Command Palette
Search for a command to run...
온라인 튜토리얼 | 16GB 노트북, 혁신적인 아키텍처를 기반으로 텍스트/이미지/사운드 모달리티 통합 처리 기능을 통해 거의 26B MoE 성능 달성: Gemma 4 12B

대규모 모델 경쟁이 여전히 파라미터 크기에 초점을 맞추고 있는 가운데, 구글 딥마인드는 성능 향상이 반드시 더 큰 모델에만 의존하는 것은 아니라는 점을 다시 한번 입증했습니다.
최근 구글 딥마인드는 젬마 4 제품군의 최신 모델인 젬마 4 12B를 공식 출시했습니다. 이 모델은 단 120억 개의 파라미터를 가진 통합 멀티모달 모델이지만, 여러 벤치마크 테스트에서 260억 개의 파라미터를 가진 하이브리드 전문가(MoE) 모델에 버금가는 성능을 보여줍니다. 공식 데이터에 따르면 젬마 4 12B는 추론, 코드 생성, 멀티모달 이해 등의 작업에서 젬마 4 26B에 근접하는 성능을 나타냅니다.동시에, 이 모델은 일부 시각적 이해 및 에이전트 작업에서 동일 수준의 현재 오픈 소스 모델 중 최첨단(SOTA) 수준을 달성합니다.더욱 중요한 것은 이 모델이 일반 소비자용 노트북에서 기본적으로 실행되는 데 필요한 비디오 메모리 또는 통합 메모리가 16GB에 불과하여 성능과 구축 비용 사이에서 보기 드문 균형을 이룬다는 점입니다.
Gemma 시리즈 최초로 오디오 입력을 기본적으로 지원하는 중형 모델인 Gemma 4 12B의 가장 큰 혁신은 파라미터 크기가 아니라 아키텍처 혁신에 있습니다. 오랫동안 멀티모달 모델은 일반적으로 "인코더 + 언어 모델" 방식을 채택해 왔습니다. 즉, 이미지는 비주얼 인코더에서, 오디오는 음성 인코더에서 처리된 후, 그 결과가 추론을 위해 대규모 언어 모델로 전달되는 방식입니다. 이러한 아키텍처는 성숙 단계에 접어들었지만,하지만 이로 인해 추가적인 계산 오버헤드, 메모리 사용량 및 추론 지연 시간이 발생합니다.
이 문제를 해결하기 위해 Google DeepMind는 Gemma 4 12B를 위해 완전히 새로운 인코더 없는 아키텍처를 설계했습니다. 이미지는 경량 임베딩 모듈을 거친 후 LLM 백본에 직접 입력되고, 오디오는 텍스트 토큰과 동일한 표현 공간으로 직접 투영됩니다.동일한 디코더 전용 트랜스포머가 텍스트, 이미지 및 사운드 양식을 일관되게 처리합니다.공식 발표에 따르면 이 설계는 멀티모달 추론 지연 시간을 크게 줄이는 동시에 시스템 복잡성과 메모리 사용량도 감소시킵니다.
Gemma 4 12B는 통합 멀티모달 아키텍처 외에도 256KB의 초장시간 컨텍스트 윈도우, 전환 가능한 Thinking 심층 추론 모드, 네이티브 함수 호출 및 에이전트 워크플로 기능을 지원합니다. 표준 벤치마크에서,전반적인 성능은 크기가 두 배 이상 큰 Gemma 4 26B MoE 모델과 거의 비슷합니다.운영 비용은 후자의 절반에도 미치지 못합니다. 고급 AI 기능을 로컬에 배포하려는 개발자에게 이는 값비싼 GPU 없이도 현재 최고 수준의 멀티모달 모델에 버금가는 추론 및 에이전트 경험을 구현할 수 있음을 의미합니다.
현재 HyperAI 공식 웹사이트(hyper.ai)의 튜토리얼 섹션에서 "Gemma 4 12B-it 원클릭 배포"를 선보였습니다. 이 자료는 노트북 형태로 배포 진입 장벽을 낮추고 개발자가 모델을 빠르게 검증할 수 있도록 지원합니다.
