Command Palette
Search for a command to run...
프랑스 연구팀은 239만 개의 항파지 단백질을 성공적으로 예측하고 딥러닝 모델을 사용하여 박테리아의 항바이러스 면역을 분석했습니다.

미시 세계에서 박테리아와 박테리오파지 사이의 "군비 경쟁"은 결코 멈추지 않았습니다. 박테리오파지는 일반적으로 박테리아보다 약 10배 더 많으며, 박테리아를 숙주로 삼아 번식합니다. 한편, 박테리아는 오랜 진화를 통해 매우 다양한 항바이러스 방어 시스템을 개발해 왔습니다. 현재까지 250개 이상의 항파지 시스템이 실험적으로 검증되었으며, 여기에는 제한-변형 시스템 및 CRISPR-Cas 시스템과 같은 다양한 메커니즘이 포함되고, 새로운 시스템이 끊임없이 발견되고 있습니다. 이러한 현상은 박테리아 방어 시스템의 복잡성과 다양성이 현재의 이해를 훨씬 뛰어넘을 수 있음을 시사합니다. 그러나전통적인 실험 방법과 계산 기술의 한계로 인해, 수많은 잠재적인 항파지 메커니즘이 박테리아 게놈 내에 숨겨져 있으며 아직 체계적으로 탐구되지 못했습니다.
기존 연구에서는 단백질 서열 및 게놈 구조 수준에서 알려진 항파지 시스템 간에 몇 가지 공통적인 특징이 있음을 지적했습니다. 예를 들어, 특징적인 도메인의 반복적인 출현과 이러한 도메인이 "방어 섬" 또는 전파지 영역에 집중적으로 분포하는 현상 등이 있습니다. 이러한 패턴은 다음과 같은 점을 시사합니다.이러한 공통 패턴을 식별하고 활용할 수 있다면 전체 게놈 규모에서 알려지지 않은 항파지 시스템을 체계적으로 밝혀낼 수 있을 것이다.
이러한 접근 방식을 바탕으로 프랑스 파스퇴르 연구소의 연구원들은 대규모 파지 내성 예측을 위한 세 가지 상호 보완적인 딥러닝 모델을 개발하고 미세 조정했습니다. ALBERT_DF 모델은 추론을 위해 국소 유전체 컨텍스트에만 의존하고, ESM_DF는 단백질 언어 모델을 사용하여 아미노산 서열을 분석하며, GeneCLR_DF는 서열 정보와 유전체 컨텍스트를 통합합니다. 통합 벤치마크 테스트에서,GeneCLR_DF가 가장 우수한 성능을 보였으며, 정밀도 991 TP3T, 재현율 921 TP3T를 달성했습니다.
이 고정밀 모델을 기반으로, 본 연구는 추가적으로 게놈 전체 규모의 항파지 시스템 예측을 수행했습니다. 그 결과, 32,000개 이상의 박테리아 게놈에서 일반적인 박테리아 게놈당 약 1.51개의 TP3T 유전자가 항바이러스 방어에 관여하는 것으로 나타났습니다. 더욱 중요한 것은, 예측된 방어 관련 단백질 패밀리를 대표하는 851개 이상의 TP3T 유전자가 이전에는 면역 기능과 연관된 적이 없었다는 점입니다. 궁극적으로,이 모델은 약 239만 개의 항파지 단백질을 예측했는데, 그중 상당수는 단일 유전자 방어 시스템에 속하며, 유전자 동시 발생 관계를 기반으로 약 23,000개의 오페론 패밀리를 정의했습니다.이러한 박테리아의 대다수는 이전에는 항바이러스 방어와 관련이 없는 것으로 여겨졌습니다. 이러한 결과들은 종합적으로 박테리아의 항바이러스 면역에 대한 체계적인 그림을 제시하며, 그 규모와 다양성이 기존 지식을 훨씬 뛰어넘는다는 것을 보여줍니다.
"단백질 및 유전체 언어 모델을 통해 밝혀지지 않았던 박테리아 면역의 다양성을 규명하다"라는 제목의 관련 연구 결과가 과학 저널 '사이언스'에 게재되었습니다.
연구 하이라이트:
* 총 239만 개의 항파지 단백질이 예측되었으며, 그중 85%는 이전에는 면역 기능과 연관된 적이 없는 단백질입니다.
* 일반적인 세균 게놈에서 약 1.51개의 TP3T 유전자가 항바이러스 방어에 특이적으로 관여합니다.
* 약 23,000개의 조작기 하위군이 예측되었으며, 그중 대다수는 이번에 처음으로 발견되었습니다.
* 예측된 방어 단백질 중 상당수가 단일 유전자 시스템 형태로 존재하며, 이는 방어 기능이 일반적으로 여러 유전자의 협력에 의해 이루어진다는 기존의 견해에 이의를 제기합니다.

서류 주소:
https://www.science.org/doi/10.1126/science.adv8275
저희 공식 위챗 계정을 팔로우하고 백그라운드에서 "GeneCLR"이라고 답장하시면 전체 PDF 파일을 받으실 수 있습니다.
