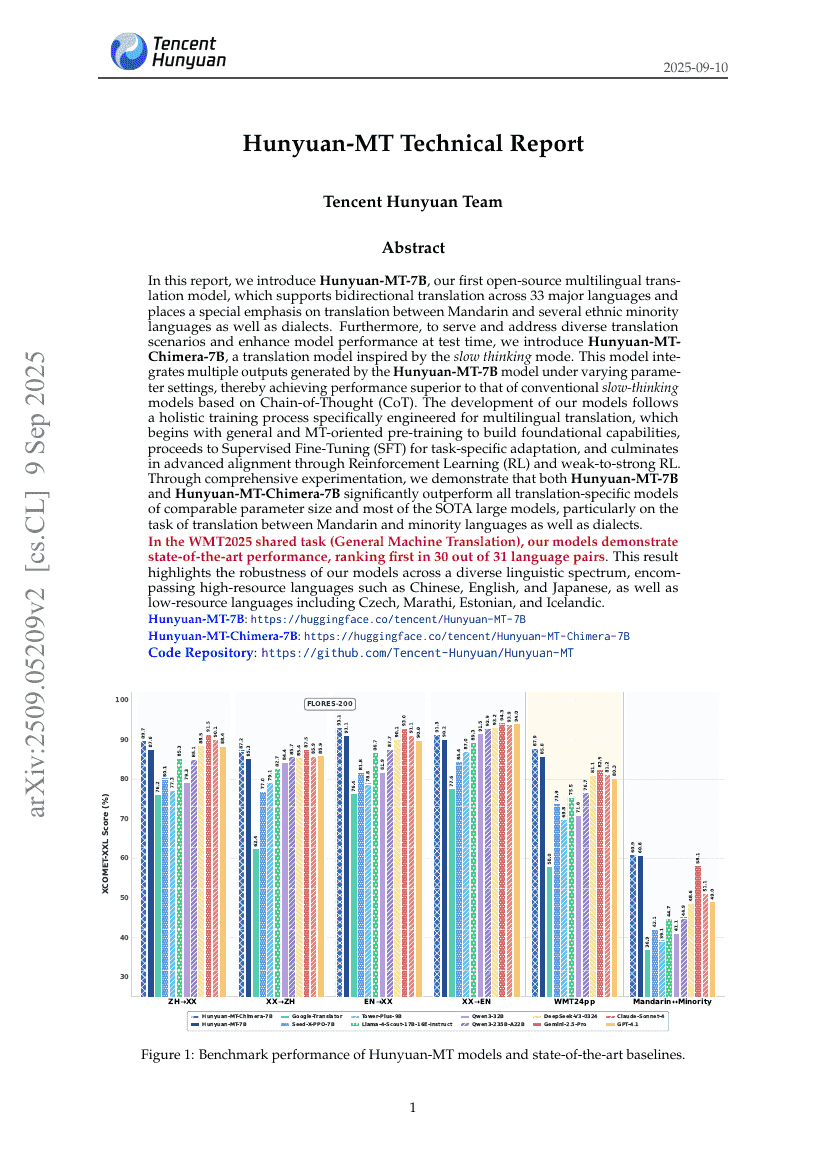
현위안-MT 기술 보고서
P3-SAM: 자연스러운 3D 부분 분할
에이전트짐-RL: 다단계 강화학습을 통한 장기 지속 의사결정을 위한 LLM 에이전트 훈련
3D 및 4D 월드 모델링: 종합 검토
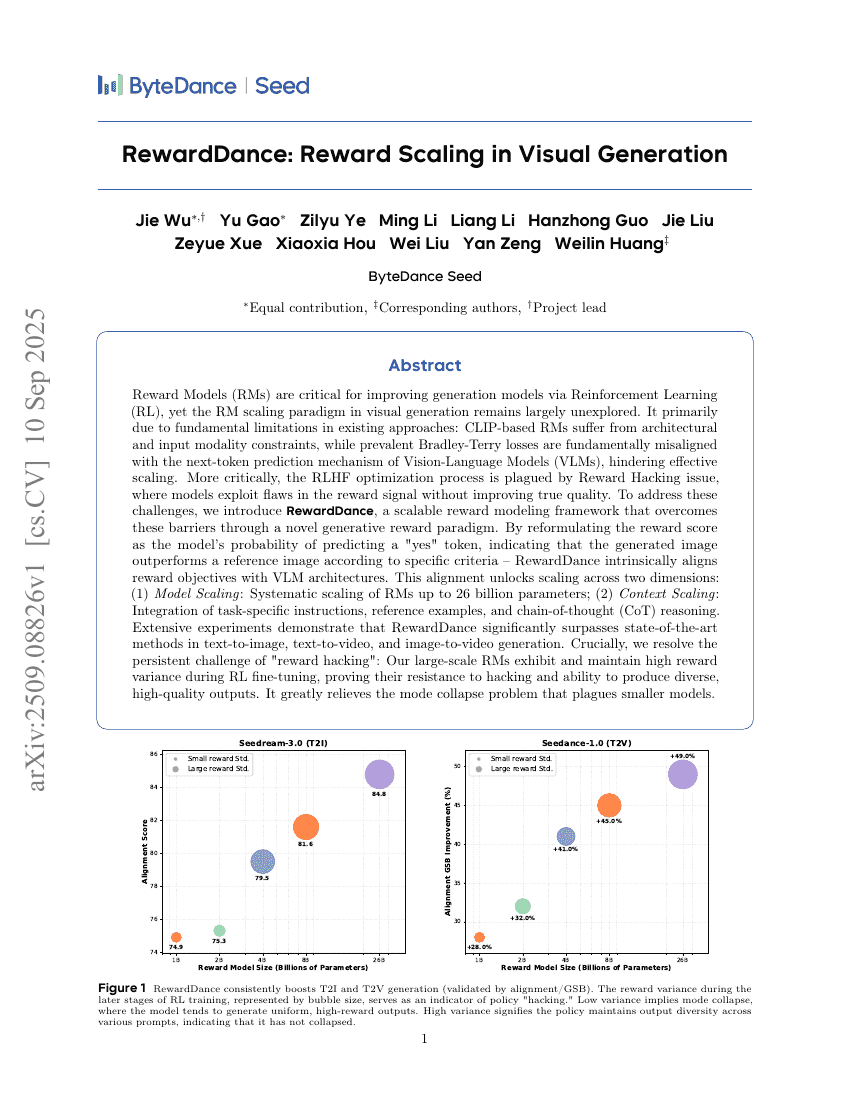
RewardDance: 시각 생성에서의 보상 스케일링
공유는 배려이다: 집단적 강화학습 경험 공유를 통한 효율적인 언어모델 후학습
FinReflectKG: 금융 지식 그래프의 에이전트 기반 구축 및 평가
대규모 추론 모델을 위한 강화 학습에 관한 종합적 조사
과도한 의존 측정 및 완화는 인간 친화적 AI 구축을 위한 필수적인 과정이다
F1: 이해와 생성을 행동으로 연결하는 시각-언어-행동 모델
UMO: 이미지 커스터마이징을 위한 다중 정체성 일관성 확장 기법: 매칭 보상 기반 접근
재구성 정렬은 통합 다중모달 모델을 개선한다
InfGen: 확장 가능한 이미지 합성을 위한 해상도 무관한 패러다임
X-Part: 높은 정밀도와 구조적 일관성을 갖춘 형태 분해
감소하는 수익의 환상: 대규모 언어 모델에서 장기적 실행 측정하기
IntrEx: 교육 대화의 참여를 모델링하기 위한 데이터셋
Youtu-GraphRAG: 그래프 검색 증강 복합 추론을 위한 수직 통합 에이전트
SceneSplat: 시각-언어 사전학습을 통한 가우시안 스플래터링 기반의 장면 이해
가상 에이전트 경제
시각 언어 모델에서 시각적 기반 이해를 위한 탐구
클링-아바타: 계단식 장시간 아바타 애니메이션 합성에 대한 다중모달 지시의 기반화