온라인으로 실행:https://go.hyper.ai/1Jrdl
더 많은 온라인 튜토리얼:
데모 실행
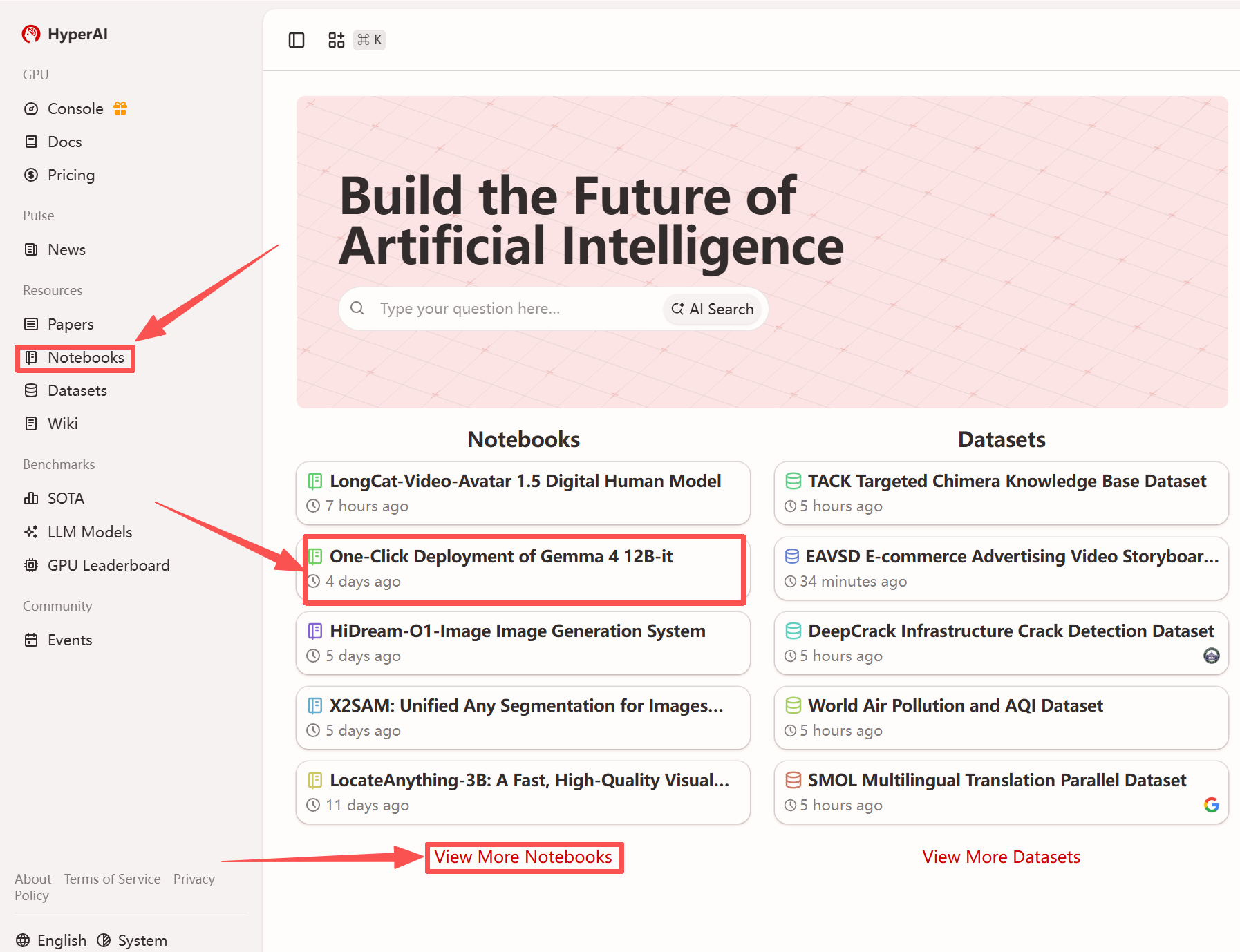
1. hyper.ai 홈페이지에 접속한 후 "튜토리얼" 페이지를 선택하거나 "더 많은 튜토리얼 보기"를 클릭하고 "Gemma 4 12B-it 원클릭 배포"를 선택한 다음 "이 튜토리얼 실행"을 클릭합니다.