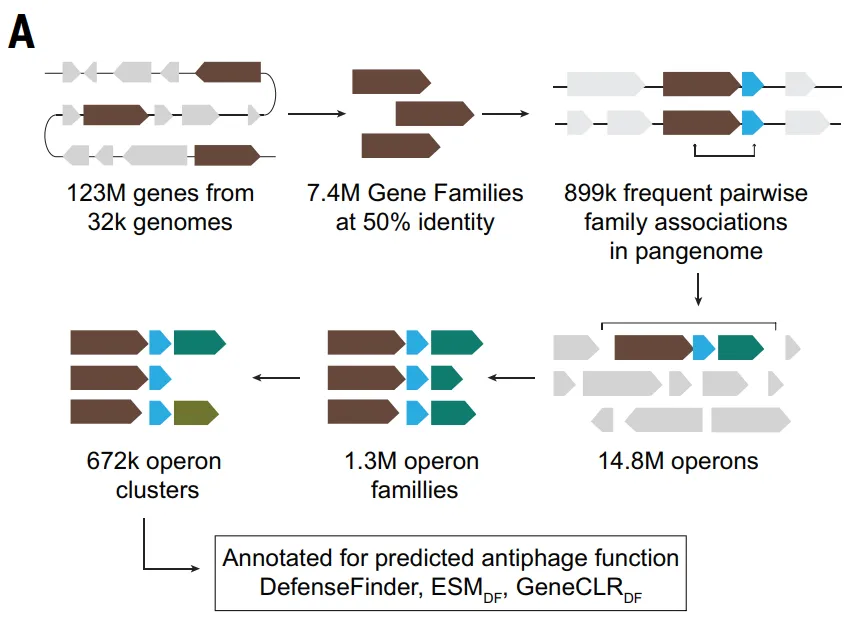
데이터셋: 1억 2,300만 개의 단백질과 32,000개의 게놈을 기반으로 함
본 연구에서는 우선 DefenseFinder와 PadLoc 도구를 활용했습니다.RefSeq 데이터베이스에 있는 32,798개의 완전한 박테리아 게놈을 체계적으로 스캔하여 알려진 항파지 시스템을 정량적으로 특성화했습니다.약 1억 2,300만 개의 단백질 중 DefenseFinder v1.3은 항파지 시스템 구성 요소에 속하는 521,360개(TP3T 0.41개에 해당)를 식별했고, PadLoc은 TP3T 0.651개에 해당하는 805,357개를 식별했습니다.
많은 방어 시스템이 처음에는 알려진 시스템과의 유전체적 연관성을 통해 발견되었다는 점에 주목할 필요가 있습니다. 이러한 연관성은 특정 단백질 계열이 유전체 내에서 알려진 방어 단백질과 함께 나타나는 빈도를 측정하는 "방어 점수"를 사용하여 단백질 계열 수준에서 정량화할 수 있습니다.
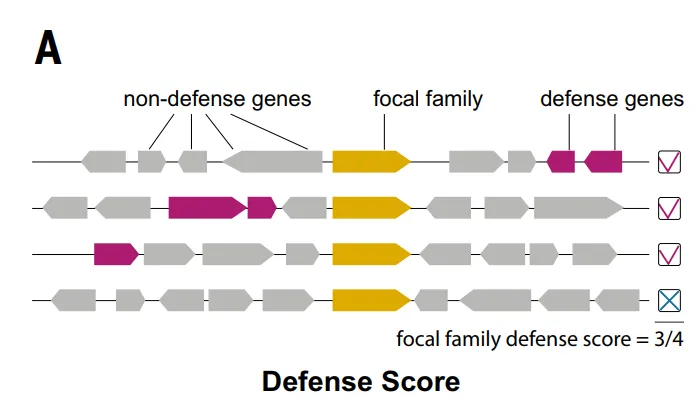
아래 그림과 같이 방어 점수 산정 방식에 따라.연구진은 총 37,959개의 단백질 패밀리(TP3T의 4.61%)를 항파지 후보 패밀리로 식별했습니다.이후 연구에서는 핵심 생물학적 기능이나 이동성 유전 요소와 관련된 인테그라제와 같은 7,799개의 패밀리를 제외하여 최종적으로 30,160개의 후보 패밀리(TP3T의 3.71%에 해당)를 선정했습니다.