머신러닝LM: 수백만 개의 합성 표형 예측 과제를 통한 언어 모델의 지속적 사전 훈련으로 인-컨텍스트 머신러닝 확장
에코X: 음성-음성 LLM을 위한 에코 훈련을 통한 음향-의미 간 격차 완화 방향
SimpleVLA-RL: 강화학습을 통한 VLA 훈련의 확장
VLA-Adapter: 미규모 시각-언어-행동 모델을 위한 효과적인 패러다임
scSiameseClu: 단일세포 RNA 시퀀싱 데이터 해석을 위한 시아메스 클러스터링 프레임워크
ST-Raptor: LLM 기반의 반구조화된 테이블 질문 응답
오미니스페이셜: 비전 언어 모델을 위한 종합적인 공간 인지 추론 벤치마크로의 도전
협상 게임에서 인간 및 인공지능 에이전트 간의 경제적 트레이드오프 이해
자니트스: 노트북 및 추론 시점 가치 기반 검색을 통한 LLM 데이터 분석 능력 향상
현위안-MT 기술 보고서
P3-SAM: 자연스러운 3D 부분 분할
에이전트짐-RL: 다단계 강화학습을 통한 장기 지속 의사결정을 위한 LLM 에이전트 훈련
3D 및 4D 월드 모델링: 종합 검토
RewardDance: 시각 생성에서의 보상 스케일링
공유는 배려이다: 집단적 강화학습 경험 공유를 통한 효율적인 언어모델 후학습
FinReflectKG: 금융 지식 그래프의 에이전트 기반 구축 및 평가
대규모 추론 모델을 위한 강화 학습에 관한 종합적 조사
과도한 의존 측정 및 완화는 인간 친화적 AI 구축을 위한 필수적인 과정이다
F1: 이해와 생성을 행동으로 연결하는 시각-언어-행동 모델
UMO: 이미지 커스터마이징을 위한 다중 정체성 일관성 확장 기법: 매칭 보상 기반 접근
재구성 정렬은 통합 다중모달 모델을 개선한다