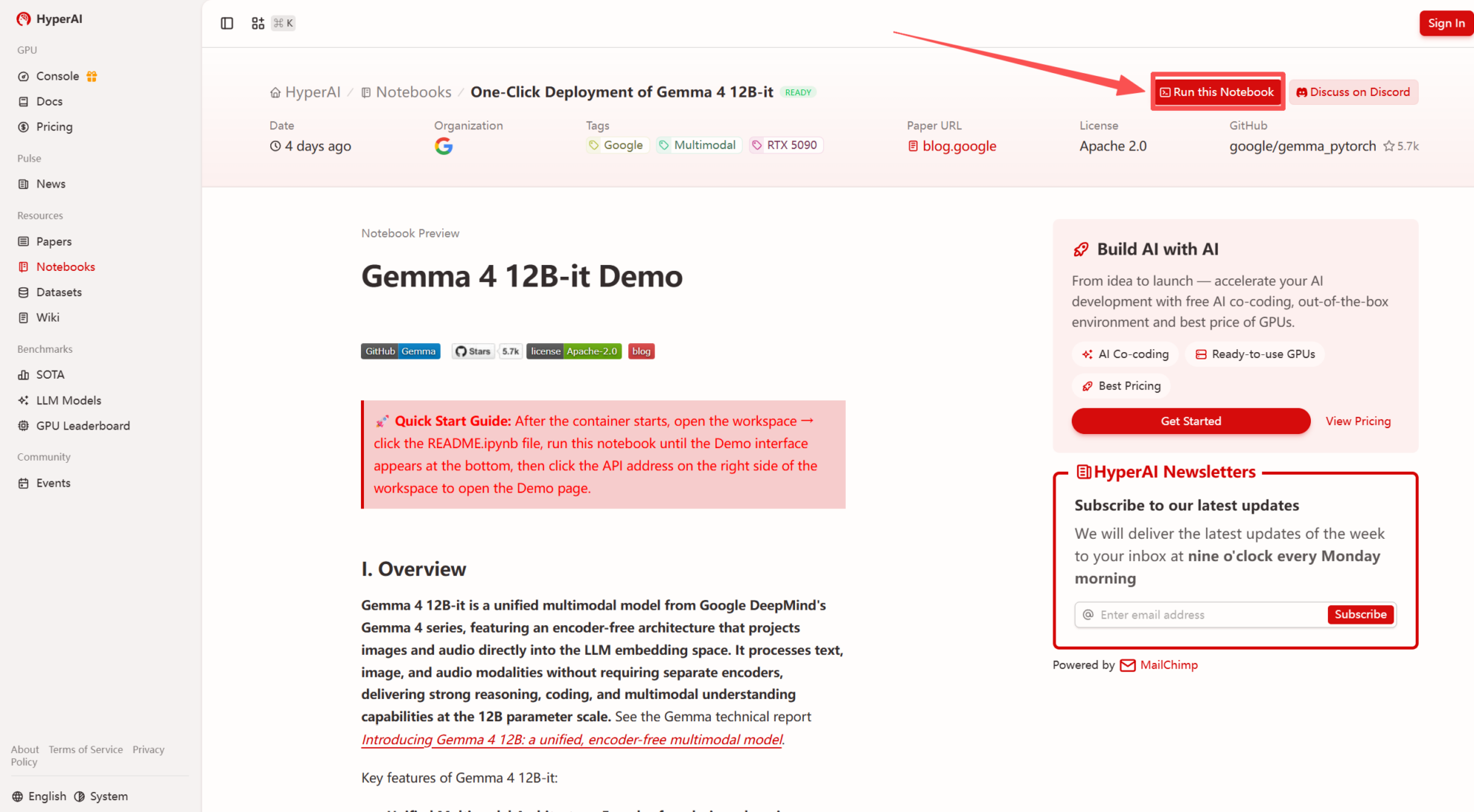
2. 페이지가 리디렉션된 후 오른쪽 상단의 "복제"를 클릭하여 튜토리얼을 자신의 컨테이너로 복제합니다.
참고: 페이지 오른쪽 상단에서 언어를 변경할 수 있습니다. 현재 중국어와 영어로만 제공됩니다. 이 튜토리얼에서는 영어로 된 단계를 안내합니다.