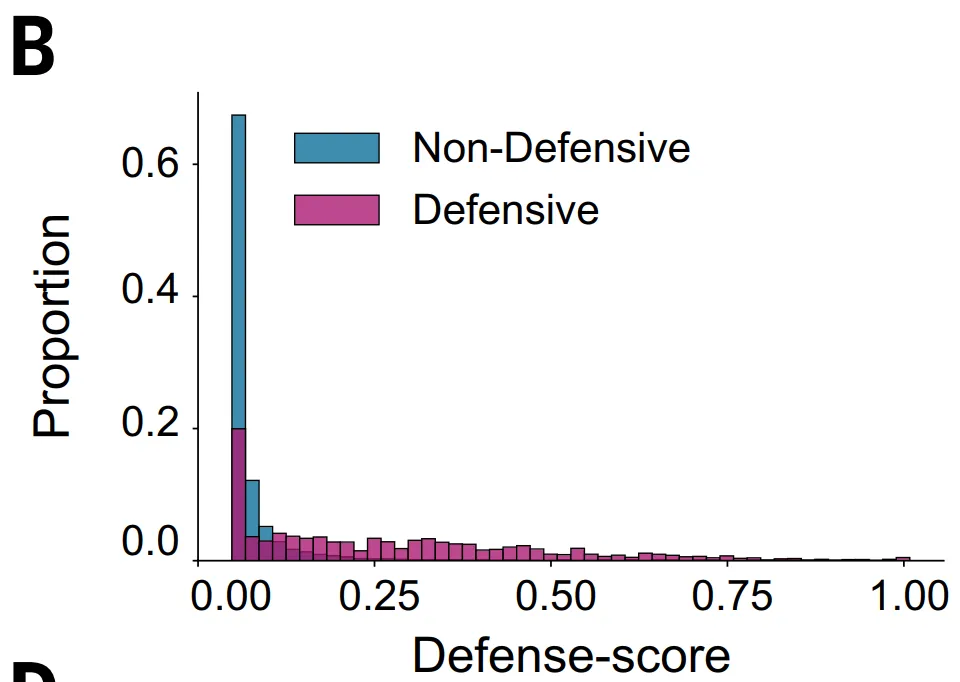
하지만 이 방법에는 명백한 한계가 있습니다.첫째로,이는 5개 이상의 상동 서열을 포함하는 단백질 패밀리에만 적용되므로 약 23%의 단백질은 제외됩니다.둘째로,일부 항파지 시스템은 일반적인 방어 영역에 위치하지 않으며, 방어 기능을 가지고 있더라도 방어 점수가 낮아 간과되는 경우가 있습니다.
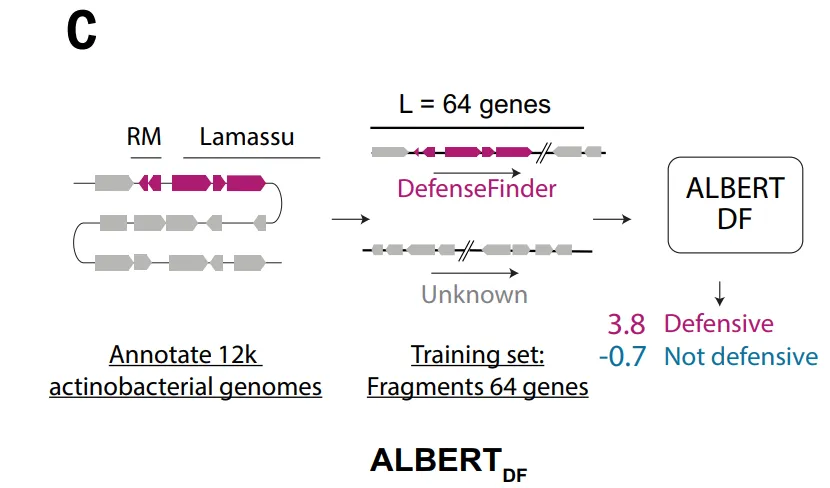
위의 한계를 극복하고 국방 관련 유전체 신호를 보다 포괄적으로 포착하기 위해,이 연구는 딥러닝에 적합한 데이터셋을 추가로 구축했습니다.ALBERT_DF 모델 프레임워크 내에서, 본 연구는 박테리아 게놈을 "언어적" 방식으로 모델링했습니다. 즉, 각 단백질 계열을 "단어"로, 인접한 유전자 부분을 "문장"으로 취급했습니다.
전체 데이터 세트에는 8백만 개 이상의 서로 다른 단백질 계열이 포함되어 있어 기존 언어 모델의 어휘 크기를 훨씬 초과하기 때문에,본 연구에서는 훈련 범위를 방선균문으로 제한하여 10,796개의 게놈을 포함하는 데이터 세트를 구축했습니다.유전자들은 420만 개의 단백질 패밀리로 분류되었고, 어휘는 가장 흔한 524,288개의 패밀리로 제한되어 약 891개의 TP3T 단백질을 포함하게 되었습니다.
ESM_DF 및 GeneCLR_DF 모델의 경우, 본 연구에서는 Gembase_DF 데이터셋을 구축했습니다. 아래 그림과 같이 DefenseFinder로 라벨링된 521,360개의 항파지 단백질을 양성 샘플로, 99% 이상에 존재하는 1억 1,600만 개의 고도로 보존된 핵심 유전자와 1,400만 개의 비방어 이동성 유전 요소 유전자를 음성 샘플로 사용했으며, 나머지 단백질은 라벨링되지 않은 후보로 유지했습니다.
훈련, 검증 및 테스트 간의 정보 유출을 방지하기 위해, 본 연구에서는 동일한 방어 시스템의 모든 단백질을 동일한 데이터 폴드로 그룹화하고 MMseqs2를 사용하여 데이터 폴드 간의 잔여 상동성을 제거함으로써 모델 평가의 엄격성을 확보했습니다.
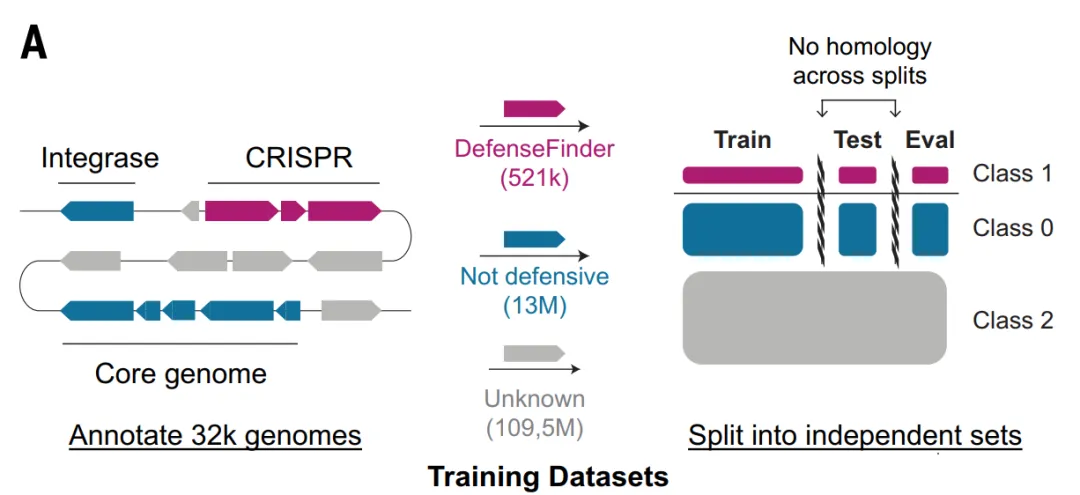
모델 아키텍처: 단계적으로 진행되는 3계층 딥러닝 모델.
기존의 "방어 점수" 방식의 한계를 극복하기 위해 연구팀은 미지의 시스템 발견, 전유전체 규모의 데이터 마이닝, 고정밀 통합 예측이라는 세 가지 목표를 지향하는 보완적이고 진보적인 딥러닝 프레임워크를 구축했습니다.구체적으로, 여기에는 유전체 컨텍스트 기반의 ALBERT_DF, 단백질 서열 기반의 ESM_DF, 그리고 서열 및 컨텍스트 정보를 통합하는 GeneCLR_DF가 포함됩니다.
그중 ALBERT_DF는 유전자 "인접 관계"로부터 기능적 신호를 학습하는 데 중점을 두고 새로운 방어 시스템을 발견할 수 있는 능력을 갖추고 있으며, ESM_DF는 아미노산 서열 모델링을 직접 사용하여 우수한 서열 간 일반화 능력을 보여주고, GeneCLR_DF는 두 가지 유형의 정보를 통합된 프레임워크에 통합하여 인식 정확도와 예측 범위 간의 균형을 더 잘 맞춘다.
ALBERT_DF 모델은 핵심적인 관찰 결과에 기반합니다. 즉, 항파지 시스템은 게놈 내에 군집을 이루는 경향이 있으며, 인접한 유전자 내부 및 유전자 간에 안정적인 조직 패턴이 존재한다는 것입니다. 이러한 특성을 바탕으로,본 연구는 자연어 처리 분야의 ALBERT 아키텍처를 유전체 모델링에 도입한다.단백질 패밀리를 "단어"로, 유전자 서열을 "구문 구조"로 취급함으로써, 숨겨진 유전자를 예측하여 지역적 맥락을 학습합니다.
기존의 염기서열 유사성 기반 방법과는 달리, 이 모델링 접근 방식은 유전체 구조 정보를 직접 활용하므로, 기존 시스템과 상동성이 없는 새로운 방어 메커니즘을 식별할 가능성이 더 큽니다. 그러나 이 방법은 이산화된 "어휘적" 표현에 의존하기 때문에 종간 확장에 있어 본질적인 한계를 지닙니다.
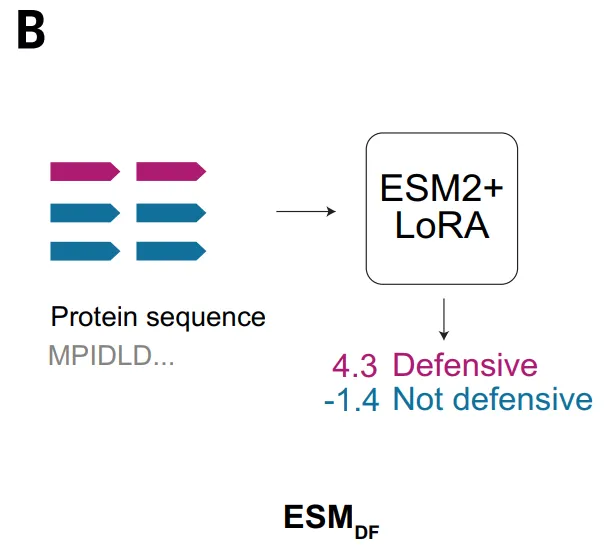
반면 ESM_DF 모델은 단백질 아미노산 서열에 직접 작용하는 다른 접근 방식을 취합니다.이 모델은 대규모 사전 학습을 통해 잔기 간의 공변량과 장거리 서열 관계를 학습합니다.이를 통해 인위적인 특징 추출에 의존하지 않고 기능적 신호를 추출할 수 있습니다. 미세 조정을 거친 ESM_DF는 모든 단백질에 점수를 매겨 항파지 방어에 참여하는지 여부를 판단할 수 있습니다. 이러한 접근 방식은 방법의 적용성을 크게 향상시켜 전체 게놈 규모에서 작동할 수 있도록 합니다. 그러나 동시에 ESM_DF의 판별 능력은 여전히 서열 유사성에 어느 정도 의존하므로, 알려진 방어 시스템의 멀리 떨어진 변이체를 식별하는 데는 더 효과적이지만, 상동성이 부족한 새로운 도메인을 식별하는 능력은 상대적으로 제한적입니다.