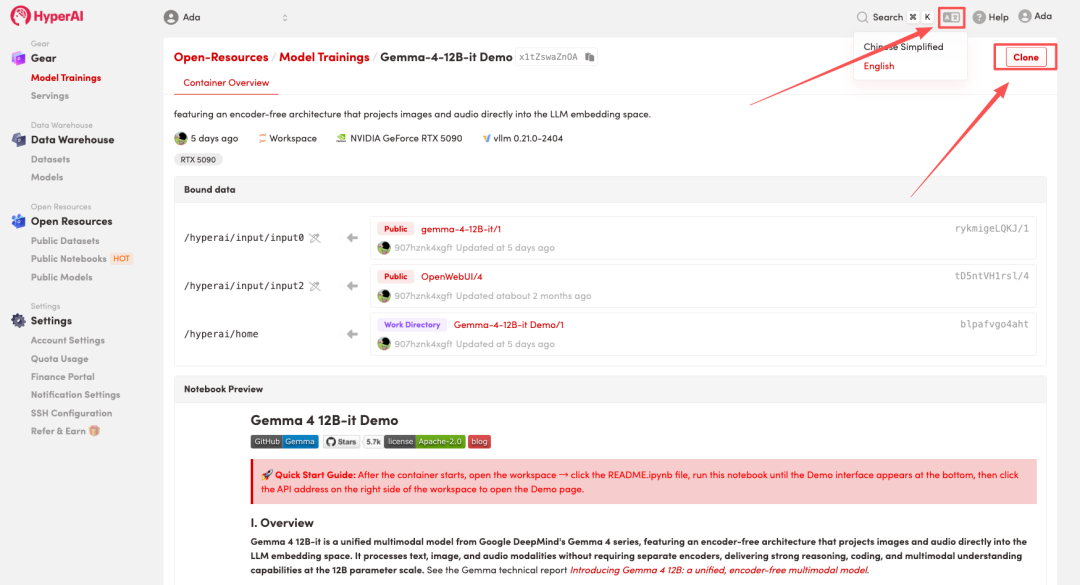
3. "NVIDIA RTX 5090" 및 "vLLM" 이미지를 선택하고 "작업 실행 계속"을 클릭합니다.
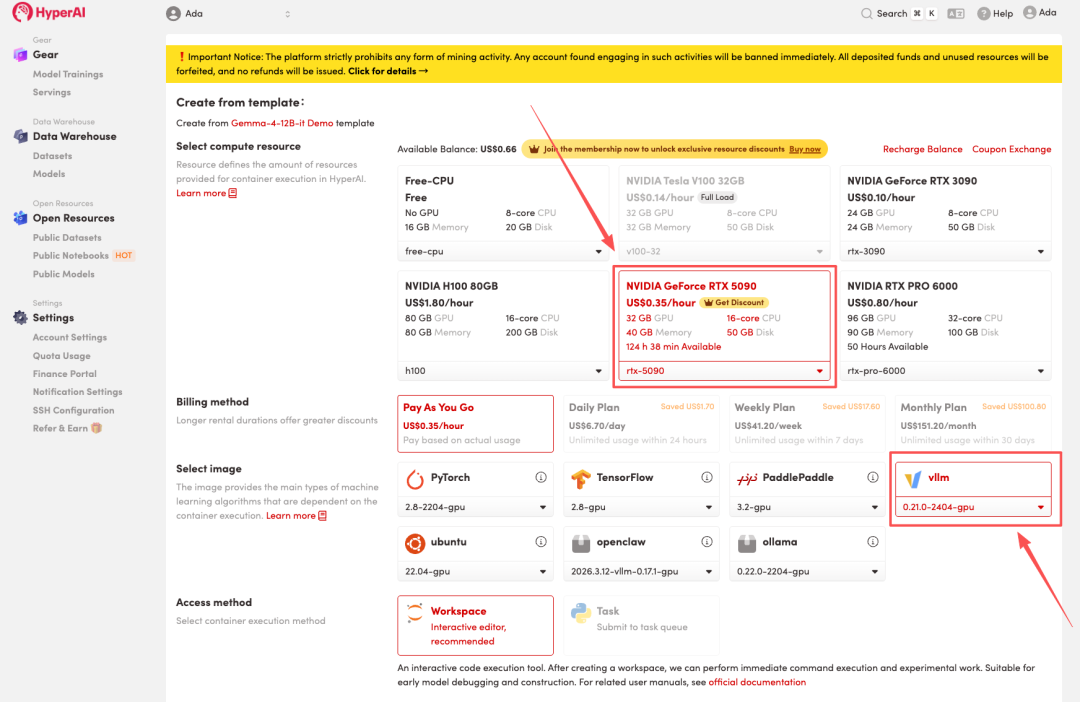