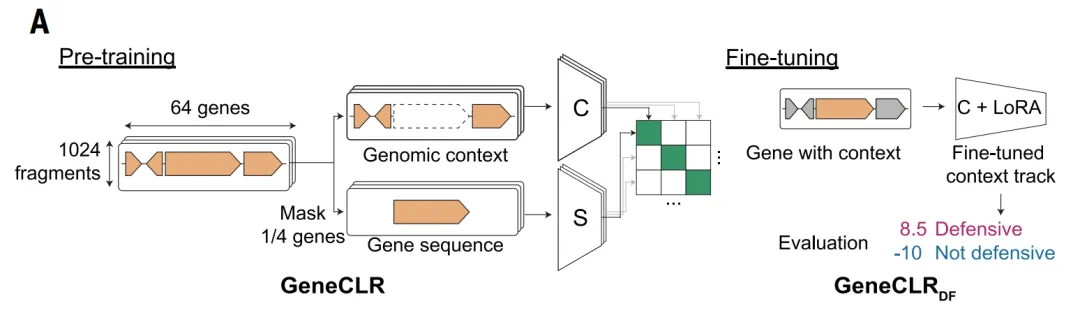
이를 바탕으로 서열 정보와 유전체 맥락 정보를 통합하기 위해 GeneCLR_DF 모델이 제안되었습니다.이 모델은 대조 학습 프레임워크를 사용하여 각 유전자에 대해 두 가지 표현을 동시에 학습합니다.한 가지 표현 방식은 단백질 서열에서, 다른 하나는 주변 유전체 서열에서 얻어집니다. 모델을 훈련시킴으로써 이 두 가지 표현 방식이 동일한 유전자에 해당하는지 여부를 판단하고, 이를 통해 표현 공간에서 두 가지 유형의 정보를 정렬합니다.
이 설계는 중요한 이점을 제공합니다. 특정 유전자가 서열 수준에서 상동성이 부족하더라도, 일반적인 유전체 맥락을 통해 식별 단서를 얻을 수 있습니다. 반대로, 맥락 정보가 비정형적일 경우에도 서열 특징을 통해 식별을 지원할 수 있습니다. 이러한 상호보완적인 메커니즘을 통해,GeneCLR은 새로운 시스템을 발견하는 능력과 후속 예측에서 대규모 응용 프로그램을 위한 확장성 사이의 균형을 유지합니다.
전반적으로, 이 세 가지 유형의 모델은 맥락 기반의 국소 패턴 학습에서 시퀀스 기반의 전역 일반화, 그리고 다중 소스 정보의 통합 모델링에 이르는 명확한 기술적 경로를 제시합니다. 이러한 계층적 설계는 단일 방법의 한계를 극복할 뿐만 아니라, 알려지지 않은 항파지 메커니즘을 체계적으로 탐구하기 위한 보다 보편적인 기술적 틀을 제공합니다.
TP3T 정밀도 991, TP3T 재현율 921을 달성하십시오.
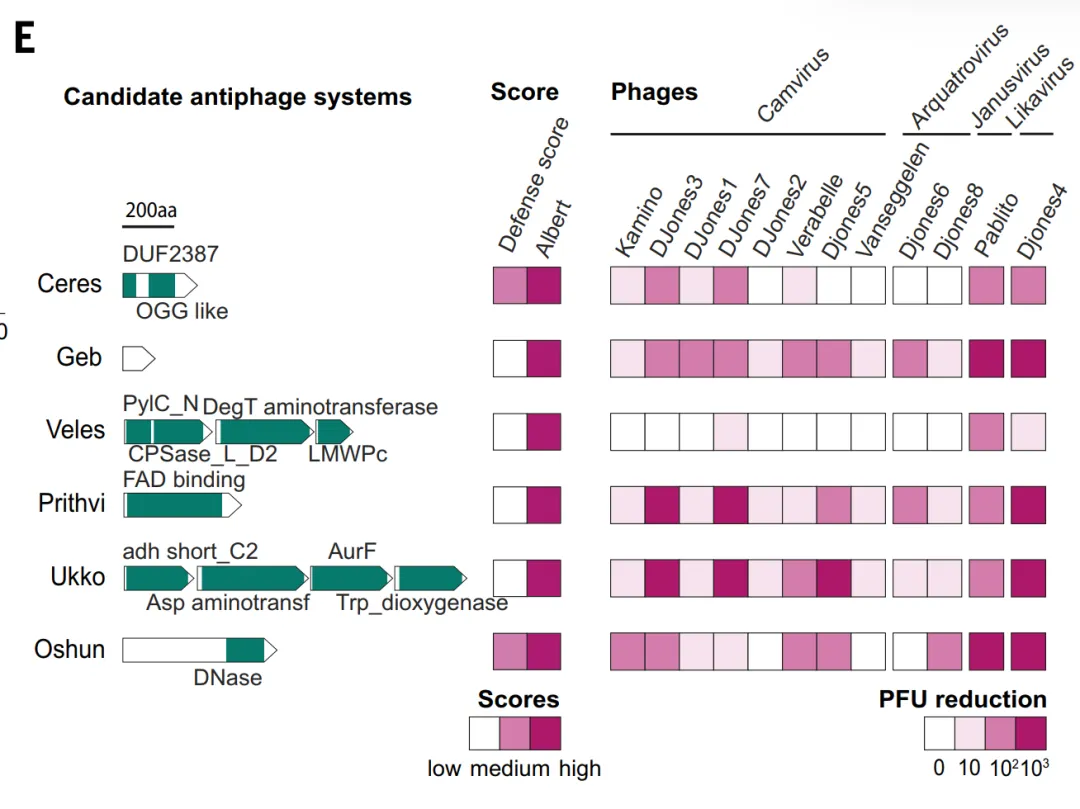
실험적 검증에서, 본 연구는 먼저 ALBERT_DF의 예측력을 평가했습니다.해당 모델은 총 1,930개의 항파지 단백질 후보군을 예측했으며, 그중 약 331개의 TP3T가 방어 점수 방법의 결과와 겹쳤습니다.연구진은 방어 점수 지원이나 알려진 상동성이 모두 부족한 10개의 후보 시스템을 추가로 선정하여 스트렙토마이세스 화이트너스(Streptomyces whiteus)에서 발현시킨 후 12개의 파지로 공격했습니다. 이 중 6개의 시스템이 강력한 방어력을 보여 플라크 형성 단위(PFU)를 100배 이상 감소시켰습니다. 세레스(Ceres)와 게브(Geb)와 같은 이 시스템들은 대사 효소와 기능이 알려지지 않은 작은 단백질들을 포함하고 있어 기존의 방어 영역 범위를 넘어서며, 유전체 맥락 기반 방법이 전통적인 방법으로는 식별하기 어려운 새로운 방어 메커니즘을 발견할 수 있음을 보여줍니다.
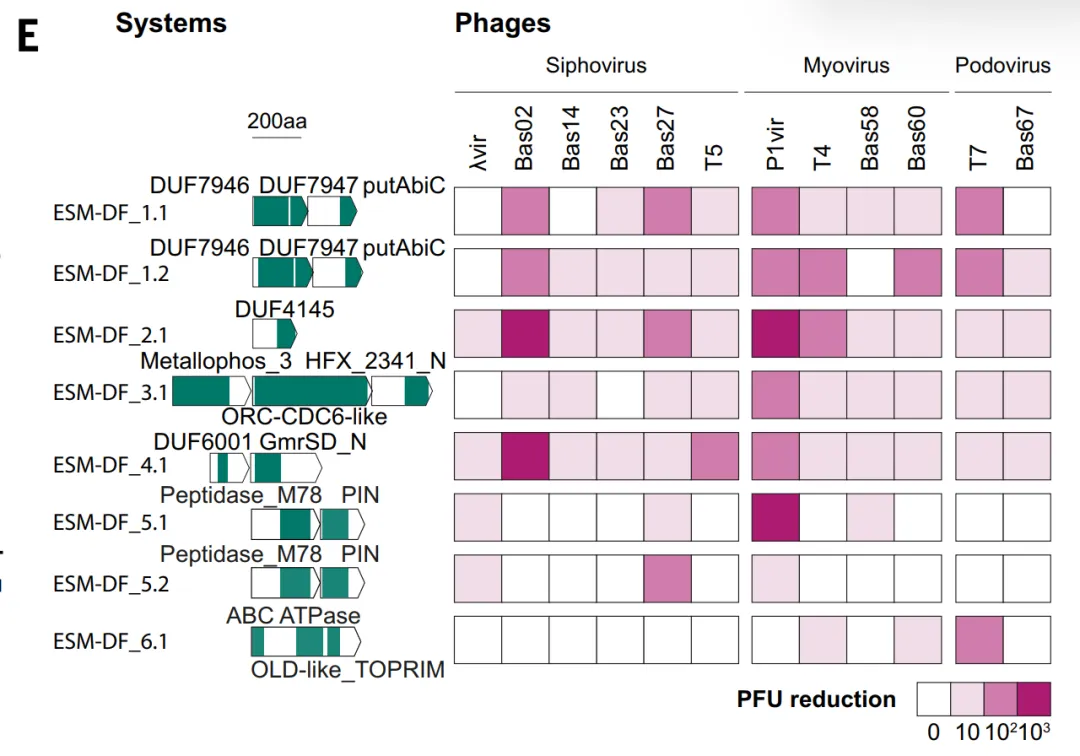
ESM_DF의 유효성 검증 연구에서는 대장균에서 높은 점수를 받은 후보 물질들을 대상으로 테스트를 진행했으며, 그중 6개 시스템이 항파지 기능을 나타냈습니다. ESM_DF는 여러 종류의 박테리오파지에 내성을 보였습니다. 이러한 시스템에는 기존에 알려진 방어 도메인의 변형체뿐만 아니라 DUF7946과 같이 이전에는 항파지 기능과 관련이 없었던 도메인도 포함되었습니다.이는 ESM이 서열 상동성뿐만 아니라 더 넓은 범위의 기능적 특징을 식별할 수 있음을 나타내지만, 전반적으로는 여전히 기존 시스템의 확장에 그치는 경향이 있음을 보여줍니다.