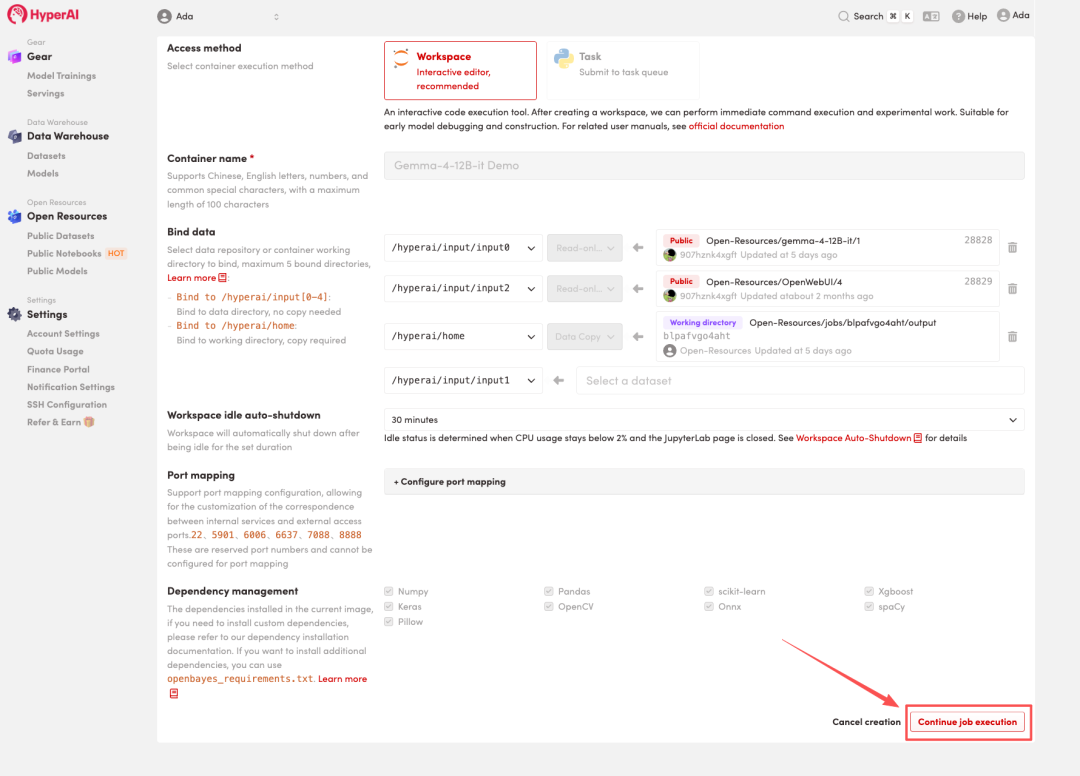
4. 리소스 할당이 완료될 때까지 기다립니다. 상태가 "실행 중"으로 변경되면 "워크스페이스 열기"를 클릭하여 Jupyter 워크스페이스에 들어갑니다.
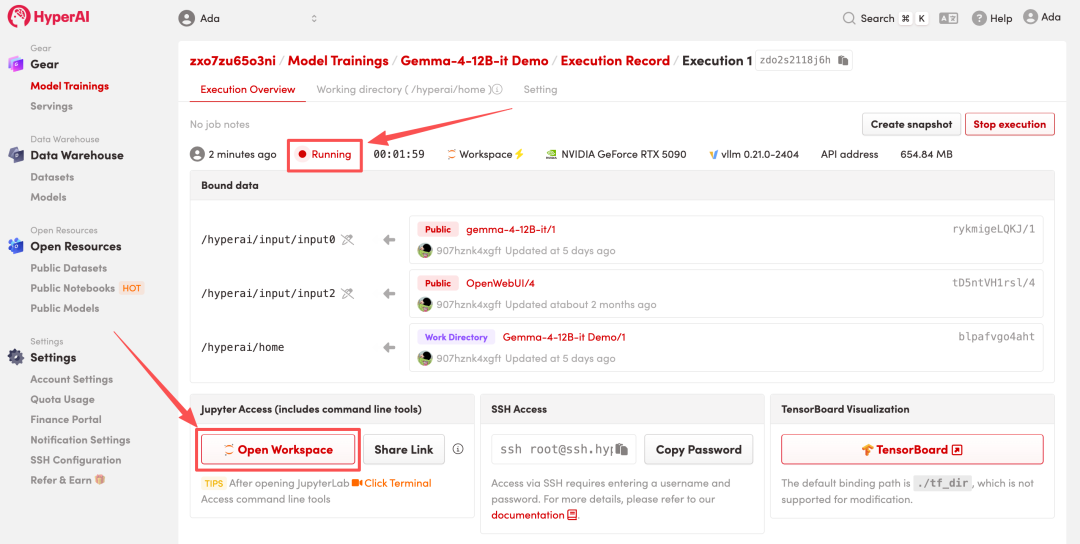