GeneCLR_DF는 시스템 평가에서 가장 우수한 성능을 보였습니다. 테스트 세트에서,예측 점수를 통해 방어 단백질과 비방어 단백질을 명확하게 구분할 수 있습니다.진화 분석에서, 이 시스템은 역전사인자, CBASS, Thoeris와 같은 주요 방어 계통에 일관되게 높은 점수를 부여한 반면, ESM-650M_DF는 이러한 계통을 부분적으로만 식별할 수 있었습니다.
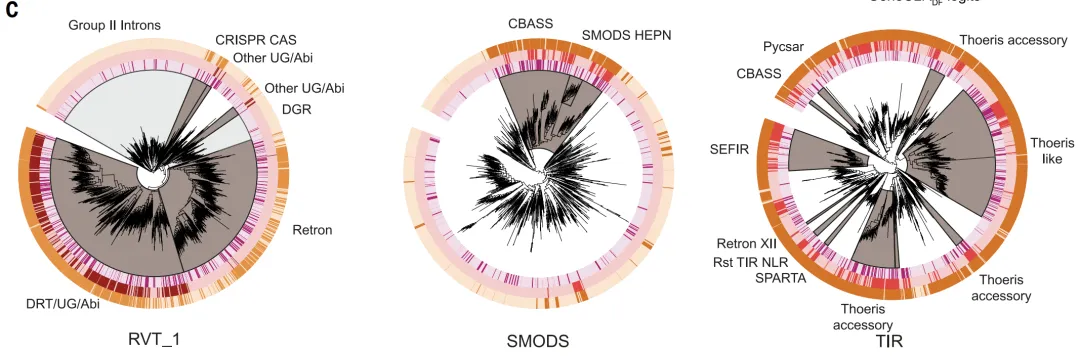
다양한 유전체 환경(방어 영역, 인테그론, 프리파지 영역)에서,GeneCLR_DF는 방어 모듈의 위치를 정확하게 파악할 수 있습니다.정량적 분석 결과, 임계값 -0.74에서 GeneCLR_DF는 991개의 TP3T를 정밀도로, 92.41개의 TP3T를 재현율로 검출한 반면, 동일한 정밀도에서 ESM_DF는 581개의 TP3T만 재현했습니다. 11개의 TP3T의 오검출률로 GeneCLR_DF는 알려진 방어 단백질 패밀리에서 941개의 TP3T를 검출했는데, 이는 ESM-650MDF(351개)와 방어 분획법(51개)보다 현저히 높은 수치이며, 561개의 TP3T 패밀리만 식별한 결과입니다. 또한, 새로 추가된 110개의 시스템에서 751개의 TP3T를 검출했습니다. 총 615,672개의 후보 단백질 패밀리 중 931개의 TP3T는 GeneCLR_DF에서만 검출되었습니다.
오페론 수준에서, 공선형 클러스터링에 기반한 추가 분석 결과, 상당수의 방어 구조가 여전히 알려지지 않은 것으로 나타났습니다. 85%의 예측 단백질 패밀리는 ESM_DF와 GeneCLR_DF에 의해서만 식별되었으며, 45%의 오페론 패밀리와 52.7%의 오페론 클러스터는 이전에 기능적 주석이 부족했습니다. 진화 분석 또한 다음과 같은 사실을 밝혀냈습니다...세균 게놈에서 방어 유전자의 중간 비율은 0.46%에서 1.53%로 증가했습니다.또한, 많은 시스템에 이동성 유전 요소가 풍부하게 포함되어 있으며, 23.5%는 MGE 경계 내에 위치하고 47.1%의 위성 요소는 방어 능력을 암호화하는 것으로 예측됩니다.
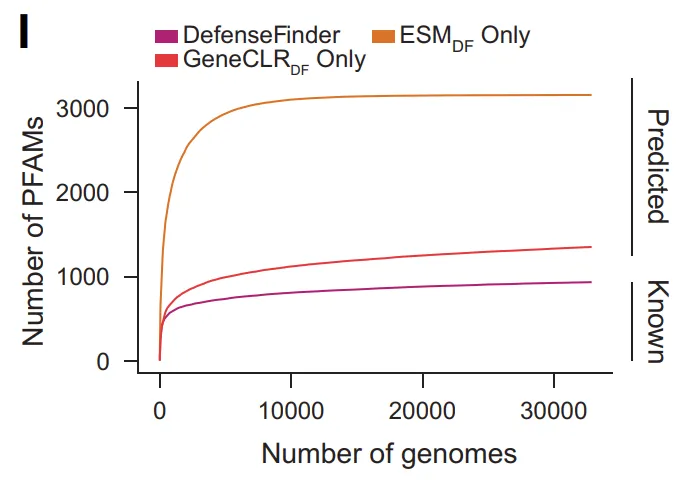
분자 다양성 수준에서 GeneCLR_DF는 방어 관련 Pfam 패밀리의 수를 934개에서 3,154개(전체 Pfam 중 약 15%)로 확장했습니다. 동시에, 예측된 단백질 패밀리 중 40만 개 이상이 Pfam 주석이 없었으며, DefenseFinder에 나타난 것은 5% 미만이었습니다. 또한 3,500개 이상의 오페론 패밀리는 알려진 도메인이 없는 단백질로만 구성되어 있었습니다. 이러한 결과는 다음과 같은 점을 시사합니다...항파지 방어의 분자적 영역 중 상당 부분은 아직 체계적으로 규명되지 않았다.
딥러닝은 항파지 방어 기작 발견의 효율성을 획기적으로 향상시킵니다.
딥러닝 기반 항파지 시스템 예측 프레임워크와 이를 통해 구축된 세균 항바이러스 면역 아틀라스는 이 분야에서 보다 확장 가능한 연구 방향을 제시하고 있습니다. 개별 사례 발견에 의존하는 "점진적 돌파구"에서 패턴 인식을 기반으로 하는 "체계적인 탐색"으로의 전환을 의미합니다. 이러한 변화는 새로운 방어 메커니즘 발견의 효율성을 높일 뿐만 아니라 학술 연구와 산업 응용 분야를 더욱 가깝게 만듭니다.
학계에서 이러한 접근 방식은 빠르게 확산되었습니다. 여러 연구 기관에서 머신 러닝과 유전체 분석을 결합하여 더 큰 규모로 파지 내성 시스템을 식별하려는 시도를 시작했습니다. 예를 들어,MIT 연구팀이 개발한 DefensePredictor 모델은,단백질 언어 모델의 모델링 논리를 활용하고 유전자 서열 및 게놈 컨텍스트 정보를 통합함으로써, 항파지 단백질을 매우 민감하게 식별할 수 있었습니다. 이 모델은 약 17,000개의 원핵생물 참조 게놈을 사용하여 훈련되었으며, 독립적인 테스트에서 약 821개의 새로운 TP3T 방어 시스템을 식별하여 "패턴 기반 미지의 기능 발견"의 실현 가능성을 더욱 입증했습니다.
논문 제목: DefensePredictor: 원핵생물 면역 체계를 발견하기 위한 기계 학습 모델
논문 링크:
https://www.science.org/doi/10.1126/science.adv7924
산업계에서도 관련 기술들이 빠르게 도입되고 있습니다. 항생제 내성이 심각해짐에 따라 박테리오파지와 그 파생 기술들이 다시 주목받으며 기존 항생제를 대체하거나 보완하는 중요한 방향으로 떠오르고 있습니다. 임상 단계 기업인 로커스 바이오사이언스(Locus Biosciences)는 머신러닝과 합성생물학을 결합한 유전자 조작 박테리오파지 기반 플랫폼을 구축하여 다제내성 대장균 치료제 후보 물질인 LBP-EC01을 개발함으로써 파지 치료의 정확성과 제어 가능성을 한 단계 끌어올렸습니다.
한편, Micreos는 박테리오파지와 엔도소말린의 산업화에 초점을 맞춰 보다 응용 지향적인 접근 방식을 취하고 있습니다. 이 회사의 제품인 Listex는 식품 가공에서 리스테리아균 오염을 억제하는 데 사용되어 여러 국가에서 규제 승인을 받았습니다. Staph Efekt는 엔도소말린의 특이적인 살균 능력을 활용하여 스킨케어 제품에 적용하고 있습니다. 이러한 접근 방식은 단순히 실험실 수준에 머무르지 않고, 항파지 메커니즘을 구체적이고 실용적인 제품으로 전환하는 "기능적 구현"을 강조합니다.
전반적으로, 알고리즘 모델에서 실험적 검증, 그리고 산업 응용에 이르기까지, 항파지 연구는 점차 완전한 사슬을 형성해 나가고 있습니다. 데이터 축적과 모델 개선이 거듭됨에 따라, 계산에서 시작하여 실험을 통해 검증하고 응용에 따라 발전하는 이러한 경로는 앞으로도 세균 면역 체계에 대한 심층적인 이해를 촉진하고, 이러한 연구 결과를 실질적인 해결책으로 효과적으로 전환하는 데 기여할 것으로 예상됩니다.
참조 링크:
https://mp.weixin.qq.com/s/usrVEOeBD5gphhslZahLCA
https://mp.weixin.qq.com/s/Pxlh69TXSr8ffAp_ul3URw