효과 표시
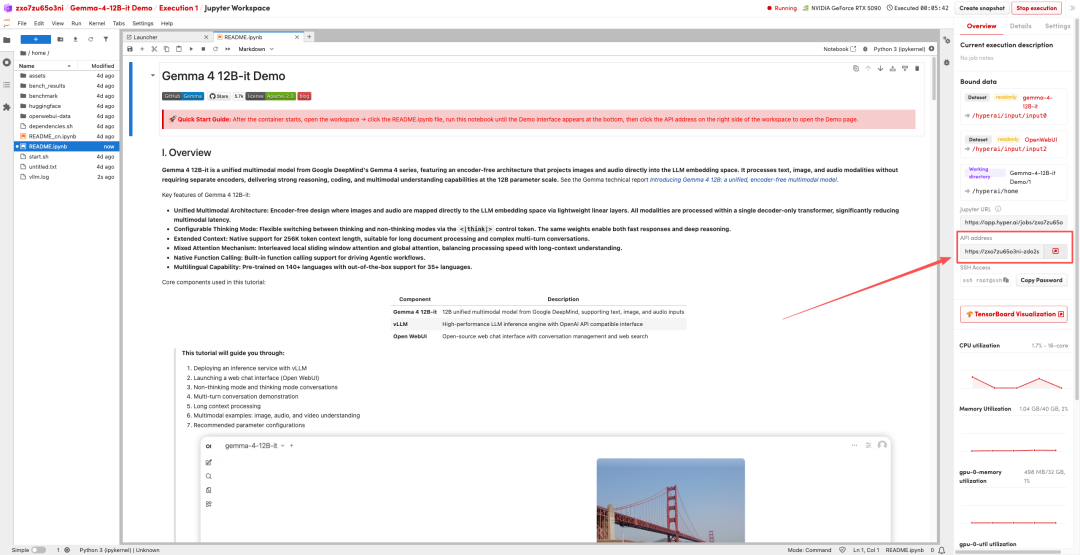
1. 페이지가 리디렉션된 후 왼쪽에 있는 README 파일을 클릭하고 상단의 실행을 클릭합니다.
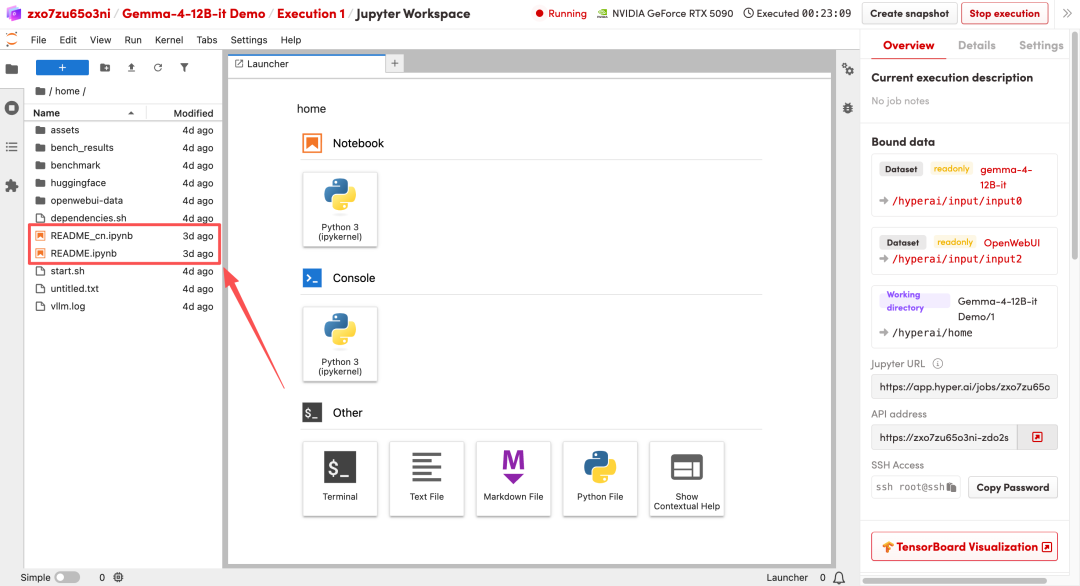
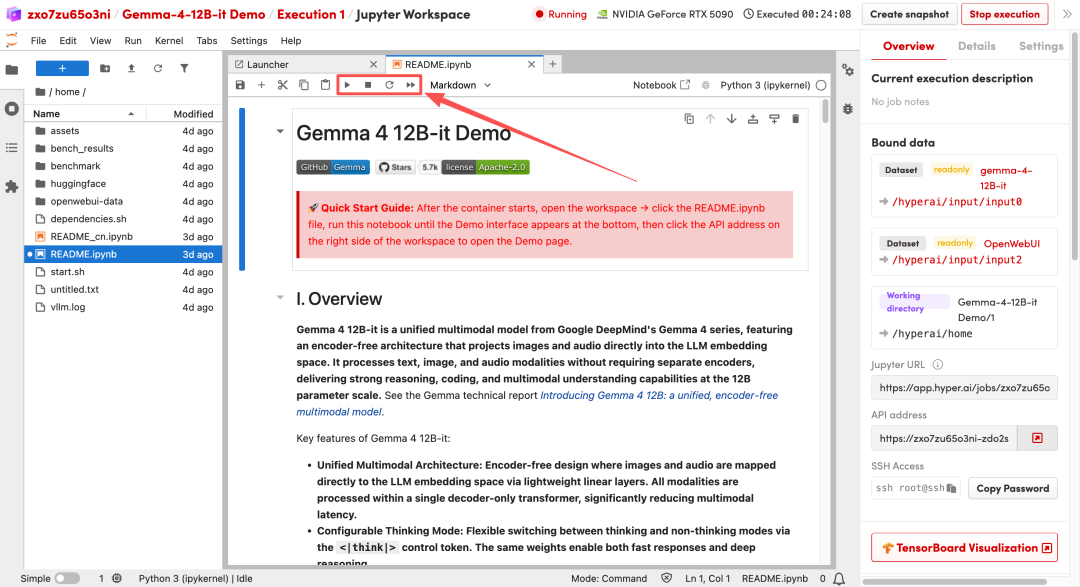
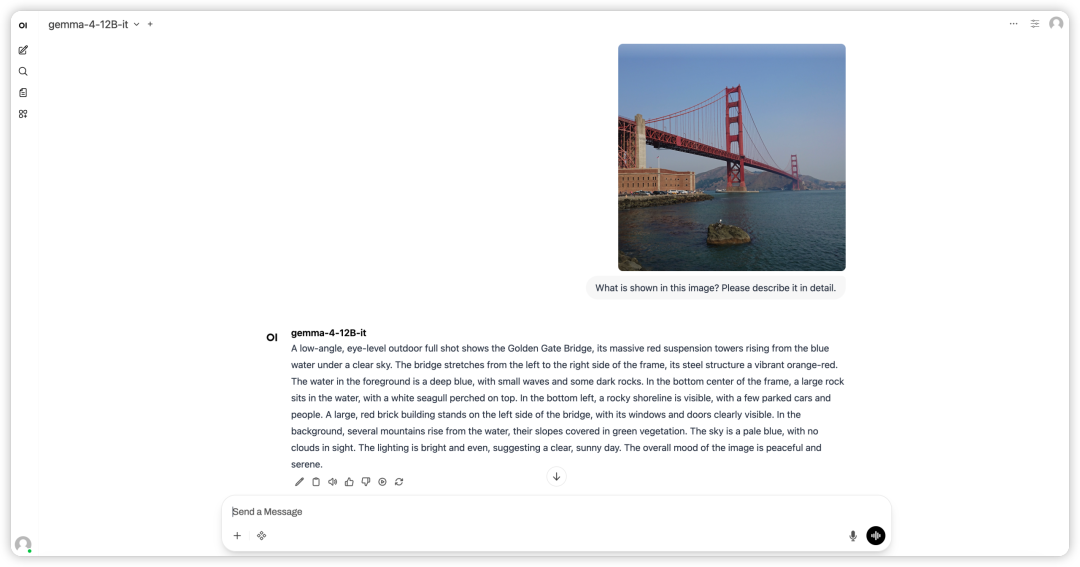
2. 프로세스가 완료되면 오른쪽에 있는 API 주소를 클릭하여 데모 인터페이스를 엽니다.